If you want to download the database, here’s the magnet link for the torrent. I don’t have another means of distributing this; it’s too big of a file.
If you want the GitHub scripts to create and load data, head over here.
Info
If you’re downloading the database, it’s about a 80 GB backup file, that needs to be restored to SQL Server 2017 or higher. It expands to a database that’s about 160 GB. It’s not the biggest database in the world, but it’s a good starting place to learn about column store. You can always make it bigger, if you want.
If you’re comfortable with a database of that size on your computer (compared to the hardware), then downloading is fine. The computers I use it on have 64-128 GB of RAM.
Some people may want to build their own and find a size that better fits their hardware, which is where the create and build scripts make more sense. I wouldn’t wanna see you trying to query tables of this size on a laptop with a VM admin amount of RAM (say 16GB or less).
Scripts To Help You Explore Column Store
Great scripts to help you look at what SQL Server’s DMVs have to say about column store indexes live here: Columnstore Indexes Scripts Library
And of course, poke around this site for Joe Obbish’s posts about column store, along with Niko’s site for his material.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Rather than an F5 script to do this, I decided to make a stored procedure out of it. It’s in good shape, but if you find any problems or have any requests, head over to my GitHub repo to file an issue.
One thing I’d love feedback on is advancing dates. Right now, the script doesn’t do that at all. I thought of different ways to handle it, but didn’t like any of them, mostly because of how it might mess with the partitioning function I’m using. I felt like I was overthinking it quite a bit, and decided to leave dates as-is, and only increment User and Post Ids.
A quick note: This script assumes that a database called StackOverflow will be the source of the loads. If you need to use a different version, that’s a manual change. I didn’t want to go down the dynamic SQL route here until I gauged popularity.
Options
The stored procedure has relatively few options.
@loops INT = 1
@truncate_tables BIT = 1
@rebuild_when_done BIT = 1
@count_when_done BIT = 1
How many loops you want to run, if you want to start fresh by truncating tables first, if you want to rebuild indexes after you’re done loading, and if you want to get a count from each table at the end.
There are good enough reasons to include these for you to decide on. For instance, you might want to:
Start fresh, and see what the DMVs say about column store compression without rebuilding
Load on top and then see what they say without rebuilding
Do the opposite
Make additional bullet points
Iter and Iterate Walked Into A Store
Without being too explain-y, the way the script works is to:
Figure out if we need to increment Ids
Go through each of the main tables (Badges, Comments, Posts, Users, Votes) and insert the contents into the CCI version
Do this for as many loops as you specify
At the end of the script, do some cleanup of things that shouldn’t exist. Then rebuild and get counts if you asked for it.
In tomorrow’s post, I’ll give you download links and some more details about the database.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I really wanted a version of the Stack Overflow data dump that was all clustered column store. In SQL Server 2016, that didn’t really work because of restrictions around MAX data types. In 2017 it did, but… If your data warehouse has a bunch of max data type columns, that’s bad and you should feel bad.
The problem here is that once you drop out the “big” columns (AboutMe from Users, Text from Comments, Body from Posts), the entire ~300GB database compressed down to about 6GB. That means if we want a realistically sized data warehouse, we’d need a “Make Big” script, like people used to use for Adventure Works before it went out of business.
This week I’m going to talk about that process, and share links to download the examples so you can mess with them, or create your own.
Today, I’m going to talk about some of the design considerations, and what the initial setup script does, if you want to build your own version.
Hand In Hand
“Large” column store tables should be partitioned. While no one in their right mind would consider partitioning to be a performance feature with row store indexes, it can be beneficial to column store indexes. One of the first things I create after the standard database script-out is a partition function and scheme.
CREATE PARTITION FUNCTION pfunc (DATETIME)
AS RANGE RIGHT FOR VALUES
(
N'2007-01-01T00:00:00.000',
N'2008-01-01T00:00:00.000',
N'2009-01-01T00:00:00.000',
N'2010-01-01T00:00:00.000',
N'2011-01-01T00:00:00.000',
N'2012-01-01T00:00:00.000',
N'2013-01-01T00:00:00.000',
N'2014-01-01T00:00:00.000',
N'2015-01-01T00:00:00.000',
N'2016-01-01T00:00:00.000',
N'2017-01-01T00:00:00.000',
N'2018-01-01T00:00:00.000',
N'2019-01-01T00:00:00.000',
N'2020-01-01T00:00:00.000'
The years here go up to 2020. This covers you in case your source database is either the full size version, or the 2010 or 2013 version.
