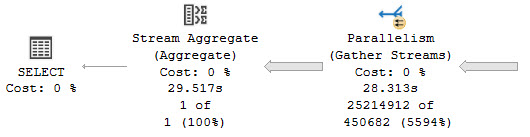I have sort of a love/hate relationship with wait stats scripts and analysis. Sometimes they’re great to correlate with larger performance problems or trends, and other times they’re totally useless.
When you’re looking at wait stats, some important things to figure out are:
How much of a wait happened compared to uptime
If the waits lasted a long time on average
And you can do that out of the box with SQL Server. What you can’t get are two very important things:
When the waits happened
Which queries caused the waits
This stuff is vitally important for figuring out if wait stats are benign overall to the workload.
For example, let’s say your server has been up for 100 hours, and you spent 50 hours waiting on PAGEIOLATCH_SH waits. Normally I’d be pretty worried about that, and I’d be looking at if the server has enough memory, if queries are asking for big memory grants, if important queries are missing any indexes, etc.
But if we knew that all 50 of those hours were outside of normal use activity, and maybe even happened in a separate database for warehousing or archiving off data, we might be able to ignore it and focus on other portions of the workload.
When this finishes running, you’ll get three results back:
Overall wait stats for the period of time
Wait stats broken down by database for the period of time
Wait stats broken down by database and query for the period of time
And because I don’t want to leave you hanging, you’ll also get details about the waits themselves, like
How much of a wait happened compared to sampled time
How long the waits lasted on average in the sampled time
If you need to figure out which queries are causing wait stats that you’re worried about, this is a great way to get started with that investigation.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
This is just a quick post to list out new wait stats in SQL Server 2022. How many will be useful, time will tell.
Some waits that I think might be interesting:
CXSYNC_CONSUMER (Currently in Azure)
CXSYNC_PORT (Currently in Azure)
PARALLEL_DB_SEEDING_SEMAPHORE
PLPGSQL
It looks like maybe automatic seeding for Availability Groups is getting the ability to process multiple databases at once, and we’re getting some parallel query waits that used to be Azure only.
I’m really scratching my head about PLPGSQL though. That’s the “programming language” that Postgres supports, which is sort of like what Oracle supports.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Memory is S-Tier crucial for most workloads to run reliably fast. It’s where SQL Server caches data pages, and it’s what it gives to queries to process Sorts and Hashes (among other things, but these are most common).
Without it, those two things, and many other caches, would be forced to live on disk. Horrible, slow disk. Talk about a good way to make databases less popular, eh?
With no offense to the SAN administrators of the world, I consider it my sworn duty to have databases avoid your domain as much as possible.
In this post, we’ll talk about how to figure out if your SQL Server needs more memory, and if there’s anything you can do to make better use of memory at the same time.
After all, you could be doing just fine.
(You’re probably not.)
Tale Of The Wait Stats
You can look at wait stats related to memory and query performance by running sp_PressureDetector.
It’ll give you some details about wait stats that relate to CPU and memory pressure. You wanna pay attention to the memory and disk waits, here. I had to squish it a little, but if you’re unfamiliar you can use the “description” column to better understand which ones to pay attention to.
Some important metrics to note here:
How do wait times relate to server uptime?
How long on average do we wait on each of these?
This won’t tell the whole story, of course, but it is a reasonable data point to start with. If your workload isn’t a 24×7 slog, though, you might need to spend more time analyzing waits for queries as they run.
In this example, it’s my local SQL instance, so it hasn’t been doing much work since I restarted it. Sometimes, you gotta look at what queries that are currently running are waiting on.
For that, go grab sp_WhoIsActive. If you see queries constantly waiting on stuff like this, it might be a sign you need more memory, because you have to keep going out to disk to get what queries need to use.
telling myself
It could also be a sign of other things, like queries and indexes that need tuning, but if it’s sustained like this then that’s not entirely likely.
It’s much more likely a memory deficiency, but it’s up to you to investigate further on your system.
How Is SQL Server Using Memory Now?
Current memory utilization can be a good way to find out if other things are using memory and taking valuable space away from your buffer pool.
A lot of folks out there don’t realize how many different things SQL Server has to share memory across.
And, hey, yeah, sp_PressureDetector will show you that, too. Here’s a “normal” run:
SQL Server’s buffer pool is uninfringed upon by other consumers! Great. But sometimes queries ask for memory grants, and that’s where things can get perilous.
i feel good
You may sometimes see Ye Olde First Memory Bank Of Motherboard loan out a swath to one or more queries:
dramarama
The difference here? The buffer pool is reduced by ~9GB to accommodate a query memory grant.
sp_PressureDetector will show you the queries doing that, too, along with query plans.
everyone is gone
It’ll also show you memory available in resource pools for granting out to queries. On this server, Max Server Memory is set to 50GB.
If you’re shocked that SQL Server is willing to give out 37GB of that to query memory grants, you haven’t been hanging around SQL Server long enough.
Then there’s a pretty good chance that it does, especially if data just plain outpaces memory by a good margin (like 3:1 or 4:1 or more).
You also have some options for making better use of your current memory, too.
Check critical queries for indexing opportunities (there may not always be a missing index request, but seasoned query tuners can spot ones the optimizer doesn’t)
Apply PAGE compression to existing row store indexes to make them smaller on disk and in memory
Check the plan cache for queries asking for large memory grants, but not using all of what’s granted to them
You can check the plan cache using a query like this. It’ll look for queries that ask for over 5GB of memory, and don’t use over 1GB of it.
WITH
unused AS
(
SELECT TOP (100)
oldest_plan =
MIN(deqs.creation_time) OVER(),
newest_plan =
MAX(deqs.creation_time) OVER(),
deqs.statement_start_offset,
deqs.statement_end_offset,
deqs.plan_handle,
deqs.execution_count,
deqs.max_grant_kb,
deqs.max_used_grant_kb,
unused_grant =
deqs.max_grant_kb - deqs.max_used_grant_kb,
deqs.min_spills,
deqs.max_spills
FROM sys.dm_exec_query_stats AS deqs
WHERE (deqs.max_grant_kb - deqs.max_used_grant_kb) > 1024.
AND deqs.max_grant_kb > 5242880.
