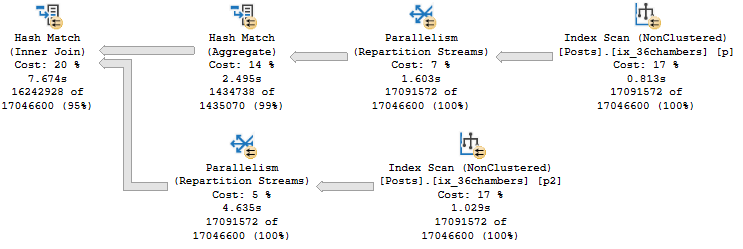
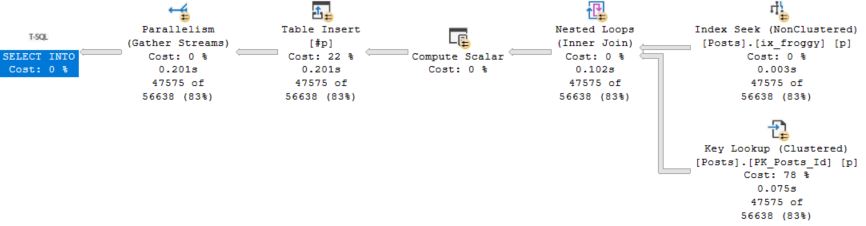
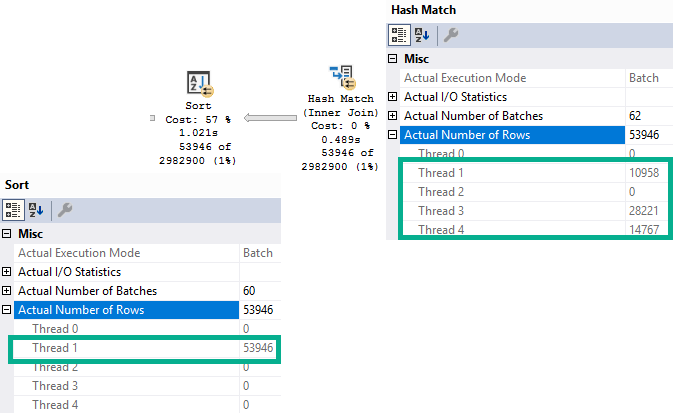
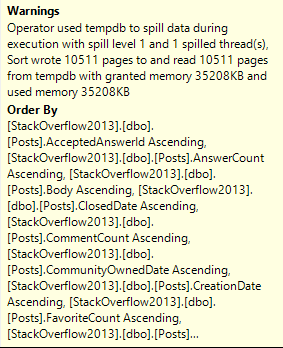
While working on my new training, part of what I want to show people is how to match what happens in a query plan to the type of wait stats they’ll see on their servers.
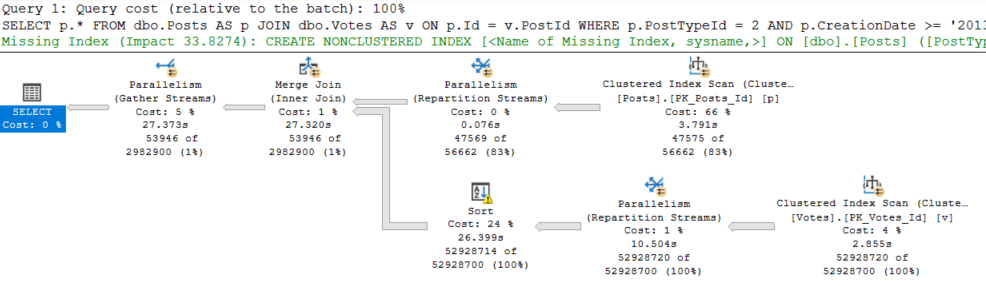
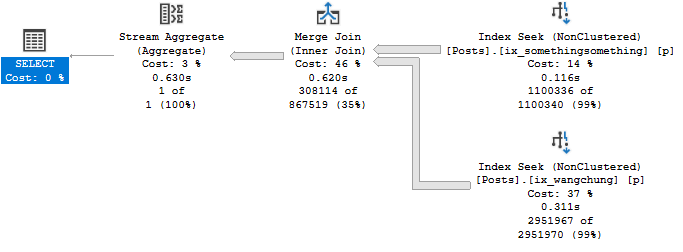
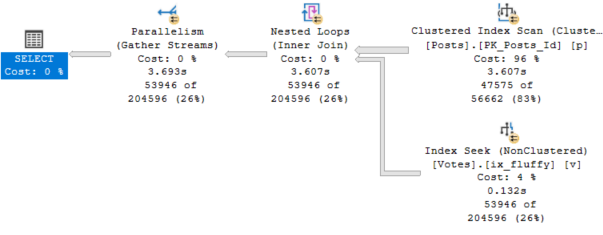
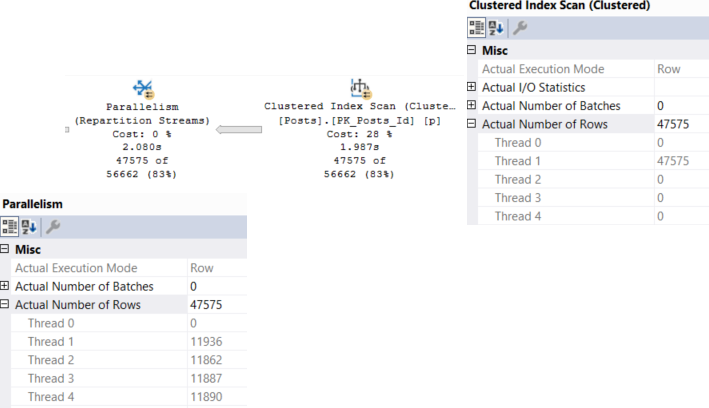
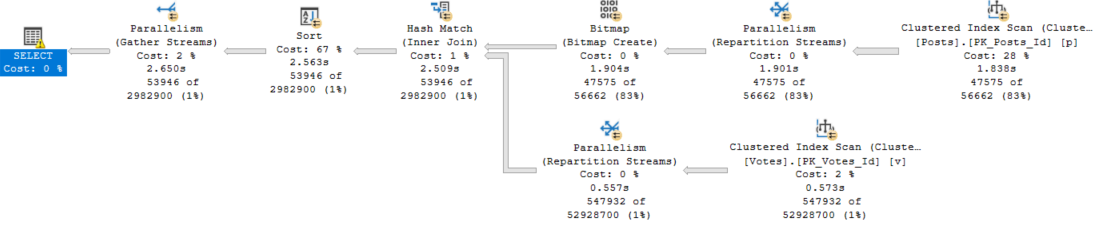
Take this query plan for example:
Nose Boop™
There are THINGS GOING ON HERE! Scans, parallelism, sorting, spilling.
What do the waits look like for this query?
Spy vs Spy
It’s fairly easy to focus in on what a session is doing using sys.dm_exec_session_wait_stats, though there are some caveats about when the numbers reset.
On my laptop, I can just open a new SSMS tab without worrying about connection pooling or any weird app stuff.
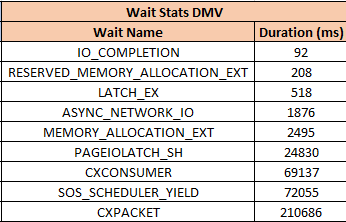
When I do, these are the waits I see while the query runs.
