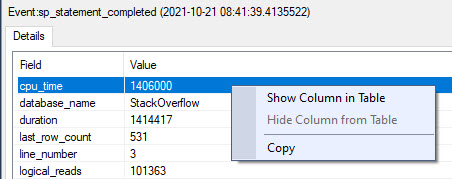
sp_WhoIsActive is probably one of the most famous utilities in SQL Server. To the point where when I see people using sp_who – sp_who4762, I immediately disqualify their ability as a DBA.
If you think that’s unfair, it’s probably because you use sp_who2.
But anyway, with Mr. Machanic being busy with outside of SQL Server projects, the script hadn’t been getting much attention lately. Since I had been working on a couple issues, and saw other piling up, I offered to help with Adam’s project in the same way I help with the First Responder Kit stuff.
hired
I’ll be working on issues over there to get new stuff and bug fixes into the script. If there’s anything you’d like to see in there, or see fixed, let us know!
Help You
If you’re hitting an issue with the script and you want to do some investigating, here’s what I suggest doing.
Run that along with any of the other parameters you’re using, and click on the sql_text column, that’ll give you the whole query that WhoIsActive runs. Paste that into a new SSMS window, and get rid of the XML artifacts like <?query -- and --?>.
After that, you’ll have to declare a few variables to make things run correctly:
After that, you can hit F5 and it’ll run. If your problem is in the main branch of the script that generates all the complicated dynamic SQL, that’ll help you figure out exactly where the problem is.
Thanks!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
This is still one of the most common problems I see in queries.
People are terrified of NULLs. People are afraid to merge on freeways in Los Angeles.
What results is this endless stream of poorly performing queries, and some surprise logic bugs along the way.
I don’t have much more else of an intro. The TL;DR is that you should use natural expressions like IS NULL or IS NOT NULL, rather than any of the built in functions available to you in SQL Server, like ISNULL, COALESCE, et al. which are presentation layer functions with no relational meaning whatsoever.
From here on out, we’ll be calling them unnatural expressions. Perhaps that will get through to you.
Tuning Wizard
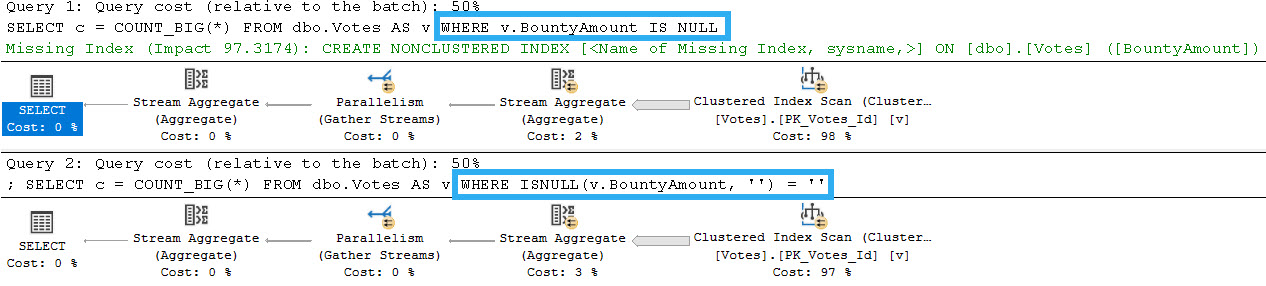
First is something I’ve covered before, but when you use unnatural expressions, the optimizer will not give you feedback about useful indexes.
tenting
The first query generates a missing index request, the second one does not. The optimizer has abandoned all hope with the use of an unnatural expression.
Lethargy
The other issue with unnatural expressions comes down to implicit conversion.
Take this, for instance.
DECLARE
@i int = 0;
SELECT
c =
CASE ISNULL(@i, '')
WHEN ''
THEN 1
ELSE 0
END;
This will return a 1, because 0 and ” can be implicitly converted.
Perhaps less obvious, and more rare, is this:
DECLARE
@d datetime = '19000101';
SELECT
c =
CASE ISNULL(@d, '')
WHEN ''
THEN 1
ELSE 0
END;
Which will also return 1.
Not many databases have stuff going back to 1900, but I do see people using that as a canary value often enough.
