Last week’s thrilling, stunning, flawless episode of whatever-you-wanna-call-it.
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Indexes remind me of salt. And no, not because they’re fun to put on slugs.
More because it’s easy to tell when there’s too little or too much indexing going on. Just like when you taste food it’s easy to tell when there’s too much or too little salt.
Salt is also one of the few ingredients that is accepted across the board in chili.
To continue feeding a dead horse, the amount of indexing that each workload and system needs and can handle can vary quite a bit.
Appetite For Nonclustered
I’m not going to get into the whole clustered index thing here. My stance is that I’d rather take a chance having one than not having one on a table (staging tables aside). Sort of like a pocket knife: I’d rather have it and not need it than need it and not have it.
At some point, you’ve gotta come to terms with the fact that you need nonclustered indexes to help your queries.
But which ones should you add? Where do you even start?
Let’s walk through your options.
If Everything Is Awful
It’s time to review those missing index requests. My favorite tool for that is sp_BlitzIndex, of course.
Now, I know, those missing index requests aren’t perfect.
I’m gonna share an industry secret with you: No one else looking at your server for the first time is going to have a better idea. Knowing what indexes you need often takes time and domain/workload knowledge.
If you’re using sp_Blitzindex, take note of a few things:
How long the server has been up for: Less than a week is usually pretty weak evidence
The “Estimated Benefit” number: If it’s less than 5 million, you may wanna put it to the side in favor of more useful indexes in round one
Duplicate requests: There may be several requests for indexes on the same table with similar definitions that you can consolidate
Insane lists of Includes: If you see requests on (one or a few key columns) and include (every other column in the table), try just adding the key columns first
Of course, I know you’re gonna test all these in Dev first, so I won’t spend too much time on that aspect ?
If One Query Is Awful
You’re gonna wanna look at the query plan — there may be an imperfect missing index request in there.
Hip Hop Hooray
And yeah, these are just the missing index requests that end up in the DMVs added to the query plan XML.
They’re not any better, and they’re subject to the same rules and problems. And they’re not even ordered by Impact.
Cute. Real cute.
sp_BlitzCache will show them to you by Impact, but that requires you being able to get the query from the plan cache, which isn’t always possible.
If You Don’t Trust Missing Index Requests
And trust me, I’m with you there, think about the kind of things indexes are good at helping queries do:
Find data
Join data
Order data
Group data
Keeping those basic things in mind can help you start designing much smarter indexes than SQL Server can give you.
You can start finding all sorts of things in your query plans that indexes might change.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I thought it could be helpful to go into more detail for what I plan to present at the columnstore precon that’s part of SQL Saturday New York City. Note that everything here is subject to change. I tried to include all of the main topics planned at this time. If you’re attending and really want to see something covered, let me know and I’ll be as transparent as possible about what I can and cannot do.
Part 1: Creating your table
Definitions
Delta rowgroups
How columnstore compression works
What can go wrong with compression
Picking the right data types
Deciding on partitioning
Indexing
When should you try columnstore?
Part 2: Loading data quickly
Serial inserts
Parallel inserts
Inserts into partitioned tables
Inserts to preserve order
Deleting rows
Updating rows
Better alternatives
Trickle insert – this is a maybe
Snapshot isolation and ADR
Loading data on large servers
Part 3: Querying your data
The value of maintenance
The value of patching
How I read execution plans
Columnstore/batch mode gotchas with DMVs and execution plans
I love helping people solve their problems. That’s probably why I stick around doing what I do instead of opening a gym.
That and I can’t deal with clanking for more than an hour at a time.
Recently I helped a client solve a problem with a broad set of causes, and it was a lot of fun uncovering the right data points to paint a picture of the problem and how to solve it.
Why So Slow?
It all started with an application. At times it would slow down.
No one was sure why, or what was happening when it did.
