Add the ability to search by query hash, plan hash, and SQL handle
The SQL Server 2022 stuff isn’t important just yet, but… Hey, maybe someday.
The new search functionality is really important though, at least for how I use sp_QuickieStore much of the time. Often, you’ll find hashes and handles in other parts of the database:
Plan cache
Deadlock XML
Blocked process report
Query plans
There’s still no good way for you to search Query Store by anything. Not plan or query id, not query text, not object names. Nothing.
Don’t worry, I’m here for you.
Some other minor updates were to:
Improve the help section
Improve code comments throughout
Remove the filter to only show successful executions (sometimes you need to find queries that timed out or something)
If you filter on any hash or handle, I’ll display that in the final output so they’re easy to identify
Replace TRY_CONVERT with TRY_CAST, which throws errors in fewer circumstances
That’s about all the stuff you need to know about. Aside from that, all my changes were slight logical errors or plumbing to implement the new features.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
USE StackOverflow2013;
EXEC dbo.DropIndexes;
SET NOCOUNT ON;
DBCC FREEPROCCACHE;
GO
CREATE INDEX
chunk
ON dbo.Posts
(OwnerUserId, Score DESC)
INCLUDE
(CreationDate, LastActivityDate)
WITH
(MAXDOP = 8, SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
GO
CREATE OR ALTER VIEW
dbo.PushyPaul
WITH SCHEMABINDING
AS
SELECT
p.OwnerUserId,
p.Score,
p.CreationDate,
p.LastActivityDate,
PostRank =
DENSE_RANK() OVER
(
PARTITION BY
p.OwnerUserId
ORDER BY
p.Score DESC
)
FROM dbo.Posts AS p;
GO
SELECT
p.*
FROM dbo.PushyPaul AS p
WHERE p.OwnerUserId = 22656;
GO
CREATE OR ALTER PROCEDURE
dbo.StinkyPete
(
@UserId int
)
AS
SET NOCOUNT, XACT_ABORT ON;
BEGIN
SELECT
p.*
FROM dbo.PushyPaul AS p
WHERE p.OwnerUserId = @UserId;
END;
GO
EXEC dbo.StinkyPete
@UserId = 22656;
/*Start Here*/
ALTER DATABASE
StackOverflow2013
SET PARAMETERIZATION SIMPLE;