Perfidy
If that’s not enough to get you off the idea, let’s look at how this stuff plays out in the real world.
First, let’s get ourselves an index. Without that, there’s fundamentally no difference in performance.
CREATE INDEX v ON dbo.Votes
(BountyAmount);
Our gold standard will be these two queries:
SELECT
c = COUNT_BIG(*)
FROM dbo.Votes AS v
WHERE v.BountyAmount IS NULL;
SELECT
c = COUNT_BIG(*)
FROM dbo.Votes AS v
WHERE v.BountyAmount IS NOT NULL;
The first one that checks for NULL values returns a count of 182,348,084.
The second one that checks for NOT NULL values returns a count of 344,070.
Keep those in mind!
The query plans for them both look like this:
jumbotron
Which run, respectively (and respectably), in 846ms and 26ms. Obviously the query with the more selective predicate will have a time advantage, here.
Wrongly
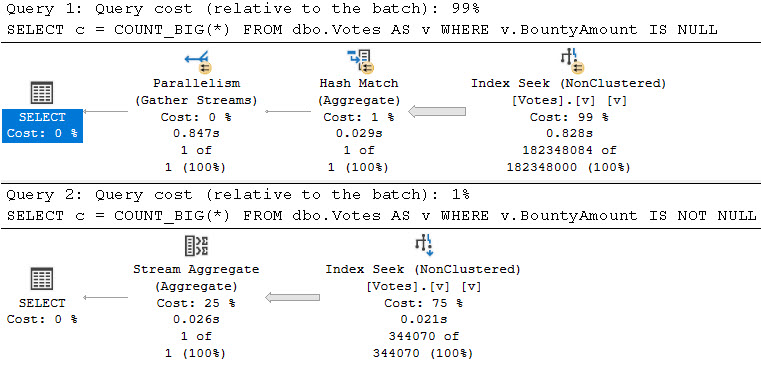
Here’s where things start to go wrong.
This query returns incorrect results, but you’re probably used to that because of all the NOLOCK hints in your queries anyway.
SELECT
c = COUNT_BIG(*)
FROM dbo.Votes AS v
WHERE ISNULL(v.BountyAmount, '') = '';
A count of 182,349,088 is returned rather than 182,348,084, because there are 1004 rows with a bounty of 0.
Even though we have an empty string in our query, it’s implicitly converted to 0.
checked
And you thought you were so clever.
Badly
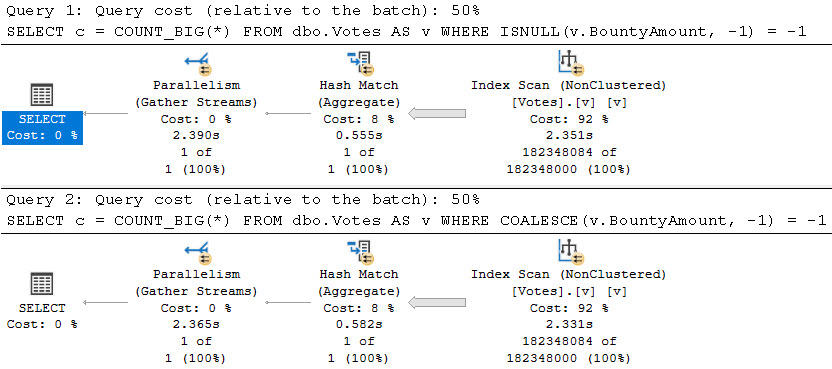
The exercises in futility that I see people carrying on with often look make use of ISNULL, COALESCE, and CASE expressions.
