Relics
When I’m tuning queries, people will often ask me what metrics I look at to judge efficiency. Usually, it’s just getting things to be done faster.
Sometimes it’s okay to use more CPU via a parallel plan to get your query faster. Sometimes it’s okay to do more reads to get a query faster.
Sure, it’s cool when it works out that you can reduce resources overall, but every query is special. It all sort of depends on where the bottleneck is.
One thing I’ve been asked about several times is about how important it is to clear out the plan cache and drop clean buffers between runs.
While this post is only about the dropping of cleanly buffers, let’s touch on clearing the plan cache in some way quickly.
Dusted
Clearing out the plan cache (or recompiling, or whatever) is rarely an effective query tuning mechanism, unless you’re working on a parameter sniffing issue, or trying to prove that something else about a query is causing a problem. Maybe it’s local variables, maybe it’s a bad estimate from a table variable.
You get the point.
But starting with a new plan every time is overblown — if you change things like indexes or the way the query is written, you’re gonna get a new plan anyway.
If you’re worried about long compile times, you might also want to do this to prove it’s not necessarily the query that’s slow.
Busted
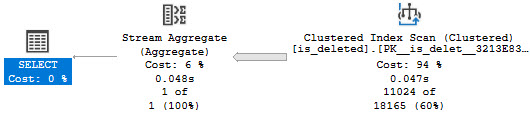
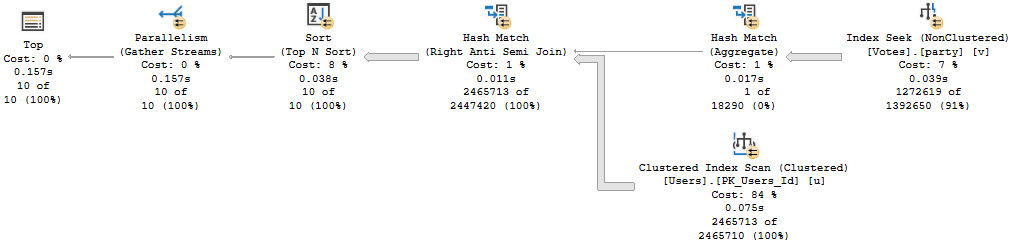
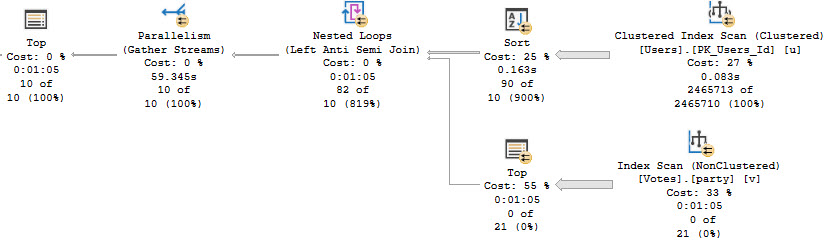
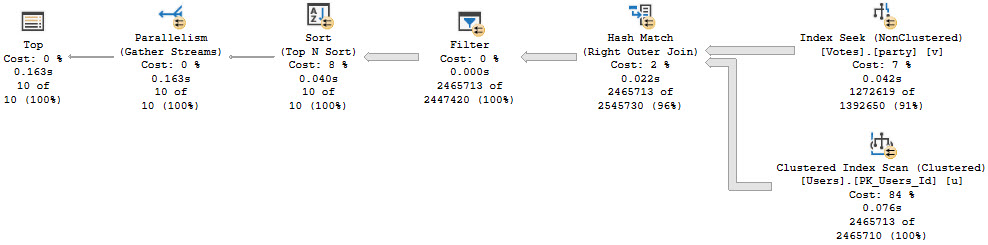
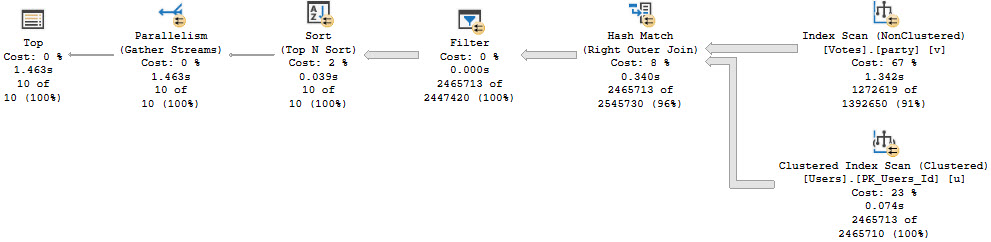
Let’s look at a big picture. The script that generates this picture is as follow:
--Calgon
DBCC DROPCLEANBUFFERS;
--o boy
SELECT
COUNT_BIG(*) AS records
FROM dbo.Posts AS p;
--table manners
SELECT
COUNT_BIG(*) AS records
FROM dbo.Posts AS p;
--so considerate
CREATE INDEX p ON dbo.Posts(Id);
--y tho?
DBCC DROPCLEANBUFFERS;
--woah woah woah
SELECT
COUNT_BIG(*) AS records
FROM dbo.Posts AS p;
--hey handsome
SELECT
COUNT_BIG(*) AS records
FROM dbo.Posts AS p;
We’re gonna drop them buffferinos, run the same count query twice, add a real narrow index, then count twice again.
Great. Great. Great.

Annalieses
For the first two executions, we performance tuned the query by about 30 seconds, just by… reading data from memory.
Hm. Okay. Unless you’re trying to prove that you don’t have enough memory, or that storage sucks, you’re not really convincing me of much.
Yes, RAM is faster than disk. Now what?
For the second two executions, query performance got way better. But reading the smaller index from disk hardly changed overall execution time.
If it’s not a strong enough argument that getting a query from 14 seconds down to half a second with a better index means you need an index, you might be working for difficult people.
Of course, Size Matters™

The second query finishes much faster because we have a much smaller amount of data to read, period. If we had a where clause that allowed our index to seek to a specific chunk of data, we could have done even less work. This shouldn’t surprise anyone, though. Reading 450MB is faster than reading 120,561MB.
This is not a math test.
Coasting
Starting queries out with an empty buffer pool doesn’t really offer any insights into if you’ve tuned the query. It only exaggerates a difference that is usually not a reality.
It is a useful tool if you want to prove that:
- You need more memory
- You need better storage
- You need a different index
But I sure wouldn’t use it to prove that I made a query better.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.