Free Work
Recently I answered a question on Stack Exchange that forced me to read the Microsoft documentation about query parallelism.
When I first read the question, and wrote the answer, I thought for sure that the OP was just misreading things, but no… the documentation was indeed misleading.
And then I had to read more of the documentation, and then I had to write demos to show what I’m talking about.
If you’re on the docs team and you’re reading this, don’t get mad because it’s in a blog post instead of a pull request. I made one of those, too.
Y’all have a lot of work to do, and putting all of this into a pull request or issue would have been dismal for me.
If you want to follow along, you can head to this link.
Constructs
The section with the weirdest errors and omissions is right up at the top. I’m going to post a screenshot of it, because I don’t want the text to appear here in a searchable format.
That might lead people not reading thoroughly to think that I condone any of it, when I don’t.
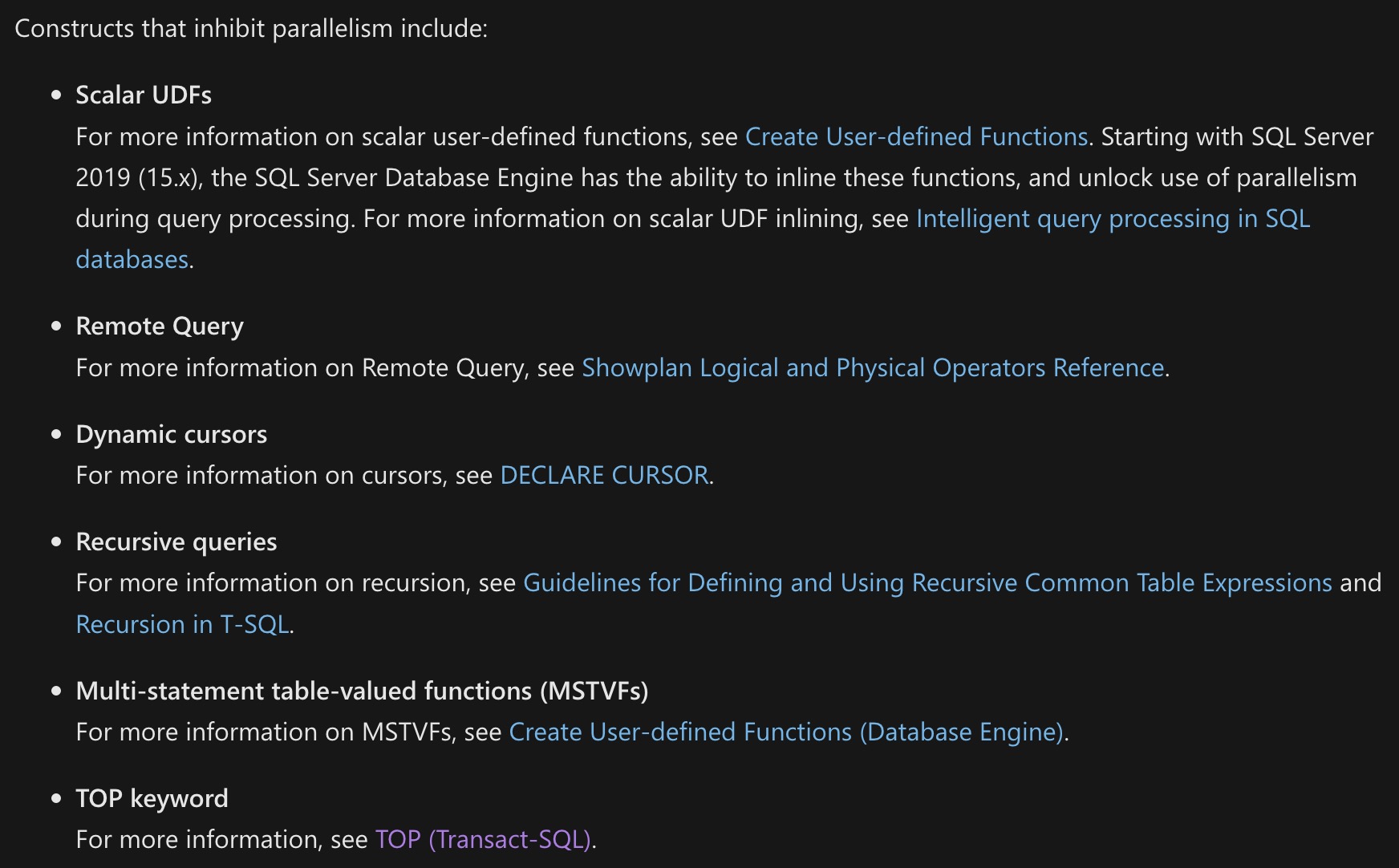
Let’s walk through these one by one.