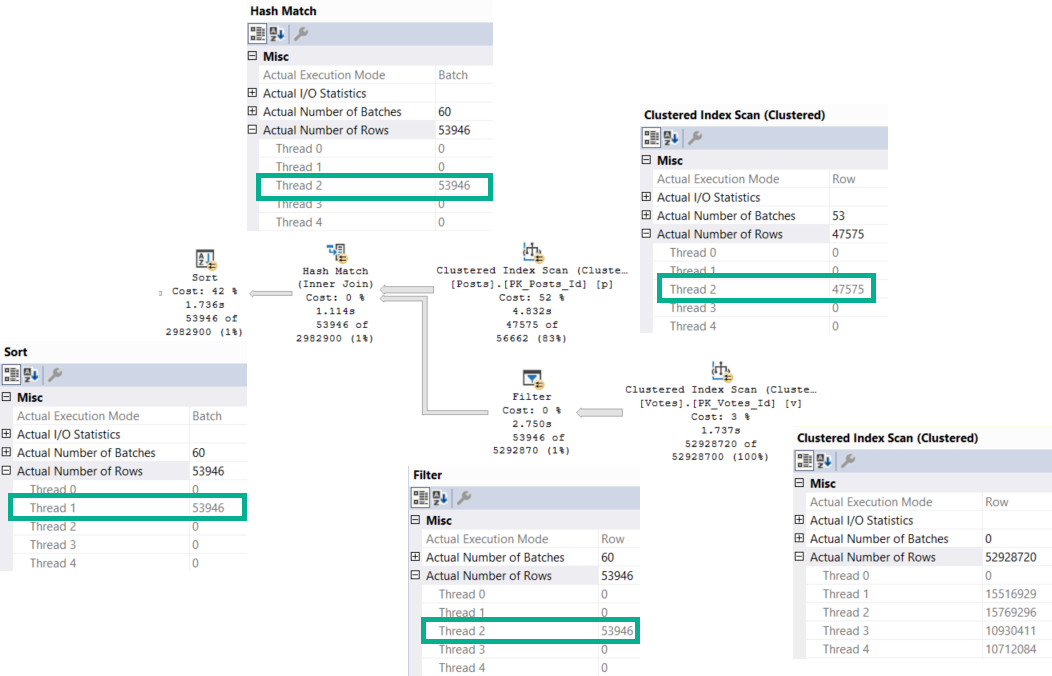
Every single one of those waits is accounted for by something that happened in the query plan (or its attributes).
Breakdown
Our pages weren’t in memory, so we read them from disk (PAGEIOLATCH_SH), we had to allocate buffer pool memory (MEMORY_ALLOCATION_EXT), we used parallelism (both CX waits), we needed memory to sort data (RESERVED_MEMORY_ALLOCATION_EXT), we didn’t get enough so we spilled (IO_COMPLETION), and we returned data to SSMS (ASYNC_NETWORK_IO).
LATCH_EX can be a lot of things. In a parallel plan, it can be associated with exchange buffers and the parallel page supplier.
The goal here is for you to both look at a server’s wait stats and come up with a mental image of the types of queries you’re going to see, and be able to tie query plan operators and attributes back to wait stats.
I had to write some hand-off training about query tuning when I was starting a new job.
As part of the training, I had to explain why writing “complicated logic” could lead to poor plan choices.
So I did what anyone would do: I found a picture of a pirate, named him Captain Or, and told the story of how he got Oared to death for giving confusing ORders.
This is something that I unfortunately still see people doing quite a bit, and then throwing their hands up as queries run forever.
I’m going to show you a simple example of when this can go wrong, and also beg and plead for the optimizer team to do something about it.
Big Bully
“Write the query in the simplest way possible”, they said.
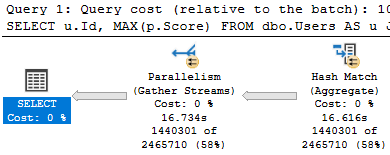
So we did, and we got this.
SELECT u.Id, MAX(p.Score)
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON u.Id = p.OwnerUserId
OR u.Id = p.LastEditorUserId
WHERE p.PostTypeId IN (1, 2)
GROUP BY u.Id;
Note the OR in the join condition — we can match on either of those columns.
Here’s the index we created to make this SUPERFAST.
CREATE NONCLUSTERED INDEX 36chambers
ON dbo.Posts ( OwnerUserId, LastEditorUserId, PostTypeId )
INCLUDE ( Score );
If we’re good DBAs, still doing as we’re told, we’ll read the query plan from right to left.
The first section we’re greeted with is this:
No Cardio
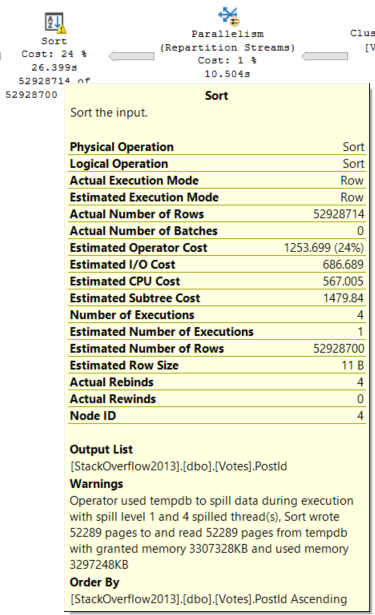
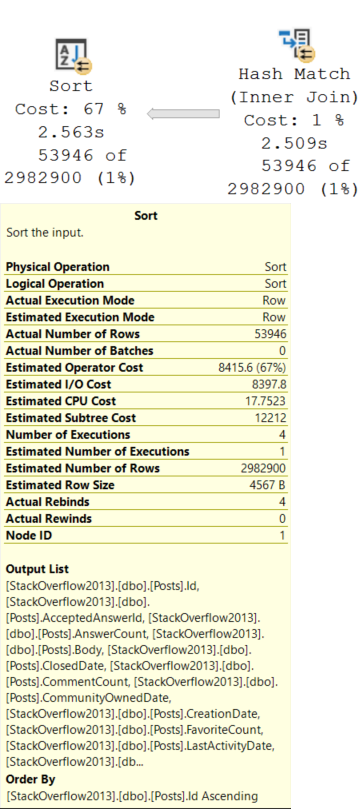
We spend a full minute organizing and ordering data. If you want to poke around, the plan XML is here.
The columns in the Compute Scalars are OwnerUserId and LastEditorUserId.
Next in the plan is this fresh hell:
Squozed
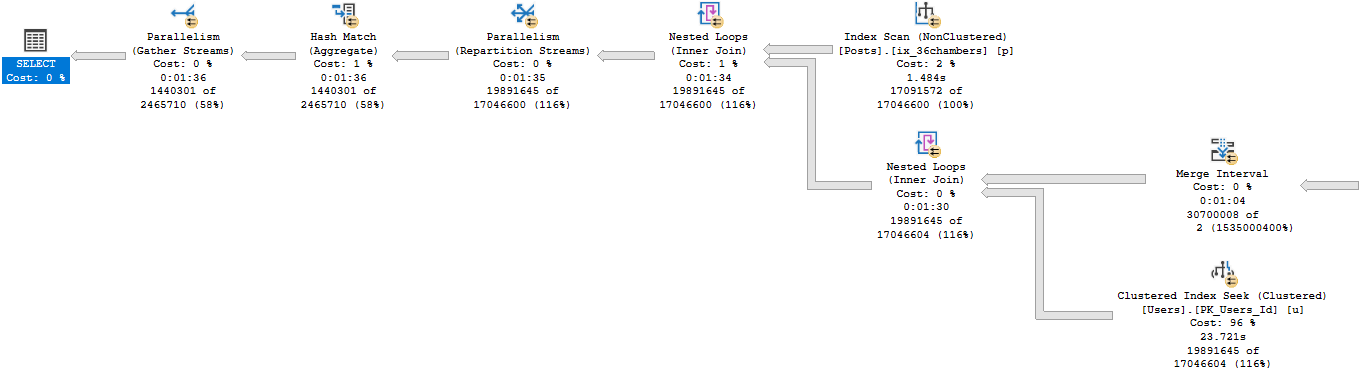
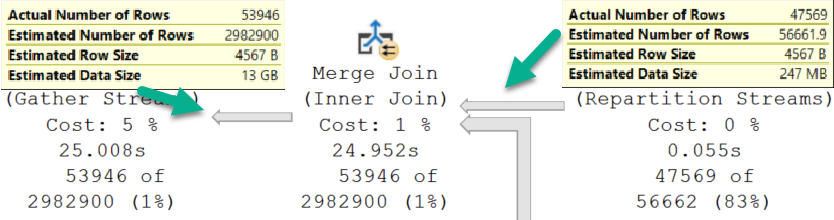
24 seconds seeking into the Users table and joining that to the results of the Constant Scans, etc.