DBCC TRACEOFF
(
4199,
-1
);
ALTER DATABASE SCOPED CONFIGURATION
SET QUERY_OPTIMIZER_HOTFIXES = OFF;
SELECT
p.*
FROM dbo.PushyPaul AS p
WHERE p.OwnerUserId = 22656
AND 1 = (SELECT 1); /*Avoid trivial plan/simple parameterization*/
/*Let's cause a problem!*/
ALTER DATABASE
StackOverflow2013
SET PARAMETERIZATION FORCED;
SELECT
p.*
FROM dbo.PushyPaul AS p
WHERE p.OwnerUserId = 22656
AND 1 = (SELECT 1); /*Avoid trivial plan/simple parameterization*/
/*Can we fix the problem?*/
DBCC TRACEON
(
4199,
-1
);
SELECT
p.*
FROM dbo.PushyPaul AS p
WHERE p.OwnerUserId = 22656
AND 1 = (SELECT 1); /*Avoid trivial plan/simple parameterization*/
/*That's kinda weird...*/
DBCC FREEPROCCACHE;
SELECT
p.*
FROM dbo.PushyPaul AS p
WHERE p.OwnerUserId = 22656
AND 1 = (SELECT 1); /*Avoid trivial plan/simple parameterization*/
/*Turn Down Service*/
DBCC TRACEOFF
(
4199,
-1
);
SELECT
p.*
FROM dbo.PushyPaul AS p
WHERE p.OwnerUserId = 22656
AND 1 = (SELECT 1); /*Avoid trivial plan/simple parameterization*/
/*Okay then.*/
/*I'm different.*/
ALTER DATABASE SCOPED CONFIGURATION
SET QUERY_OPTIMIZER_HOTFIXES = ON;
SELECT
p.*
FROM dbo.PushyPaul AS p
WHERE p.OwnerUserId = 22656
AND 1 = (SELECT 1); /*Avoid trivial plan/simple parameterization*/
/*Cleanup*/
ALTER DATABASE
StackOverflow2013
SET PARAMETERIZATION SIMPLE;
ALTER DATABASE SCOPED CONFIGURATION
SET QUERY_OPTIMIZER_HOTFIXES = OFF;
DBCC TRACEOFF
(
4199,
-1
);
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
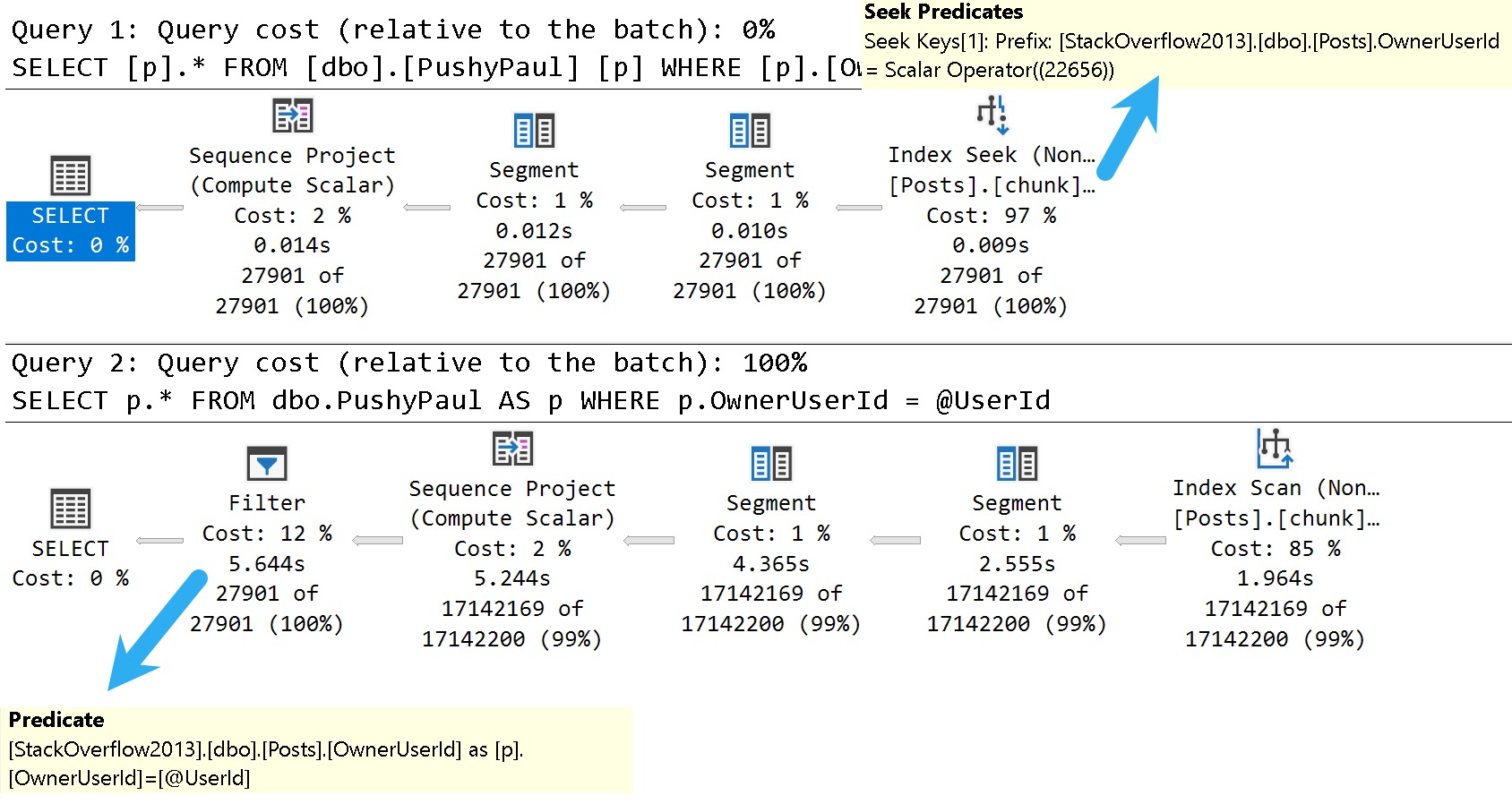
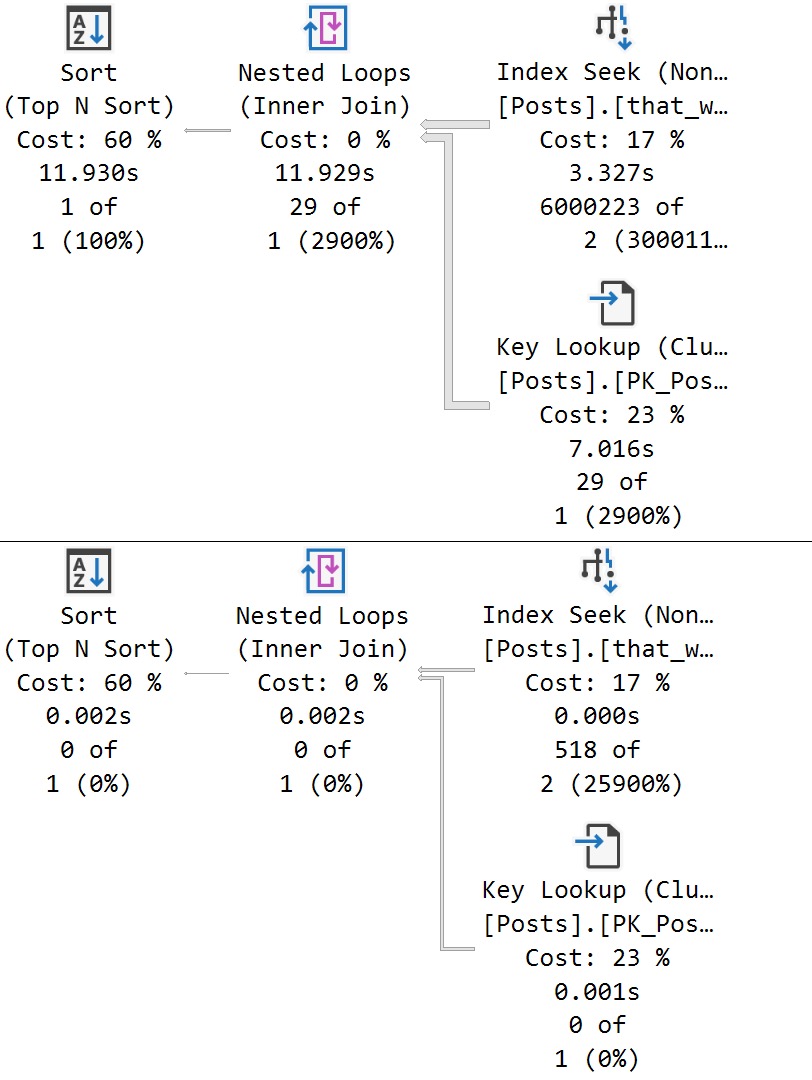
In the release notes for SQL Server 2017 CU30, there’s a note that it fixes a problem where parameters can’t be pushed passed Sequence Project operators:
“In Microsoft SQL Server 2017, running parameterized queries skips the SelOnSeqPrj rule. Therefore, pushdown does not occur.” But it doesn’t actually do that.
Here are the good and bad plans, comparing using a literal value vs. a parameterized value:
dunksville