Scalar UDFs
While it’s true that scalar UDFs that can’t be inlined will force the query that calls them to run single-threaded, the work done inside of the scalar UDF is still eligible for parallelism.
This is important, because anyone looking at query wait stats while troubleshooting might see CX* waits for an execution plan that is forced to run single threaded by a UDF.
Here’s a function written with a Common Table Expression, which prevents UDF inlining from taking place.
CREATE OR ALTER FUNCTION
dbo.AnteUp
(
@UserId int
)
RETURNS integer
WITH SCHEMABINDING
AS
BEGIN
DECLARE
@AnteUp bigint = 0;
WITH
x AS
(
SELECT
p.Score
FROM dbo.Posts AS p
WHERE p.OwnerUserId = @UserId
UNION ALL
SELECT
c.Score
FROM dbo.Comments AS c
WHERE c.UserId = @UserId
)
SELECT
@AnteUp =
SUM(CONVERT(bigint, x.Score))
FROM x AS x;
RETURN @AnteUp;
END;
Getting the estimated execution plan for this query will show us a parallel zone within the function body.
SELECT
u.DisplayName,
TotalScore =
dbo.AnteUp(u.AccountId)
FROM dbo.Users AS u
WHERE u.Reputation >= 500000;
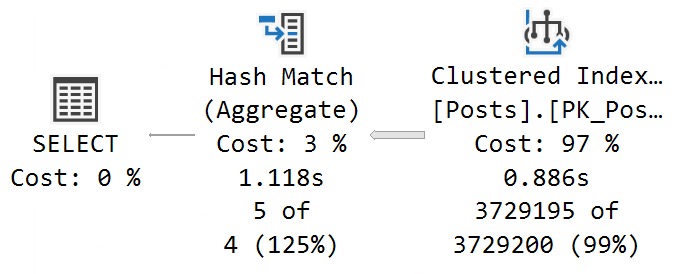
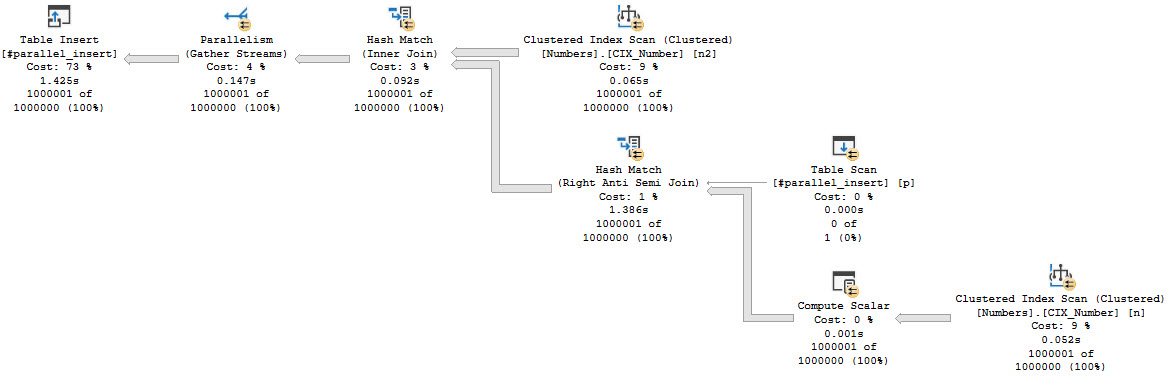
If you get an actual execution plan, you can’t see the work done by the scalar UDF. This is sensible, since the function can’t be inlined, and the UDF would run once per row, which would also return a separate query plan per row.