Over the course of looking at the server together, here’s what we found:
The server had 32 GB of RAM, and 200 GB of data
There were a significant number of long locking waits
There were a significant number of PAGEIOLATCH_** waits
Indexes had fill factor of 70%
There were many unused indexes on important tables
The error log was full of 15 second IO warnings
There was a network choke point where 10Gb Ethernet went to 1Gb iSCSI
Putting together the evidence
Alone, none of these data points means much. Even the 15 second I/O warnings could just be happening at night, when no one cares.
But when you put them all together, you can see exactly what the problem is.
Server memory wasn’t being used well, both because indexes had a very low fill factor (lots of empty space), and because indexes that don’t help queries had to get maintained by modification queries. That contributed to the PAGEIOLATCH_** waits.
Lots of indexes means more objects to lock, which generally means more locking waits.
Because we couldn’t make good use of memory, and we had to go to disk a lot, the poorly chosen 1Gb iSCSI connections were overwhelmed.
To give you an idea of how bad things were, the 1Gb iSCSI connections were only moving data at around USB 2 speeds.
Putting together the plan
Most of the problems could be solved with two easy changes: getting rid of unused indexes, and raising fill factor to 100. The size of data SQL Server would regularly have to deal with would drop drastically, so we’d be making better use of memory, and be less reliant on disk.
Making those two changes fixed 90% of their problems. Those are great short term wins. There was still some blocking, but user complaints disappeared.
We could make more changes, like adding memory to be even less reliant on disk, and replacing the 1Gb connections, sure. But the more immediate solution didn’t require any downtime, outages, or visits to the data center, and it bought them time to carefully plan those changes out.
If you’re hitting SQL Server problems that you just can’t get a handle on, drop me a line!
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I use it often in my demo queries because I try to make the base query to show some behavior as simple as possible. That doesn’t always work out, but, whatever. I’m just a bouncer, after all.
The problem with very simple queries is that they may not trigger the parts of the optimizer that display the behavior I’m after. This is the result of them only reaching trivial optimization. For example, trivial plans will not go parallel.
If there’s one downside to making the query as simple as possible and using 1 = (SELECT 1), is that people get very distracted by it. Sometimes I think it would be less distracting to make the query complicated and make a joke about it instead.
The Trouble With Trivial
I already mentioned that trivial plans will never go parallel. That’s because they never reach that stage of optimization.
They also don’t reach the “index matching” portion of query optimization, which may trigger missing index requests, with all their fault and frailty.
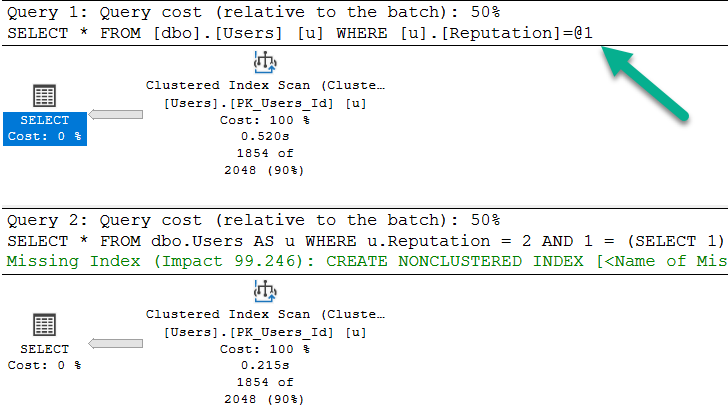
/*Nothing for you*/
SELECT *
FROM dbo.Users AS u
WHERE u.Reputation = 2;
/*Missing index requests*/
SELECT *
FROM dbo.Users AS u
WHERE u.Reputation = 2
AND 1 = (SELECT 1);
>greentext
Note that the bottom query gets a missing index request, and is not simple parameterized. The only reason the first query takes ~2x as long as the second query is because the cache was cold. In subsequent runs, they’re equal enough.
What Gets Fully Optimized?
Generally, things that introduce cost based decisions, and/or inflate the cost of a query > Cost Threshold for Parallelism.
