Quarrelin’
The next time you’re writing a query, I want you to try something in your head: Break the columns down into two groups.
- Informational: Columns you’re only selecting
- Relational: Columns that show up below the “from” clause
There may be some crossover, and that’s okay. If you’re selecting a short enough list of columns, and doing a group by, there might be total crossover.
But I’m willing to bet most of your queries don’t look that neat and tidy.
Your queries probably have a distinctly more robust list of columns, probably with a DISTINCT to fend off the dozen or so left joins for just in case columns.
And that’s… Okay, let’s reserve judgement. Instead, let’s figure out a better way to get them all.
Narrowin’
That long list of columns in your query has weight to it. Not physical weight, exactly. But to the optimizer, it represents a bunch of weight in CPU and I/O.
The more columns you want to drag around, the harder you make your queries work. Especially because the architect who migrated your app from Access to SQL Server 2000 made every column as wide as possible.
That weight changes a lot of things: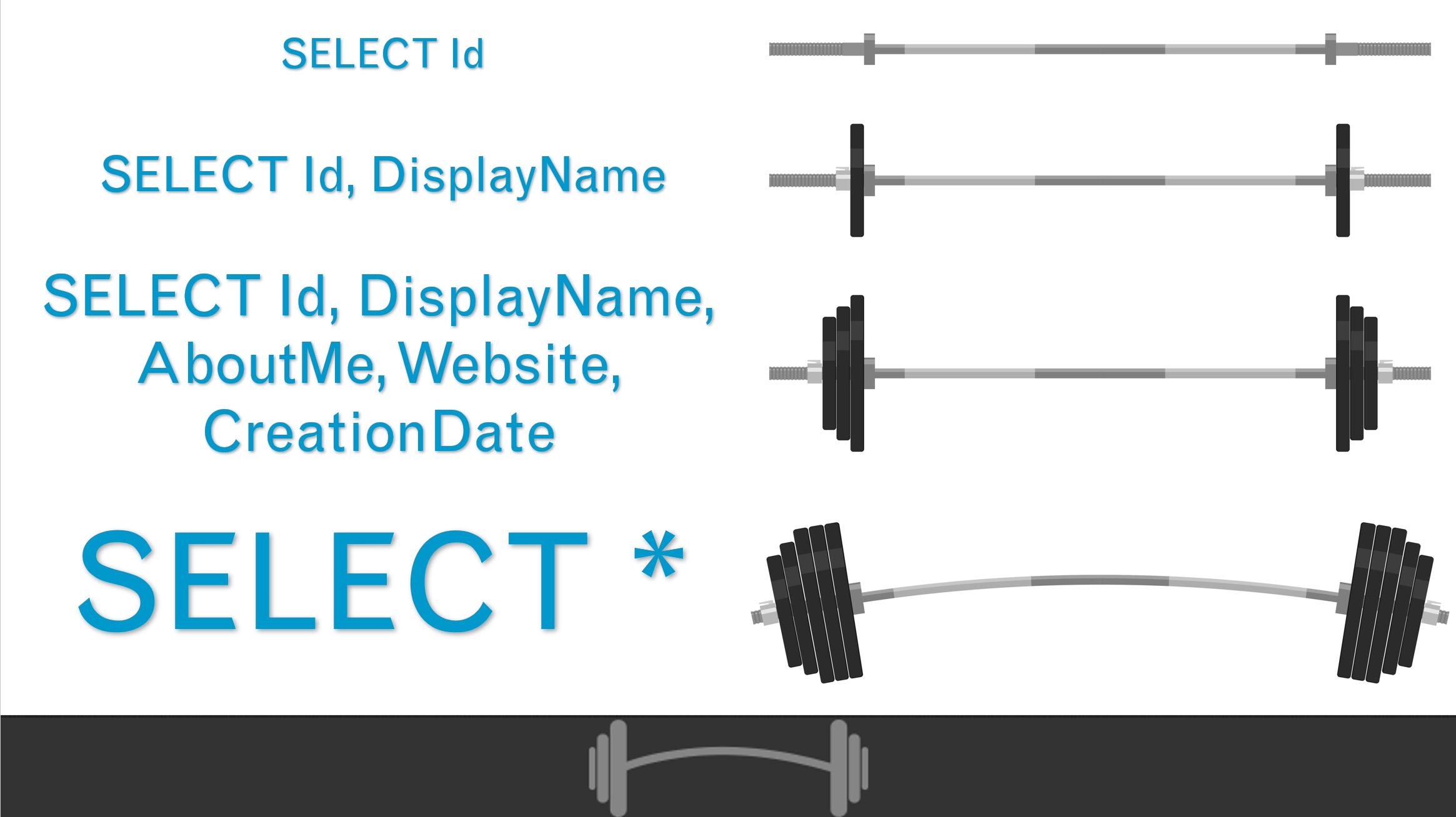
- How much memory your query asks for
- Which indexes your query uses
- The kind of operators the optimizer chooses
And I know, you need to show people that data. I’m not opposed to that.
I’m only opposed to when you’re doing it.
Filterin’
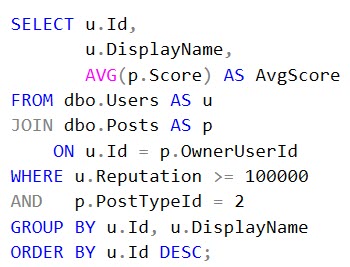
The reason why I want you to separate these concepts mentally is so that when you’re writing a query and you know you have to show people a lot of columns, to not try to show them all immediately. Instead, just take the columns you need to relate tables and put them in a temp table. It’s fine if you have your joins and where clause stuff here.
The idea is to get a narrow list of columns for a filtered set of rows. We’ll worry about the informational stuff after we get the relational stuff.
Something like this:

Splainin’
If you avoid getting long lists of columns up front, you can:
- Avoid overly wide indexes, and just index for the important stuff in the join/where clause
- Be less sensitive to parameter sniffing, because there will be less variability in plan choices
- Need fewer resources to push queries with, because less data is moving about
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.