For findings NULLs, people will screw up and do this:
SELECT
c = COUNT_BIG(*)
FROM dbo.Votes AS v
WHERE ISNULL(v.BountyAmount, -1) = -1;
SELECT
c = COUNT_BIG(*)
FROM dbo.Votes AS v
WHERE COALESCE(v.BountyAmount, -1) = -1;
We can use -1 here because it doesn’t naturally occur in the data. Results are correct for both, but performance is comparatively horrible.
up high
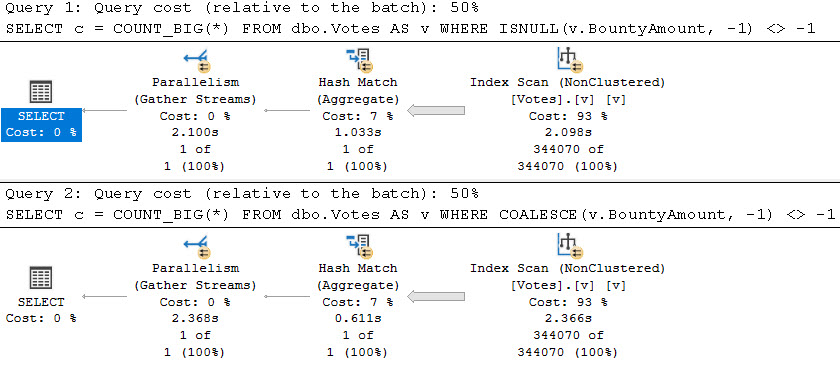
We’re looking at 2.5 seconds compared to 900ms. This situation gets worse with the more selective predicates, too.
down low
These both take roughly the same time as the other unnatural forms of this query, but recall the natural version of this query finished in under 30ms.
Deadly
I hope I don’t have to write about this anymore, but at the rate I see people doing this stuff, I kind of doubt it.
Broken Record Enterprises, it feels like sometimes.
I’m not sure why anyone thinks this is a good idea. I’ve heard rumors that it comes from application developers who are used to NULLs throwing errors writing SQL queries, where they don’t pose the same threat.
Who knows, though. Maybe people just really like the festive pink text color that functions turn in SSMS.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
You’re running a query that selects a lot of columns, and you get a missing index request.
For the sake of brevity, let’s say it’s a query like this:
SELECT
p.*
FROM dbo.Posts AS p
WHERE p.ParentId = 0;
The missing index request I get for this query is about like so:
CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>]
ON [dbo].[Posts] ([ParentId])
INCLUDE ([AcceptedAnswerId],[AnswerCount],[Body],[ClosedDate],[CommentCount],[CommunityOwnedDate],
[CreationDate],[FavoriteCount],[LastActivityDate],[LastEditDate],[LastEditorDisplayName],[LastEditorUserId],
[OwnerUserId],[PostTypeId],[Score],[Tags],[Title],[ViewCount])
But that’s laughable, because it’s essentially a shadow clustered index. It’s every column in the table ordered by <some column>.
And Again
Under many circumstances, you can trim all those included columns off and make sure there’s a usable index with ParentId as the leading column.
But sure, if you have reasonably selective predicates, you’ll get a decent seek + lookup plan. That’s not always going to be the case, though, and for various reasons you may end up getting a poor-enough estimate on a reasonably selective predicate, which will result in a bad-enough plan.
Of course, other times you may not have very selective predicates at all. Take that query up there, for example. There are 17,142,169 rows in the Posts table (2013), and 6,050,820 of them qualify for our predicate on ParentId.
This isn’t a case where I’d go after a filtered index, either, because it’d only be useful for this one query. And it’d still be really wide.
There are four string columns in there, all nvarchar.
Title (250)
Tags (150)
LastEditorDisplayName(40)
Body(max)
Maybe Something Different
If I’m going to create an index like that, I want more out of it than I could get with the one that the optimizer asked for.
On a decently recent version of SQL Server (preferably Enterprise Edition), I’d probably opt for creating a nonclustered column store index here.
You get a lot of benefits from that, which you wouldn’t get from the row store index.
Column independence for searching
High compression ratio
Batch Mode execution
That means you can use the index for better searching on other predicates that aren’t terribly selective, the data source is smaller and less likely to be I/O bound, and batch mode is aces for queries that process a lot of rows.
Column store indexes still have some weird limitations and restrictions. Especially around data types and included columns, I don’t quite understand why there isn’t better parity between clustered and nonclustered column store.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I got a very interesting issue about sp_HumanEvents recently, and I couldn’t quite figure out why things were going wonky.
The problem was that at some point when monitoring blocking long-term, something was taking up a whole lot of tempdb.
