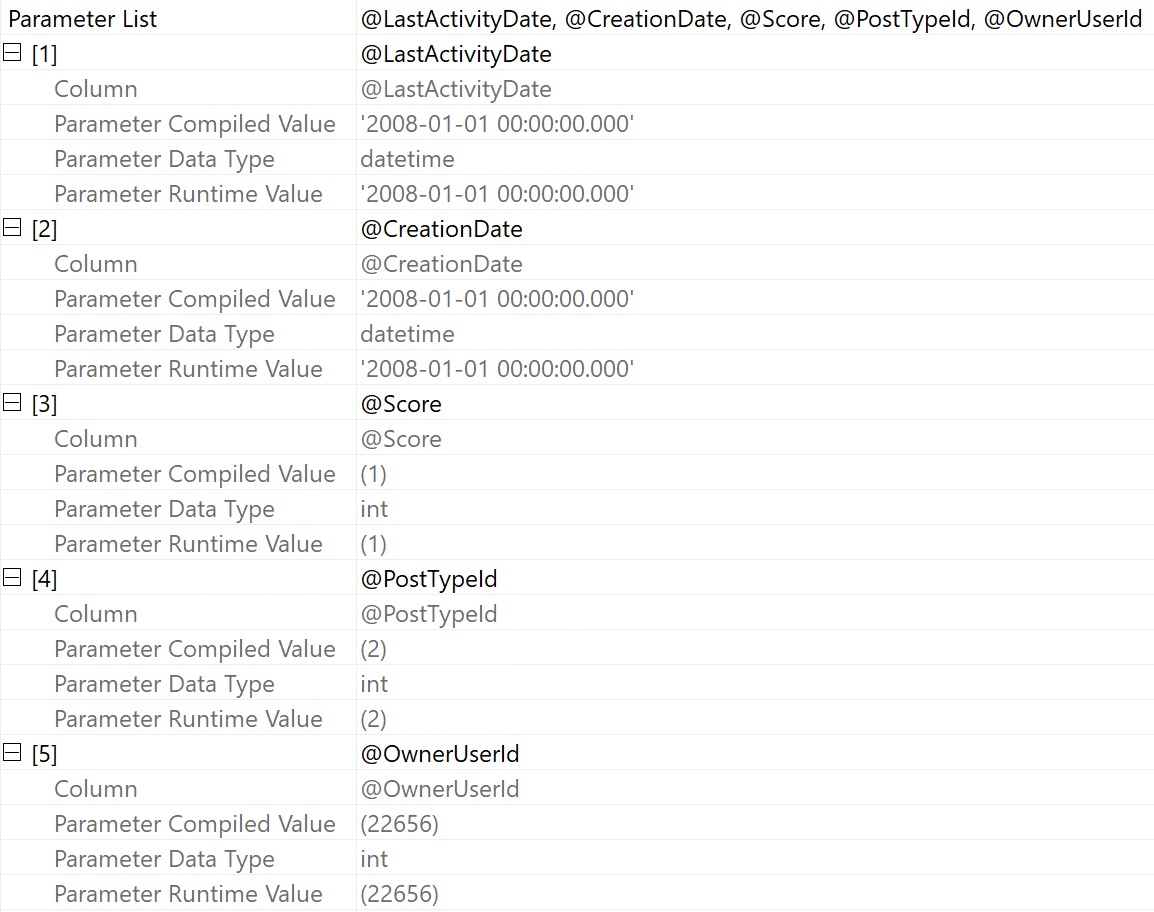
I found a few stored procedures with single plan cache entries over 500 MB of memory each according to sys.dm_exec_cached_plans while optimizing the plan cache in production. The stored procedures were relatively simple and both execution plans were less than 1 MB when saved as sqlplan files. I was confused, offended, and confused.
First published on MSDN on Jan 09, 2007
Did you know that the memory used for cursors can be cached along with the compiled plan? I’ll include a direct quote of the ancient wisdom:
Inactive cursors are cached in the compiled plan. Just like MXCs there are two lists maintained here: the lookup list and the enum list. The lookup list stores the inactive cursors. When a cursor is de-allocated, the memory used to store the cursor is cached. On subsequent re-execution of the batch with this cursor, the cached cursor memory is reused and re-initialized as an active cursor. The enum list has the list of active and inactive cursors and is used to enumerate all cursors for a compiled plan.
Cursors are re-generatable given a compiled plan. Relative to compiled plans they are also relatively inexpensive to re-generate.
I checked sys.dm_exec_cached_plan_dependent_objects and found that nearly all of the cached memory was used for the cursors instead of the execution plans. This makes sense because there was no reason why a simple procedure should use 500 MB for a cached plan, but why were the cursors using so much memory?
Back to 2022
I was able to create a simple reproduction of the issue on SQL Server 2022 CU13 which is the most recent version currently available at the time of writing. Create a stored procedure that uses the OPENJSON() function along with an NVARCHAR(MAX) local variable as part of a cursor declaration. Here is one example:
CREATE OR ALTER PROCEDURE TestMemoryLeak_1
AS
BEGIN
SET NOCOUNT ON;
DECLARE @json NVARCHAR(MAX);
SET @json = N'[
{
"Order": {
"Number": "SO43659",
"Date": "2024-05-31T00:00:00"
},
"AccountNumber": "AW29825",
"Item": {
"Price": 2024.9940,
"Quantity": 1
}
},
{
"Order": {
"Number": "SO43661",
"Date": "2024-06-01T00:00:00"
},
"AccountNumber": "AW73565",
"Item": {
"Price": 2024.9940,
"Quantity": 3
}
}
]';
DECLARE json_cursor CURSOR FAST_FORWARD FOR
SELECT Number, OrderDate, Customer, Quantity
FROM OPENJSON(@json) WITH (
Number VARCHAR(200) '$.Order.Number',
OrderDate DATETIME '$.Order.Date',
Customer VARCHAR(200) '$.AccountNumber',
Quantity INT '$.Item.Quantity'
);
DECLARE
@Number VARCHAR(200),
@OrderDate DATETIME,
@Customer VARCHAR(200),
@Quantity INT;
OPEN json_cursor;
FETCH NEXT FROM json_cursor INTO @Number, @OrderDate, @Customer, @Quantity;
WHILE @@FETCH_STATUS = 0
BEGIN
-- nobody wants to work anymore
FETCH NEXT FROM json_cursor INTO @Number, @OrderDate, @Customer, @Quantity;
END;
CLOSE json_cursor;
DEALLOCATE json_cursor;
RETURN;
END;
GO
The amount of memory cached for the cursor execution can be seen with the following code:
DECLARE @plan_handle varbinary(64);
SELECT @plan_handle = plan_handle
FROM sys.dm_exec_procedure_stats
where object_id = object_id('[TestMemoryLeak_1]');
SELECT * FROM
sys.dm_os_memory_objects
WHERE type = 'MEMOBJ_CURSOREXEC'
AND memory_object_address IN (
SELECT memory_object_address
FROM sys.dm_exec_cached_plan_dependent_objects(@plan_handle)
);
I executed the test stored procedure 1 time, measured the memory usage, then executed it 9999 more times, and finally measured the memory usage again. I expected the memory usage to not change because the cursor always processes the same data. SQL Server betrayed my expectations:

A cursor that processes 2 rows of data has managed to use 163 MB of cached memory. Wonderful. One workaround is to remove OPENJSON() from the cursor definition by inserting the data into a table variable and making the cursor read from the table variable:
DECLARE @json_table TABLE (
Number VARCHAR(200) NULL,
OrderDate DATETIME NULL,
Customer VARCHAR(200) NULL,
Quantity INT NULL
);
INSERT INTO @json_table (Number, OrderDate, Customer, Quantity)
SELECT Number, OrderDate, Customer, Quantity
FROM OPENJSON(@json) WITH (
Number VARCHAR(200) '$.Order.Number',
OrderDate DATETIME '$.Order.Date',
Customer VARCHAR(200) '$.AccountNumber',
Quantity INT '$.Item.Quantity'
);
DECLARE json_cursor CURSOR FAST_FORWARD FOR
SELECT Number, OrderDate, Customer, Quantity
FROM @json_table;
SQL Server no longer betrays my expectations. The amount of cached memory for the cursor does not change between 1 and 10000 executions:

Here is a comparison using the sys.dm_exec_cached_plans DMV:

Determining which row is associated with each stored procedure is an exercise left up to the reader.
A second workaround is to define the cursor using the LOCAL argument. A third workaround is to define the local variable as NVARCHAR(4000). Thank you to the comments for both of these workarounds. Note that I originally thought the issue was related to OPENJSON() but it appears that was an error on my part. The presence of an LOB variable looks to be the determining factor.
Final Thoughts
Using local LOB variables as part of a cursor declaration can lead to ever-increasing amounts of cached memory associated with its cached plan. It’s possible that SQL Server will prune this plan once it experiences plan cache pressure, but it may also choose to prune other plans instead. I recommend coding defensively by always using the LOCAL argument for your cursor declarations. Thanks for reading!