If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
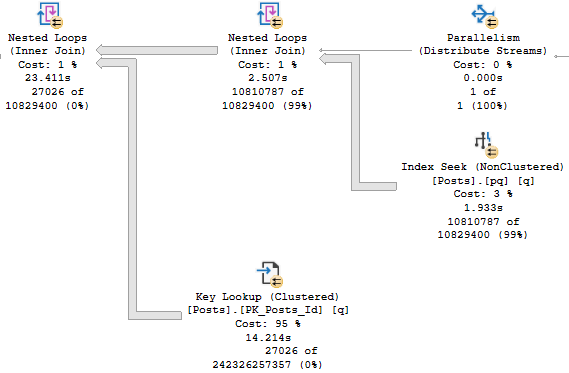
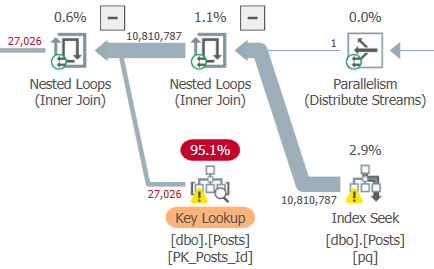
If you’ve ever read Kim Tripp’s wonderful post on tipping points, you’re probably staring at this Key Lookup and wondering why SQL Server would ever even consider it here. That’s like a 12 digit number. Twelve. That’s like a foreign phone number. That’s like what I spent on cheese plates last year.
I kid, I kid. Though I would not be opposed to that lifestyle.
The thing is, what that number represents is a little different from what we might first expect.
That number comes from multiplying these two numbers:
MedleyPass the brie
But Really
That’s how many rows we read. Which isn’t great, obviously. Look how long that thing runs for.
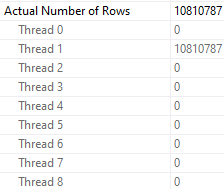
And it gets worse when we examine how rows were distributed on threads.
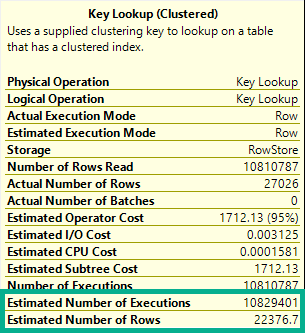
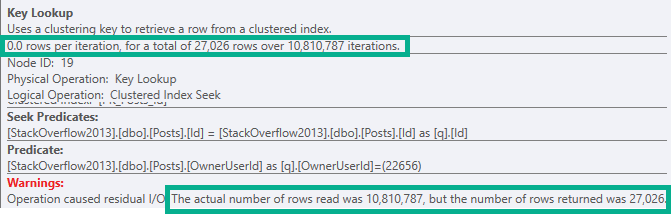
[deep breaths]We produced far fewer rows than that in all, because the Lookup is evaluating a predicate, which only produces ~27k rows.
So for each of the ~11 million rows that comes out of the index seek of our nonclustered index, we:
“Join” it to the clustered index based on the clustered index key column
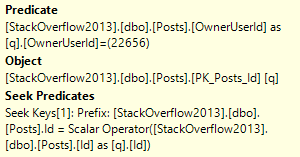
Evaluate if the OwnerUserId for that row is 22656
“ONLY”
The 27,062 number is how many rows are produced after the filter is applied. That’s a bit more obvious when using Plan Explorer.
I can’t go a day without my scotch.Do Be Real, Please
This lookup doesn’t produce any rows or columns, that’s why there are 0.0 rows per iteration.
It’s purely to filter data out, and it does that. Slowly.
Look, I’m not defending the choice, I’m just using it to teach you something.
How Can You Fix It?
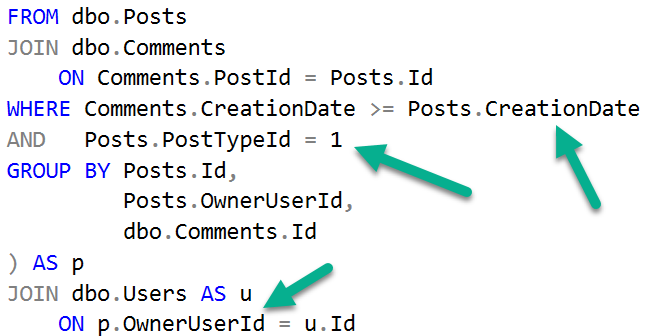
In this case, it would probably be worth adding the OwnerUserId column to the nonclustered index we already have on Posts that’s being used in this query, assuming that it wouldn’t be disruptive to other queries. If that’s not possible, then a new index that satisfies the entire where clause would be a good solution.