What’s a little confusing here is that the scan on the Posts table occurs on the outer side of Nested Loops.
It’s also responsible for feeding rows through the Constant Scans. That’s their data source.
Overall, this query takes 1:36 seconds to run.
My gripe with it is that it’s possible to rewrite this query in an obvious way to fix the problem.
Magick
Using a second join to Posts clears things up quite a bit.
SELECT u.Id, MAX(p.Score)
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON u.Id = p.OwnerUserId
AND p.PostTypeId IN (1, 2)
JOIN dbo.Posts AS p2
ON u.Id = p2.LastEditorUserId
AND p2.PostTypeId IN (1, 2)
GROUP BY u.Id;
I know, it probably sounds counterintuitive to touch a table twice.
Someone will scream that we’re doing more reads.
Someone else will faint at all the extra code we wrote.
But when we run this query, it finishes in 10 seconds.
That’s better!
This plan does something a bit different. It joins the nonclustered index we have on Posts to itself.
Seminar
The optimizer has a rule that makes this possible, called Index Intersection.
Extra Magick
A more accurate description of what I’d want the optimizer to consider here would be the plan we get when we rewrite the query like this.
SELECT u.Id, MAX(p.Score)
FROM dbo.Users AS u
CROSS APPLY
(
SELECT p.Score
FROM dbo.Posts AS p
WHERE u.Id = p.OwnerUserId
AND p.PostTypeId IN (1, 2)
UNION ALL
SELECT p2.Score
FROM dbo.Posts AS p2
WHERE u.Id = p2.LastEditorUserId
AND p2.PostTypeId IN (1, 2)
) AS p
GROUP BY u.Id;
Mush.
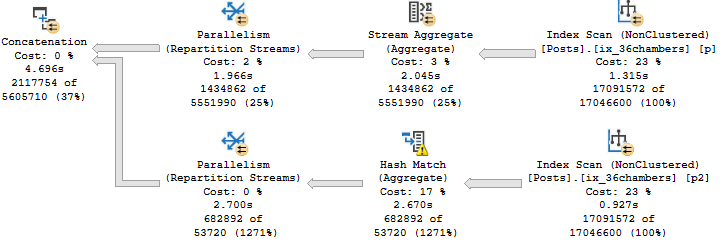
This query runs a bit faster than the second one (around 7 seconds), and the plan is a little different.
Rather than a Hash Join between the index on the Posts table, we have a Concatenation operator.
The rest of the plan looks like this:
Yabadabadoo!
The optimizer has a rule that can produce this plan, too, called Index Union.
Problemagick
The thing is, these rules seem to be favored more with WHERE clauses than with JOINs.
CREATE INDEX ix_fangoria
ON dbo.Posts(ClosedDate);
SELECT COUNT_BIG(*) AS records
FROM dbo.Posts AS p
WHERE p.ClosedDate IS NULL
OR p.ClosedDate >= '20170101'
AND 1 = (SELECT 1);
Index Union
CREATE INDEX ix_somethingsomething
ON dbo.Posts(PostTypeId);
CREATE INDEX ix_wangchung
ON dbo.Posts(AcceptedAnswerId);
SELECT COUNT_BIG(*) AS records
FROM dbo.Posts AS p
WHERE p.PostTypeId = 1
AND p.AcceptedAnswerId = 0
AND 1 = (SELECT 1);
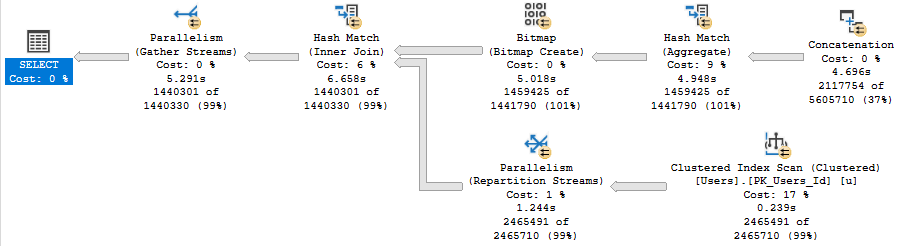
Index Intersection
Knackered
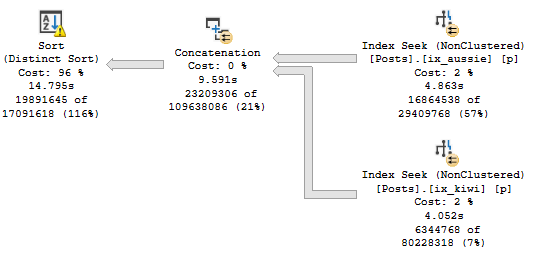
It is possible to get these kind of plans with joins, but not without join hints and a couple indexes.
CREATE INDEX aussie
ON dbo.Posts (OwnerUserId, PostTypeId, Score);
CREATE INDEX kiwi
ON dbo.Posts (LastEditorUserId, PostTypeId, Score);
SELECT u.Id, MAX(p.Score)
FROM dbo.Users AS u
JOIN dbo.Posts AS p
WITH (FORCESEEK)
ON u.Id = p.OwnerUserId
OR u.Id = p.LastEditorUserId
WHERE p.PostTypeId IN (1, 2)
GROUP BY u.Id;
There’s more background from, of course, Paul White, here and here.
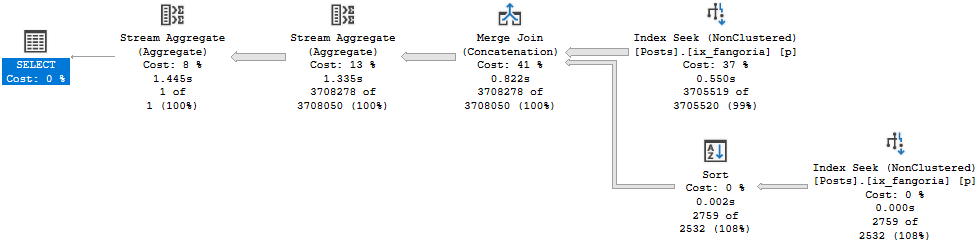
Even with Paul White ~*~Magick~*~, the hinted query runs for ~16 seconds.
If you remember, the Index Intersection plan ran for around 10 seconds, and the Index Union plan ran for around 7 seconds.
2slow
This plan uses Index Union:
Spillzo
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Let’s say we have a super important query. It’s not really important.
None of this is important.