In the plan with a literal value, the predicate is applied at the index seek, and the filtering is really quick.
In the plan with a parameterized value, the index is scanned, and applied at a filter way later in the query plan.
This is where the SelOnSeqPrj rule comes in: The parameter can’t be pushed past the Sequence Project operator like the literal value can.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
A while back, I wrote a bunch of posts about things I’d like to see vNext take care of. In this post, since it’s Friday and I don’t wanna do anything, will round those up and cover whether or they made it in or not.
Well, maybe I’ll need to update the list for future releases of SQL Server 2022.
Hmpf.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Why two are zero-based and one is not is beyond what I can explain to you, here.
Perhaps that will be addressed in a future release.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
You’re a DBA or Developer, and you’ve been using SQL Server for a few years.
You know there are different ways to make queries faster, but you’re not sure when to use them.
I’m Erik Darling, and I’ll be your sommelier for the evening.
Over several courses of delicious demos, I’ll show you the types of performance problems different tuning techniques pair well with, and which ones to avoid.
When we’re done, you’ll understand exactly what patterns to look for when you’re troubleshooting slow queries, and how to approach them.
You’ll have the secret recipe for gourmet queries.
Dates And Times
The PASS Data Community Summit is taking place in Seattle November 15-18, 2022 and online.
You can register here, to attend online or in-person. I’ll be there in all my fleshy goodness, and I hope to see you there too!
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I can’t have my dear friend Brent being all distraught with all those fast cars around. That’s how accidents happen, and I fear he might leave the Blitz scripts to me in his will or something.