The scheme I create puts everything on the primary filegroup. Since the bones of this database is a backup/restore, it has four files, but they’re all in the primary filegroup. You’re welcome to change that, but I don’t find it necessary.
CREATE PARTITION SCHEME pscheme AS PARTITION pfunc ALL TO ([PRIMARY]);
Also I’m a bit lazy.
Swimmin’ In Synonyms With Their Own Condominiums
I did something kind of goofy at first. When I was experimenting with doing this, everything was in one database. So uh, I suffixed all the column store tables with “_cs”.
That turned out to be really annoying when running different demo scripts against this database, because I’d have to change all the names. To get around that, I created synonyms, but that felt hacky too.
For instance, any time I needed to write a DMV query that referenced a table, I’d screw up and reference the synonym, which doesn’t quite work as well as you’d hope. By that I mean not at all.
In the final version, all object names match those in other versions of the Stack Overflow database.
Tomorrow
In tomorrow’s post, I’ll show you parts of the script that use a StackOverflow database of your choice as a source to build up the column store version.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I ran into a very funny situation while working with a client recently. They were using Entity Framework, and a query with around 10 left joins ended up with a compile time of nearly 70 seconds.
Relatively.
Once the query finished compiling, it ran instantly with a pretty simple plan with all nested loops joins.
So what happened?
Tracing Flags
For science, I broke out a Rocket Science Trace Flag™ that will show optimization phases and how long were spent in them.
What came back looked like this:
end exploration, tasks: 3098 Cost = 242.433 time: 0 net: 0 total: 0.049 net: 0.047
end exploration, tasks: 3099 Cost = 242.433 time: 0 net: 0 total: 0.049 net: 0.047
end exploration, tasks: 3104 Cost = 242.433 time: 0 net: 0 total: 0.049 net: 0.048
end exploration, tasks: 3331 Cost = 242.433 time: 0.002 net: 0.002 total: 0.052 net: 0.05
end exploration, tasks: 3332 Cost = 242.433 time: 0 net: 0 total: 0.052 net: 0.05
end search(1), cost: 210.273 tasks: 3332 time: 0 net: 0 total: 0.052 net: 0.05
*** Optimizer time out abort at task 211100 ***
end search(2), cost: 210.273 tasks: 211100 time: 69.214 net: 69.678 total: 69.267 net: 69.729
*** Optimizer time out abort at task 211100 ***
End of post optimization rewrite, time: 0.001 net: 0.001 total: 69.268 net: 69.73
End of query plan compilation, time: 0.002 net: 0.002 total: 69.271 net: 69.732
The numbers aren’t quite the same, since the plan is from a different run than when I captured the trace flag (8675) output.
But you can see pretty clearly, in Search 2, we hung out for a while trying different rewrites.
What happens during Search 2? The whole enchilada.
In this case? Probably mostly join reordering.
Tracking Lags
If you don’t have query store enabled, it’s possible to search the plan cache, or get a warning from BlitzCache for long compile times.