I’m gonna say up front that the problem was using a recompile hint with LOB variable assignment in a loop. That doesn’t mean you should avoid any one of those things, but be careful when you use them in concert.
This post wouldn’t be possible without my friends Joe and Paul, who helped me track down the issue and with the internals of it.
Thumper
Rather than make you go through running and causing blocking, the issue is reproduced through this demo:
DECLARE @lob nvarchar(max) = N'x';
DECLARE @x xml = N'<x>' + REPLICATE(@lob, 1024 * 1024) + N'</x>';
DECLARE @loop integer = 0;
DECLARE @t table (x nvarchar(1));
WHILE @loop < 5
BEGIN
INSERT
@t
(
x
)
SELECT
x = @x.value('(./x/text())[1]', 'nvarchar(1)')
OPTION (RECOMPILE);
DELETE @t;
SELECT
ddtsu.internal_objects_alloc_page_count,
ddtsu.internal_objects_dealloc_page_count,
internal_object_reserved_page_count =
(
SELECT
SUM(internal_object_reserved_page_count)
FROM tempdb.sys.dm_db_file_space_usage
)
FROM sys.dm_db_task_space_usage AS ddtsu
WHERE ddtsu.session_id = @@SPID;
SET @loop += 1;
END;
The trick here is to run it with the recompile hint available, and then quoted out.
Jumper
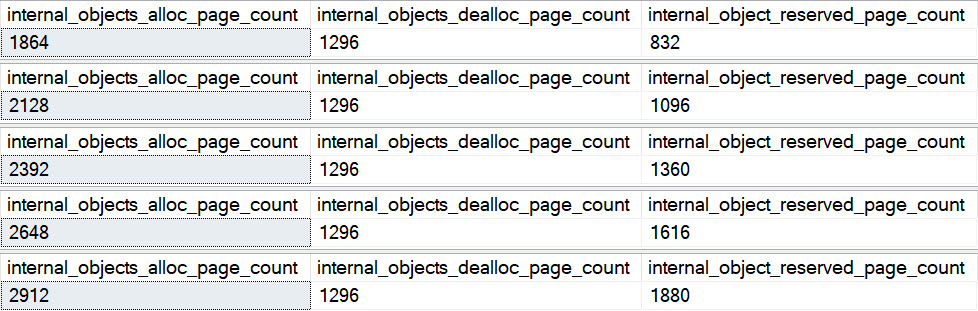
With recompile available, this is the result:
denial
The internal objects keep going up, except the deallocated number. That’s the column in the middle.
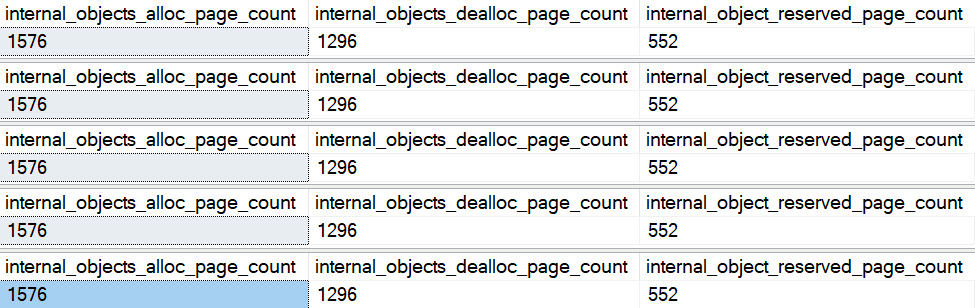
With recompile quoted out, the numbers are a lot different.
When it’s allowed, tempdb objects get cleaned up at the end of the statement.
When it’s not, it gets cleaned up at the end of the batch.
This has been reported to Microsoft for some analysis. Hopefully there’s some remedy for it in the future.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Fixed a bug where date filtering was messing up query results
Enjoy, and as always, please let me know if there’s anything I can do to improve the scripts usability, or any issues you encounter while using them.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
You’ve got a stored procedure that runs slowly, but the problem is that it’s… long. It’s really hard to tell which part is slow, sometimes.
With shorter procedures you can probably just collect actual execution plans and slam F5 like a tall glass of gin at 6am.
