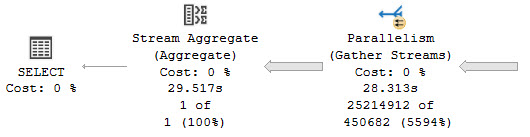Queries that use the AT TIME ZONE operator may perform worse than desired. For example, Jonathan Kehayias blogged about performance struggles with AT TIME ZONE at sqlskills.com. One key difference between Jonathan’s opinion and my own is that I enjoy writing these kinds of posts.
Test Data
The test data consists of one million rows per day over the month of January 2022 for a total of 31 million rows.
DROP TABLE IF EXISTS dbo.CCIForBlog;
CREATE TABLE dbo.CCIForBlog (
SaleTimeUTC DATETIME2 NOT NULL,
WidgetCount BIGINT NOT NULL,
INDEX CCI CLUSTERED COLUMNSTORE
);
GO
SET NOCOUNT ON;
DECLARE
@StartDate DATETIME2 = '20220101',
@DaysToLoad INT = 31,
@DaysLoaded INT = 0;
WHILE @DaysLoaded < @DaysToLoad
BEGIN
INSERT INTO dbo.CCIForBlog (SaleTimeUTC, WidgetCount)
SELECT DATEADD(SECOND, q.RN / 11.5, @StartDate), q.RN / 100000
FROM
(
SELECT TOP (1000000) ROW_NUMBER() OVER (ORDER BY (SELECT NULL))
FROM master..spt_values t1
CROSS JOIN master..spt_values t2
) q (RN)
OPTION (MAXDOP 1);
SET @StartDate = DATEADD(DAY, 1, @StartDate);
SET @DaysLoaded = @DaysLoaded + 1;
END;
CREATE STATISTICS S1 ON CCIForBlog (SaleTimeUTC);
Data is saved to a table with a clustered columnstore index. Of course, this is a small amount of data for a columnstore table. However, it is more than sufficient to demonstrate AT TIME ZONE as a performance bottleneck.
Filtering
Suppose an end user wants a count of widgets sold between January 3rd and January 6th. A first attempt at this query could look like the following:
SELECT SUM(WidgetCount) FROM dbo.CCIForBlog c WHERE c.SaleTimeUTC >= '20220103' AND c.SaleTimeUTC < '20220106' OPTION (MAXDOP 1);
This query plays to all of columnstore’s strengths and it only takes around 10 milliseconds to execute. The data was loaded in date order so most of the rowgroups are eliminated. However, end users don’t think in terms of UTC time. The end user actually wanted Central Standard Time. After a bit of research, the query is changed to as follows:
SELECT SUM(WidgetCount) FROM dbo.CCIForBlog c WHERE SWITCHOFFSET(c.SaleTimeUTC, 0) AT TIME ZONE 'Central Standard Time' >= '20220103' AND SWITCHOFFSET(c.SaleTimeUTC, 0) AT TIME ZONE 'Central Standard Time' < '20220106' OPTION (MAXDOP 1);
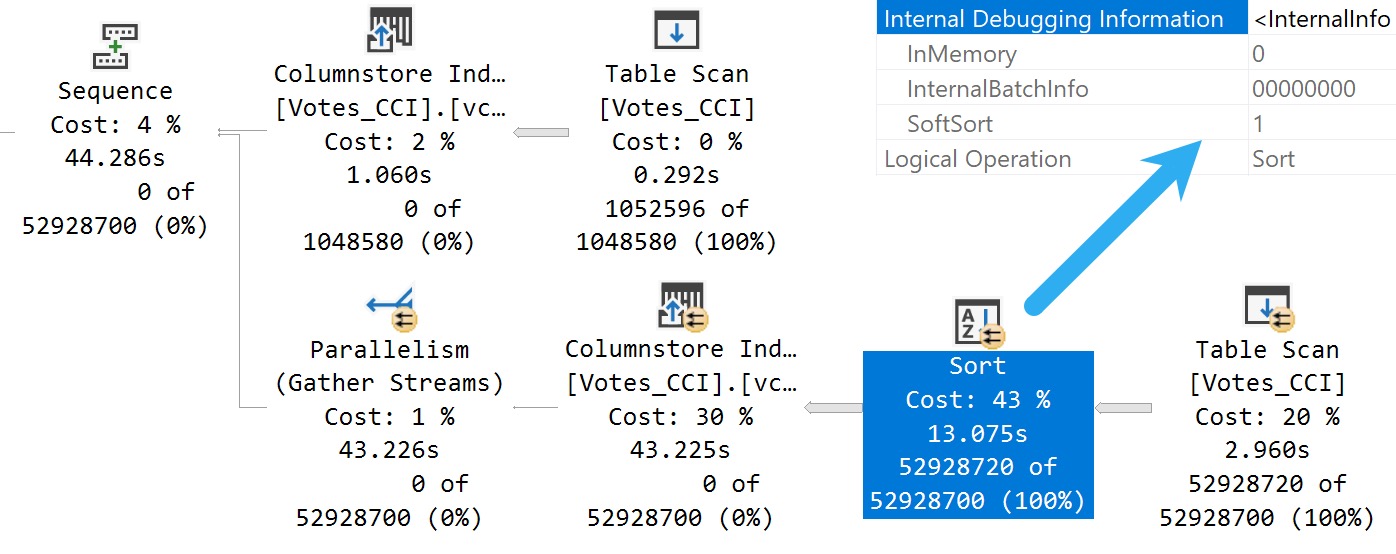
The AT TIME ZONE operator is useful when the number of offset minutes is unknown. UTC always has an offset of 0 so it is better to use SWITCHOFFSET(datetimeoffset_expression, 0)as opposed to AT TIME ZONE ‘UTC’. Even so, the query still takes over 3 minutes to execute on my machine. Nearly all of the execution time is spent on performing AT TIME ZONE calculations:

Note that using c.SaleTimeUTC AT TIME ZONE 'UTC' AT TIME ZONE 'Central Standard Time' would double the execution time.
One idea is to rewrite the filtering so that the time zone conversions are done on the constant values instead of the column:
WHERE c.SaleTimeUTC >= SWITCHOFFSET('20220103' AT TIME ZONE 'Central Standard Time', 0)
AND c.SaleTimeUTC < SWITCHOFFSET('20220106' AT TIME ZONE 'Central Standard Time', 0)
I strongly recommend against this approach. It can lead to wrong results for some time zones and boundary points. Instead, you can use the fact that datetimeoffset only supports an offset of up to +-14 hours. That means that (local – 14 hours) < UTC < (local + 14 hours) is true for any time zone and any point in time. A logically redundant filter can be added to the query:
SELECT SUM(WidgetCount) FROM dbo.CCIForBlog c WHERE SWITCHOFFSET(c.SaleTimeUTC, 0) AT TIME ZONE 'Central Standard Time' >= '20220103' AND SWITCHOFFSET(c.SaleTimeUTC, 0) AT TIME ZONE 'Central Standard Time' < '20220106' AND c.SaleTimeUTC >= DATEADD(HOUR, -14, '20220103') AND c.SaleTimeUTC < DATEADD(HOUR, 14, '20220106') OPTION (MAXDOP 1);
The newly improved query finishes in around 26 seconds. It is able to benefit from rowgroup elimination and performs significantly fewer time zone conversions compared to the original query. In this case, we were able to use knowledge about time zones and a bit of date math to improve performance from over 3 minutes to about 26 seconds.