ORDER BY unused_grant DESC
)
SELECT
plan_cache_age_hours =
DATEDIFF
(
HOUR,
u.oldest_plan,
u.newest_plan
),
query_text =
(
SELECT [processing-instruction(query)] =
SUBSTRING
(
dest.text,
( u.statement_start_offset / 2 ) + 1,
(
(
CASE u.statement_end_offset
WHEN -1
THEN DATALENGTH(dest.text)
ELSE u.statement_end_offset
END - u.statement_start_offset
) / 2
) + 1
)
FOR XML PATH(''),
TYPE
),
deqp.query_plan,
u.execution_count,
u.max_grant_kb,
u.max_used_grant_kb,
u.min_spills,
u.max_spills,
u.unused_grant
FROM unused AS u
OUTER APPLY sys.dm_exec_sql_text(u.plan_handle) AS dest
OUTER APPLY sys.dm_exec_query_plan(u.plan_handle) AS deqp
ORDER BY u.unused_grant DESC
OPTION (RECOMPILE, MAXDOP 1);
This will get you the top (up to!) 100 plans in the cache that have an unused memory grant, ordered by the largest difference between grant and usage.
What you wanna pay attention to here:
How old the plan cache is: if it’s not very old, you’re not getting the full picture
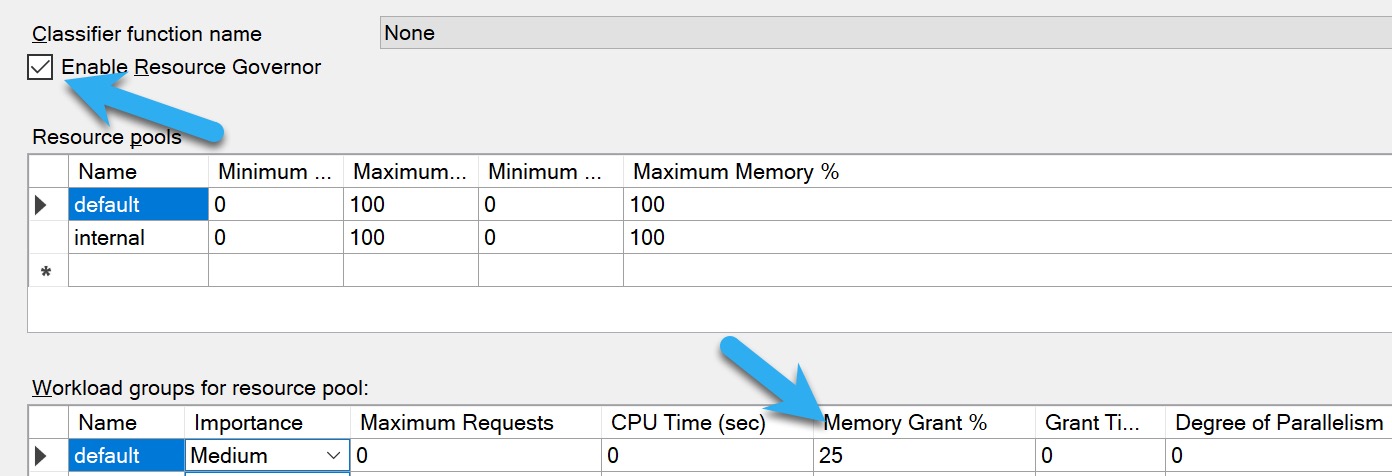
How big the memory grants are: by default, the max is ~25% of max server memory
Controlling Memory Grants
If you’re looking for ways to control memory grants that doesn’t involved a bunch of query and index tuning, you have a few options:
Resource Governor: Enterprise Edition only, and usually applies to the whole workload
MIN_GRANT_PERCENT and MAX_GRANT_PERCENT query hints: You usually wanna use both to set a proper memory grant, just setting an upper level isn’t always helpful
Batch Mode Memory Grant Feedback: Requires Batch Mode/Columnstore, only helps queries between executions, usually takes a few tries to get right
For Resource Governor, you’ll wanna do some analysis using the query in the previous section to see what a generally safe upper limit for memory grants is. The more memory you have, and the higher your max server memory is, the more insane 25% is.
signs and numbers
Again, just be cautious here. If you change this setting based on a not-very-old plan cache, you’re not gonna have a clear pictures of which queries use memory, and how much they use. If you’re wondering why I’m not telling you to use Query Store for this, it’s because it only logs how much memory queries used, not how much they asked for. It’s pretty ridiculous.
After you make a change like this, or start using those query hints, you’ll wanna do some additional analysis to figure out if queries are spilling to disk. You can change the query above to something like this to look at those:
WITH
unused AS
(
SELECT TOP (100)
oldest_plan =
MIN(deqs.creation_time) OVER(),
newest_plan =
MAX(deqs.creation_time) OVER(),
deqs.statement_start_offset,
deqs.statement_end_offset,
deqs.plan_handle,
deqs.execution_count,
deqs.max_grant_kb,
deqs.max_used_grant_kb,
unused_grant =
deqs.max_grant_kb - deqs.max_used_grant_kb,
deqs.min_spills,
deqs.max_spills
FROM sys.dm_exec_query_stats AS deqs
WHERE deqs.min_spills > (128. * 1024.)
ORDER BY deqs.max_spills DESC
)
SELECT
plan_cache_age_hours =
DATEDIFF
(
HOUR,
u.oldest_plan,
u.newest_plan
),
query_text =
(
SELECT [processing-instruction(query)] =
SUBSTRING
(
dest.text,
( u.statement_start_offset / 2 ) + 1,
(
(
CASE u.statement_end_offset
WHEN -1
THEN DATALENGTH(dest.text)
ELSE u.statement_end_offset
END - u.statement_start_offset
) / 2
) + 1
)
FOR XML PATH(''),
TYPE
),
deqp.query_plan,
u.execution_count,
u.max_grant_kb,
u.max_used_grant_kb,
u.min_spills,
u.max_spills,
u.unused_grant
FROM unused AS u
OUTER APPLY sys.dm_exec_sql_text(u.plan_handle) AS dest
OUTER APPLY sys.dm_exec_query_plan(u.plan_handle) AS deqp
ORDER BY u.max_spills DESC
OPTION (RECOMPILE, MAXDOP 1);
Small spills aren’t a big deal here, but you’ll definitely wanna pay attention to larger ones. This is set to find ones that are over 1GB, which is still pretty small, but could be meaningful.
If you notice a lot more queries spilling in a substantial way, you may have capped the high end of query memory grants too low.
Recap
Memory is something that I see people struggle to right-size, forecast, and understand the physics of in SQL Server. The worst part is that hardly anything in this post applies to Standard Edition, which is basically dead to me.
The cap for the buffer pool is 128GB, but you can use memory over that for other stuff
The main things to keep an eye on are:
Wait stats overall, and for running queries
Large unused memory grants in the plan cache
Size of data compared to size of memory
If you need help with this sort of thing, hit the link below to drop me a line about consulting.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Upon reading the title, you may be thinking that of course parallel scans will be slow in the cloud. Cloud storage storage simply isn’t very fast. I would argue that there’s a bit more to it.