But you don’t wanna do that with the larger procedures, for a few practical reasons:
Lots of little queries run quickly, and we don’t care about those
Navigating through lots of plans in SSMS is tedious
There’s no differentiation when other procedures, etc. are invoked
You introduce a lot of overhead retrieving and rendering all those plans
The full query text might not be captured, which is a limitation in many places
Let’s save the day with sp_HumanEvents, my stored procedure that makes using Extended Events really easy.
Wanna Ride
There are a lot of issues you can run into with Extended Events. They’re rather unpleasant, and there’s almost zero guidance from Microsoft about usage.
Wouldn’t it be nice to just hit F5?
Once you have a window open with your procedure ready to run, take note of the session id that it’s using, and tailor this command for your situation:
The events we want to focus on are for executed queries
We only care about queries that run for more than one second
We’re going to focus in on the session id for the query window we’re tuning in
We want the session to stay running so we can watch and re-watch after we make changes
I know it looks a little funny that @session_id is a string, but that’s because there are some sampling capabilities if you want to look at a workload instead of a single procedure without overwhelming a server by collecting everything.
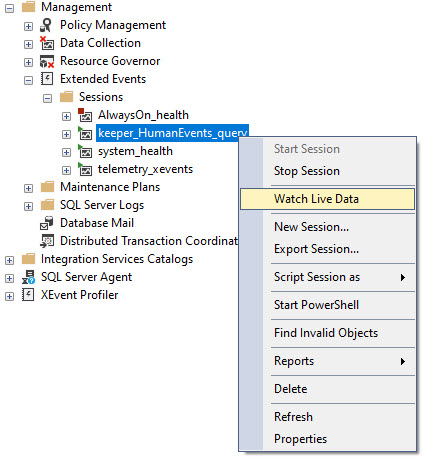
Once that’s done, you’ll have a new Extended Event session like this, and you’ll wanna watch live data from it:
big bux
Watch Out Now
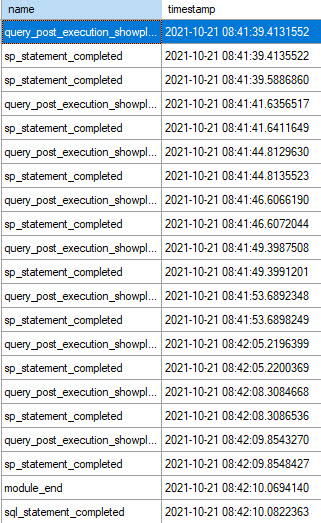
Once you’ve got that window open and you run your procedure, you’ll see any queries that meet the duration criteria, and you should see something that looks like this.
good for you
The procedure that I’m looking at in here is sp_BlitzCache, because it’s a good example of a procedure with a lot of queries in it, where only some of them (like the XML parsing) might get slowed down.
Some notes on the output:
The statement doesn’t get collected with the query plan (more on that in a second)
INSERT…EXEC shows up as two statements (lines 2 and 3 over there)
You only see these two columns at first, but you can go through and add in any other columns that you find useful from each specific session type.
Two Point Two
The output can be a little confusing at first. Generally the pattern is query plan, then statement associated with it.
If you click on each event, you can choose different elements from it to show in the main result window.
like you
Here’s how I usually set things up to find what I wanna go after:
get it
I like to grab CPU, duration, information about requested, granted, and used memory, and the statement.
Not every element is available in every event. Where things are NULL, that’s where they’re not available. I wish there were a general extended event that captured everything I need in one go, but that doesn’t seem to exist.
One last point on the output is that if you click on the query_post_execution_showplan lines, the query plan is available in the second result set:
one time
Crossover
Before you ask, the lightweight profiling events are useless. They’re so nerfed and collect so little helpful detail that you might as well be looking at a cached plan or Query Store plan.
Lightweight, baby 🙄
To that point, I don’t recommend running something like this across a whole workload. Though Extended Events are purported to have far less observer overhead than Profiler, I’ve seen even heavily-filtered sessions like this slow workloads down quite a bit.
Anyway, this is how I work when I’m trying to tune things for clients. Hopefully you find it useful as well.
Grab sp_HumanEvents and lemme know how it goes on GitHub.
