The fine folks over at the Carnegie Mellon Database Group have been putting on a series of talks about different databases, and they finally got around to my beloved SQL Server.
This is a really interesting talk, but don’t stop there. Be sure to check out their other videos. They’re a little more database agnostic, but still generally useful.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Many people will go their entire lives without using or seeing a lock hint other than NOLOCK.
Thankfully, NOLOCK only ever leads to weird errors and incorrect results. You’ll probably never have to deal with the stuff I’m about to talk about here.
But that’s okay, you’re probably busy with the weird errors and incorrect results.
Fill The Void
It doesn’t matter who you are, or which Who you use, they all look at the same stuff.
If I run a query with a locking hint to use the serializable isolation level, it won’t be reflected anywhere.
SELECT
u.*
FROM dbo.Users AS u WITH(HOLDLOCK)
WHERE u.Reputation = 2;
GO 100
This isn’t to say that either of the tools is broken, or wrong necessarily. They just use the information available to them.
ah well
Higher Ground
If you set the isolation level at a higher level, they both pick things up correctly.
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
SELECT
u.*
FROM dbo.Users AS u WITH(HOLDLOCK)
WHERE u.Reputation = 2;
GO 100
gratz
Deadlocks, Too
If we set up a deadlock situation — and look, I know, these would deadlock anyway, that’s not the point — we’ll see the same isolation level incorrectness in the deadlock XML.
BEGIN TRAN
UPDATE u
SET u.Age = 1
FROM dbo.Users AS u WITH(HOLDLOCK)
WHERE u.Reputation = 2;
UPDATE b
SET b.Name = N'Totally Tot'
FROM dbo.Badges AS b WITH(HOLDLOCK)
WHERE b.Date >= '20140101'
ROLLBACK
Again, it’s not like the tool is wrong. It’s just parsing out information from the deadlock XML. The deadlock XML isn’t technically wrong either. The isolation level for the transaction is read committed, but the query is asking for more.
The problem is obvious when the query hints are right in front of you, but sometimes people will bury hints down in things like views or functions, and it makes life a little bit more interesting.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
When you have queries that need to process a lot of data, and probably do some aggregations over that lot-of-data, batch mode is usually the thing you want.
Originally introduced to accompany column store indexes, it works by allowing CPUs to apply instructions to up to 900 rows at a time.
It’s a great thing to have in your corner when you’re tuning queries that do a lot of work, especially if you find yourself dealing with pesky parallel exchanges.
Oh, Yeah
One way to get that to happen is to use a temp table with a column store index on it.
SELECT
v.UserId,
SUM(v.BountyAmount) AS SumBounty
FROM dbo.Comments AS c
JOIN dbo.Votes AS v
ON v.PostId = c.PostId
AND v.UserId = c.UserId
GROUP BY v.UserId
ORDER BY SumBounty DESC;
CREATE TABLE #t(id INT, INDEX c CLUSTERED COLUMNSTORE);
SELECT
v.UserId,
SUM(v.BountyAmount) AS SumBounty
FROM dbo.Comments AS c
JOIN dbo.Votes AS v
ON v.PostId = c.PostId
AND v.UserId = c.UserId
LEFT JOIN #t AS t
ON 1 = 0
GROUP BY v.UserId
ORDER BY SumBounty DESC;
If you end up using this enough, you may just wanna create a real table to use, anyway.
Remarkable!
If we look at the end (or beginning, depending on how you read your query plans) just to see the final times, there’s a pretty solid difference.
you can’t make me
The first query takes around 10 seconds, and the second query takes around 4 seconds. That’s a pretty handsome improvement without touching anything else.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
You have too many indexes on too many tables already, and the thought of adding more fills you with a dread that has a first, middle, last, and even a confirmation name.
This is another place where temp tables can save your bacon, because as soon as the query is done they basically disappear.
Forever. Goodbye.
Off to buy a pack of smokes.
That Yesterday
In yesterday’s post, we looked at how a temp table can help you materialize an expression that would otherwise be awkward to join on.
If we take that same query, we can see how using the temp table simplifies indexing.
SELECT
p.OwnerUserId,
SUM(p.Score) AS TotalScore,
COUNT_BIG(*) AS records,
CASE WHEN p.PostTypeId = 1
THEN p.OwnerUserId
WHEN p.PostTypeId = 2
THEN p.LastEditorUserId
END AS JoinKey
INTO #Posts
FROM dbo.Posts AS p
WHERE p.PostTypeId IN (1, 2)
AND p.Score > 100
GROUP BY CASE
WHEN p.PostTypeId = 1
THEN p.OwnerUserId
WHEN p.PostTypeId = 2
THEN p.LastEditorUserId
END,
p.OwnerUserId;
CREATE CLUSTERED INDEX c ON #Posts(JoinKey);
SELECT *
FROM #Posts AS p
WHERE EXISTS
(
SELECT 1/0
FROM dbo.Users AS u
WHERE p.JoinKey = u.Id
);
Rather than have to worry about how to handle a bunch of columns across the where and join and select, we can just stick a clustered index on the one column we care about doing anything relational with to get the final result.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
A lot of the time when I see queries that are written with all sorts of gymnastics in the join or where clause and I ask some questions about it, people usually start complaining about the design of the table.
That’s fine, but when I ask about changing the design, everyone gets quiet. Normalizing tables, especially for Applications Of A Certain Age™ can be a tremendously painful project. This is why it’s worth it to get things right the first time. Simple!