For functions that suffer many invocations, SSMS may crash.
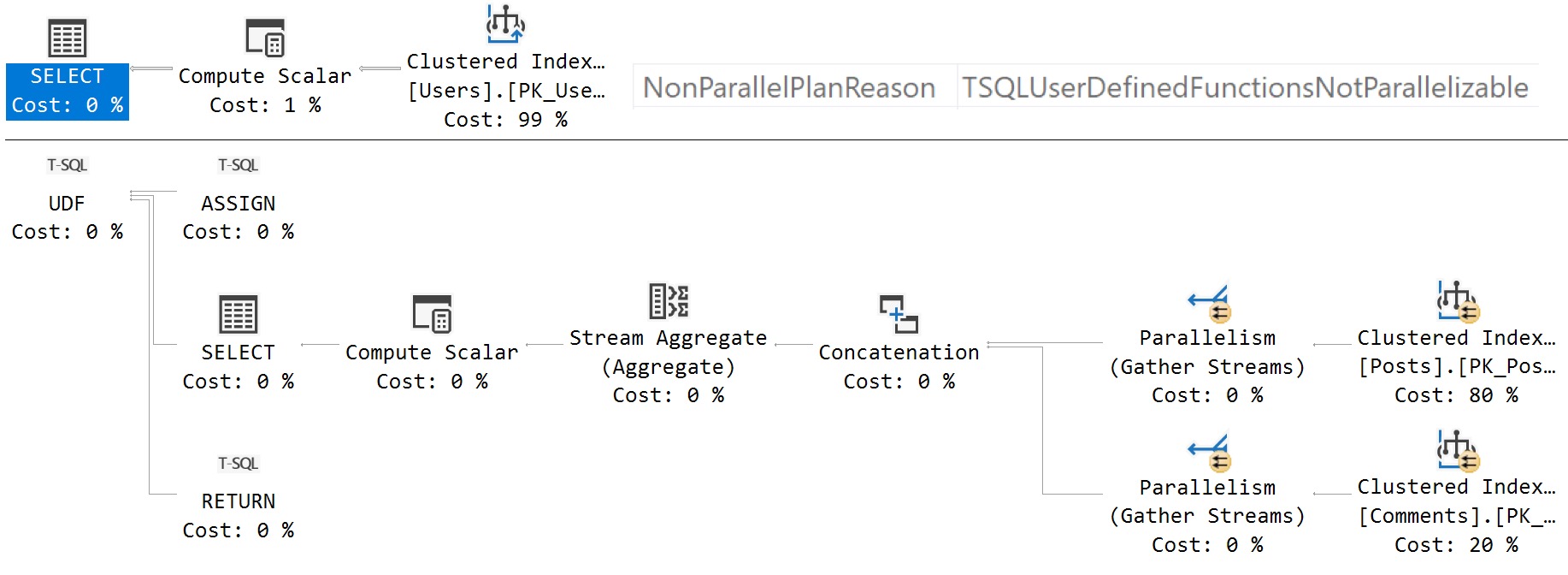
The calling query runs single threaded with a non-parallel execution plan reason, but the body of the function scans both tables that it touches in a parallel zone.
The documentation is quite imprecise in this instance, and many of the others in similar ways.