Thanks for reading.
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I’d like to start this post off by thanking my co-blogger Joe Obbish for being lazy and not blogging about this when he first ran into it three years ago.
Now that we’re through with pleasantries, let’s talk turkey.
Over in this post, by Arvind Shyamsundar, which I’m sure Microsoft doesn’t consider official documentation since it lacks a GUID in the URL, there’s a list of… things about parallel inserts.
Just as it is with SQL Server 2016, in order to utilize the parallel insert in Azure SQL DB, do ensure that your compatibility level is set to 130. In addition, it is recommended to use a suitable SKU from the Premium service tier to ensure that the I/O and CPU requirements of parallel insert are satisfied.
The usage of any scalar UDFs in the SELECT query will prevent the usage of parallelism. While usage of non-inlined UDFs are in general ‘considered harmful’ they end up actually ‘blocking’ usage of this new feature.
Presence of triggers on the target table and / or indexed views which reference this table will prevent parallel insert.
If the SET ROWCOUNT clause is enabled for the session, then we cannot use parallel insert.
If the OUTPUT clause is specified in the INSERT…SELECT statement to return results to the client, then parallel plans are disabled in general, including INSERTs. If the OUTPUT…INTO clause is specified to insert into another table, then parallelism is used for the primary table, and not used for the target of the OUTPUT…INTO clause.
Parallel INSERT is used only when inserting into a heap without any additional non-clustered indexes. It is also used when inserting into a Columnstore index.
Watch out when IDENTITY or SEQUENCE is present!
In the actual post, some of these points are spread out a bit; I’ve editorially condensed them here. Some of them, like OUTPUT and UDFs, I’ve blogged about a bazillion times over here.
Others may come as a surprise, like well, the rest of them. Hm.
But there’s something missing from here, too!
Lonesome
Let’s create a #temp table, here.
DROP TABLE IF EXISTS
#parallel_insert;
CREATE TABLE
#parallel_insert
(
id int NOT NULL
)
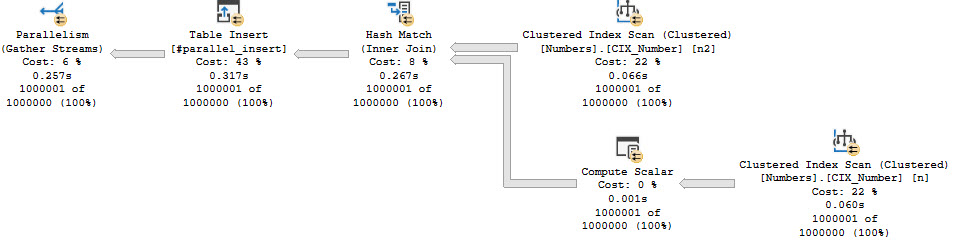
Now let’s look at a parallel insert. I’m using an auxiliary Numbers table for this demo because whatever it’s my demo.
INSERT
#parallel_insert WITH (TABLOCK)
(
id
)
SELECT
n.Number
FROM dbo.Numbers AS n
JOIN dbo.Numbers AS n2
ON n2.Number = n.Number
OPTION
(
USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE')
);
The query plan does exactly what we want it to do, and stays parallel through the insert.