SELECT u.DisplayName, u.Reputation, u.CreationDate
FROM dbo.Users AS u
WHERE u.CreationDate >= DATEADD(DAY, DATEDIFF(DAY, 0, GETDATE()), 0)
AND u.Reputation < 6
ORDER BY u.CreationDate DESC;
Maybe it’ll find users who created accounts in the last day who haven’t gotten any upvotes.
Shocking find, I know.
An okay index to help us find data and avoid sorting data would look like this:
CREATE INDEX ix_apathy
ON dbo.Users(CreationDate DESC, Reputation);
So now we know whose fault it is that we have this index, and we know who to blame when this happens.
Blocko
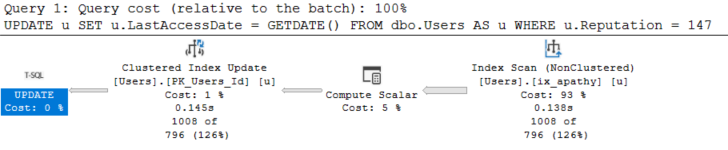
UPDATE u
SET u.LastAccessDate = GETDATE()
FROM dbo.Users AS u
WHERE u.Reputation = 147;
ScannoObjectified
What’s going on here is that the optimizer chooses our narrower index to find data to update.
It’s helpful because we read far less pages than we would if we just scanned the clustered index, but the Reputation column being second means we can’t seek to rows we want.
The optimizer isn’t asking for a missing index here, either (okay, I don’t blame it for a query that runs in 145ms, but stick with me).
Switcheroo
If we change our index to have Reputation first, something nice happens.
To this query.
CREATE INDEX ix_whatever
ON dbo.Users(Reputation, CreationDate DESC);
SoughtOnly Keys Now
With index order switched, we take more fine-grained locks, and we take them for a shorter period of time.
All That For This
If you have a locking problem, here’s what you should do:
Look at your modification queries that have WHERE clauses, and make sure they have the right indexes
Look at your modification queries that modify lots of rows, and try batching them
If your critical read and write queries are at odds with each other, look into an optimistic isolation level
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Like most tricks, this has a specific use case, but can be quite effective when you spot it.
I’m going to assume you have a vague understanding of parameter sniffing with stored procedures going into this. If you don’t, the post may not make a lot of sense.
Or, heck, maybe it’ll give you a vague understanding of parameter sniffing in stored procedures.
One For The Money
Say I have a stored procedure that accepts a parameter called @Reputation.
The body of the procedure looks like this:
SELECT TOP (1000)
u.*
FROM dbo.Users AS u
WHERE u.Reputation = @Reputation
ORDER BY u.CreationDate DESC;
In the users table, there are a lot of people with a Reputation of 1.
Data distributions like this matter. They change how SQL Server approaches coming up with an execution plan for a query.
Which indexes to use, what kind of joins to use, how to aggregate data, if the plan should be serial or parallel…
The list goes on and on.
In this case, we have a narrow-ish nonclustered index:
CREATE INDEX whatever
ON dbo.Users (Reputation, Age, CreationDate);
When I run my stored procedure and look for Reputation = 2, the plan is very fast.
EXEC dbo.WORLDSTAR @Reputation = 2;
Getting to know you.
This is a great plan for a small number of rows.
When I run it for a large number of rows, it’s not nearly as fast.
EXEC dbo.WORLDSTAR @Reputation = 1;
Stuck on you.
We go from a fraction of a second to over three seconds.
This is bad parameter sniffing.
If we run it for Reputation = 1 first, we don’t have the same problem.
That’s good(ish) parameter sniffing.
Better For Everyone
Many things that prevent parameter sniffing will only give you a so-so plan. It may be better than the alternative, but it’s certainly not a “fix”.
It’s possible to get a better plan for everyone in this situation by re-writing the Key Lookup as a self join
SELECT TOP (1000)
u2.*
FROM dbo.Users AS u
JOIN dbo.Users AS u2
ON u.Id = u2.Id
WHERE u.Reputation = @Reputation
ORDER BY u.CreationDate DESC;
The reason why is slightly complicated, but I’ll do my best to explain it simply.
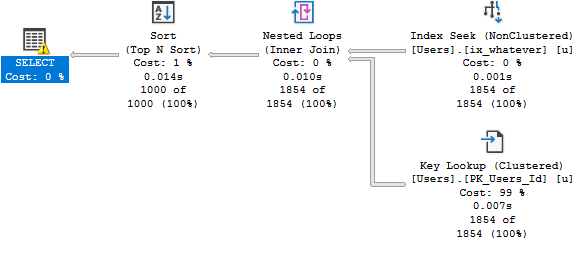
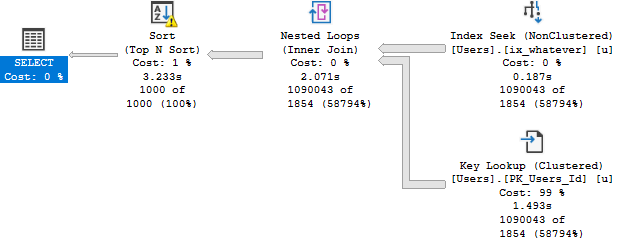
Here’s what the bad parameter sniffing plan looks like for each query.
Note that the Key Lookup plan still runs for ~3 seconds, while the self-join plan runs for around half a second.
DAWG CHILL
While it’s possible for Key Lookups to have Sorts introduced to optimize I/O… That doesn’t happen here.
The main difference between the two plans (aside from run time), is the position of the Sort.
In the Key Lookup plan (top), the Key Lookup between the nonclustered and clustered indexes runs to completion.
In other words, for everyone with a Reputation of 1, we go to the clustered index to retrieve the columns that aren’t part of the nonclustered index.
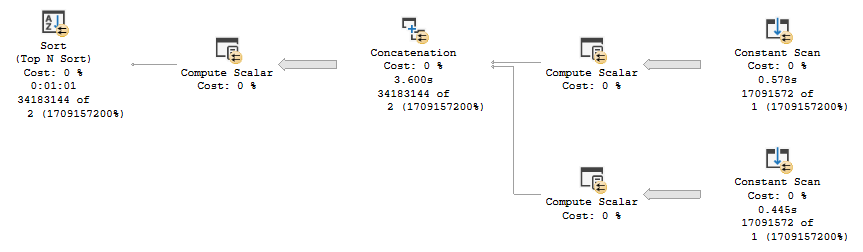
In the self-join plan (bottom), all rows go into the Sort, but only the 1000 come out.