If you do have Query Store enabled, compile time is logged in a couple places:
SELECT TOP (10)
qsq.query_id,
qsq.query_text_id,
qsq.initial_compile_start_time,
qsq.last_compile_start_time,
qsq.last_execution_time,
qsq.count_compiles,
qsq.last_compile_duration / 1000000. last_compile_duration,
qsq.avg_compile_duration / 1000000. avg_compile_duration,
qsq.avg_bind_duration / 1000000. avg_bind_duration,
qsq.avg_bind_cpu_time / 1000000. avg_bind_cpu_time,
qsq.avg_optimize_duration / 1000000. avg_optimize_duration,
qsq.avg_optimize_cpu_time / 1000000. avg_optimize_cpu_time,
qsq.avg_compile_memory_kb / 1024. avg_compile_memory_mb,
qsq.max_compile_memory_kb / 1024. max_compile_memory_mb
--INTO #query_store_query
FROM sys.query_store_query AS qsq
WHERE qsq.is_internal_query = 0
AND qsq.avg_compile_duration >= 1000000. --This is one second in microseconds
ORDER BY avg_compile_duration DESC
SELECT TOP (10)
qsp.plan_id,
qsp.query_id,
qsp.engine_version,
qsp.count_compiles,
qsp.initial_compile_start_time,
qsp.last_compile_start_time,
qsp.last_execution_time,
qsp.avg_compile_duration / 1000000. avg_compile_duration,
qsp.last_compile_duration / 1000000. last_compile_duration,
CONVERT(XML, qsp.query_plan) query_plan
--INTO #query_store_plan
FROM sys.query_store_plan AS qsp
WHERE qsp.avg_compile_duration >= 1000000. --This is one second in microseconds
ORDER BY qsp.avg_compile_duration DESC
I’ve seen different numbers show up in these, so I like to look at both. I don’t know why that happens. There’s probably a reasonable explanation.
If you wanted to add in some other metrics, you could do this:
DROP TABLE IF EXISTS #query_store_query;
DROP TABLE IF EXISTS #query_store_plan;
SELECT TOP (10)
qsq.query_id,
qsq.query_text_id,
qsq.initial_compile_start_time,
qsq.last_compile_start_time,
qsq.last_execution_time,
qsq.count_compiles,
qsq.last_compile_duration / 1000000. last_compile_duration,
qsq.avg_compile_duration / 1000000. avg_compile_duration,
qsq.avg_bind_duration / 1000000. avg_bind_duration,
qsq.avg_bind_cpu_time / 1000000. avg_bind_cpu_time,
qsq.avg_optimize_duration / 1000000. avg_optimize_duration,
qsq.avg_optimize_cpu_time / 1000000. avg_optimize_cpu_time,
qsq.avg_compile_memory_kb / 1024. avg_compile_memory_mb,
qsq.max_compile_memory_kb / 1024. max_compile_memory_mb
INTO #query_store_query
FROM sys.query_store_query AS qsq
WHERE qsq.is_internal_query = 0
AND qsq.avg_compile_duration >= 1000000. --This is one second in microseconds
ORDER BY avg_compile_duration DESC;
SELECT TOP (10)
qsp.plan_id,
qsp.query_id,
qsp.engine_version,
qsp.count_compiles,
qsp.initial_compile_start_time,
qsp.last_compile_start_time,
qsp.last_execution_time,
qsp.avg_compile_duration / 1000000. avg_compile_duration,
qsp.last_compile_duration / 1000000. last_compile_duration,
CONVERT(XML, qsp.query_plan) query_plan
INTO #query_store_plan
FROM sys.query_store_plan AS qsp
WHERE qsp.avg_compile_duration >= 1000000. --This is one second in microseconds
ORDER BY qsp.avg_compile_duration DESC;
SELECT (avg_cpu_time - qsq.avg_compile_duration) AS cpu_time_minus_qsq_compile_time,
(avg_cpu_time - qsp.avg_compile_duration) AS cpu_time_minus_qsp_compile_time,
qsrs.avg_cpu_time,
qsrs.avg_duration,
qsq.avg_compile_duration,
qsq.avg_bind_duration,
qsq.avg_bind_cpu_time,
qsq.avg_optimize_duration,
qsq.avg_optimize_cpu_time,
qsq.avg_compile_memory_mb,
qsp.avg_compile_duration,
qsq.count_compiles,
qsrs.count_executions,
qsp.engine_version,
qsp.query_id,
qsp.plan_id,
CONVERT(XML, qsp.query_plan) query_plan,
qsqt.query_sql_text,
qsrs.first_execution_time,
qsrs.last_execution_time,
qsq.initial_compile_start_time,
qsq.last_compile_start_time,
qsq.last_execution_time
FROM #query_store_query AS qsq
JOIN #query_store_plan AS qsp
ON qsq.query_id = qsp.query_id
JOIN sys.query_store_query_text AS qsqt
ON qsqt.query_text_id = qsq.query_text_id
JOIN
(
SELECT qsrs.plan_id,
qsrs.first_execution_time,
qsrs.last_execution_time,
qsrs.count_executions,
qsrs.avg_duration / 1000000. avg_duration,
qsrs.avg_cpu_time / 1000000. avg_cpu_time
FROM sys.query_store_runtime_stats AS qsrs
) AS qsrs
ON qsrs.plan_id = qsp.plan_id
ORDER BY qsq.avg_compile_duration DESC;
--ORDER BY qsp.avg_compile_duration DESC;
Fixes?
