We’ve All Been There
You’re running a query that selects a lot of columns, and you get a missing index request.
For the sake of brevity, let’s say it’s a query like this:
SELECT
p.*
FROM dbo.Posts AS p
WHERE p.ParentId = 0;
The missing index request I get for this query is about like so:
CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [dbo].[Posts] ([ParentId]) INCLUDE ([AcceptedAnswerId],[AnswerCount],[Body],[ClosedDate],[CommentCount],[CommunityOwnedDate], [CreationDate],[FavoriteCount],[LastActivityDate],[LastEditDate],[LastEditorDisplayName],[LastEditorUserId], [OwnerUserId],[PostTypeId],[Score],[Tags],[Title],[ViewCount])
But that’s laughable, because it’s essentially a shadow clustered index. It’s every column in the table ordered by <some column>.
And Again
Under many circumstances, you can trim all those included columns off and make sure there’s a usable index with ParentId as the leading column.
I’m not a fan of single key column indexes most of the time, so I’d avoid that practice.
But sure, if you have reasonably selective predicates, you’ll get a decent seek + lookup plan. That’s not always going to be the case, though, and for various reasons you may end up getting a poor-enough estimate on a reasonably selective predicate, which will result in a bad-enough plan.
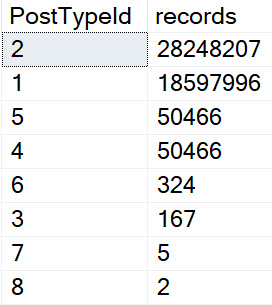
Of course, other times you may not have very selective predicates at all. Take that query up there, for example. There are 17,142,169 rows in the Posts table (2013), and 6,050,820 of them qualify for our predicate on ParentId.
This isn’t a case where I’d go after a filtered index, either, because it’d only be useful for this one query. And it’d still be really wide.
There are four string columns in there, all nvarchar.
- Title (250)
- Tags (150)
- LastEditorDisplayName(40)
- Body(max)
Maybe Something Different
If I’m going to create an index like that, I want more out of it than I could get with the one that the optimizer asked for.
On a decently recent version of SQL Server (preferably Enterprise Edition), I’d probably opt for creating a nonclustered column store index here.
You get a lot of benefits from that, which you wouldn’t get from the row store index.
- Column independence for searching
- High compression ratio
- Batch Mode execution
That means you can use the index for better searching on other predicates that aren’t terribly selective, the data source is smaller and less likely to be I/O bound, and batch mode is aces for queries that process a lot of rows.
Column store indexes still have some weird limitations and restrictions. Especially around data types and included columns, I don’t quite understand why there isn’t better parity between clustered and nonclustered column store.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.