In Paul’s post, he talks about using undocumented trace flag 8666 to get additional details about Sort operators.
Let’s do that. Paul is smart, though he is always completely wrong about which season it is.
DROP TABLE IF EXISTS
dbo.Votes_CCI;
SELECT
v.*
INTO dbo.Votes_CCI
FROM dbo.Votes AS v;
I’m using the Votes table because it’s nice and narrow and I don’t have to tinker with any string columns.
Strings in databases were a mistake, after all.
DBCC TRACEON(8666);
CREATE CLUSTERED COLUMNSTORE INDEX
vcci
ON dbo.Votes_CCI
ORDER (Postid);
DBCC TRACEOFF(8666);
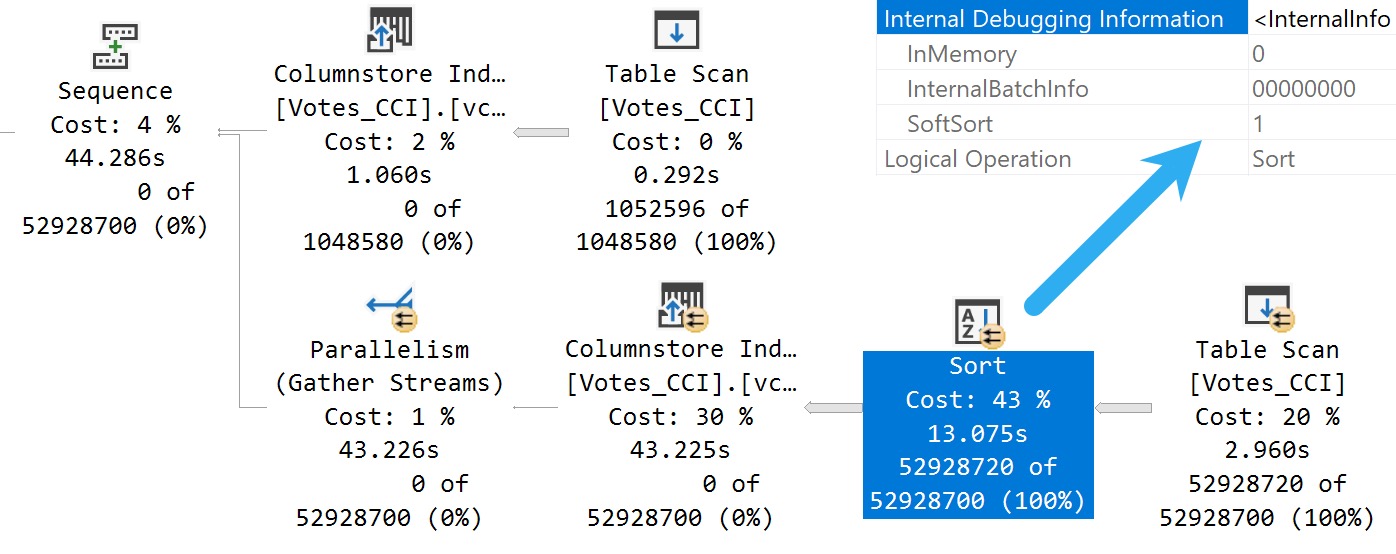
Here’s what we get back in the query plan:
Tainted Sort
We’ve got a Soft Sort! What does our seasonally maladjusted friend say about those?
A “soft sort” uses only its primary memory grant and never spills. It doesn’t guarantee fully-sorted output. Each sort run using the available memory grant will be sorted. A “sort sort” represents a best effort given the resource available. This property can be used to infer that a Sort is implemented with CQScanPartitionSortNew without attaching a debugger. The meaning of the InMemory property flag shown above will be covered in part 2. It does not indicate whether a regular sort was performed in memory or not.
Well, with that attitude, it’s not surprising that there are so many overlapping buckets in the column store index. If it’s not good enough, what can you do?
Building the index with the Soft Sort here also leads to things being as bad as they were in Brent’s post.
Insert Debugging Here
Alas, there’s (almost) always a way. Microsoft keeps making these trace flag things.
There are a bunch of different ways to track them down, but figuring out the behavior of random trace flags that you may find just by enabling them isn’t easy.
One way to tie a trace flag to a behavior is to use WinDbg to step through different behaviors in action, and see if SQL Server checks to see if a trace flag is enabled when that behavior is performed.
