Booze Schmooze
As a counterpart to yesterday’s post, I have a list of Great Ideas™ that sometimes it’s hard to get people on board with, for some reason.
Don’t get me wrong, some people can’t jump on this stuff fast enough — I’ve had people take “unscheduled maintenance” during engagements to flip the right switches — but other times there’s a hem and a haw and a whole lot of’em to go along with the plan.
Somehow people who have auto close and Priority Boost turned on and haven’t checked for corruption since 30 Rock went off the air want a full-bore fisking of every change and every assurance that no edge case exists that could ever cross their path.
Okay pal. You go on with your bad 2012 RTM self.
Lock Pages In Memory
“Please don’t pop my balloon animals.”
To say that this setting only lets SQL Server hang onto memory is a grand injustice. It also lets SQL Server use completely different APIs to access memory through Windows, including skipping over virtual memory space. That can be an awesome benefit for servers with gobs of memory.
What are people worried about, here? Usually some article they read about balloon drivers in 2011, or something.
But the same people aren’t afraid to set min server memory to max server memory, and then wonder why they have no plan cache.
I love this setting though, and if you can also get away with turning on trace flag 834, there are some nice additional benefits.
DBCC CHECKDB
“Well, our index maintenance job runs for 9 hours, so we don’t have time for this. Besides, won’t it cause a lot of blocking?”
Lord have mercy, the foot dragging on this. Part of your job as a DBA is to keep data safe and backed up. Running CHECKDB is part of that.
No DBA got fired over fragmented indexes. More than a few have for data going corrupt.
Granted, this can get a little more complicated for really big databases. Some people break it up into different steps, and other people offload the process.
Some third party backup tools from vendors like Quest and Red Gate allow you to automate processes like that, too. Full backup, restore to new server, run CHECKDB, tell us what happened.
How nice, you get a tested restore, too.
Query Store
“Won’t this catch my server on fire and leak PII to hackers?”
If you’re too cheap to spring for a proper monitoring tool, Query Store makes a pretty okay pseudo replacement. Especially in 2017 and up where you can track wait stats too, you can get some pretty good insights out of it.
Microsoft has also gotten pretty smart about better default settings for this thing, and in 2019 you have more knobs to set smarter standards for which plans get tracked in there.
It’d be really nice if you could choose to ignore queries, too, but you know. Can’t always get what you want, there.
I’d much rather look at Query Store than that unreliable old plan cache, too.
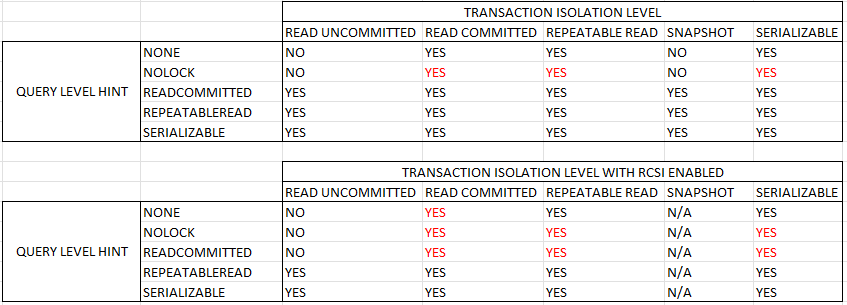
Read Committed Snapshot Isolation
“Why do I want tempdb to be full of old data?”
Remember yesterday? Me either. Nothing good happened, anyway. Do you remember what that row looked like before the update started? No?
Read Committed Snapshot Isolation does. And it wants you to, too. This setting solves so many dumb problems that people run headlong into because Microsoft committed to a garbage isolation level.
One complaint I hear all the time is that a particular application runs a lot better on Oracle with no other changes. This setting is usually the reason why: It’s not turned on.
Once you turn it on, reader/writer blocking and deadlocking goes away, and you don’t need to add a SSMS keyboard shortcut that inserts WITH NOLOCK.
Changing Indexes
“They’re fine the way they are, trust me. That burning smell is another server.”
Index tuning needs to be a process that starts with cleaning up indexes, and ends with adding in better ones.
What makes an index bad? When it’s unused, and/or duplicative.
What makes an index good? When it gets read from more than it’s written to, and it’s a usefully different way for queries to access data.
There are other index anti-patterns that are good to look for too, like lots of single key column indexes, but they usually get cleaned up when you start merging duplicates.
There’s a near fully eclipsed Venn Diagram of people who are worried about having too many indexes and people who have never dropped an index in their career.
Talk, Talk
These are the kinds of changes and processes people should be comfortable with making when they work with SQL Server.
Sure, there are a ton of others, but some of them have become part of the installer and get a little more leeway — parallelism settings, instant file initialization, tempdb etc. — I only wish that more of this stuff would follow suit.
One wonders quite loudly why setting MAXDOP made it into the installer, but setting Cost Threshold For Parallelism did not.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.