The Timeout
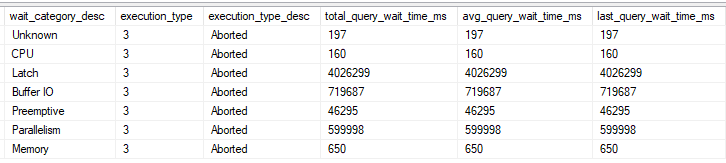
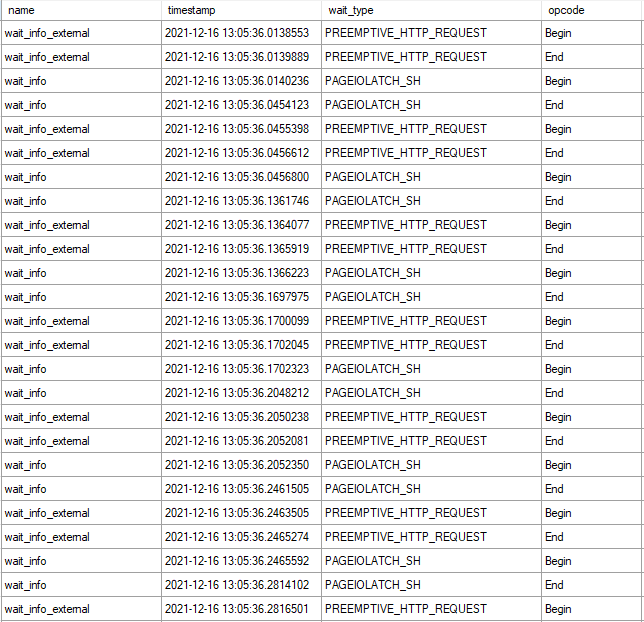
A query timed out the other day in production after running for 600 seconds. Of note, one of the tables used by the stored procedure is in a database with data files hosted by Azure blob storage. I grabbed the wait stats for the timed out query using query store:
According to the documentation, the latch category maps to LATCH_% wait types and the preemptive category maps to PREEMPTIVE_% wait types. I wasn’t able to reproduce the timeout when executing the same query text, even if I forced the exact same query plan with a USE PLAN. Admittedly, I was puzzled by the wait stats distribution for a while.
Decoding the Categories
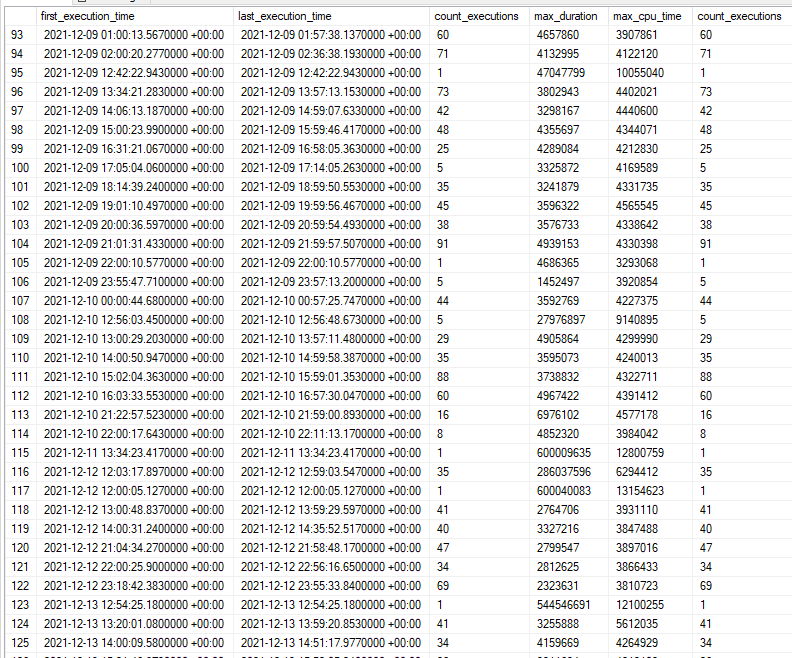
I eventually realized that typically the first execution of the stored procedure for the business day tended to be the slowest. Sorting query store runtime DMV results by time:
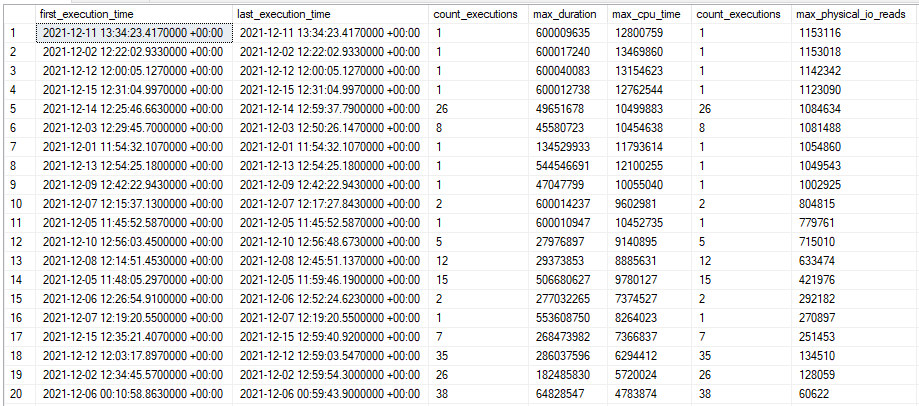
I also noticed that the timed out executions tended to have higher physical I/O than the other executions. Sorting query store runtime DMV results by I/O:
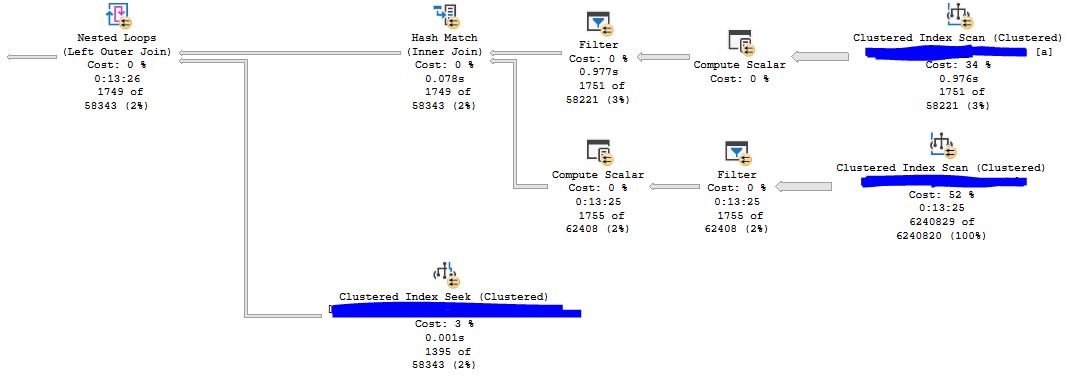
I now finally had a method to reproduce the poor performance of the stored procedure: being the first one to run the code in the morning, presumably when the buffer pool didn’t have anything helpful for this stored procedure. Early in the morning, I was able to capture an actual plan that took 13 minutes at MAXDOP 8. Nearly all of the execution time is spent on an index scan for a table that is hosted on cloud storage:
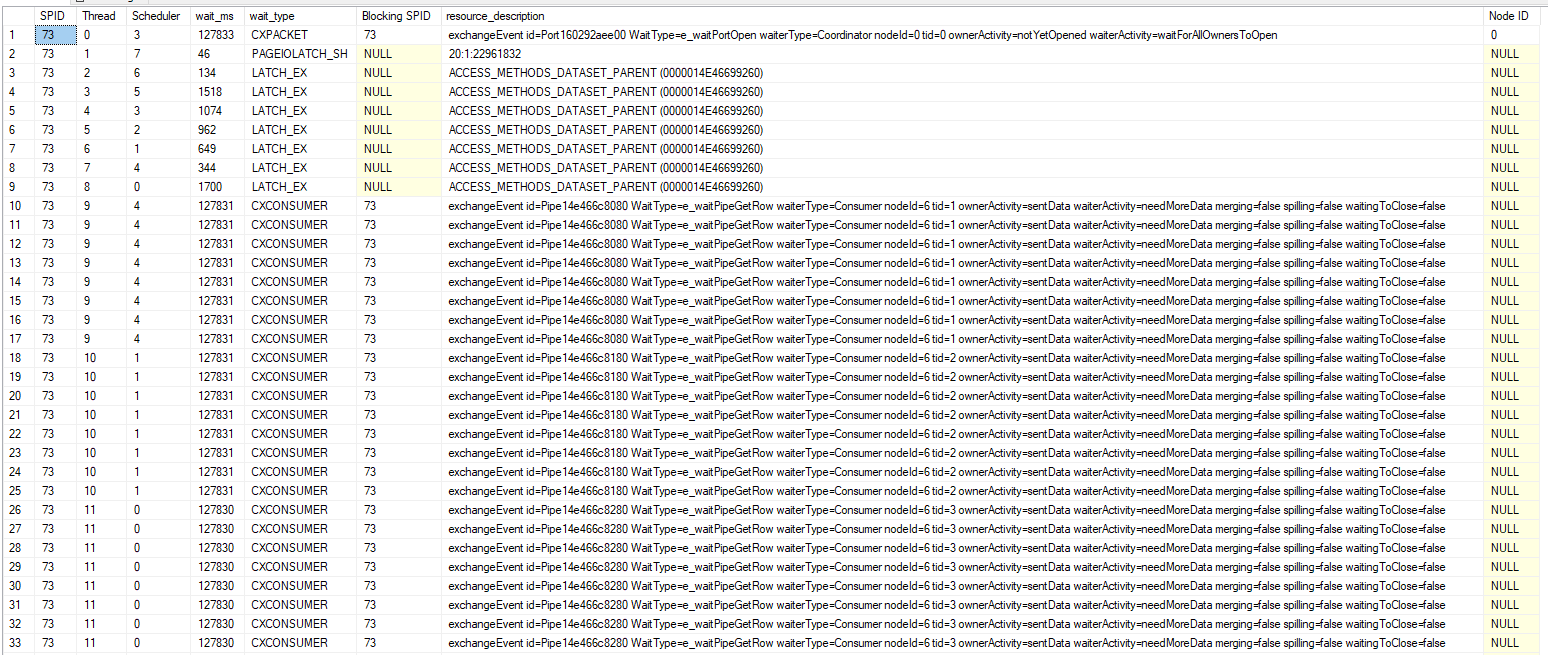
I used the task DMVs during query execution to get information about the latch type:
Now I know that the query spends most of its time trying to acquire exclusive latches of the ACCESS_METHODS_DATASET_PARENT type. There is also a fair amount of I/O wait time compared to the mysterious PREEMPTIVE_HTTP_REQUEST wait type.
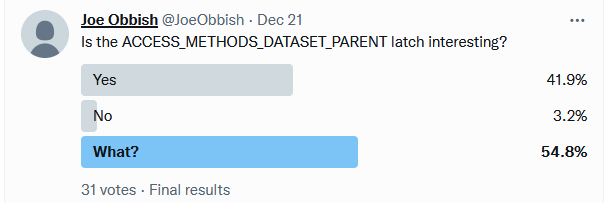
The ACCESS_METHODS_DATASET_PARENT Latch
I asked the community if this latch was considered to be interesting. The winning option was “What?”. As usual, twitter is useless:
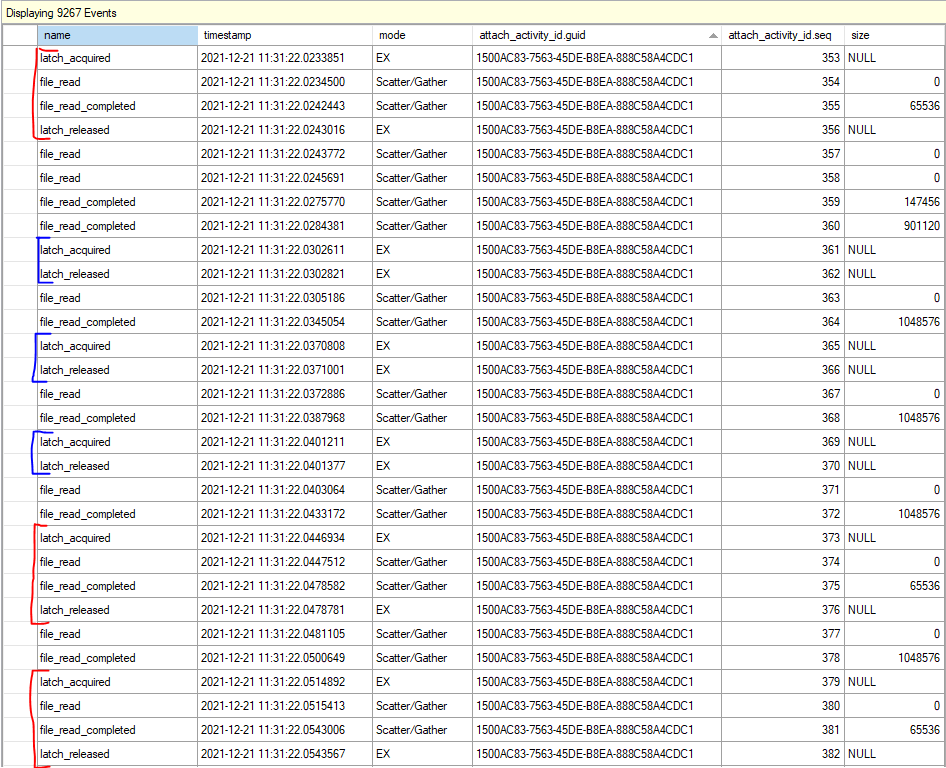
For my query, at times I observed seven out of eight worker threads all waiting for an exclusive latch at the same time. This isn’t surprising considering that the query averaged 6.7 LATCH_EX wait seconds per second. That the other thread was doing an I/O wait while the others were waiting for the latch, so perhaps the worker threads were doing I/Os while holding the latch resource. On a development environment (with unfortunately significantly better I/O), I mocked up a roughly similar table and enabled the latch_acquired, latch_released, file_read, and file_read_completed extended events. The results were quite educational:
There were two different patterns in the XE files. Sometimes the worker threads would acquire the latch, perform one or more I/Os, and release the latch. Otherwise they would acquire the latch and quickly release it without performing any I/Os. Paul Randal recently wrote the following about this latch:
When either a heap or an index is being accessed, internally there’s an object called a HeapDataSetSession or IndexDataSetSession, respectively. When a parallel scan is being performed, the threads doing the actual work of the scan each have a “child” dataset (another instance of the two objects I just described), and the main dataset, which is really controlling the scan, is called the “parent.”