Remote Queries
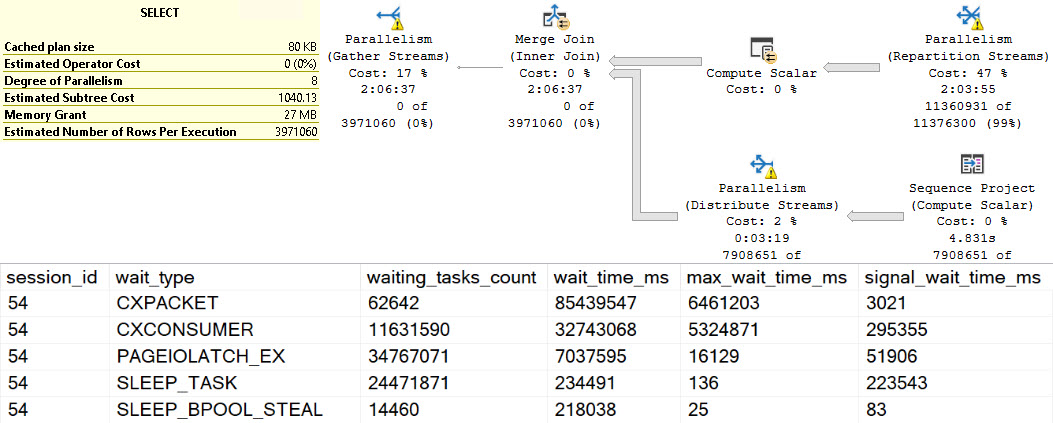
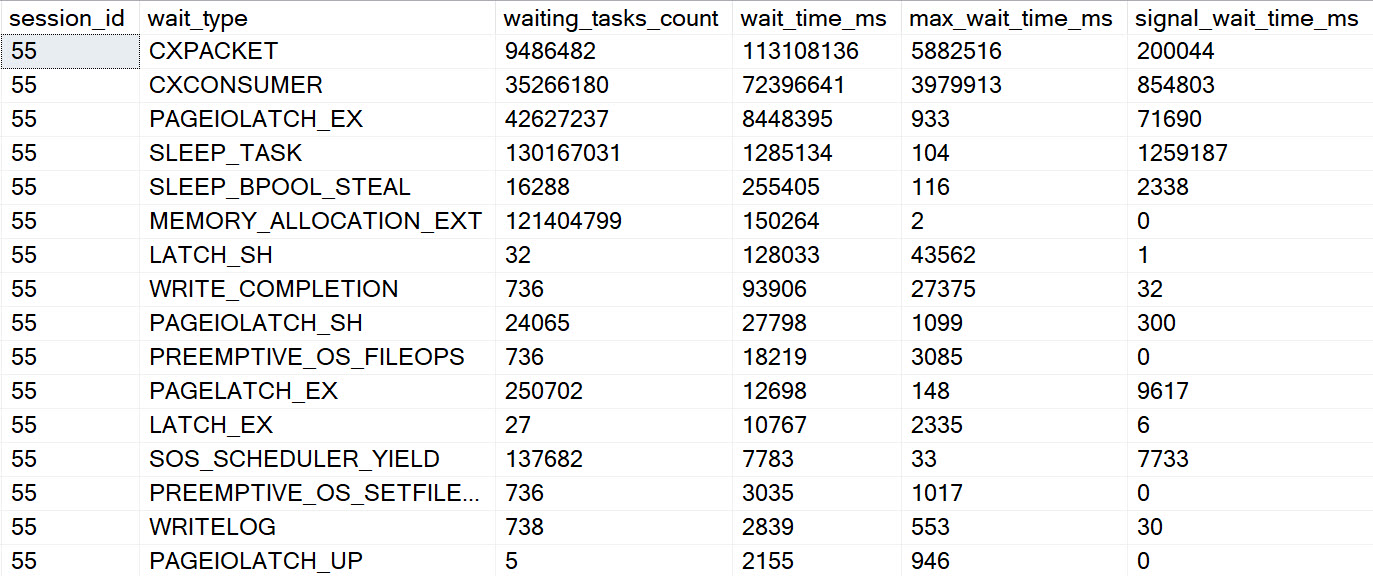
This one is a little tough to prove, and I’ll talk about why, but the parallelism restriction is only on the local side of the query. The portion of the query that executes remotely can use a parallel execution plan.
The reasons why this is hard to prove is that getting the execution plan for the remote side of the query doesn’t seem to be an easy thing to accomplish.
I couldn’t find a cached execution plan for my attempts, nor could I catch the query during execution with a query plan attached to it using the usual methods.