Grouping
Suppose that an end user wants widget counts summarized by date. A first attempt at this query could look like the following:
SELECT ca.ConvertedDate, SUM(WidgetCount)
FROM dbo.CCIForBlog c
CROSS APPLY (
SELECT CAST(c.SaleTimeUTC AS DATE)
) ca (ConvertedDate)
GROUP BY ca.ConvertedDate
OPTION (MAXDOP 1);
This query takes about 1 second on my machine. However, once again, the end user wants the data to be in CST instead of UTC. The following approach takes around 3 minutes:
SELECT ca.ConvertedDate, SUM(WidgetCount)
FROM dbo.CCIForBlog c
CROSS APPLY (
SELECT CAST(SWITCHOFFSET(c.SaleTimeUTC, 0) AT TIME ZONE 'Central Standard Time' AS DATE)
) ca (ConvertedDate)
GROUP BY ca.ConvertedDate
OPTION (MAXDOP 1);
This should not be a surprise because the bottleneck in query performance is performing 31 million AT TIME ZONE calculations. That doesn’t change if the query performs filtering or grouping.
Historically, governments only perform daylight saving time or offset switches on the minute. For example, an offset won’t change at 2:00:01 AM, but it might change at 2:00:00 AM. The source data has one million rows per day, so grouping the date truncated to the minute, applying the time zone conversion to the truncated distinct values, and finally grouping by date should lead to significant performance improvement. One way to accomplish this:
SELECT ca.ConvertedDate, SUM(SumWidgetCount)
FROM
(
SELECT DATEADD(MINUTE, DATEDIFF(MINUTE, '20000101', c.SaleTimeUTC), '20000101'), SUM(WidgetCount)
FROM dbo.CCIForBlog c
GROUP BY DATEADD(MINUTE, DATEDIFF(MINUTE, '20000101', c.SaleTimeUTC), '20000101')
) q (SaleTimeUTCTrunc, SumWidgetCount)
CROSS APPLY (
SELECT CAST(SWITCHOFFSET(q.SaleTimeUTCTrunc, 0) AT TIME ZONE 'Central Standard Time' AS DATE)
) ca (ConvertedDate)
GROUP BY ca.ConvertedDate
OPTION (MAXDOP 1);
The new query takes around 4 seconds on my machine. It needs to perform 44650 time zone conversions instead of 31 million. Once again, we were able to use knowledge about time zones and a bit of date math to improve performance.
Functioning
I’ve developed and open sourced replacement functions for AT TIME ZONE to provide an easier way of improving performance for queries that use AT TIME ZONE. The TZGetOffsetsDT2 function returns a pair of offsets and the TZFormatDT2 function transforms those offsets into the desired data type. The filtering query can be written as the following:
SELECT SUM(WidgetCount) FROM dbo.CCIForBlog c OUTER APPLY dbo.TZGetOffsetsDT2 (c.SaleTimeUTC, N'UTC', N'Central Standard Time') o CROSS APPLY dbo.TZFormatDT2 (c.SaleTimeUTC, N'UTC', N'Central Standard Time', o.OffsetMinutes, o.TargetOffsetMinutes) f WHERE f.ConvertedDateTime2 >= '20220103' AND f.ConvertedDateTime2 < '20220106' OPTION (MAXDOP 1);
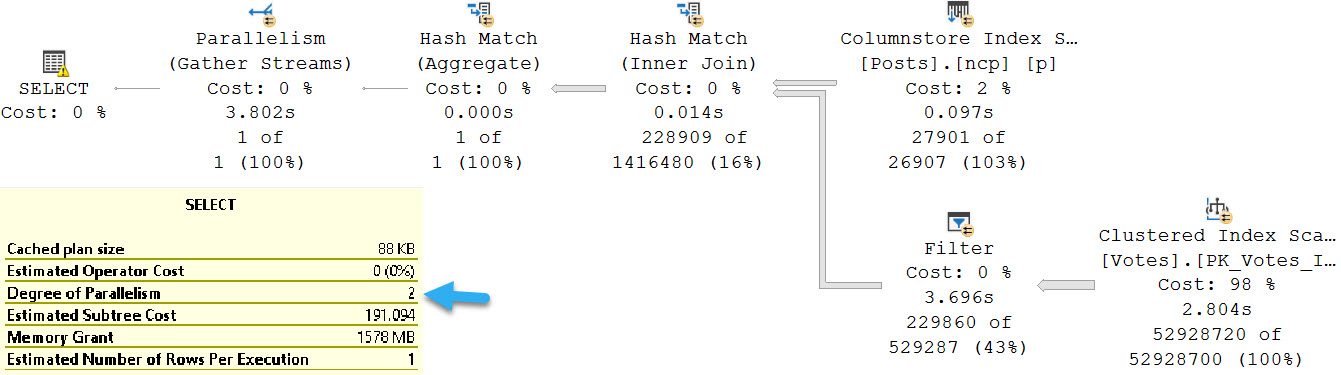
The new query takes around 10 seconds to execute. The new query plan is able to use batch mode processing at every step:
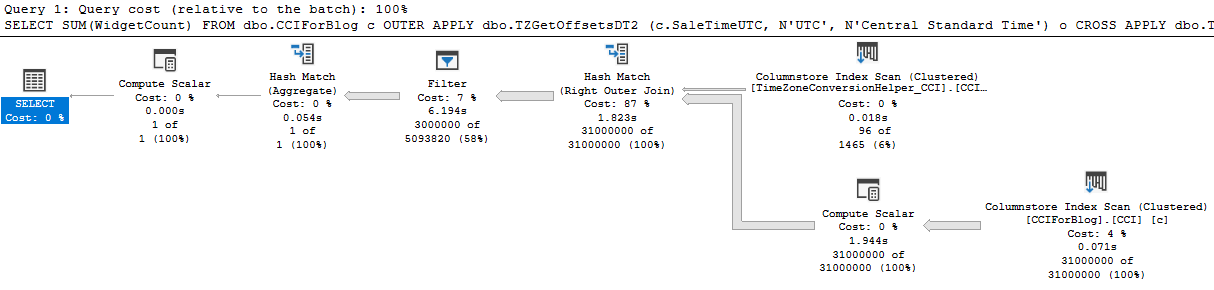
If desired, performance can be further improved by adding the same redundant filters as before:
SELECT SUM(WidgetCount) FROM dbo.CCIForBlog c OUTER APPLY dbo.TZGetOffsetsDT2 (c.SaleTimeUTC, N'UTC', N'Central Standard Time') o CROSS APPLY dbo.TZFormatDT2 (c.SaleTimeUTC, N'UTC', N'Central Standard Time', o.OffsetMinutes, o.TargetOffsetMinutes) f WHERE f.ConvertedDateTime2 >= '20220103' AND f.ConvertedDateTime2 < '20220106' AND c.SaleTimeUTC >= DATEADD(HOUR, -14, '20220103') AND c.SaleTimeUTC < DATEADD(HOUR, 14, '20220106') OPTION (MAXDOP 1);
The most optimized version takes around 1 second to execute. Quite an improvement compared to 3 minutes!
The grouping query can also be rewritten using the new functions:
SELECT f.ConvertedDate, SUM(WidgetCount) FROM dbo.CCIForBlog c OUTER APPLY dbo.TZGetOffsetsDT2 (c.SaleTimeUTC, N'UTC', N'Central Standard Time') o CROSS APPLY dbo.TZFormatDT2 (c.SaleTimeUTC, N'UTC', N'Central Standard Time', o.OffsetMinutes, o.TargetOffsetMinutes) f GROUP BY f.ConvertedDate OPTION (MAXDOP 1);
This version takes about 7 seconds to execute. This is slower than the date truncation method which took 4 seconds but still much faster than the original AT TIME ZONE method.
Unfortunately, SQL Server limitations require a pair of functions to get the best performance. The open source project does provide a simpler function that can be called by itself but it is only eligible for nested loop joins.
Upgrading
SQL Server 2022 RC1 has signs of improvement for AT TIME ZONE. The basic queries that use AT TIME ZONE in this blog post take about 75 seconds to execute on my machine, so it could be estimated that SQL Server 2022 will reduce the CPU footprint of AT TIME ZONE by 60%. Release candidates are not fully optimized so it’s possible that final performance numbers will be different once the product goes GA. I suspect that these performance improvements are already present in Azure SQL Database but I can’t find any documentation for the change.
Final Thoughts
Please try my open source project if you’re experiencing performance problems with AT TIME ZONE. Thanks for reading!