If you catch that, you can be reasonably sure that the trace flag will have some impact on the behavior. Not all trace flags can be enabled at runtime. Some need to be enabled as startup options.
Sometimes it’s hours and hours of work to track this stuff down, and other times Paul White (b|t) already has notes on helpful ones.
The trace flag below, 2417, is present going back to SQL Server 2014, and can help with the Soft Sort issues we’re seeing when building ordered clustered column store indexes today.
Here’s another one:
DBCC TRACEON(8666, 2417);
CREATE CLUSTERED COLUMNSTORE INDEX
vcci
ON dbo.Votes_CCI
ORDER (Postid)
WITH(MAXDOP = 1);
DBCC TRACEOFF(8666, 2417);
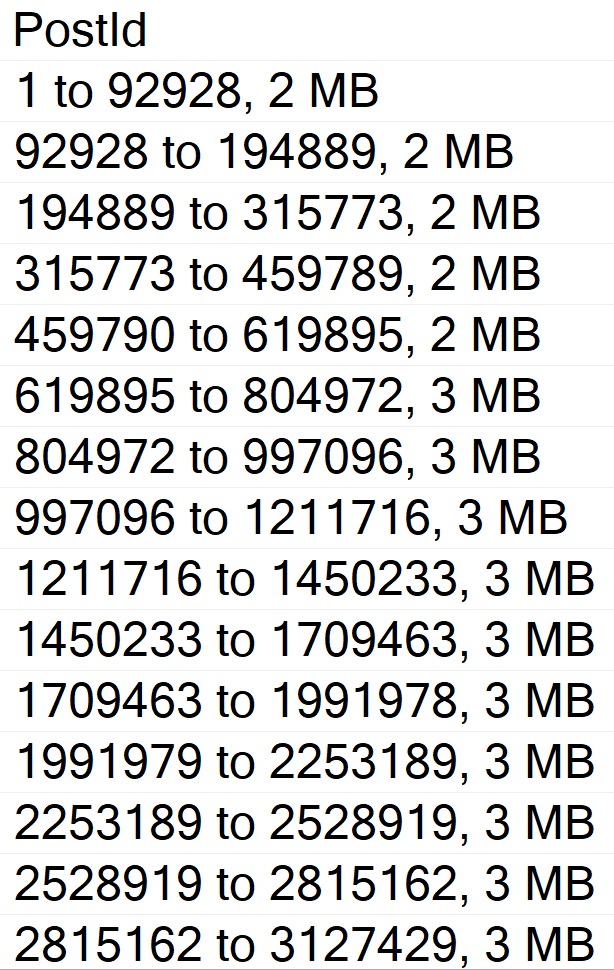
The MAXDOP 1 hint isn’t strictly necessary. With a parallel plan, you may see up to DOP overlapping row groups.
community service
That’s why it was a popular maneuver to emulate this behavior by creating a clustered row store index, and then create a clustered column store index over it with drop existing and a MAXDOP 1 hint.
At DOP 1, you don’t see that overlap. It takes a lot longer of course — 3 minutes instead of 30 or so seconds — which is a real bummer. But without it, you could see DOP over lapping rowgroups.
If you want All The Pretty Little Rowgroups, this is what you have to do.
Anyway, the result using sp_BlitzIndex looks a lot better now:
EXEC sp_BlitzIndex
@TableName = 'Votes_CCI';
capture the flag
How nice.
You can also use undocumented and unsupported trace flag 11621, which is
[A] feature flag for the ‘partition sort on column store order’ so the end result is similar, but via a different mechanism to 2417.
A partition sort is useful in general to prevent unnecessary switching between partitions. If you sort the stream by partition, you process all the rows for one before moving on to the next. A soft sort is ok there because it’s just a performance optimization. Worst case, you end up switching between partitions quite often because the sort ran out of memory, but correct results will still occur.
Chain Gang
A “reasonable” alternative to trace flags maybe to adjust the index create memory configuration option. If we set it down to the minimum value, we get a “helpful” error message:
This index operation requires 123208 KB of memory per DOP.
The total requirement of 985800 KB for DOP of 8 is greater than the sp_configure value of 704 KB set for the advanced server configuration option “index create memory (KB)”.
Increase this setting or reduce DOP and rerun the query.
If you get the actual execution plan for the clustered column store index create or rebuild with the Soft Sort disabled and look at the memory grant, you get a reasonable estimate for what to set index create memory to.