Different World
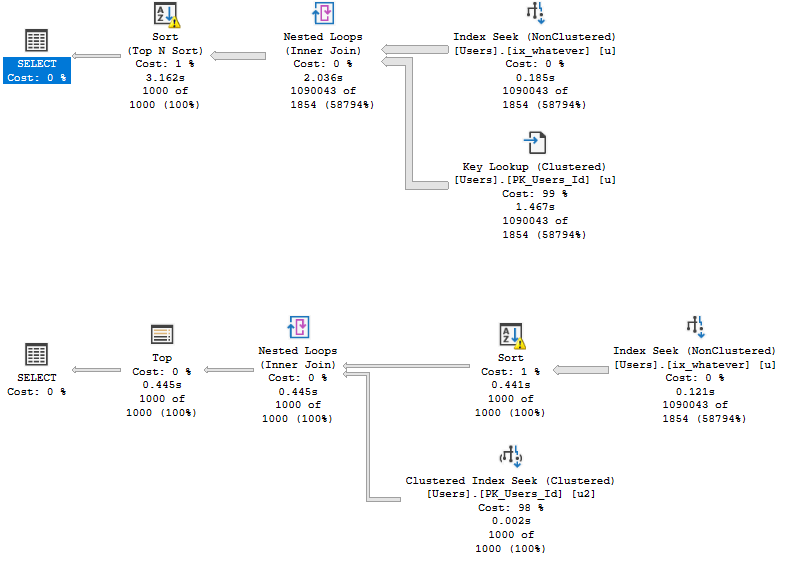
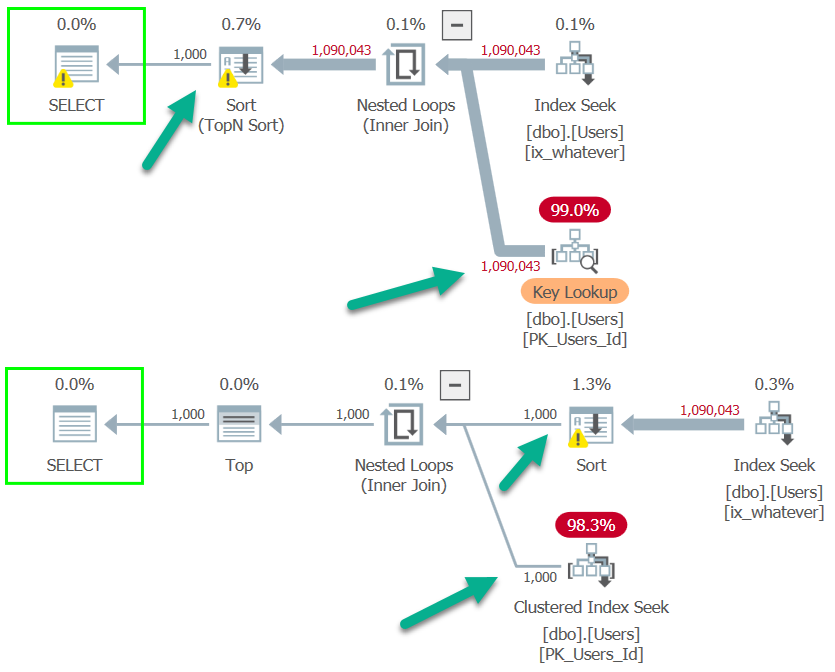
The difference is more obvious when viewed with Plan Explorer.
Get’Em High
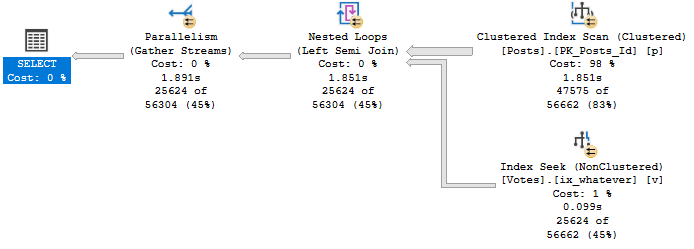
In the Key Lookup plan, rows aren’t narrowed until the end so a seek occurs ~1mm times.
In the self-join plan, they’re eliminated directly after the Index Seek, so the join only runs for 1000 rows and produces 1000 seeks.
This doesn’t mean that Top N Sorts are bad, it just means that they may not produce the most optimal plans for Key Lookups.
When This Doesn’t Work
Without a TOP, the self-join pattern isn’t as dramatically faster, but it is about half a second better (4.3s vs. 3.8s) for the bad parameter sniffing scenario, and far less for the others.
Of course, an index change to put CreationDate as the second key column fixes the issue by removing the need to sort data at all.
CREATE INDEX whatever --Current Index
ON dbo.Users (Reputation, Age, CreationDate);
GO
CREATE INDEX apathy --Better Index For This Query
ON dbo.Users (Reputation, CreationDate, Age);
GO
But, you know, not everyone is able to make index changes easily, and changing the key column order can cause problems for other queries.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
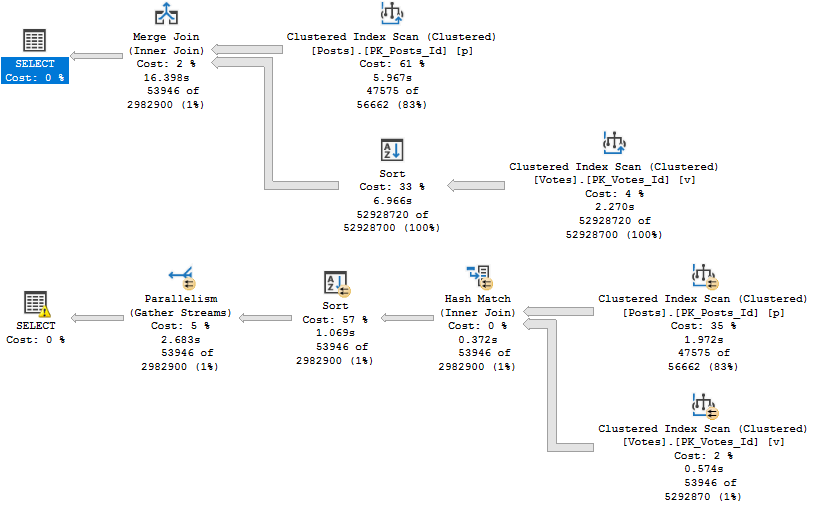
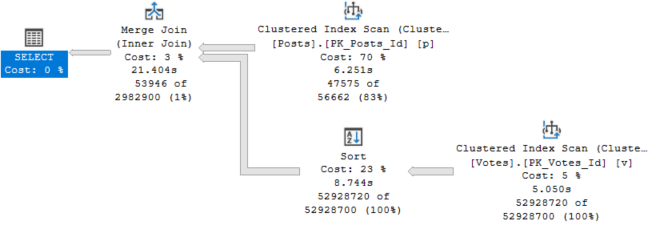
In the last post, we looked at how SQL Server 2019’s Batch Mode for Row Store could have helped our query.
In short, it didn’t. Not because it’s bad, just because the original guess was still bad.
Without a hint, we still got a poorly performing Merge Join plan. With a hint, we got a less-badly-skewed parallel plan.
Ideally, I’d like a good plan without a hint.
In this post, I’ll focus on more traditional things we could do to improve our query.
I’ll approach this like I would if you gave me any ol’ query to tune.
Here’s what we’re starting with:
SELECT p.*
FROM dbo.Posts AS p
JOIN dbo.Votes AS v
ON p.Id = v.PostId
WHERE p.PostTypeId = 2
AND p.CreationDate >= '20131225'
ORDER BY p.Id;
First Pass
I don’t know about you, but I typically like to index my join columns.
Maybe not always, but when the optimizer is choosing to SORT 52 MILLION ROWS each and every time, I consider that a cry for help.
Indexes sort data.
Let’s try that first.
CREATE INDEX ix_fluffy
ON dbo.Votes(PostId);
This is… Okay.
Willingly!
I’m not saying this plan is great. It’s certainly faster than the Merge Join plan, and the optimizer chose it without us having to hint anything.
It takes 3.6 seconds total. I think we can do better.
Second Pass
I wonder if a temp table might help us.
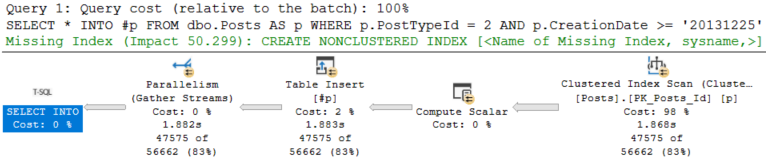
SELECT *
INTO #p
FROM dbo.Posts AS p
WHERE p.PostTypeId = 2
AND p.CreationDate >= '20131225';
This is… Okay. Again.
