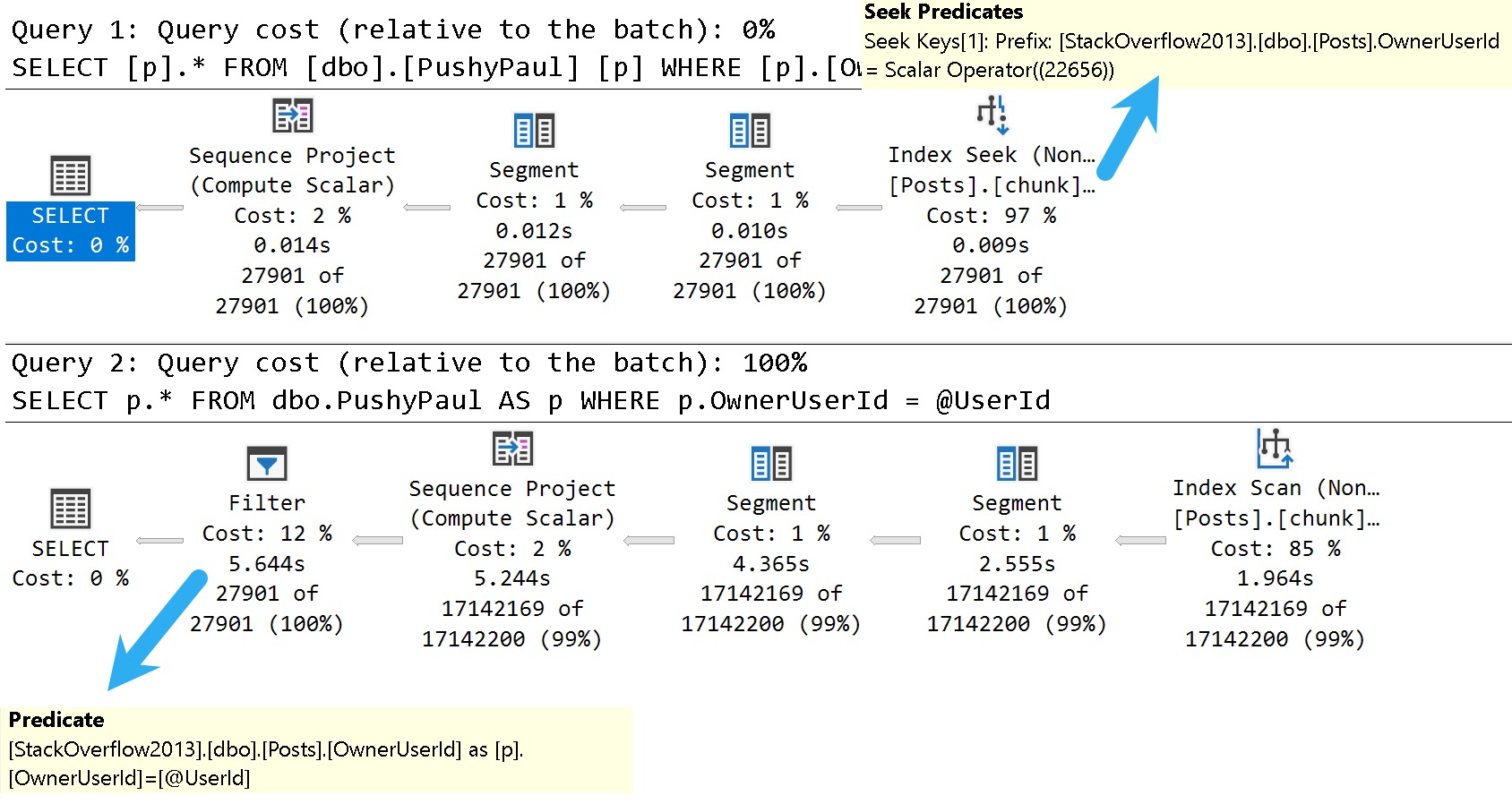
Basically
I get this question a lot while working with clients, largely in a couple specific contexts:
- Me telling someone they need to use dynamic SQL in a stored procedure
- Applications sending over parameterized SQL statements that are executed with sp_executesql
Often, the dynamic SQL recommendation comes from needing to deal with:
- IF branching
- Parameter sensitivity
- Optional parameters
- Local variables
Even in the context of a stored procedure, these things can really suck performance down to a sad nub.
But The Code
Now, much of the SQL generated by ORMs terrifies me.
Even when it’s developer misuse, and not the fault of the ORM, it can be difficult to convince those perfect angels that the query their code generated is submaximal.
Now, look, simple queries do fine with an ORM (usually). Provided you’re:
- Paying attention to indexes
- Not using long IN clauses
- Strongly typing parameters
- Avoiding AddWithValues
You can skate by with your basic CRUD stuffs. I get worried as soon as someone looks at an ORM query and says “oh, that’s a report…” because there’s no way you’re generating reasonable reporting queries with an ORM.
Procedural Drama
The real upside of stored procedures isn’t stuff like plan reuse or caching or 1:1 better performance. A single parameterized query run in either context will perform the same, all things considered.
Where they shine is with additional flexibility in tuning things. Rather than one huge query that the optimizer has to deal with, you can split things up into more manageable chunks.
You also have quite a bit more freedom with various hints, trace flags, query rewrites, isolation levels, etc.
In other words: eventually your query needs will outgrow your ORMs ability to generate optimal queries.
Until then, use whatever you’re able to get your job done with.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.