Changing it does two things:
Avoids the very low memory grant that Soft Sorts receive, and causes the uneven row groups
The Soft Sort keeps the index create from going above that index create memory number
Setting index create memory for this particular index creation/rebuild to 5,561,824 gets you the nice, even row groups (at MAXDOP 1) that we saw when disabling the Soft Sort entirely.
Bottom line, here is that uneven row groups happen with column store indexes when there’s a:
Parallel create/rebuild
Low memory grant create/rebuild
If this sort of thing is particularly important to you, you could adjust index create memory to a value that allows the Soft Sort adequate memory.
But that’s a hell of a lot of work, and I hope Microsoft just fixes this in a later build.
The bits for this were technically available in SQL Server 2019 as well, but I’m not telling you how to do that. It’s not supported, and bad things might happen if you use it.
I mean, bad things happen in SQL Server 2022 where it’s supported unless you use an undocumented trace flag, but… Uh. I dunno.
This trace flag seems to set things back to how things worked in the Before Times, though, which is probably how they should have stayed.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
They sort of changed my life a little, despite the author’s aversion to the letter Z. So that’s cool. Can’t have everything.
To this day, though, I see people screw up paging queries in numerous ways.
Selecting all the columns in one go
Adding in joins when exists will do
Sticking a DISTINCT on there just because
Thinking a view will solve some problem
Piles and piles of UDFs
Local variables for TOP or OFFSET/FETCH
Not paying attention to indexing
It’s sort of like every other query I see, except with additional complications.
Especially cute for a query slathered in NOLOCK hints is the oft-accompanying concern that “data might change and people might see something weird when they query for the next page”.
Okay, pal. Now you’re concerned.
Modern Love
A while back I recorded a video about using nonclustered column store indexes to improve the performance of paging queries:
While a lot of the details in there are still true, I want to talk about something slightly different today. While nonclustered column store indexes make great data sources for queries with unpredictable search predicates, they’re not strictly necessary to get batch mode anymore.
With SQL Server 2019, you can get batch mode on row store indexes, as long as you’re on Enterprise Edition, and in compatibility level 150.
Deal with it.
The thing is, how you structure your paging queries can definitely hurt your chances of getting that optimization.
Saddened Face
The bummer here is that the paging technique that I learned from Paul’s articles (linked above) doesn’t seem to qualify for batch mode on row store without a column store index in place, so they don’t make the demo cut here.
The good news is that if you’re going to approach this with any degree of hope for performance, you’re gonna be using a column store index anyway.
The two methods we’re going to look at are OFFSET/FETCH and a more traditional ROW_NUMBER query.
As you may have picked up from the title, one will turn out better, and it’s not the OFFSET/FETCH variety. Especially as you get larger, or go deeper into results, it becomes a real boat anchor.
Anyway, let’s examine, as they say in France.
Barfset Wretch
This is the best way of writing this query that I can come up with.
DECLARE
@page_number int = 1,
@page_size int = 1000;
WITH
paging AS
(
SELECT
p.Id
FROM dbo.Posts AS p
ORDER BY
p.LastActivityDate,
p.Id
OFFSET ((@page_number - 1) * @page_size)
ROW FETCH NEXT (@page_size) ROWS ONLY
)
SELECT
p.*
FROM paging AS pg
JOIN dbo.Posts AS p
ON pg.id = p.Id
ORDER BY
p.LastActivityDate,
p.Id
OPTION (RECOMPILE);
Note that the local variables don’t come into play so much here because of the recompile hint.
Still, just to grab 1000 rows, this query takes just about 4 seconds.
what took you so long?
This is not so good.
Examine!
Hero Number
The better-performing query here with the batch mode on row store enhancement(!) is using a single filtered ROW_NUMBER to grab the rows we care about.
DECLARE
@page_number int = 1,
@page_size int = 1000;
WITH
fetching AS
(
SELECT
p.Id,
n =
ROW_NUMBER() OVER
(
ORDER BY
p.LastActivityDate,
p.Id
)
FROM dbo.Posts AS p
)
SELECT
p.*
FROM fetching AS f
JOIN dbo.Posts AS p
ON f.Id = p.Id
WHERE f.n > ((@page_number - 1) * @page_size)
AND f.n < ((@page_number * @page_size) + 1)
ORDER BY
p.LastActivityDate,
p.Id
OPTION (RECOMPILE);
Again, this is about the best I can write the query. Maybe you have a better way. Maybe you don’t.