The Insert takes 1.8 seconds:
Scrunchy face.
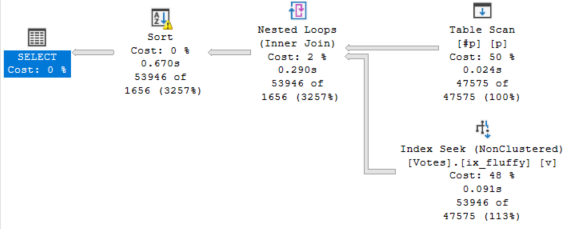
The final select takes 670ms:
Add’em up.
Usually this is the point where I’ll stop and report in:
“I’ve spent X amount of time working on this, and I’ve gotten the query from 27 seconds down to about 2.5 seconds. I can do a little more and maybe shave more time off, but I’ll probably need to add another index. It’s up to you though, and how important this query is to end users.”
We could totally stop here, but sometimes people wanna go one step further. That’s cool with me.
Third Pass
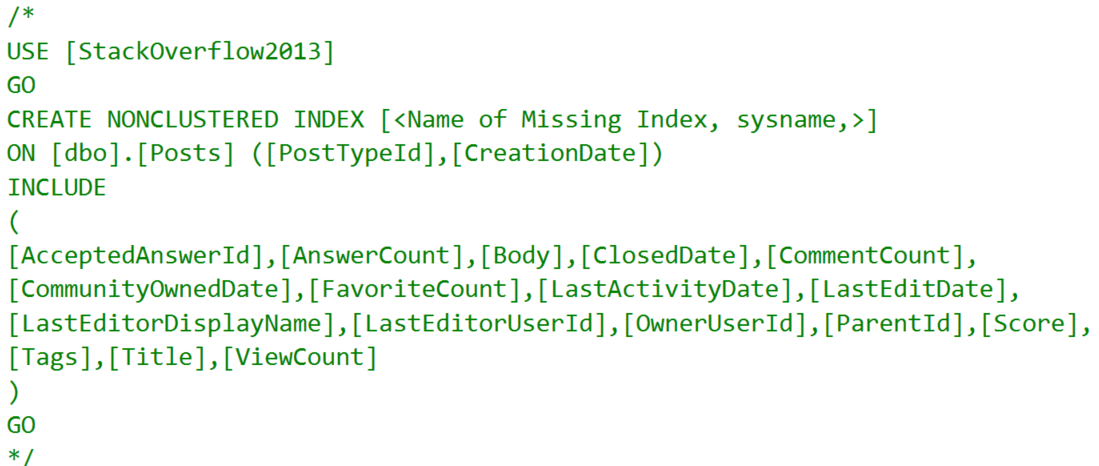
The insert query is asking for an index, but it’s a dumb dumb booty head index.
Thanks, Robots.
Yep. Include every column in the table. Sounds legit.
Let’s hedge our bets a little.
CREATE INDEX ix_froggy
ON dbo.Posts(PostTypeId, CreationDate);
I bet we’ll use a narrow index on just the key columns here, and do a key lookup for the rest.
Righto
This time I was right, and our Insert is down to 200ms.
This doesn’t change the speed of our final select — it’s still around 630-670ms when I run it.
Buuuuuuut, this does get us down to ~900ms total.
Final Destination
Would end users notice 900ms over 2.5 seconds? Maybe if they’re just running it in SSMS.
In my experience, by the time data ends up in the application, gets rendered, and then displayed to end users, your query tuning work can feel a bit sabotaged.
They’ll notice 27 seconds vs 2.5 seconds, but not usually 2.5 seconds vs 1 second.
It might make you feel better as a query tuner, but I’m not sure another index is totally worth that gain (unless it’s really helping other queries, too).
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
In the last post, I tried to play some tricks on the optimizer to have Batch Mode make a query faster.
It didn’t quite work out the way I wanted.
That isn’t to knock Batch Mode. It’s not supposed to fix everything, and I played a silly trick to get some operators to use it.
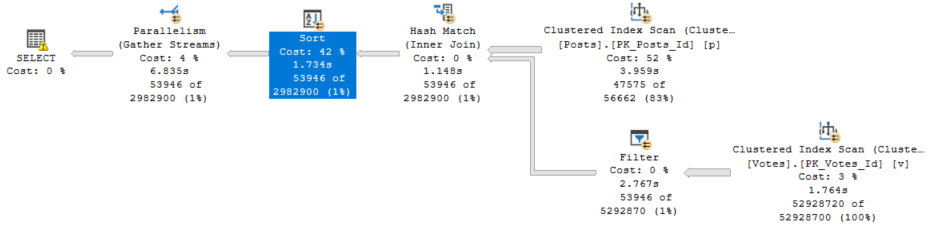
But it did make me curious if 2019’s Batch Mode for Row Store would improve anything.
After all, no dirty tricks are involved, which means more operators can potentially use Batch Mode, and maybe we’ll avoid that whole skewed parallelism problem.
I mean, what are the odds that I’ll get the exact same plans and everything?
Spoiler
50%
The Merge Join plan is still wack as hell.
The forced hash join plan got better, though.
Still Skewy?
The skewed parallelism isn’t as contagious going across without the separate Filter/Bitmap operator.
Uggo
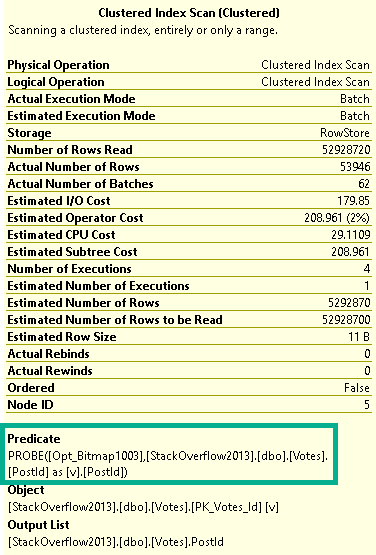
With both the Hash Join and the Scan of Votes occurring in Batch Mode, the Bitmap is able to be pushed to the storage engine.
Note that there’s no explicit Bitmap filter anywhere in the plan, but one still shows up in the predicate of the Scan of the Votes table.
Something new
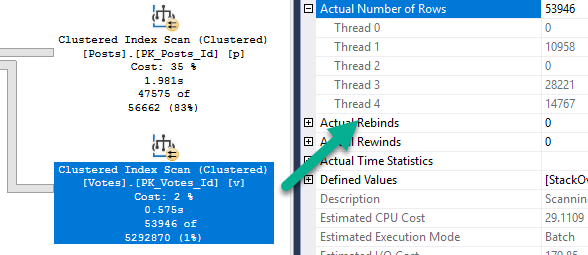
With 3 out of 4 threads doing… vaguely even work, we end up in a better place, especially compared to only one thread doing any work.
At least now I can show you the Batch Mode Sort lie about being parallel.
Crud
Three threads with rows at the Hash Join go into the Sort on a single thread.
You Know…
As much as I love these new bells and whistles, I’m gonna go back to good ol’ fashion query tuning next.
The problem here is still that a bad estimate causes a Merge Join to be chosen in the first place.
When we force the Hash Join, query runtime is reduced at the expense of a quite large memory grant.
This is likely preferable for most people (especially with Batch Mode Memory Grant Feedback), but it doesn’t address the root cause.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
In the last post, I showed you a query where a bad plan was chosen because of bad guesses.
In this post, I’m going to see if Batch Mode will help anything.
To do that, we’re going to use an empty temp table with a clustered columnstore index on it.