Here’s what I did instead:
- Create a loopback linked server
- Clear wait stats
- Query wait stats
- Run my linked server/openquery query
- Query wait stats again
Here’s the linked server:
DECLARE
@ServerName sysname =
(
SELECT
CONVERT
(
sysname,
SERVERPROPERTY(N'ServerName')
)
);
EXEC sp_addlinkedserver
@server = N'loop',
@srvproduct = N' ',
@provider = N'SQLNCLI',
@datasrc = @ServerName;
GO
Here’s the query stuff:
DBCC SQLPERF('sys.dm_os_wait_stats', CLEAR);
GO
SELECT
dows.wait_type,
dows.waiting_tasks_count,
dows.wait_time_ms,
dows.max_wait_time_ms,
dows.signal_wait_time_ms
FROM sys.dm_os_wait_stats AS dows
WHERE dows.wait_type LIKE N'CX%'
ORDER BY dows.wait_time_ms DESC;
GO
SELECT TOP (1000)
u.Id
FROM loop.StackOverflow2013.dbo.Users AS u
ORDER BY
u.Reputation
GO
SELECT
u.*
FROM
OPENQUERY
(
loop,
N'
SELECT TOP (1000)
u.Id,
u.Reputation
FROM loop.StackOverflow2013.dbo.Users AS u
ORDER BY
u.Reputation;
'
) AS u;
GO
SELECT
dows.wait_type,
dows.waiting_tasks_count,
dows.wait_time_ms,
dows.max_wait_time_ms,
dows.signal_wait_time_ms
FROM sys.dm_os_wait_stats AS dows
WHERE dows.wait_type LIKE N'CX%'
ORDER BY dows.wait_time_ms DESC;
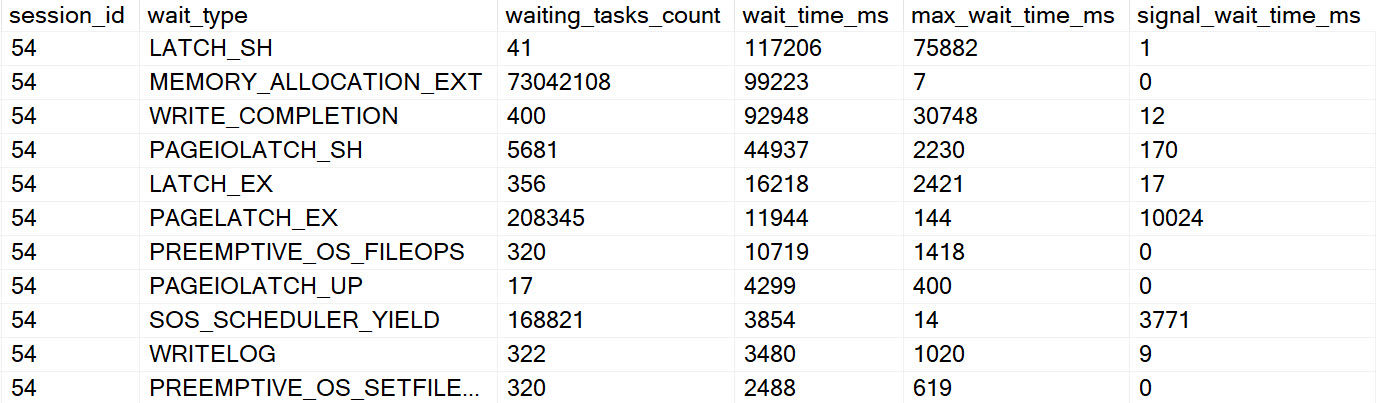
You can quote in/out either the linked server or the OPENQUERY version, but each time a consistent amount of parallel query waits were returned by the second wait stats query.
Given that this is a local instance with no other activity, I’m pretty confident that I’m right here.
Dynamic Cursors
It is true that dynamic cursors will prevent a parallel execution plan, but the documentation leaves out that fast forward cursors will also do that.
That does get noted in the table of non-parallel execution plan reasons decoder ring a little further down, but it’s odd here because only one type of cursor is mentioned, and the cursor documentation itself doesn’t say anything about which cursors inhibit parallelism.
Bit odd since there’s a note that tells you that you can learn more by going there.
