No, Not More DMVs
Though I would be cool with new ones, as long as they’re not memes.
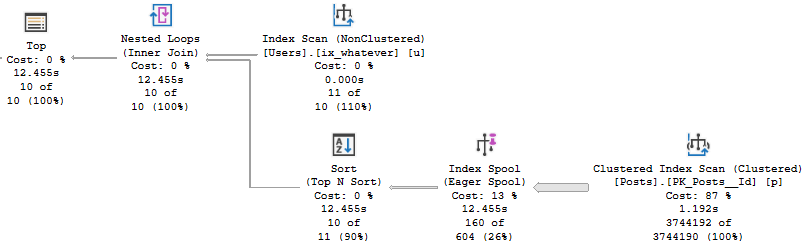
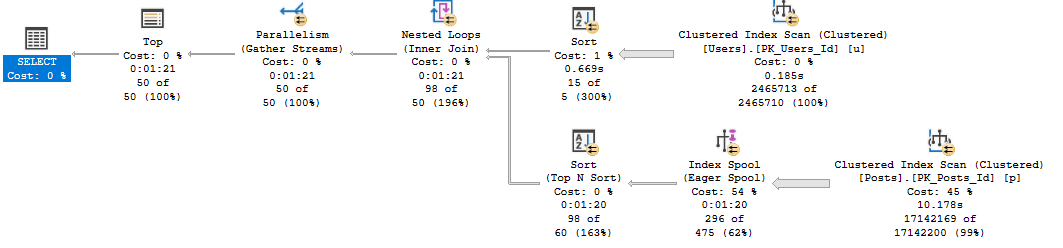
When you’re trying to gauge some high level performance metrics on a new server, you probably have your favorite scripts.
They could be various Blitzes, they could be some stuff you’ve had sitting in your script folder, maybe they’re from the Tiger Toolbox.
Whatever.
The point is that you, dear reader, are smart and engaged enough to know about and use these things.
A lot of people aren’t.