Mine takes a shade under 2 seconds. Twice as fast. Examine!
cell tv
I’ll take twice as fast any day of the week.
Compare/Contrast
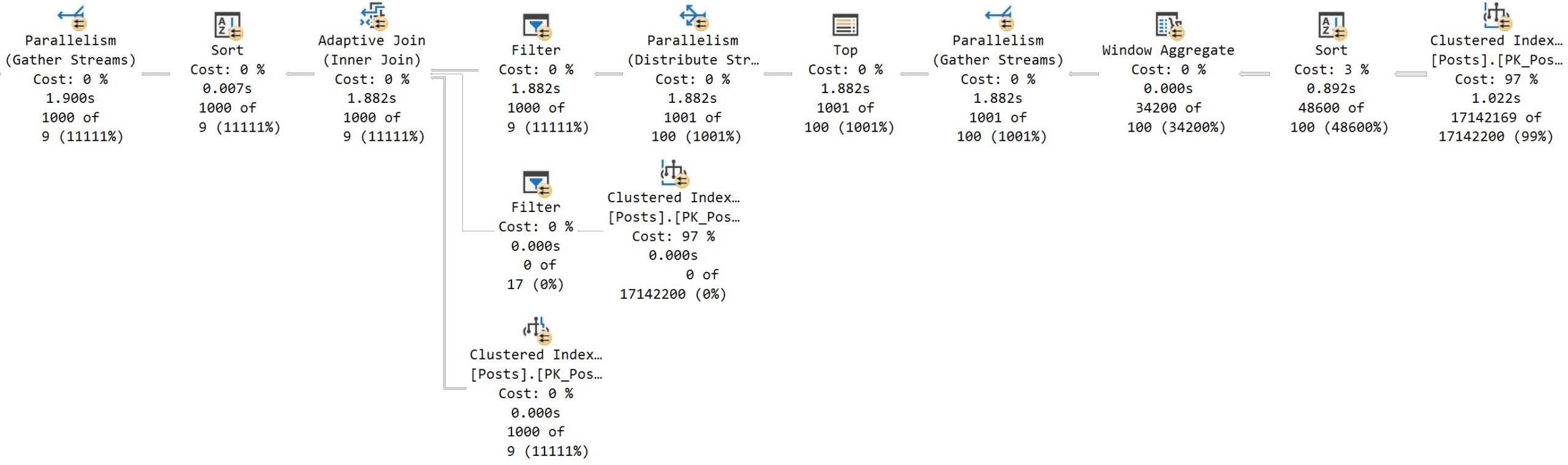
The OFFSET/FETCH query plan is all in row mode, while the ROW_NUMBER query has batch mode elements.
You can see this by eyeballing the plan: it has a window aggregate operator, and an adaptive join. There are other batch mode operators here, but none have visual cues in the graphical elements of the plan.
This is part of what makes things faster, of course. The differences can be even more profound when you add in the “real life” stuff that paging queries usually require. Filtering, joining, other sorting elements, etc.
Anyway, the point here is that how you write your paging queries from the start can make a big difference in how they end up, performance-wise.
Newer versions of SQL Server where certain behaviors are locked behind heuristics (absent column store indexes being present in some manner) can be especially fickle.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
There are some code comments you see that really set the stage for how tuning a query is going to go.
Usually one misgiving about how SQL Server works gives way to a whole levee-breaking bevy of other ones and three days later you can’t feel your legs but dammit it’s done.
Okay, maybe it was three hours, but it felt like three days. Something about the gravitation pull of these black hole queries.
One fix I’ve been wishing for, or wish I’ve been fixing for, is a cure for local variables. I’d even be cool if Forced Parameterization was that cure, but you know…
Time will tell.
Husk
Let’s say we’ve got this stored procedure, which does something similar to the “I’m gonna fix parameter sniffing with a local variable hey why is everything around me turning to brimstone before my very eyes?” idea, but with… less of an end-of-times vibe.
CREATE OR ALTER PROCEDURE
dbo.IndexTuningMaster
(
@OwnerUserId int,
@ParentId int,
@PostTypeId int
)
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
/*Someone passed in bad data and we got a bad query plan,
and we have to make sure that doesn't happen again*/
DECLARE
@ParentIdFix int =
CASE
WHEN @ParentId < 0
THEN 0
ELSE @ParentId
END;
SELECT TOP (1)
p.*
FROM dbo.Posts AS p
WHERE p.ParentId = @ParentIdFix
AND p.PostTypeId = @PostTypeId
AND p.OwnerUserId = @OwnerUserId
ORDER BY
p.Score DESC,
p.Id DESC;
END;
We get a super low guess for both. obviously that guess hurts a large set of matched data far worse than a small one, but the important thing here is that both queries receive the same bad guess.