DECLARE
ff CURSOR FAST_FORWARD
FOR
SELECT TOP (1)
u.Id
FROM dbo.Users AS u
ORDER BY u.Reputation DESC
OPEN ff;
FETCH NEXT
FROM ff;
CLOSE ff;
DEALLOCATE ff;
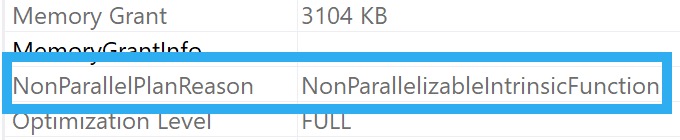
Anyway, this cursor gives us this execution plan:

Which has a non parallel execution plan reason that is wonderfully descriptive.
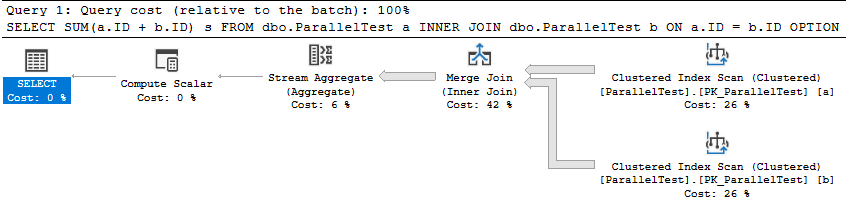
Recursive Queries
This is only partially true. The “recursive” part of the CTE cannot use a parallel execution plan (blame the Stack Spool or something), but work done outside of the recursive common table expression can.
Consider this query, with a recursive CTE, and then an additional join outside of the portion that achieved maximum recursion.
WITH
p AS
(
SELECT
p.Id,
p.ParentId,
p.OwnerUserId,
p.Score
FROM dbo.Posts AS p
WHERE p.Id = 184618
UNION ALL
SELECT
p2.Id,
p2.ParentId,
p2.OwnerUserId,
p2.Score
FROM p
JOIN dbo.Posts AS p2
ON p.Id = p2.ParentId
)
SELECT
p.*,
u.DisplayName,
u.Reputation
FROM p
JOIN dbo.Users AS u
ON u.Id = p.OwnerUserId
ORDER BY p.Id;
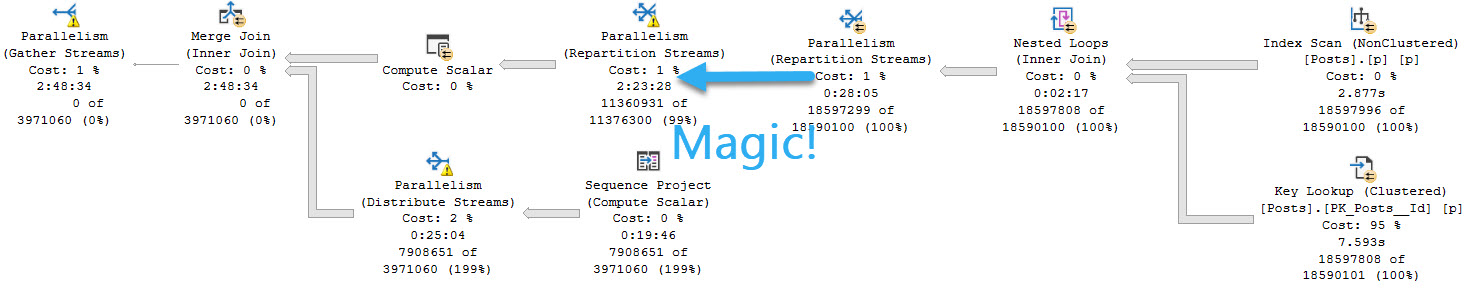
In this execution plan, the join to the Users table is done in a parallel zone after the recursive common table expression “completes”:

These do not force a totally serial execution plan, as the documentation suggests.
Multi-Statement Table Valued Functions
This is another area where the documentation seems to indicate that a completely serial execution plan is forced by invoking a multi-statement table valued function, but they don’t do that either.
They only force a serial zone in the execution plan, both where the table variable is populated, and later returned by the functions. Table variables read from outside of multi-statement table valued functions, and even table variables used elsewhere in the function’s body may be read from in a parallel zone, but the returned table variable does not support that.