CREATE TABLE #t (id INT NOT NULL,
INDEX c CLUSTERED COLUMNSTORE);
First Up, No Hints
SELECT p.*
FROM dbo.Posts AS p
JOIN dbo.Votes AS v
ON p.Id = v.PostId
LEFT JOIN #t ON 1 = 0
WHERE p.PostTypeId = 2
AND p.CreationDate >= '20131225'
ORDER BY p.Id;
Deeply Unsatisfying
Though this plan is ~6 seconds faster than the Merge Join equivalent in the last post, that’s not the kind of improvement I’m shooting for.
Remember than the Hash Join plan in Row Mode ran in 2.6 seconds.
The only operator to run in Batch Mode here is the Sort. To be fair, it’s really the only one eligible with the trick we used.
Forcing this plan to run in parallel, we go back to a 27 second runtime with no operators in Batch Mode.
Next Up, Hash Hint
Disappointingly, this gets worse. The Row Mode only plan was 2.6 seconds, and this is 6.8 seconds.
Hush now
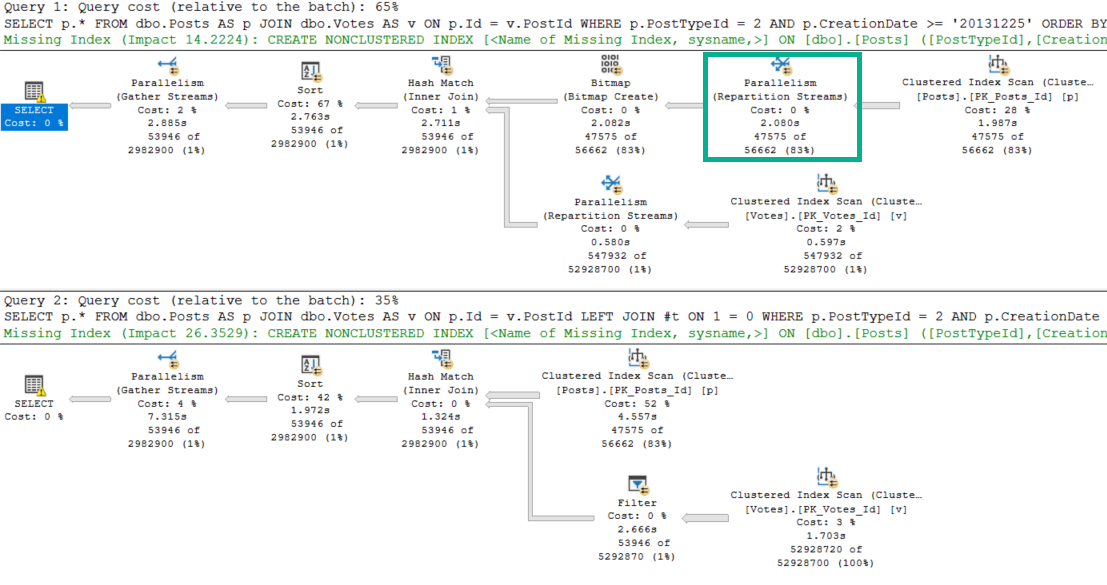
The answer to why the Batch Mode plan is 3x slower lies in our Row Mode plan. Let’s look at them head to head.
Pick me!
See that Repartition Streams operator? It literally saves the entire query.
The Batch Mode plan doesn’t get one. Because of that, Bad Things Happen™
Skew Job
Both plans start out with an unfortunate scan of the Posts table.
Sucktown
But in the Row Mode plan, Repartition Streams does exactly what it sounds like it does, and balances things out. The number of rows on each thread is even because of this. Crazy to think about, but threads dividing work up evenly is, like, a good thing.
In the Batch Mode plan, that… doesn’t happen.
Apology dog
We have the dreaded serial parallel query. Aside from the Scan of the Votes table, only one thread is ever active across the rest of the query.
This isn’t a limitation of Batch Mode generally, though I suspect it has something to do with why we don’t see Repartition Streams show up.
One limitation of Batch Mode is with Sorts — they are single threaded — a point this particular demo obfuscates, unless they’re a child operator of a Window Aggregate.
Well, Darn
I was expecting some fireworks there.
Maybe 2019 will help?
In the next post, we’ll look at that.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
We’ve got no supporting indexes right now. That’s fine.
The optimizer is used to not having helpful indexes. It can figure things out.
SELECT p.*
FROM dbo.Posts AS p
JOIN dbo.Votes AS v
ON p.Id = v.PostId
WHERE p.PostTypeId = 2
AND p.CreationDate >= '20131225'
ORDER BY p.Id;
Snap City.
So uh. We got a merge join here. For some reason. And a query that runs for 27 seconds.
The optimizer was all “no, don’t worry, we’re good to sort 52 million rows. We got this.”
YOU’VE GOT THIS.
[You don’t got this — ED]
Choices, Choices
Since we have an order by on the Id column of the Posts table, and that column is the Primary Key and Clustered index, it’s already in order.
The optimizer chose to order the PostId column from the Votes table, and preserve the index order of the Id column.
Merge Joins expect ordered input on both sides, don’tcha know?
It could have chosen a Hash Join, but then the order of the Id column from the Posts table wouldn’t have been preserved on the other side.
Merge Joins are order preserving, Hash Joins aren’t. If we use a Hash Join, we’re looking at ordering the results of the join after it’s done.
But why?
Good Guess, Bad Guess
Going into the Merge Join, we have a Good Guess™
Coming out of the Merge Join, we have a Bad Guess™
Thinking back to the Sort operator, it only has to order the PostId column from the Votes table.
That matters.
Hash It Up
To compare, we need to see what happens with a Hash Join.
smh
Okay, ignore the fact that this one runs for 2.6 seconds, and the other one ran for 27 seconds.
Just, like, put that aside.
Here’s why:
Neither Nor
This Sort operator is different. We need to sort all of the columns in the Posts table by the Id column.
Remember that the Id column is now out of order after the Hash Join.
Needing to sort all those columns, including a bunch of string columns, along with an NVARCHAR(MAX) column — Body — inflates the ever-weeping-Jesus out of the memory grant.
I see.
The Hash Join plan is not only judged to be more than twice as expensive, but it also asks for a memory grant that’s ~3x the size of the Merge Join plan.
Finish Strong
Let’s tally up where we’re at.
Both queries have identical estimated rows.
The optimizer chooses the Merge Join plan because it’s cheaper.
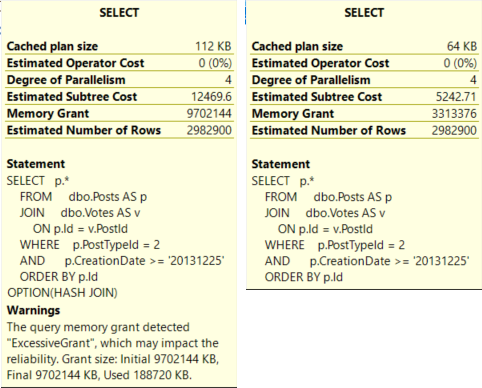
The Merge Join plan runs for 27 seconds, asks for 3.3GB of RAM, and spills to disk.
The Hash Join plan runs for 3 seconds, asks for 9.7GB of RAM and doesn’t spill, but it only uses 188MB of the memory grant.
That has impacted the reliability.
In a world where memory grants adjust between executions, I’ll take the Hash Join plan any day of the week.
But this is SQL Server 2017, and we don’t get that without Batch Mode, and we don’t get Batch Mode without playing some tricks.
There are lots of solutions if you’re allowed to tune queries or indexes, but not so much otherwise.