When one of the scan worker threads has exhausted the set of rows it’s supposed to scan, it needs to get a new range by accessing the parent dataset, which means acquiring the ACCESS_METHODS_DATASET_PARENT latch in exclusive mode. While this can seem like a bottleneck, it’s not really, and there’s nothing you can do to stop the threads performing a parallel scan from occasionally showing a LATCH_EX wait for this latch.
At a very high level, I suspect that the fast latch releases (marked in blue in the above picture) occur when the worker thread can acquire an already available range of rows from the parent object. The slow latch releases (marked in red) occur when the worker thread tries to acquire a new range, can’t find one, and has to perform I/Os to add more ranges to the parent object. In both cases the parent object needs to be modified, so an exclusive latch is always taken. I don’t know how it actually works behind the scenes, but the theory matches the observed behavior.
In summary, the query does a parallel scan which is protected by the ACCESS_METHODS_DATASET_PARENT latch. The table getting scanned is hosted on cloud storage with high I/O latency. Latency being high contributes to the exclusive latch on ACCESS_METHODS_DATASET_PARENT getting held for a long time which can block all of the other parallel worker threads from proceeding.
The PREEMPTIVE_HTTP_REQUEST Wait Type
I already have enough information to be confident in a query tuning fix for the stored procedure, but for completeness, I also investigated the PREEMPTIVE_HTTP_REQUEST wait type. I was not able to find any useful documentation for this wait type. The official documentation only says “Internal use only.” Thanks, Microsoft.
A common technique to learn more about undocumented waits is to get callstacks associated with the wait type. I’ve seen the PREEMPTIVE_HTTP_REQUEST wait occur in Azure SQL databases, Azure SQL Managed Instances, and for databases hosted in Azure blob storage. It is possible to get callstacks for managed instances, but it is not possible to translate them because Microsoft does not release public symbols for managed instances. However, the blob storage scenario did allow me to get and translate call stacks for the wait. Below are a few of the stacks that I captured:
Performing I/Os to read data not in the buffer pool:
I’m guessing this one is renewing the lease as noted in the documentation: “the implementation of SQL Server Data Files in Azure Storage feature requires a renewal of blob lease every 45 to 60 seconds implicitly”
Not surprisingly, all of them have to do with accessing azure storage. I was able to observe an interesting pattern during a table scan: every PAGEIOLATCH_SH wait was immediately preceded by a PREEMPTIVE_HTTP_REQUEST wait.
Getting stacks for the waits that are close together, with shared code removed and the I/O wait on top with the preemptive wait on the bottom:
My understanding is that SQL Server makes an HTTP request to the blob storage in preemptive mode in order to queue an asynchronous I/O. The preemptive wait ends and the PAGEIOLATCH_SH wait begins shortly after. The traditional I/O wait ends when the I/O is received by SQL Server. That’s just a guess though.
I think a reasonable summary is that you should expect to see PREEMPTIVE_HTTP_REQUEST waits if you’re performing I/O against Azure storage. They are a normal part of SQL Server’s operations.
Reducing ACCESS_METHODS_DATASET_PARENT Latch Wait Time
In some situations, a query that is slow due to I/O performance can run faster with a higher DOP. Instead of one thread waiting for I/O you can have many threads waiting and overall runtime will decrease. Of course, this won’t work in all scenarios, such as if you’re hitting an IOPs limit. For my scenario, the DOP 8 query had 6.7 LATCH_EX wait seconds per second of runtime. Latch contention is so bad that it nearly steals all of the theoretical benefits achieved with query parallelism.
The obvious solution is to reduce the amount of I/O that is done by the query. That is what was indeed done to resolve the production issue. Another obvious solution is to improve I/O performance. More on that in the next section. However, in some cases the query may simply need to scan a lot of data and you can’t do anything about storage performance. In that situation, it may sometimes be practical to change the type of parallel scan performed by SQL Server.