heavy bags
Referential
If we drop and re-create the #temp table, and then run this insert instead, that doesn’t happen:
INSERT
#parallel_insert WITH (TABLOCK)
(
id
)
SELECT
n.Number
FROM dbo.Numbers AS n
JOIN dbo.Numbers AS n2
ON n2.Number = n.Number
AND NOT EXISTS
(
SELECT
1/0
FROM #parallel_insert AS p
WHERE p.id = n.Number
)
OPTION
(
USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE')
);
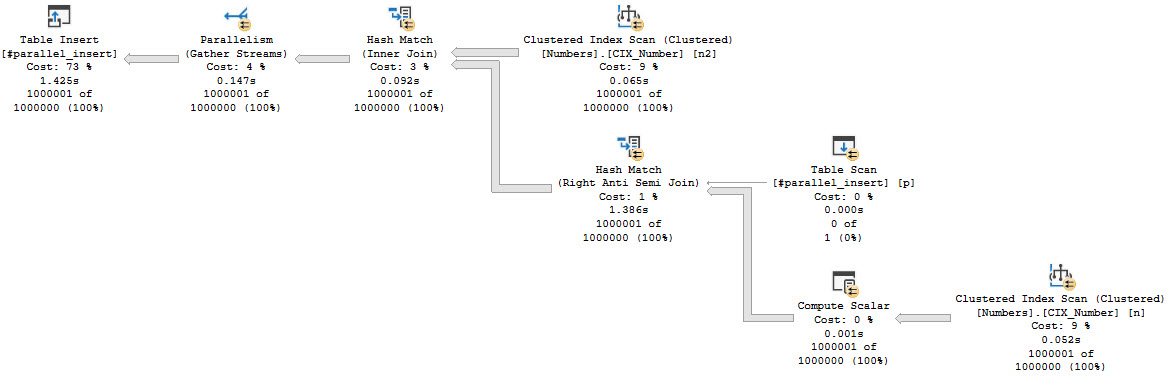
Note that the not exists is against an empty table, and will not eliminate any rows. The optimizer estimates this correctly, and yet…
collect call
The insert is in a fully serial zone. This happens because we reference the table that we’re inserting into in the select portion of the query. It’s no longer just the target for the select to insert into.
Zone Out
If you’re tuning queries like this and hit situations where this limitation kicks in, you may need to use another #temp table to stage rows first.
I’m not complaining about this limitation. I can only imagine how difficult it would be to guarantee correct results in these situations.
I do want to point out that the fully parallel insert finishes in around 250ms, and the serial zone insert finishes in 1.4 seconds. This likely isn’t the most damning thing, but in larger examples the difference can be far more profound.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
In the Stack Overflow database, the biggest (and probably most important) table is Posts.
The Comments table should be truncated hourly. Comments were a mistake.
But the Posts table suffers from a serious design flaw in the public data dump: Questions and Answers are in the same table.
I’ve heard that it’s worse behind the scenes, but I don’t have any additional details on that.
Aspiring Aspirin
This ends up with some weird data distributions. Certain attributes can only ever be “true” for a question or an answer.
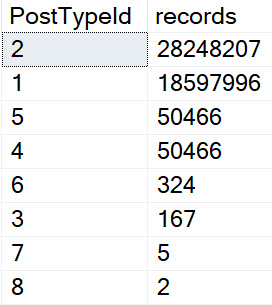
For example, only questions can have a non-zero AcceptedAnswerId, or AnswerCount. Some questions might have a ClosedDate, or a FavoriteCount, too. In the same way, only answers can have a ParentId. This ends up with some really weird patterns in the data.
breezy
Was it easier at first to design things this way? Probably. But introducing skew like this only makes dealing with parameter sniffing issues worse.
Even though questions and answers are the most common types of Posts, they’re not the only types of Posts. Even if you make people specify a type along with other things they’re searching for, you can end up with some really different query plans.
4:44
Designer Drugs
When you’re designing tables, try to keep this sort of stuff in mind. It might not be a big deal for small tables, but once you realize your data is getting big, it might be too late to make the change. It’s not just a matter of changes to the database, but the application, too.
Late stage redesigns often lead to the LET’S JUST REWRITE THE WHOLE APPLICATION FROM THE GROUND UP projects that take years and usually never make it.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
In 2016, we got the STRING_SPLIT function. That was nice, because prior implementations had a lot of problems
But out of the gate, everyone looked at what we got and couldn’t figure why this would drop without a column to tell you the position of each element in the string.
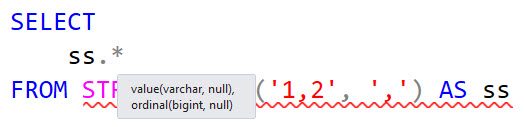
Recently I updated SSMS to 18.10, and went to work on a couple scripts that use STRING_SPLIT.
I was immediately confronted by a bunch of RED SQUIGGLY LINES.
Why?
Not Yet But Soon
Huh.
reminder
Insufficient! You’re insufficient!
stones
Oh, enable_ordinal. Neat.
selected
At least it’s a bigint.
get it
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.