This is a direct side effect of the local variable’s poor estimate, which PSP isn’t quite yet ready to go up against.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
While the Parameter Sensitive Plan (PSP) optimization won’t fix every problem with this lazy coding habit, it can fix some of them in very specific circumstances, assuming:
The parameter is eligible for PSP
The parameter is present across IF branches
We’re going to use a simple one parameter example to illustrate the potential utility here.
After all, if I make these things too complicated, someone might leave a comment question.
The horror
IFTTT
Here’s the procedure we’re using. The point is to execute one branch if @Reputation parameter is equal to one, and another branch if it equals something else.
In the bad old days, both queries would get a plan optimized at compile time, and neither one would get the performance boost that you hoped for.
In the good news days that you’ll probably get to experience around 2025, things are different!
CREATE OR ALTER PROCEDURE
dbo.IFTTT
(
@Reputation int
)
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
SET STATISTICS XML ON;
IF @Reputation = 1
BEGIN
SELECT
u.Id,
u.DisplayName,
u.Reputation,
u.CreationDate
FROM dbo.Users AS u
WHERE u.Reputation = @Reputation;
END;
IF @Reputation > 1
BEGIN
SELECT
u.Id,
u.DisplayName,
u.Reputation,
u.CreationDate
FROM dbo.Users AS u
WHERE u.Reputation = @Reputation;
END;
SET STATISTICS XML OFF;
END;
GO
Johnson & Johnson
If we execute these queries back to back, each one gets a new plan:
EXEC dbo.IFTTT
@Reputation = 1;
GO
EXEC dbo.IFTTT
@Reputation = 2;
GO
psychic driving
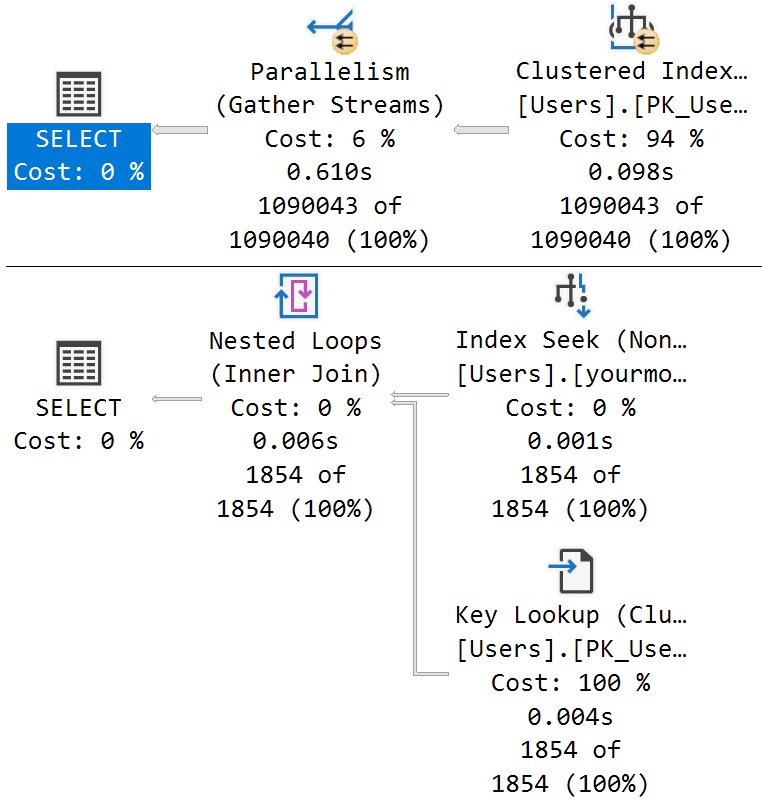
Optimize For You
The reason why is in the resulting queries, as usual. The Reputation column has enough skew present to trigger the PSP optimization, so executions with differently-bucketed parameter values end up with different plans.
And of course, each plan has different compile and runtime values:
care
If I were to run this demo in a compatibility level under 160, this would all look totally different.
This is one change I’m sort of interested to see the play-out on.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.