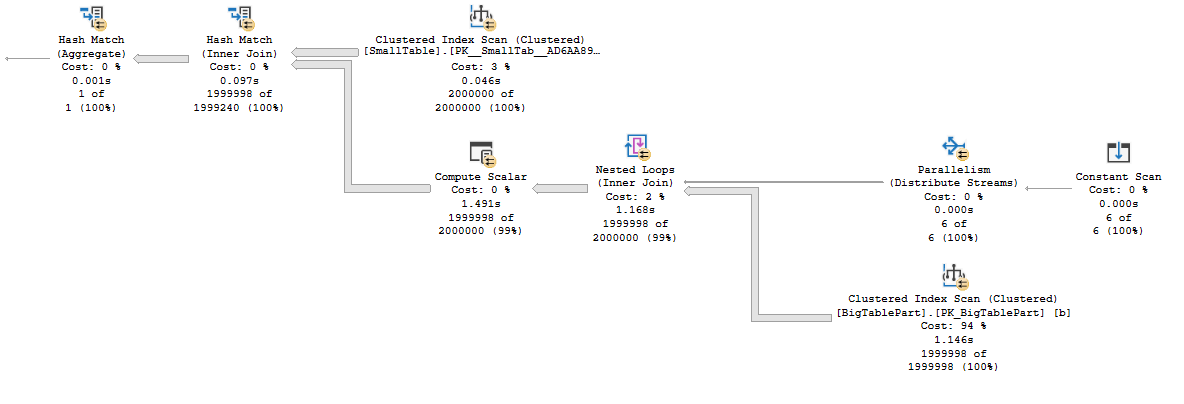
Consider the following parallel plan against a partitioned table on the probe side:
For clarity, here is what the T-SQL looks like:
SELECT SUM(Case WHEN OffPageFiller IS NOT NULL THEN 1 ELSE 0 END)
FROM (
VALUES (1),(2),(3),(4),(5),(6)
) v(v)
CROSS APPLY(
SELECT OffPageFiller
FROM dbo.SmallTable s
INNER JOIN dbo.BigTablePart b ON s.JoinId = b.JoinId
WHERE b.PartId = v.v
) q;
Each thread of the parallel nested loop operator gets assigned an entire partition and reads all of the data for that partition. There is no longer a need for the ACCESS_METHODS_DATASET_PARENT latch because the shared state between worker threads has been removed. I checked using extended events and found that the ACCESS_METHODS_DATASET_PARENT latch wait count was significantly decreased as expected. I suspect that the remaining latch acquisitions were from the hash build side scan. This type of access pattern requires a partitioned table, can be a pain to express in T-SQL, and may not work well if partitions are unevenly sized or if there aren’t enough partitions compared to DOP to get good demand-based distribution.
Perhaps a more reasonable option is to switch to columnstore instead. The query will do less I/O and I assume that the latch pattern is quite different, but I didn’t test this. Testing things in the cloud costs money. Maybe I should start a Patreon.
Reducing PREEMPTIVE_HTTP_REQUEST Wait Time
As I said earlier, I believe that seeing this wait is normal if you’re using azure storage. In my limited experience with it, any noticeable wait time was always tied to even longer PAGEIOLATCH waits. Tuning the query using traditional methods to reduce I/O wait time was always sufficient and I never had a need to specifically focus on PREEMPTIVE_HTTP_REQUEST. However, if you really need to focus on this wait type in particular for some reason, I’ll theorize some ways to reduce it:
For all platforms, reduce I/O performed by the query using query tuning, schema changes, and so on.
For managed instances, move your I/O from user databases to tempdb (it uses locally attached storage).
For azure blob storage databases, make sure that you are using the right geographical region for your storage.
Here are a few more options which may not specifically reduce PREEMPTIVE_HTTP_REQUEST wait time but may improve I/O performance overall:
The query timed out in production because it performed a large parallel scan against a table that had little to no data in the buffer pool. PAGEIOLATCH waits were not the dominant wait type due to high latency from Azure blob storage. That high latency caused latch contention on the ACCESS_METHODS_DATASET_PARENT latch. My parallel scan was slow because cloud storage isn’t very fast. Maybe it isn’t so complicated after all?
Most of these signs have to do with wait stats. One could venture out and say that if you have way less memory than data, you need more memory, but… If the server is sitting around bored, who cares?
If we’re going to spend money on memory, let’s make sure it’ll get used. When I’m talking to people with performance problems that memory would solve, here are some of the top reasons.
You’re In The Cloud Where Storage Sucks
Okay, okay, storage can totally suck other places, too. I’ve seen some JBOD setups that would make you cry, and some of them weren’t in the cloud. Where you need to differentiate a little bit here is that memory isn’t going to help slow writes directly. If you add a bunch more memory and free up some network bandwidth for writes by focusing the reads more from the buffer pool, it might.
Look, just avoid disk as much as possible and you’ll be happy.
You’re Using Column Store And/Or Batch Mode
Good column store compression can often rely on adequate memory, but you also need to account for the much larger memory grants that batch mode queries ask for. As more and more workloads move towards SQL Server 2019 and beyond, query memory needs are going to go up because Batch Mode On Row Store will become more common.
You’re Waiting On RESOURCE_SEMAPHORE A Lot
This wait shows up when a bunch of queries are contending for memory grants, but SQL Server has given out all it can. If you run into these a lot, it’s a pretty good sign you need more memory. Especially if you’ve already tuned queries and indexes a bunch, or you’re dealing with a vendor app where they refuse to fix anything.
Other things that might help? The MAX_GRANT_PERCENT hint or Resource Governor
You’re Waiting On RESOURCE_SEMAPHORE_QUERY_COMPILE A Lot
This is another “queue” wait, but it’s for query compilation rather than query execution. Having more memory can certainly help this quite a bit, but so can simplifying queries so that the amount of memory SQL Server has to throw at compiling them chills out a little. You can start by reconsidering those views nested 10 levels deep and the schema design that leads you to needing a 23 table join to construct one row.
You’re Waiting On PAGEIOLATCH_SH Or PAGEIOLATCH_EX A Lot
These waits show up when data pages your query needs aren’t already there. The more you see these, the more latency you’re adding to your workload by constantly shuffling out to disk to get them. Of course, there’s other stuff you can do, like clean up unused and overlapping indexes, compress your indexes, etc. But not everyone is comfortable with or able to do that.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I speak with a lot of DBAs and developers who have either heard nothing about column store and batch mode, or they’ve only heard the bare minimum and aren’t sure where it can help them.
Here’s a short list of reasons I usually talk through with people.
Your Reporting Queries Hit Big Tables
The bigger your tables get, the more likely you are to benefit, especially if the queries are unpredictable in nature. If you let people write their own, or design their own reports, nonclustered column store can be a good replacement for nonclustered row store indexes that were created specifically for reporting queries.
In row store indexes, index key column order matters quite a bit. That’s not so much the case with column store. That makes them an ideal data source for queries, since they can scan and select from column independently.
Your Predicates Aren’t Always Very Selective
Picture the opposite of OLTP. Picture queries that collect large quantities of data and (usually) aggregate it down. Those are the ones that get along well with column store indexes and batch mode.
If most of your queries grab and pass around a couple thousand rows, you’re not likely to see a lot of benefit, here. You wanna target the ones with the big arrows in query plans.
Your Main Waits Are I/O And CPU
If you have a bunch of waits on blocking or something, this isn’t going to be your solve.
When your main waits are CPU, it could indicate that queries are overall CPU-bound. Batch mode is useful here, because for those “big” queries, you’re passing millions of rows around and making SQL Server send each one to CPU registers. Under batch mode, you can send up to 900 at a time. Just not in Standard Edition.
When your main waits are on I/O — reading pages from disk specifically — column store can be useful because of the compression they offer. It’s easy to visualize reading more compact structures being faster, especially when you throw in segment and column elimination.