Joins
Subqueries
Aggregations
Ordering without a supporting index
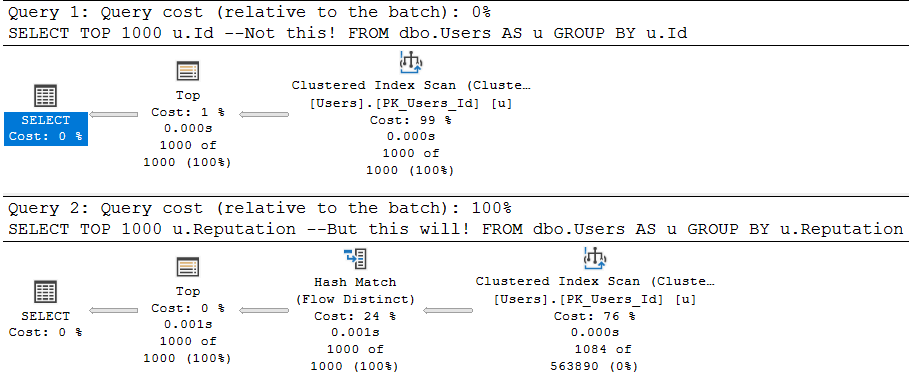
As a quick example, these two queries are fairly similar, but…
/*Unique column*/
SELECT TOP 1000 u.Id --Not this!
FROM dbo.Users AS u
GROUP BY u.Id;
/*Non-unique column*/
SELECT TOP 1000 u.Reputation --But this will!
FROM dbo.Users AS u
GROUP BY u.Reputation;
One attempts to aggregate a unique column (the pk of the Users table), and the other aggregates a non-unique column.
The optimizer is smart about this:
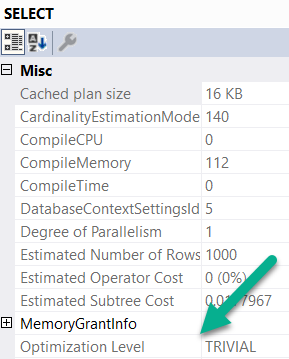
Flowy
The first query is trivially optimized. If you want to see this, hit F4 when you’re looking at a query plan. Highlight the root operator (select, insert, update, delete — whatever), and look at the optimization level.
wouldacouldashoulda
Since aggregations have no effect on unique columns, the optimizer throws the group by away. Keep in mind, the optimizer has to know a column is unique for that to happen. It has to be guaranteed by a uniqueness constraint of some kind: primary key, unique index, unique constraint.
The second query introduces a choice, though! What’s the cheapest way to aggregate the Reputation column? Hash Match Aggregate? Stream Aggregate? Sort Distinct? The optimizer had to make a choice, so the optimization level is full.
What About Indexes?
Another component of trivial plan choice is when the choice of index is completely obvious. I typically see it when there’s either a) only a clustered index or b) when there’s a covering nonclustered index.
If there’s a non-covering nonclustered index, the choice of a key lookup vs. clustered index scan introduces that cost based decision, so trivial plans go out the window.
Here’s an example:
CREATE INDEX ix_creationdate
ON dbo.Users(CreationDate);
SELECT u.CreationDate, u.Id
FROM dbo.Users AS u
WHERE u.CreationDate >= '20131229';
SELECT u.Reputation, u.Id
FROM dbo.Users AS u
WHERE u.Reputation = 2;
SELECT u.Reputation, u.Id
FROM dbo.Users AS u WITH(INDEX = ix_creationdate)
WHERE u.Reputation = 2;
With an index only on CreationDate, the first query gets a trivial plan. There’s no cost based decision, and the index we created covers the query fully.
For the next two queries, the optimization level is full. The optimizer had a choice, illustrated by the third query. Thankfully it isn’t one that gets chosen unless we force the issue with a hint. It’s a very bad choice, but it exists.