If neither of those is palatable, then you might try some exotic rewrites to isolate those rows, correlate on a different column, or “persuade” the optimize to stop pursuing nested loops joins.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
For many people, index tuning means occasionally adding an index when there’s a report about a slow query. Those indexes might come from a query plan, or from the missing index DMVs, where SQL Server stores every complaint the optimizer files when it thinks an index might make a query better.
Sure, there are some people who think index tuning means rebuilding indexes or running DTA and checking all the boxes, but I ban those IP addresses.
Of course, there’s a whole lot more to index tuning. Adding indexes is fine to a point, but you really should spring clean those suckers once in a while, too.
Look for overlapping indexes, unused indexes, and check for any Heaps that may have snuck in there. sp_BlitzIndex is a pretty cool tool for that.
But even for adding indexes, sometimes it takes more than one pass, especially if you’re taking advice from query plans and DMVs.
How The What
Let’s say you’re looking at a server for the first time, or you’re not quite comfortable with designing your own indexes. No judgment, there.
You see a query plan for some piece of code that’s running slowly, and it has a missing index request.
Sugar Sugar Sugar
There’s only one missing index request — there’s not a bunch of hidden ones like in some plans — and it looks moderately helpful so you decide to try it.
Treefiddy
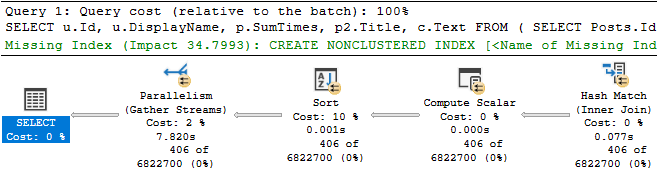
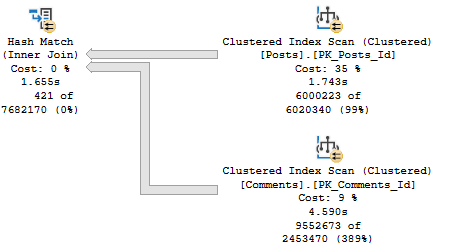
The thing is that as far as “stuff I want to go faster” in the plan, the clustered index scan on Posts is about 3x faster than the clustered index scan on Comments.
Deal with it
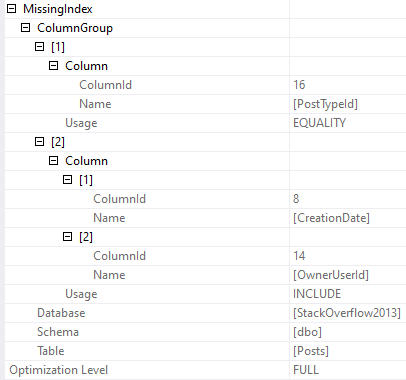
And the index that’s being asked for is only going to help us find PostTypeId = 1. It’s not going to help with the rest of or join or filtering very much.
CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>]
ON [dbo].[Posts] ([PostTypeId])
INCLUDE ([CreationDate],[OwnerUserId])
Una Posta
We still need to filter on CreationDate, and join on OwnerUserId later. Sometimes this index will be “good enough” and other times it “won’t”.
If PostTypeId were really selective, or if this query were searching for a particularly selective PostTypeId, then it’d probably be okay-ish.
But we’re not, so we may settle on this index instead.
CREATE NONCLUSTERED INDEX p
ON [dbo].[Posts] ([PostTypeId], [CreationDate], [OwnerUserId]);
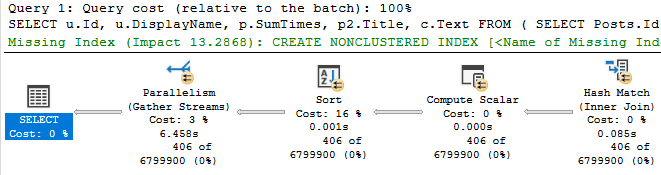
With that in place, we only get marginal improvement in the timing of the plan. It’s about 1.5 seconds faster.
Probably not what we’d wanna report to end users.
Hella
But we have new green text! This time it’s for the Comments table, which is where our pain point lies time-wise.
CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>]
ON [dbo].[Comments] ([PostId],[CreationDate])
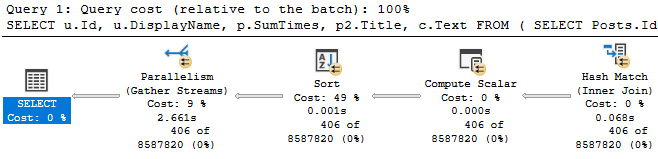
We add that, and reduce our query runtime to less than half of what it was originally.
Babewood
Is 2.6 seconds good? Or great? All depends on expectations.
Could we keep going and experimenting? Sure.
It all depends what we’re allowed to change, what our skill level is (mine is quite low, ho ho ho), and what our priorities are (these are also quite low).
This Is Just One Query
And since we had the luxury of having it in front of us, running it, adding an index, running it again to test the index, etc., we were able to spot the second index request that ended up helping even more than the first one.
If you don’t have that luxury, or if you just poke around the missing index DMVs every 3-6 months, you could miss stuff like this. Sure, that first request would be there, and it might look tempting enough for you to add, but the second one wouldn’t appear until after that. That’s the one that really helped.
Whenever you’re tuning indexes, or releasing code that’s going to use existing data in new ways, you’d be doing yourself a big favor to check in on this stuff at least weekly.
You might be an index tuning wiz and not need to — if you are, I’d be amazed if you made it this far into my blog post, though — or you may catch “obvious” new indexes during development.
But I’m going to tell you something about end users: they’re devious, mischievous, and they’re out to make you look bad.
As soon as they start using those new features of yours, they’re going to abuse them. They’re going to do all sorts of horrible things that you never would have dreamed of. And I’ll bet some different indexes would help you keep your good name.
Or at least your job.
Thanks for reading!
As a postscript to this: I don’t want you to think that missing index requests are the end-all be-all of indexing wisdom. There are lots of limitations, and suggested column order isn’t perfect. But if you’re just getting started, they’re a great way to start to understand indexing, and see the problems they do and don’t solve. And look, the only way to make them better would be to spend longer during compilation thinking about things. That’s not how the optimizer should be spending its time. We’re lucky to get these for free, and you should view them as a learning tool.
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
This is an okay trick to keep in mind when you need to use order by on a large table.
Of course, we care about order by for many very good reasons, especially when we don’t have an index to support the ordering.
Sorting data requires memory, and Sort operators particularly may ask for quite a bit of memory.
Why? Because you need to sort all the columns you’re selecting by the column you’re ordering by.
Sorts aren’t just for the column(s) in your order by — if you SELECT *, you need order to all the columns in the * by all the columns in the order by.
I know I basically repeated myself. That’s for emphasis. It’s something professional writers do.
Dig it.
Butheywhatabout
Let’s say, just for kicks, that we have a table in our database. And maybe it has a column called something like “Id” in it.
Pushing this tale further into glory, let’s also assume that this legendary “Id” column is the primary key and clustered index.
That means we have the entire table sorted by this one column. Cool.
Tighten those wood screws, because we’re about to go cat 5 here. Ready?
There’s a date or date time column in the table — let’s say it defines when the row was first inserted into the table.
It could be a creation date, or an order date. Doesn’t matter.
What does matter? That the “Id” and the “*Date” column increment at the same time, which means that they’re in the same order.
It may suit your queries better to order by the clustered index key column rather than another column in the table which may not be in a helpful index in a helpful order for you query.
Too Sort
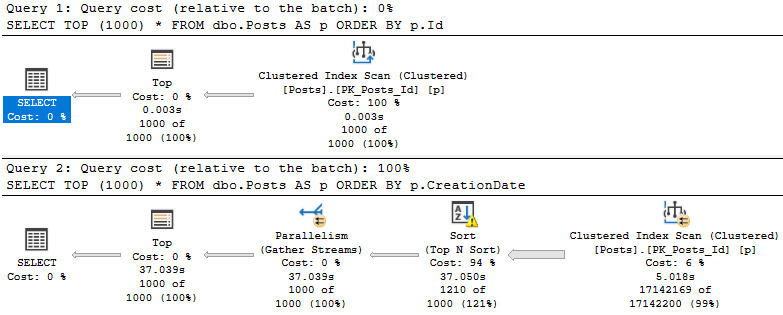
Take these two queries:
SELECT TOP (1000) *
FROM dbo.Posts AS p
ORDER BY p.Id;
SELECT TOP (1000) *
FROM dbo.Posts AS p
ORDER BY p.CreationDate;
I know, they’re terribly unrealistic. No one would ever. Not even close. Fine.
smh
Though both queries present the same data in the same order, the query that orders by the CreationDate column takes uh.
Considerably longer.