Rather than make someone re-design their schema in front of me, often times a temp table is a good workaround.
Egg Splat
Let’s say we have a query that looks like this. Before you laugh, and you have every right to laugh, keep in mind that I see queries like this all the time.
They don’t have to be this weird to qualify. You can try this if you have functions like ISNULL, SUBSTRING, REPLACE, or whatever in joins and where clauses, too.
SELECT
p.OwnerUserId,
SUM(p.Score) AS TotalScore,
COUNT_BIG(*) AS records
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON u.Id = CASE
WHEN p.PostTypeId = 1
THEN p.OwnerUserId
WHEN p.PostTypeId = 2
THEN p.LastEditorUserId
END
WHERE p.PostTypeId IN (1, 2)
AND p.Score > 100
GROUP BY p.OwnerUserId;
There’s not a great way to index for this, and sure, we could rewrite it as a UNION ALL, but then we’d have two queries to index for.
Sometimes getting people to add indexes is hard, too.
People are weird. All day weird.
Steak Splat
You can replace it with a query like this, which also allows you to index a single column in a temp table to do your correlation.
SELECT
p.OwnerUserId,
SUM(p.Score) AS TotalScore,
COUNT_BIG(*) AS records,
CASE WHEN p.PostTypeId = 1
THEN p.OwnerUserId
WHEN p.PostTypeId = 2
THEN p.LastEditorUserId
END AS JoinKey
INTO #Posts
FROM dbo.Posts AS p
WHERE p.PostTypeId IN (1, 2)
AND p.Score > 100
GROUP BY CASE
WHEN p.PostTypeId = 1
THEN p.OwnerUserId
WHEN p.PostTypeId = 2
THEN p.LastEditorUserId
END,
p.OwnerUserId;
SELECT *
FROM #Posts AS p
WHERE EXISTS
(
SELECT 1/0
FROM dbo.Users AS u
WHERE p.JoinKey = u.Id
);
Remember that temp tables are like a second chance to get schema right. Don’t waste those precious chances.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
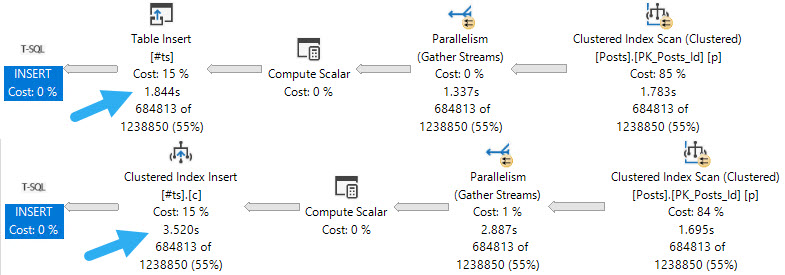
If you have a workload that uses #temp tables to stage intermediate results, and you probably do because you’re smart, it might be worth taking advantage of being able to insert into the #temp table in parallel.
If your code is already using the SELECT ... INTO #some_table pattern, you’re probably already getting parallel inserts. But if you’re following the INSERT ... SELECT ... pattern, you’re probably not, and, well, that could be holding you back.
Pile On
Of course, there are some limitations. If your temp table has indexes, primary keys, or an identity column, you won’t get the parallel insert no matter how hard you try.
The first thing to note is that inserting into an indexed temp table, parallel or not, does slow things down. If your goal is the fastest possible insert, you may want to create the index later.
No Talent
When it comes to parallel inserts, you do need the TABLOCK, or TABLOCKX hint to get it, e.g. INSERT #tp WITH(TABLOCK) which is sort of annoying.
But you know. It’s the little things we do that often end up making the biggest differences. Another little thing we may need to tinker with is DOP.
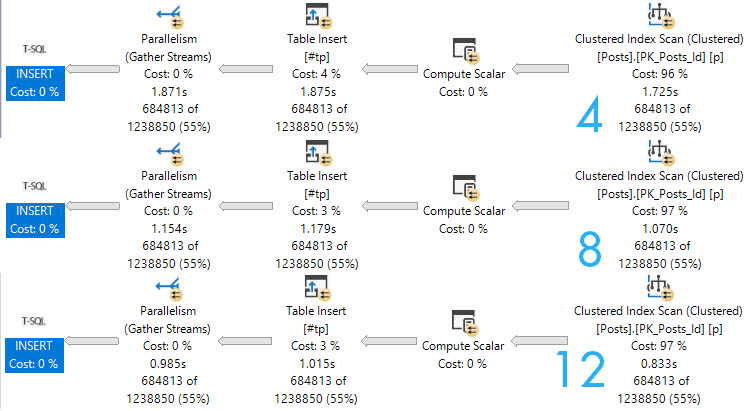
little pigs
Here are the query plans for 3 fully parallel inserts into an empty, index-less temp #table. Note the execution times dropping as DOP increases. At DOP 4, the insert really isn’t any faster than the serial insert.
If you start experimenting with this trick, and don’t see noticeable improvements at your current DOP, you may need to bump it up to see throughput increases.
Though the speed ups above at higher DOPs are largely efficiency boosters while reading from the Posts table, the speed does stay consistent through the insert.
If we crank one of the queries that gets a serial insert up to DOP 12, we lose some speed when we hit the table.
oops
Next time you’re tuning a query and want to drop some data into a temp table, you should experiment with this technique.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.