I’m not talking about another thing to go find and install. I mean these should come with the product.
Perf Schema
It would be really cool if SQL Server had a system schema called perf. In there you could have views to all sorts of neat things.
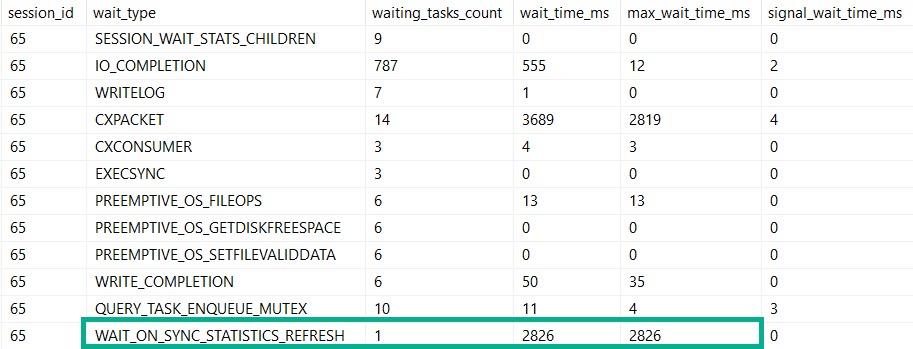
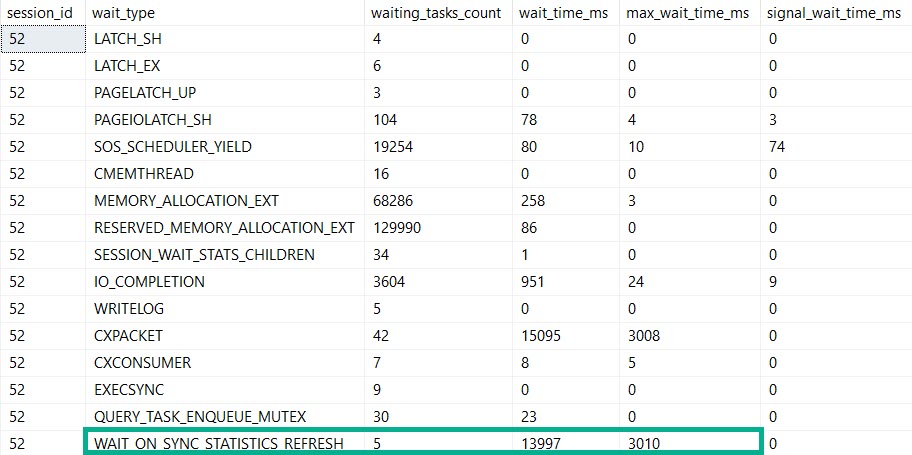
It would exist in every database, and it would have views in it to fully assemble the mess of DMVs that accompany:
- Query Store
- Plan Cache
- Index Usage
- Missing Indexes
- File Stats
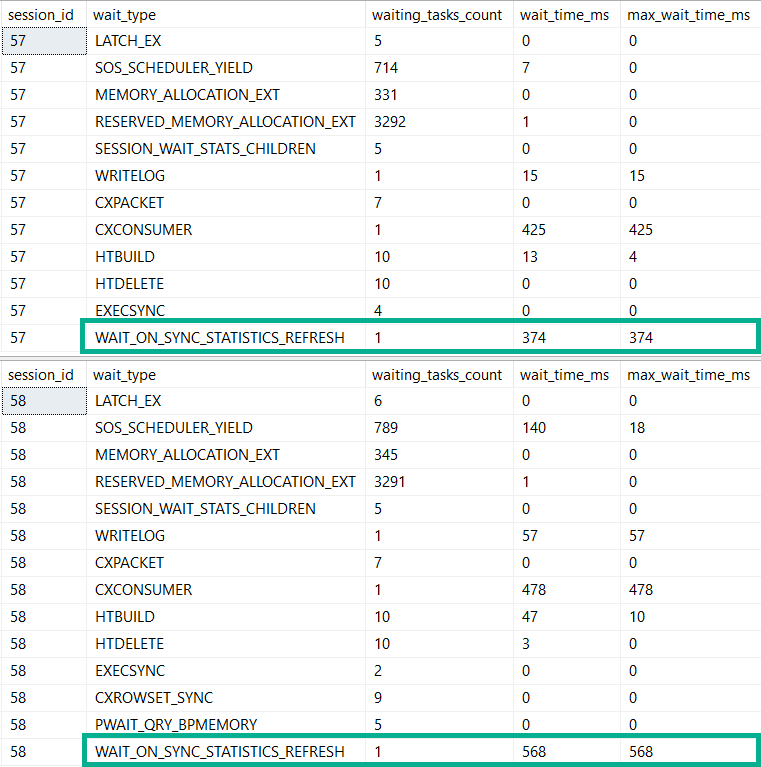