Here’s a function:
CREATE OR ALTER FUNCTION
dbo.BadgerJoin
(
@h bigint
)
RETURNS
@Out table
(
UserId int,
BadgeCount bigint
)
AS
BEGIN
INSERT INTO
@Out
(
UserId,
BadgeCount
)
SELECT
b.UserId,
BadgeCount =
COUNT_BIG(*)
FROM dbo.Badges AS b
GROUP BY b.UserId
HAVING COUNT_BIG(*) > @h;
RETURN;
END;
Here’s a query that calls it:
SELECT
u.Id,
o.*
FROM dbo.Users AS u
JOIN dbo.BadgerJoin(0) AS o
ON o.UserId = u.Id
WHERE u.LastAccessDate >= '20180901';
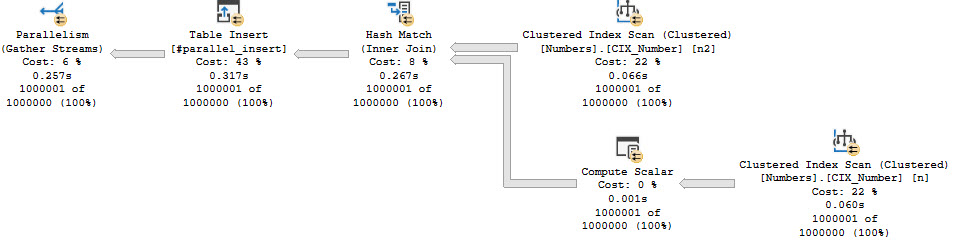
And here’s the query execution plan:
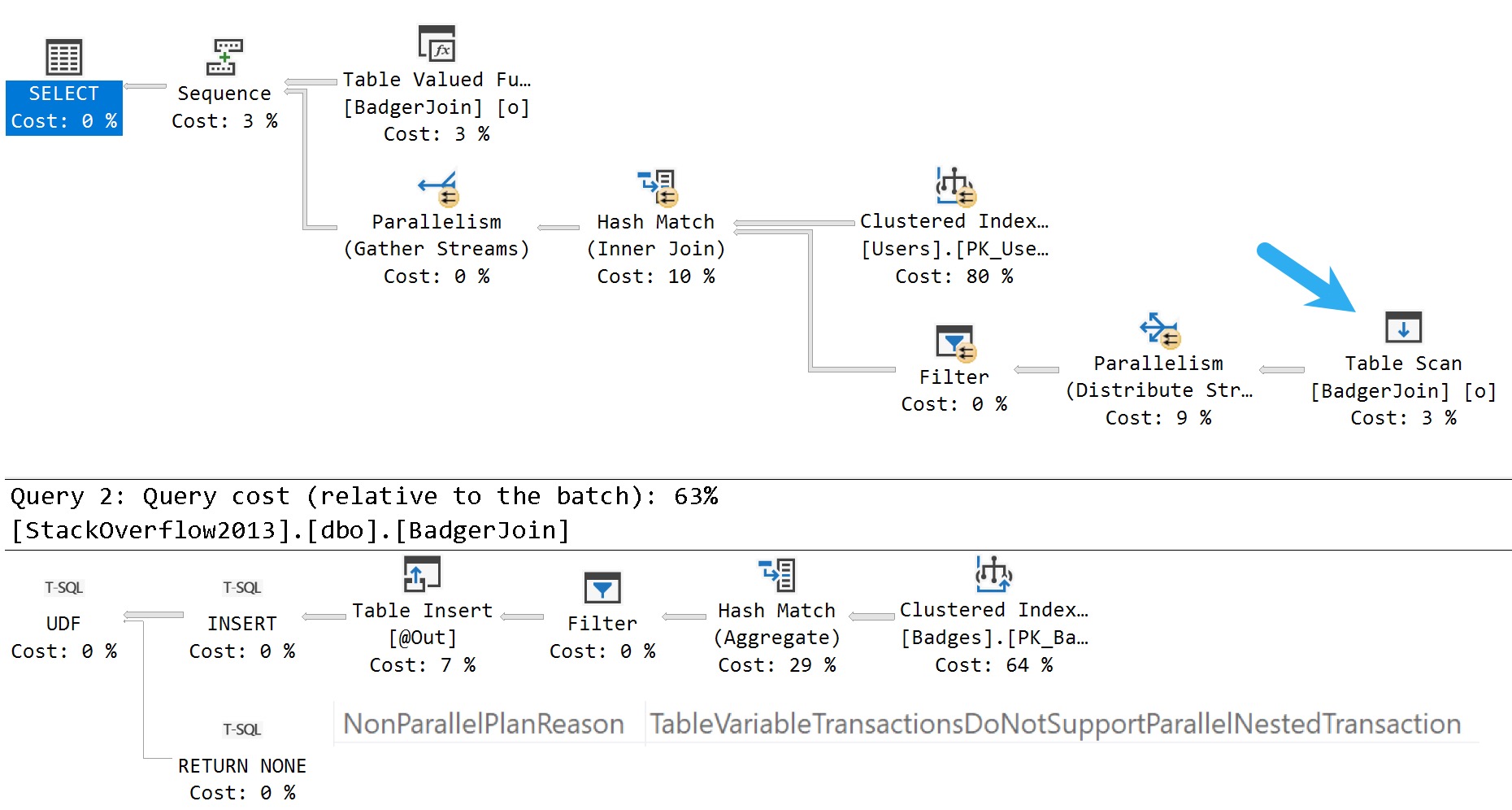
Again, only a serial zone in the execution plan. The table variable modification does force a serial execution plan, but that is more of a side note and somewhat unrelated to the documentation.
Completion is important.
Top
Finally, the TOP operator is documented as causing a serial execution plan, but it’s only the TOP operator that doesn’t support parallelism.
Consider this query:
SELECT
*
FROM
(
SELECT TOP (1)
u.*
FROM dbo.Users AS u
ORDER BY
u.Reputation DESC,
u.Id
) AS u
INNER JOIN
(
SELECT TOP (1)
u.*
FROM dbo.Users AS u
ORDER BY
u.Reputation DESC,
u.Id
) AS u2
ON u.Id = u2.Id
ORDER BY
u.Reputation,
u2.Reputation;
Both of the derived selects happen fully in parallel zones, but there is a gather streams operator prior to each top operator, to end each parallel zone.

It would be a little silly to re-parallelize things after the tops going into the nested loops join, but you probably get the point.
You may see some query execution plans where there is a parallel zone, a gather streams operator, a top operator, and then a distribute streams operator to reinitialize parallelism out in the wild.
