Gateway Drug
Most servers I look at have some level of problems with queries deadlocking with one another. In many cases, they’re read queries deadlocking with write queries, which is easy to resolve using an optimistic isolation level.
My approach to resolving deadlocks is nearly identical to my approach for resolving blocking problems: make the queries go faster to reduce the potential for overlap.
Deadlocks are a result of queries blocking each other, where they’d drag on forever in an unwinnable grudge match. Sometimes this happens just because of bad timing, weird locking hints, using implicit transactions, or application bugs that leave sessions in a sleeping state while holding locks. The fastest queries in the world generally can’t fix those kinds of problems, because they’re going out of their way to do bad things.
But it still comes back to locks being taken and held. Not all blocking leads to deadlocks of course, but the longer you leave locks out there, the higher your chances of running into deadlocks is.
A lot of the time, just figuring out what deadlocks is only half the battle. You’ll also need to diagnose what’s blocking to fully resolve things.
How do you do that?
Blocked Process Report
Turning on the blocked process report is a good starting place. You can do that like so.
EXEC sys.sp_configure
N'show advanced options',
1;
RECONFIGURE;
GO
EXEC sys.sp_configure
N'blocked process threshold',
5; --Seconds
RECONFIGURE;
GO
The only real downside of the blocked process report is that you can’t go below five seconds for the block duration that you have to hit before things are logged.
We’ll talk about other options next, but first! How do you log to the blocked process report now that it’s enabled?
Extended events, my dear friends.
CREATE EVENT SESSION
blocked_process_report
ON SERVER
ADD EVENT
sqlserver.blocked_process_report
ADD TARGET
package0.event_file
(
SET filename = N'bpr'
)
WITH
(
MAX_MEMORY = 4096KB,
EVENT_RETENTION_MODE = ALLOW_SINGLE_EVENT_LOSS,
MAX_DISPATCH_LATENCY = 5 SECONDS,
MAX_EVENT_SIZE = 0KB,
MEMORY_PARTITION_MODE = NONE,
TRACK_CAUSALITY = OFF,
STARTUP_STATE = ON
);
ALTER EVENT SESSION
blocked_process_report
ON SERVER
STATE = START;
GO
To read data from it, you can use my stored procedure sp_HumanEventsBlockViewer.
EXEC dbo.sp_HumanEventsBlockViewer
@session_name = N'blocked_process_report';
That should get you most of the way to figuring out where your blocking problems are.
Logging sp_WhoIsActive
If you want try to catch blocking problems shorter than 5 seconds, one popular way to do that is to log sp_WhoIsActive to a table.
I have a whole set of code to help you do that, too. In that repo, you’ll find:
- A stored procedure that creates a view that will walk the blocking chain
- A stored procedure that logs sp_WhoIsActive to a table, creating a new table for each day
- A script to create an agent job to call do automate the logging
It works pretty well for most use cases, but feel free to tweak it to meet your needs.
Getting To The Deadlocks
The best way known to god, dog, and man to look at deadlocks is to use sp_BlitzLock.
I put a lot of work into a big rewrite of it recently to speed things up and fix a lot of bugs that I noticed over the years.
You can use it to look at the system health extended event session, or to look at a custom extended event session.
CREATE EVENT SESSION
deadlock
ON SERVER
ADD EVENT
sqlserver.xml_deadlock_report
ADD TARGET
package0.event_file
(
SET filename = N'deadlock'
)
WITH
(
MAX_MEMORY = 4096KB,
EVENT_RETENTION_MODE = ALLOW_SINGLE_EVENT_LOSS,
MAX_DISPATCH_LATENCY = 5 SECONDS,
MAX_EVENT_SIZE = 0KB,
MEMORY_PARTITION_MODE = NONE,
TRACK_CAUSALITY = OFF,
STARTUP_STATE = ON
);
GO
ALTER EVENT SESSION
deadlock
ON SERVER
STATE = START;
GO
And then to analyze it:
EXEC dbo.sp_BlitzLock
@EventSessionName = N'deadlock';
Problem Solving
Once you have queries that are blocking and deadlocking, you get to choose your own adventure when it comes to resolving things.
If you need help with that, click the link below to set up a sales call with me. If you’re gonna go it on your own, here are some basic things to check:
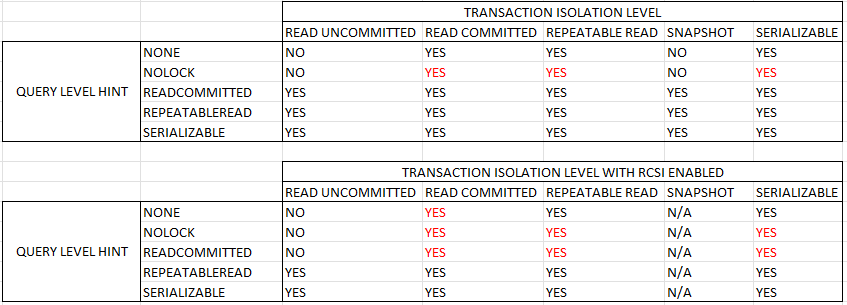
- Isolation levels: are you using repeatable read or serializable without knowing it?
- Do you have the right indexes for your queries to find data quickly?
- Are your queries written in a way to take full advantage of your indexes?
- Do you have any foreign keys or indexed views that are slowing modifications down?
- Are you starting transactions and doing a lot of work before committing them?
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.