Your Query Plans Have Some Bad Choices In Them
SQL Server 2019 (Enterprise Edition) introduced Batch Mode On Row Store, which let the optimizer heuristically select queries for Batch Mode execution. With that, you get some cool unlocks that you used to have to trick the optimizer into before 2019, like adaptive joins, memory grant feedback, etc.
While those things don’t solve every single performance issue, they can certainly help by letting SQL Server be a little more flexible with plan choices and attributes.
The Optimizer Keeps Choosing Cockamamie Parallel Sort Merge Plans That Make No Sense And Force You To Use Hash Join Hints All The Time
🤦♂️
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
As a counterpart to yesterday’s post, I have a list of Great Ideas™ that sometimes it’s hard to get people on board with, for some reason.
Don’t get me wrong, some people can’t jump on this stuff fast enough — I’ve had people take “unscheduled maintenance” during engagements to flip the right switches — but other times there’s a hem and a haw and a whole lot of’em to go along with the plan.
Somehow people who have auto close and Priority Boost turned on and haven’t checked for corruption since 30 Rock went off the air want a full-bore fisking of every change and every assurance that no edge case exists that could ever cross their path.
Okay pal. You go on with your bad 2012 RTM self.
Lock Pages In Memory
“Please don’t pop my balloon animals.”
To say that this setting only lets SQL Server hang onto memory is a grand injustice. It also lets SQL Server use completely different APIs to access memory through Windows, including skipping over virtual memory space. That can be an awesome benefit for servers with gobs of memory.
What are people worried about, here? Usually some article they read about balloon drivers in 2011, or something.
But the same people aren’t afraid to set min server memory to max server memory, and then wonder why they have no plan cache.
I love this setting though, and if you can also get away with turning on trace flag 834, there are some nice additional benefits.
DBCC CHECKDB
“Well, our index maintenance job runs for 9 hours, so we don’t have time for this. Besides, won’t it cause a lot of blocking?”
Lord have mercy, the foot dragging on this. Part of your job as a DBA is to keep data safe and backed up. Running CHECKDB is part of that.
No DBA got fired over fragmented indexes. More than a few have for data going corrupt.
Granted, this can get a little more complicated for really big databases. Some people break it up into different steps, and other people offload the process.
Some third party backup tools from vendors like Quest and Red Gate allow you to automate processes like that, too. Full backup, restore to new server, run CHECKDB, tell us what happened.
How nice, you get a tested restore, too.
Query Store
“Won’t this catch my server on fire and leak PII to hackers?”
If you’re too cheap to spring for a proper monitoring tool, Query Store makes a pretty okay pseudo replacement. Especially in 2017 and up where you can track wait stats too, you can get some pretty good insights out of it.
Microsoft has also gotten pretty smart about better default settings for this thing, and in 2019 you have more knobs to set smarter standards for which plans get tracked in there.
It’d be really nice if you could choose to ignore queries, too, but you know. Can’t always get what you want, there.
I’d much rather look at Query Store than that unreliable old plan cache, too.
Read Committed Snapshot Isolation
“Why do I want tempdb to be full of old data?”
Remember yesterday? Me either. Nothing good happened, anyway. Do you remember what that row looked like before the update started? No?
Read Committed Snapshot Isolation does. And it wants you to, too. This setting solves so many dumb problems that people run headlong into because Microsoft committed to a garbage isolation level.
One complaint I hear all the time is that a particular application runs a lot better on Oracle with no other changes. This setting is usually the reason why: It’s not turned on.
Once you turn it on, reader/writer blocking and deadlocking goes away, and you don’t need to add a SSMS keyboard shortcut that inserts WITH NOLOCK.
Changing Indexes
“They’re fine the way they are, trust me. That burning smell is another server.”
Index tuning needs to be a process that starts with cleaning up indexes, and ends with adding in better ones.
What makes an index bad? When it’s unused, and/or duplicative.
What makes an index good? When it gets read from more than it’s written to, and it’s a usefully different way for queries to access data.
There are other index anti-patterns that are good to look for too, like lots of single key column indexes, but they usually get cleaned up when you start merging duplicates.
There’s a near fully eclipsed Venn Diagram of people who are worried about having too many indexes and people who have never dropped an index in their career.
Talk, Talk
These are the kinds of changes and processes people should be comfortable with making when they work with SQL Server.
Sure, there are a ton of others, but some of them have become part of the installer and get a little more leeway — parallelism settings, instant file initialization, tempdb etc. — I only wish that more of this stuff would follow suit.
One wonders quite loudly why setting MAXDOP made it into the installer, but setting Cost Threshold For Parallelism did not.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
No one ever says a broken record is right twice a day, perhaps because DJs are far more replaceable than clock makers.
I say that only to acknowledge that I may sound like a broken record when I say that when you’re tuning a query, it’s quite important to compare wall clock time and duration. Things you should note:
If CPU and duration were about equal in a serial plan, that’s normal
If CPU is much higher than duration in a parallel plan, that’s normal
If duration is much higher than CPU in any plan, something else held your query up
In this post, I’m going to outline a non-exhaustive list of reasons why that last bullet point just might be.
Hammer Time
Big Data: One common reason you may run into is that you’re returning a large result set, either locally to SSMS, or to an app server that is either overloaded or underpowered. It’s also possible that something is happening on the application side that’s slowing things down. In these cases, you’ll usually see a lot of ASYNC_NETWORK_IO waits. To better test the speed of the actual query, you can dump the results into a #temp table.
Blocking: Another quite common issue is that the query you’re running is getting blocked. Before you go reaching for that NOLOCK hint, make sure you know what it does. Blocking is each to check on with sp_WhoIsActive. If you see your query waiting on waits that start with LCK_ Some common ones are LCK_M_SCH_S, LCK_M_SCH_M, LCK_M_S, LCK_M_U, LCK_M_X, LCK_M_IS, LCK_M_IU, LCK_M_IX. While your query is being blocked, it’s just gonna rack up wall clock time, while using zero CPU.
Stats updates: Once in a while I’ll run into a query that runs slowly the first time and fast the second time because behind the scenes the query had to wait on stats to update. It’s a bit hard to figure out unless you’re on SQL Server 2019, but it can totally make your query look like you sat around doing nothing for a chunk of time, especially if you’re waiting on large tables, or a bunch of smaller updates.
Reading from disk: If the tables or indexes you’re reading are bigger than your buffer pool, your queries are gonna eat it going to disk to read data in. If this is your limitation, you’ll see a lot of PAGIOLATCH_SH or PAGEIOLATCH_EX waits, depending on if your query is reading data, writing data, or both.
Waiting for a worker thread: When your queries can’t get a worker thread to run on, they end up waiting on THREADPOOL. While some waits on it are to be expected, you don’t want queries to wait long periods of time on this. It’s a serious sign your server is jammed way up.