This is almost no different than global aggregates which also cause serial zones in query plans. Take this query for example:
SELECT
s = SUM(x.r)
FROM
(
SELECT
r = COUNT(*)
FROM dbo.Users AS u
WHERE u.Age < 18
UNION ALL
SELECT
r = COUNT(*)
FROM dbo.Users AS u
WHERE u.Age IS NULL
) AS x;
Which gives us this query plan, where each count operation (stream aggregate) occurs in a serial zone immediately after gather streams.

But no one’s getting all riled up and shouting that from the docs pages.
Afterthoughts
There are some other areas where the documentation is off, and it’s a shame that Microsoft didn’t choose to link to the series of index build strategy posts that it has had published locally since ~2006 or so.
But hey. It’s not like the internet is forever, especially when it comes to Microsoft content.
- Index Build strategy in SQL Server – Introduction (I)
- Index Build strategy in SQL Server – Introduction (II)
- Index Build strategy in SQL Server – Part 1: offline, serial, no partitioning
- Index Build strategy in SQL Server – Part 2: Offline, Parallel, No Partitioning
- Index Build strategy in SQL Server – Part 2: Offline, Parallel, No Partitioning (Non stats plan (no histogram))
- Index Build strategy in SQL Server – Part 3: Offline Serial/Parallel Partitioning (Aligned partitioned parallel index build)
- Index Build strategy in SQL Server – Part 3: Offline Serial/Parallel Partitioning
- Index Build strategy in SQL Server – Part 4-1: Offline Serial/Parallel Partitioning (Non-aligned partitioned index build)
- Index Build strategy in SQL Server – Part 4-2: Offline Serial/Parallel Partitioning (Non-aligned partitioned index build)
I’ve also submitted a pull request to address other issues in the documentation.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.