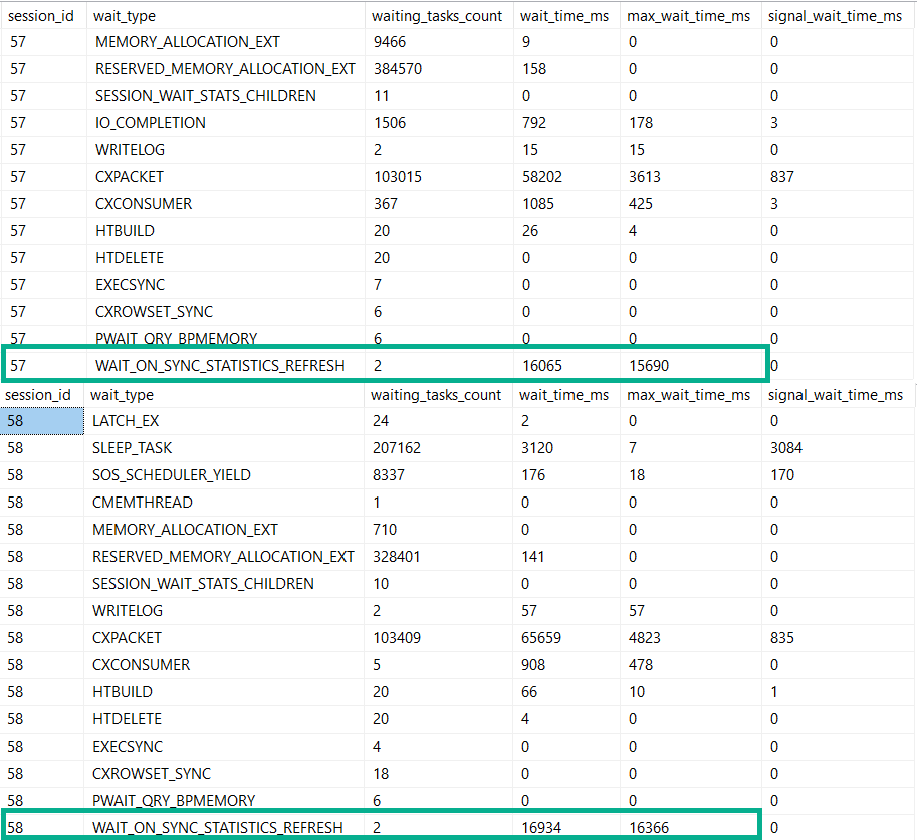
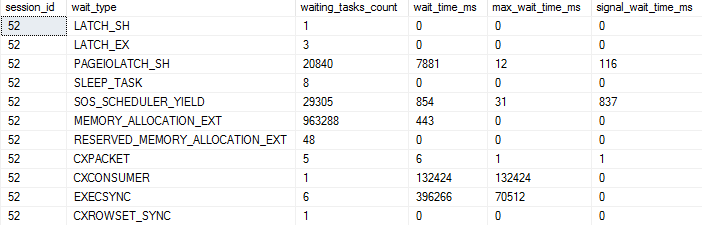
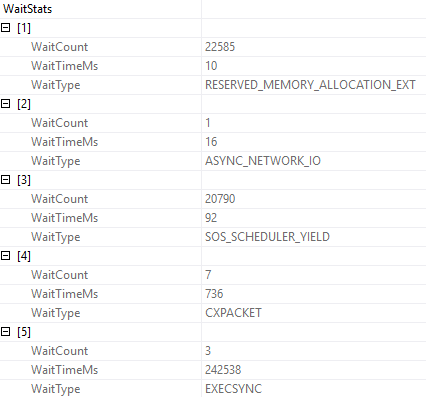
- Wait Stats
- Locking
- Deadlocks
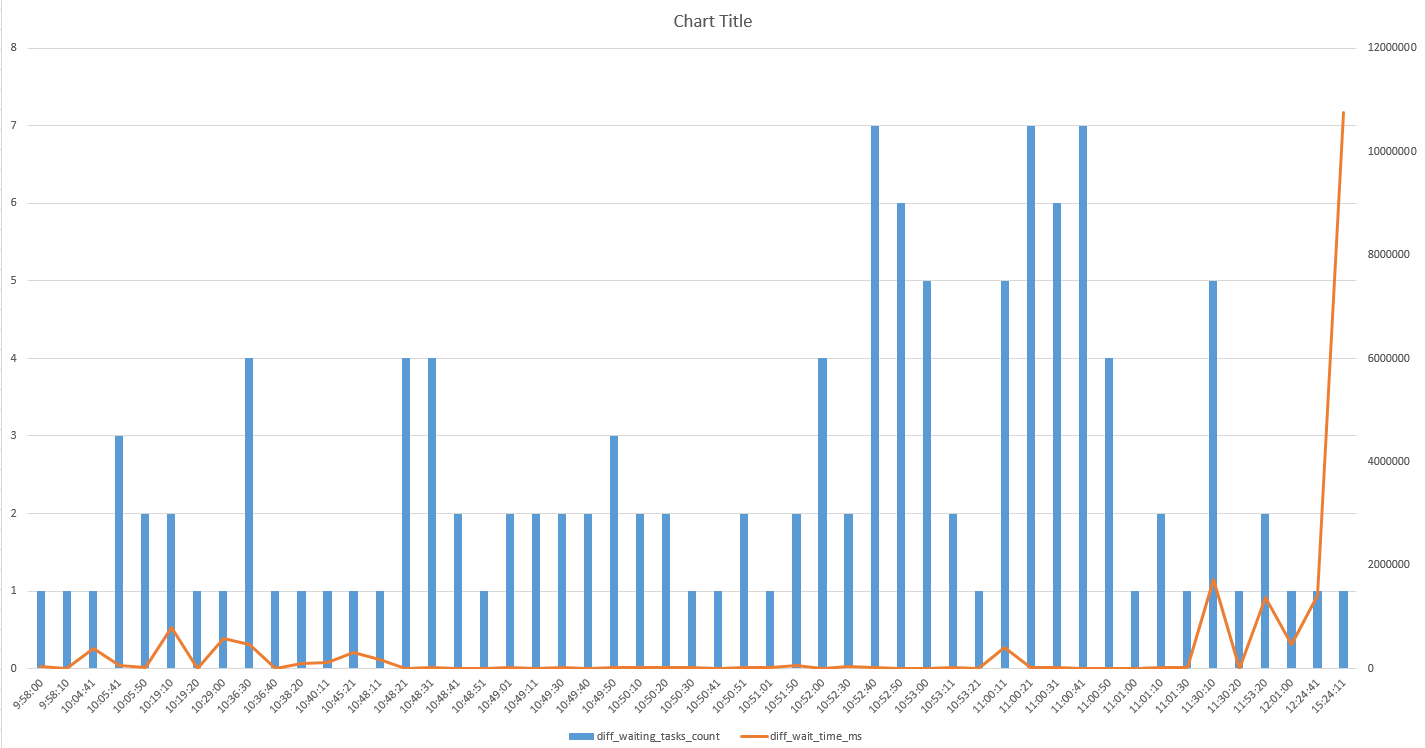
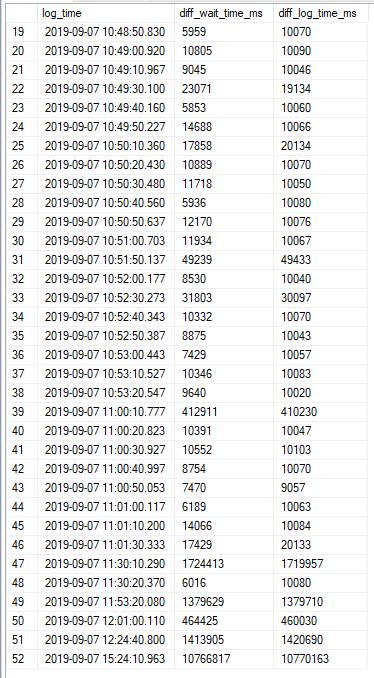
Assembling all those views is painful for beginners (heck Query Store is painful for everyone). Worse, they may find scripts on the internet that are wrong or outdated (meaning they may not have new columns, or they may give outdated advice on things).
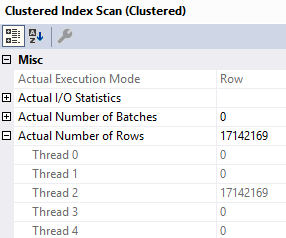
What would make these particularly helpful is that they could aggregate metrics at the database level. Server-wide counters are cool until your server is really wide, and it’s impossible to tell where stuff like wait stats are coming from. This wouldn’t be too difficult to implement, since Azure SQLDB already has to have a bunch of self-contained stuff, due to the lack of cross-database queries.
Best of all, Microsoft can keep them up to date based on which version and edition of SQL Server you’re on, and if certain changes get back ported.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.