In the next couple posts, I’ll look at different ways to approach this.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I have two queries. They return the same number of rows.
The only difference is one column in the select list.
This query has the Id column, which is the primary key and clustered index of the Posts table.
SELECT DISTINCT
p.Id, p.AcceptedAnswerId, p.AnswerCount, p.Body, p.ClosedDate,
p.CommentCount, p.CommunityOwnedDate, p.CreationDate,
p.FavoriteCount, p.LastActivityDate, p.LastEditDate,
p.LastEditorDisplayName, p.LastEditorUserId, p.OwnerUserId,
p.ParentId, p.PostTypeId, p.Score, p.Tags, p.Title, p.ViewCount
FROM dbo.Posts AS p
JOIN dbo.Votes AS v
ON p.Id = v.PostId
WHERE p.PostTypeId = 2
AND p.CreationDate >= '20131225'
ORDER BY p.Id;
The query plan for it looks like this:
Eligible
Notice that no operator in this plan performs any kind of aggregation.
There’s no Hash Match Aggregate, no Stream Aggregate, no Distinct Sort, NADA!
It runs for ~1.9 seconds to return about 25k rows.
Lessen
Watch how much changes when we remove that Id column from the select list.
SELECT DISTINCT
p.AcceptedAnswerId, p.AnswerCount, p.Body, p.ClosedDate,
p.CommentCount, p.CommunityOwnedDate, p.CreationDate,
p.FavoriteCount, p.LastActivityDate, p.LastEditDate,
p.LastEditorDisplayName, p.LastEditorUserId, p.OwnerUserId,
p.ParentId, p.PostTypeId, p.Score, p.Tags, p.Title, p.ViewCount
FROM dbo.Posts AS p
JOIN dbo.Votes AS v
ON p.Id = v.PostId
WHERE p.PostTypeId = 2
AND p.CreationDate >= '20131225';
This is what the query plan now looks like:
What’s wrong with you.
Zooming in a bit…
Woof.
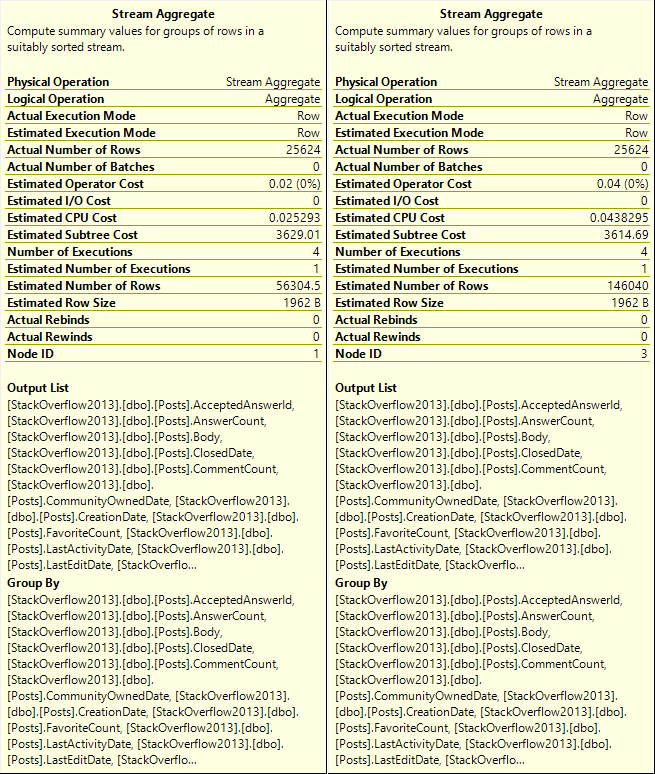
After we Scan the Posts table, we sort about 47k rows.
After the join to Votes, we aggregate data twice. There are two Stream Aggregate operators.
What do we sort?
Boogers.
We Sort every column in the table by every column in the table.
In other words, we order by every column we’ve selected.
What do we aggregate?
Everything. Twice.
What Does It All Mean?
When selecting distinct rows, it can be beneficial to include a column that the optimizer can guarantee is unique in the set of selected columns. Think of a primary key, or another column with a uniqueness constraint on it.
Without that, you can end up doing a lot of extra work to create a distinct result set.
Of course, there are times when that changes the logic of the query.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
The other night I was presenting for a user group, and I had a demo break on me.
Not the first time, not the last time. But this was weird because I had rehearsed things that morning.
I skipped over it at the time, but afterwards I started thinking about what had happened, and walking back through other stuff I had done that day.
Turns out, I had fragmented my indexes, and that broke a trivial plan demo.
Just Too Trivial
The working demo looks like this.
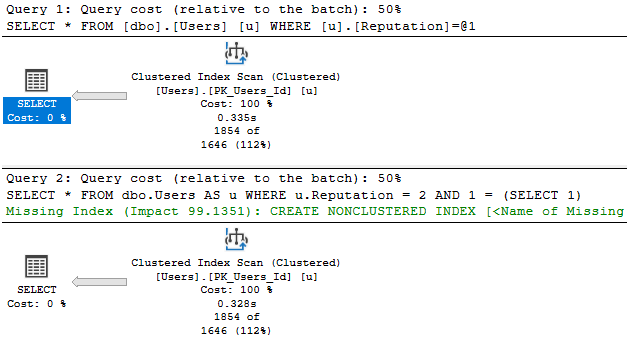
I run these queries. The top one receives a trivial plan, and doesn’t have a missing index request.
The bottom one gets full optimization, and one shows up.
/*Nothing for you*/
SELECT *
FROM dbo.Users AS u
WHERE u.Reputation = 2;
/*Missing index requests*/
SELECT *
FROM dbo.Users AS u
WHERE u.Reputation = 2
AND 1 = (SELECT 1);
Picture perfect.
Snap Your Shot
How I had broken this demo was by playing with Snapshot Isolation.
At some point earlier in the day, I had done something like this:
ALTER DATABASE StackOverflow2013
SET ALLOW_SNAPSHOT_ISOLATION ON;
BEGIN TRAN
UPDATE dbo.Users SET Reputation += 1
ROLLBACK
When you use optimistic isolation levels, a 14 byte pointer gets added to every row to keep track of its version.
If I had run the update without it, it wouldn’t have been a big deal. But, you know.
I’m not that lucky. Or smart.
See, after updating every row in the table, my table got uh… bigger.
Looter in a riot
Now, if I rebuild the table with snapshot still on, the problem goes away.
The problem is that I didn’t do that before or after my little experiment.
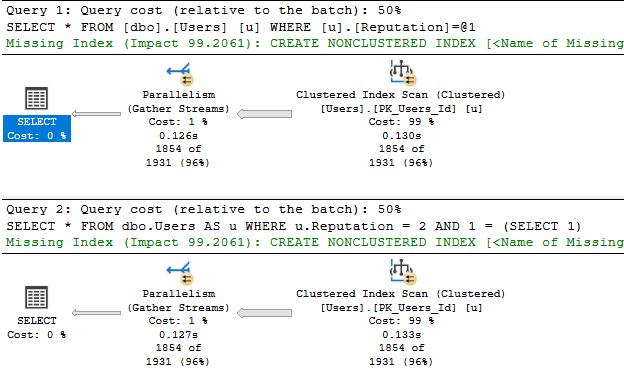
With a heavily fragmented index, both queries not only get fully optimized, but also go parallel.
Faster/Stronger
They’re both a bit faster. They both use a little more resources.
Why? Because SQL Server looked at the size of the table and decided it would be expensive to scan this big chonker.
Egg Wipes
Moral of the story: Index fragmentation makes your queries better.
Don’t @ me.
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.