For reasons that should be apparent.
Of course, we could add an index to help. Just add all the indexes. What could go wrong?
If you have the type of application that lets users, say, dynamically filter and order by whatever columns they want, you’ve got a whole lot of index to create.
Better get started.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Yes, indexed view maintenance can be quite rough. I don’t mean like, rebuilding them. I will never talk about that.
I mean that, in some cases locks are serializable, and that if you don’t mind your indexes you may find run-of-the-mill modifications taking quite a long time.
Let’s go look!
Mill Town
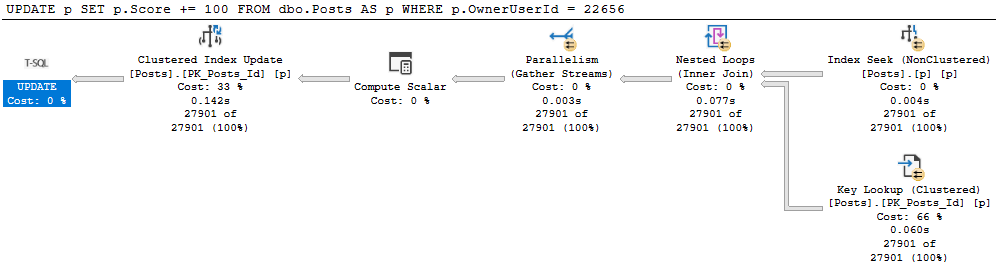
Let’s get update a small chunk of the Posts table.
BEGIN TRAN
UPDATE p
SET p.Score += 100
FROM dbo.Posts AS p
WHERE p.OwnerUserId = 22656;
ROLLBACK
Let’s all digress from the main point of this post for a moment!
It’s generally useful to give modifications an easy path to find data they need to update. For example:
Uh no
This update takes 1.6 seconds because we have no useful index on OwnerUserId. But we get a daft missing index request, because it wants to include Score, which would mean we’d need to then update that index as well as read from it. Locking leads to NOLOCK hints. I tend to want to introduce as little of it as possible.
With an index on just OwnerUserId, our situation improves dramatically.
100000X IMPROVEMENT
Allow Me To Reintroduce Myself
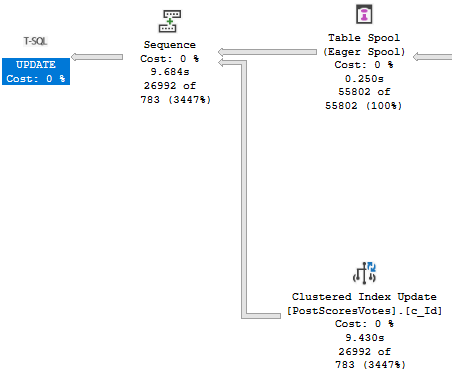
Let’s see what happens to our update with an indexed view in place.
CREATE OR ALTER VIEW dbo.PostScoresVotes
WITH SCHEMABINDING
AS
SELECT p.Id,
SUM(p.Score * 1.0) AS ScoreSum,
COUNT_BIG(v.Id) AS VoteCount,
COUNT_BIG(*) AS OkayThen
FROM dbo.Posts AS p
JOIN dbo.Votes AS v
ON p.Id = v.PostId
WHERE p.PostTypeId = 2
AND p.CommunityOwnedDate IS NULL
GROUP BY p.Id;
GO
CREATE UNIQUE CLUSTERED INDEX c_Id
ON dbo.PostScoresVotes(Id);
Our update query now takes about 10 seconds…
Oof dawg
With the majority of the time being spent assembling the indexed view for maintenance.
Yikes dawg
The Problem Of Course
Is that our indexes are bad. We’ve got no helpful index between Posts and Votes to help with the assembly.
Our first clue may have been when creating the indexed view took a long time, but hey.
Let’s fix it.
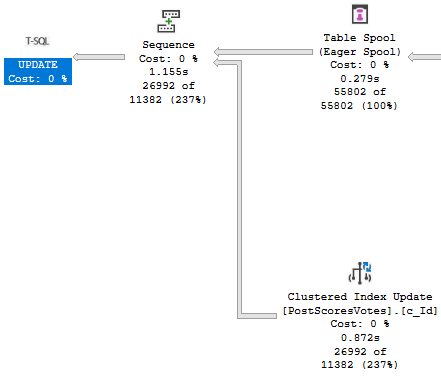
CREATE INDEX v ON dbo.Votes(PostId);
Now our update finishes in about a second!
Cleant Up
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.