When It’s Wack
Let’s say you create a constraint, because u loev ur datea.
ALTER TABLE dbo.Users
ADD CONSTRAINT cx_rep CHECK
( Reputation >= 1 AND Reputation <= 2000000 );
When we run this query, our newly created and trusted constraint should let it bail out without doing any work.
SELECT u.DisplayName, u.Age, u.Reputation
FROM dbo.Users AS u
WHERE u.Reputation = 0;
But two things happen:
my name is bogus
The plan is trivial, and it’s auto-parameterized.
The auto-parameterization means a plan is chosen where the literal value 0 is replaced with a parameter by SQL Server. This is normally “okay”, because it promotes plan reuse. However, in this case, the auto-parameterized plan has to be safe for any value we pass in. Sure, it was 0 this time, but next time it could be one within the range of valid reputations.
Since we don’t have an index on Reputation, we have to read the entire table. If we had an index on Reputation, it would still result in a lot of extra reads, but I’m using the clustered index here for ~dramatic effect~
Table 'Users'. Scan count 1, logical reads 44440
Of course, adding the 1 = (SELECT 1) thing to the end introduces full optimization, and prevents this.
The query plan without it is just a constant scan, and it does 0 reads.
Rounding Down
So there you have it. When you see me (or anyone else) use 1 = (SELECT 1), this is why. Sometimes when you write demos, a trivial plan or auto-parameterization can mess things up. The easiest way to get around it is to add that to the end of a query.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I always try to impart on people that SQL injection isn’t necessarily about vandalizing or trashing data in some way.
Often it’s about getting data. One great way to figure out how difficult it might be to get that data is to figure out who you’re logged in as.
There’s a somewhat easy way to figure out if you’re logged in as sa.
Wanna see it?
Still Ill
SELECT SUSER_SID();
SELECT CONVERT(INT, SUSER_SID());
SELECT SUSER_NAME(1);
DECLARE @Top INT = 1000 + (SELECT CONVERT(INT, SUSER_SID()));
SELECT TOP (@Top)
u.Id, u.DisplayName, u.Reputation, u.CreationDate
FROM dbo.Users AS u
ORDER BY u.Reputation DESC;
GO
It doesn’t even require dynamic SQL.
All you need is a user entry field to do something like pass in how many records you want returned.
The results of the first three selects looks like this:
Full Size
This is always the case for the sa login.
If your app is logged in using it, the results of the TOP will return 1001 rows rather than 1000 rows.
If it’s a different login, the number could end up being positive or negative, and so a little bit more difficult to work with.
But hey! Things.
Validation
Be mindful of those input fields.
Lots of times, I’ll see people have what should be integer fields accept string values so users can use shortcut codes.
For example, let’s say we wanted someone to be able to select all available rows without making them memorize the integer maximum.
We might use a text field so someone could say “all” instead of 2147483647.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Clustered columnstore indexes can be a great solution for data warehouse workloads, but there’s not a lot of advanced training or detailed documentation out there. It’s easy to feel all alone when you want a second opinion or run into a problem with query performance or data loading that you don’t know how to solve.
In this full day session, I’ll teach you the most important things I know about clustered columnstore indexes. Specifically, I’ll teach you how to make the right choices with your schema, data loads, query tuning, and columnstore maintenance. All of these lessons have been learned the hard way with 4 TB of production data on large, 96+ core servers. Material is applicable from SQL Server 2016 through 2019.
Here’s what I’ll be talking about:
– How columnstore compression works and tips for picking the right data types
– Loading columnstore data quickly, especially on large servers
– Improving query performance on columnstore tables
– Maintaining your columnstore tables
This is an advanced level session. To get the most out of the material, attendees should have some practical experience with columnstore and query tuning, and a solid understanding of internals such as wait stats analysis. You don’t need to bring a laptop to follow along.
Wanna save 25%? Use coupon code “actionjoe” at checkout — it’s good for the first 10 seats, so hurry up and get yours today.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.