Infrequent
I have occasionally cheated a little and used OPTIMIZE FOR some_value to fix a parameter sniffing issue that didn’t have any other viable options available to it.
This is a pretty rare situation, but there’s a place for everything. Keep in mind that I’m not talking about UNKNOWN here. I’m talking about a real value.
Recently I had to fix a specific problem where cardinality estimates for datetime values would get completely screwed up if they were older than a day.
You’d be tempted to call this an ascending key problem, but it was really an ascending key solution. Whenever a query got an off histogram estimate, it chose a good plan — when it got a histogram step hit, the estimate was high by several million rows, and the plan looked like someone asked for all the rows in all the databases in all the world.
So, you go through the usual troubleshooting steps:
- More frequent stats updates: uh oh, lots of recompiles
- Stats updates with fullscan during maintenance: crapped out during the day
- Various trace flags and acts of God: Had the opposite effect
- Is my query doing anything dumb? Nope.
- Are my indexes eating crayons? Nope.
Drawing Board
The problem with OPTIMIZE FOR is that… it’s picky. You can’t just optimize for anything.
For example, you can’t do this:
DECLARE
@s datetime = '19000101'''
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
WHERE u.CreationDate >= @s
OPTION
(
OPTIMIZE FOR (@s = GETDATE())
);
And you can’t do this:
DECLARE
@s datetime = '19000101',
@d datetime = GETDATE()
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
WHERE u.CreationDate >= @s
OPTION
(
OPTIMIZE FOR (@s = @d)
);
We get a nasty message.
Msg 320, Level 15, State 1, Line 26
The compile-time variable value for ‘@s’ in the OPTIMIZE FOR clause must be a literal.
Ever Heard Of A Chef Who Can’t Cook?
The solution is, as usual, dynamic SQL, but there’s a catch. Because there’s always a catch.
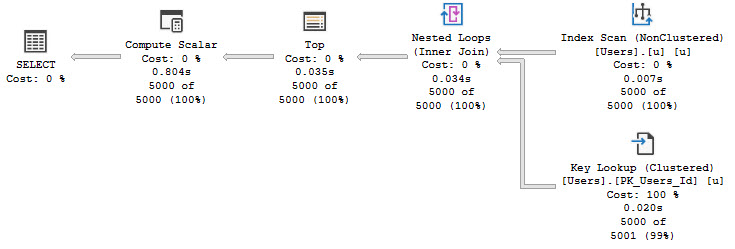
For example this works, but if you run it a minute or so apart, you get multiple plans in the cache.
DBCC FREEPROCCACHE;
DECLARE
@sql nvarchar(MAX) = N'',
@s datetime = '19000101',
@d datetime = GETDATE(),
@i int = 0;
WHILE @i < 10
BEGIN
SELECT
@sql = N'
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
WHERE u.CreationDate >= @s
OPTION
(
OPTIMIZE FOR (@s = ''' + CONVERT(nvarchar(30), @d) + ''')
);
';
EXEC sys.sp_executesql
@sql,
N'@s datetime',
@s;
SELECT
@i += 1;
END
EXEC sp_BlitzCache
@DatabaseName = 'StackOverflow';

Are You Ready For Some Date Math?
Depending on how we want to address this, we can either:
- Do some date math to go to the beginning of the current day
- Do some date math to go to the end of the current day
- Set the value to the furthest possible date in the future
The first two cases should generally be fine. Saying the quiet part out loud, not a lot of plans survive a long time, either due to plan cache instability or other recompilation events, like from stats updates.
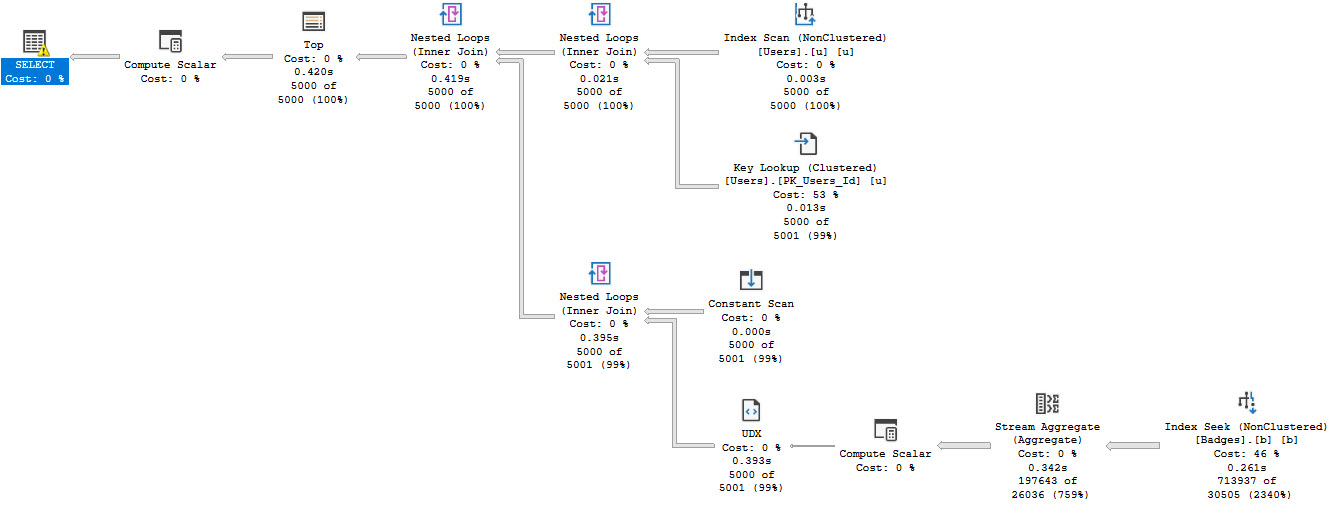
If you’re super-picky about that, go with the third option. This may also be considered the safest option because a stats update might give you a histogram for today’s value. The datetime max value will theoretically “never” be a histogram step value, but that depends on if you let users do Stupid Things™
DBCC FREEPROCCACHE;
DECLARE
@sql nvarchar(MAX) = N'',
@s datetime = '19000101',
@d datetime = '99991231',
@i int = 0;
WHILE @i < 10
BEGIN
SELECT
@sql = N'
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
WHERE u.CreationDate >= @s
OPTION
(
OPTIMIZE FOR (@s = ''' + CONVERT(nvarchar(30), @d) + ''')
);
';
EXEC sys.sp_executesql
@sql,
N'@s datetime',
@s;
SELECT
@i += 1;
END
No matter how many times you run this, the plan will get reused and you’ll always have the off-histogram step.
Qualifying Events?
This is one of those “good ideas” I have for a specific circumstance without any other easy workarounds. I don’t suggest it as a general practice, and it certainly has some drawbacks that would make it dangerous in other circumstances.
I can’t easily reproduce the problem this solved locally, but I can show you why you probably don’t want to make it a habit.
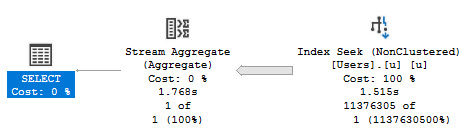
In cases where you are able to get good cardinality estimates, this will hamper it greatly.
So, you know, last resort.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.