Waiting for memory: When your queries can’t get the memory grant they want, they sit around waiting on RESOURCE_SEMAPHORE. Just like above, it’s a sure sign your server is having problems if it’s a wait you see occurring a lot, or for long average periods of time.
Waiting for a query plan: I know, this sounds like a long compilation time — and it sort of is — but only because the query is waiting a long time to get memory to compile an execution plan. This wait is going to be RESOURCE_SEMAPHORE_QUERY_COMPILE, instead.
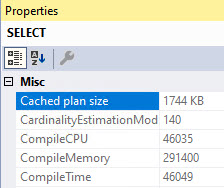
Query Plan Compilation: Sometimes the optimizer gets a bit carried away and spend a whole bunch of time in search2 trying to reorder joins, and do other tricks to make your query faster. Under extreme circumstances, you might wait a really long time for that query plan. There’s no wait stats to tell you that, but if you look at your query plan’s properties (F4 key on the root operator), you can see the compile time.
yeesh.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Whenever I see people using NOLOCK hints, I try to point out that they’re not a great idea, for various reasons explained in detail all across the internet.
At minimum, I want them to understand that the hint name is the same as setting the entire transaction isolation level to READ UNCOMMITTED, and that the hint name is quite misleading. It doesn’t mean your query takes no locks, it means your query ignores locks taken by other queries.
That’s how you can end up getting incorrect results.
That warning often comes with a lot of questions about how to fix blocking problems so you can get rid of those hints.
After all, if you get rid of them, your SQL Server queries will (most likely) go back to using the READ COMMITTED isolation level and we all know that read committed is a garbage isolation level, anyway.
Cause and Wrecked
An important thing to understand is why the hint was used in the first place. I’ve worked with some nice developers who slapped it on every query just in case.
There was no blocking or deadlocking. They just always used it, and never stopped.
Not that I blame them; the blocking that can occur under read committed the garbage isolation level is plain stupid, and no respectable database platform should use it as a default.
In many ways, it’s easier for a user to re-run a query and hopefully get the right result and shrug and mumble something about computers being awful, which is also true.
So, first step: ask yourself if there was ever really a blocking problem to begin with.
Bing Tutsby
Next, we need to understand where the blocking was coming from. Under read committed the garbage isolation level, writers can block readers, and readers can block writers.
In most cases though, people have added the hint to all of their queries, even ones that never participated in blocking.
If the problem was writers blocking writers, no isolation can help you.
If the problem was readers blocking writers, you may need to look at long running queries with Key Lookups
If the problem was writers blocking readers, you’d have to look at a few things:
Do they have good indexes in place to locate rows to update or delete?
If you have query store enabled, you can use sp_QuickieStore to search it for queries that do a lot of writes. If you don’t, you can use sp_BlitzCache to search the plan cache for them.
Best Case
Of course, you can avoid all of these problems, except for writers blocking writers, by using an optimistic isolation level like Read Committed Snapshot Isolation or Snapshot Isolation.
In the past, people made a lot of fuss about turning these on, because
You may not have tempdb configured correctly
You have queue type code that relied on blocking for correctness
But in reasonably new versions of SQL Server, tempdb’s setup is part of the install process, and the wacky trace flags you used to have to turn on are the default behavior.
If you do have code in your application that processes queues and relies on locking to correctly process them, you’re better off using locking hints in that code, and using an optimistic isolation level for the rest of your queries. This may also be true of triggers that are used to enforce referential integrity, which would need READCOMMITTEDLOCK hints.
The reason why they’re a much better choice than using uncommitted isolation levels is because rather than get a bunch of dirty reads from in-flight changes, you read the last known good version of the row before a modification started.
This may not be perfect, but it will prevent the absolute majority of your blocking headaches. It will even prevent deadlocks between readers and writers.
No, Lock
If your code has a lot of either NOLOCK hints or READ UNCOMITTED usage, you should absolutely be worried about incorrect results.
There are much better ways to deal with blocking, and I’ve outlined some of them in this post.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
When you’re looking for queries to tune, it’s important to understand which part is causing the slowdown.
That’s why Actual Execution plans are so valuable in newer versions of SQL Server and SSMS. Getting to see operator timing and wait stats for a query can tell you a lot about what kind of problem you’re facing.
Let’s take a look at some examples.
Diskord
If you’re looking at a query plan, and all the time is spent way to the right, when you’re reading from indexes, it’s usually a sign of one or two things:
You’re missing a good index for the query
You don’t have enough memory to cache data relevant to the query
If you run the query a second time, and it has the same characteristics — meaning we should now have the data cached in the buffer pool but we don’t — then one or both of those two things is true.
If you run the query a second time and it’s fast because all the data we care about is cached, then it’s more likely that only the second thing is true.
wasabi
For example, every time I run this query it takes 20 seconds because every time it has to read the clustered index from disk into memory to get a count. That’s because my VM has 96 GB of RAM, and the clustered index of the Posts table is about 120 GB. I can’t fit the whole thing into the buffer pool, so each time I run this query has the gas station sushi effect on the buffer pool.
If I add a nonclustered index — and keep in mind I don’t really condone adding single key column nonclustered indexes like this — the query finishes much faster, because the smaller nonclustered index takes less time to read, and it fits into the buffer pool.
CREATE INDEX pr ON dbo.Posts
(
Id
);
birthday
If our query had different characteristics, like a where clause, join, group by, order by, or windowing function, I’d consider all of those things for the index definition. Just grabbing a count can still benefit from a smaller index, but there’s nothing relational that we need to account for here.
Proc Rock
Let’s say you already have ideal indexes for a query, but it’s still slow. Then what?
There are lots of possible reasons, but we’re going to examine what a CPU bound query looks like. A good example is one that needs to process a lot of rows, though not necessarily return a lot of rows, like a count or other aggregate.
splish splash
While this query runs, CPUs are pegged like suburban husbands.
in the middle of the street
For queries of this stature, inducing batch mode is often the most logical choice. Why? Because CPU instructions are run over batches of rows at once, rather than a single row at a time.
With a small number of rows — like in an OLTP workload — you probably won’t notice any real gains. But for this query that takes many millions of rows and produces an aggregate, it’s Hammer Time™
known as such
Rather than ~30 seconds, we can get our query down to ~8 seconds without making a single other change to the indexes or written form.
Under Compression
For truly large data sets, compression indexes is a great choice for further reducing I/O bound portions of queries. In SQL Server, you have row, page, and column store (clustered and nonclustered) compression available to you based on the type of workload you’re running.
When you’re tuning a query, it’s important to keep the type of bottleneck you’re facing in mind. If you don’t, you can end up trying to solve the wrong problem and getting nowhere.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.