For EF, the only solution was to use a plan guide with a FORCE ORDER hint supplied. This let us arm wrestle the optimizer into just joining the tables in the order that the joins are written in the query. For some reason, forcing the plan with query store did not force the plan that forced the order.
I didn’t dig much into why. I do not get along with query store most of the time.
If you’re finding this happen with queries you have control over, doing your own rewrites to simplify the query and reduce the number of joins that the optimizer has to consider can help.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Startup Expression Predicates can be helpful. They may also exacerbate parameter sniffing issues in similar ways to IF branches.
Take a simple example:
CREATE INDEX bud_light ON dbo.Posts(OwnerUserId, Score);
CREATE INDEX coors_light ON dbo.Comments(UserId, Score);
GO
CREATE OR ALTER PROCEDURE dbo.sup (@check_posts BIT, @check_comments BIT, @post_score INT, @comment_score INT)
AS
BEGIN
SELECT MAX(ISNULL(p.CreationDate, c.CreationDate)) AS max_date,
COUNT_BIG(*) AS records
FROM dbo.Users AS u
LEFT JOIN dbo.Posts AS p
ON @check_posts = 1
AND p.OwnerUserId = u.Id
AND p.Score > @post_score
LEFT JOIN dbo.Comments AS c
ON @check_comments = 1
AND c.UserId = u.Id
AND c.Score > @comment_score;
END
GO
This gives users — and users only — an easy way to get data from certain tables.
This does not give the optimizer a good way of coming up with an execution plan to get or or the other, or both.
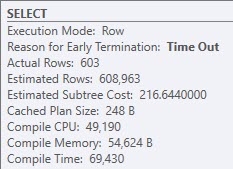
The first finishes instantly, the second not so instantly.
The Times
ENHANCE
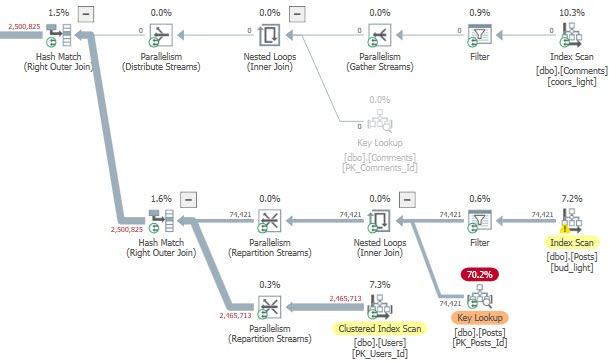
The problem is a bit easier to visualize in Sentry One Plan Explorer than SSMS, which greys out sections of the query plan that aren’t used.
The cached plan was totally unpreparedIt shows when the second query runs
Four million Key Lookups isn’t my idea of a good time.
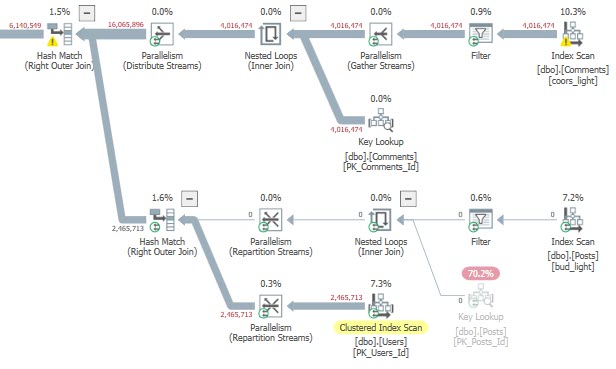
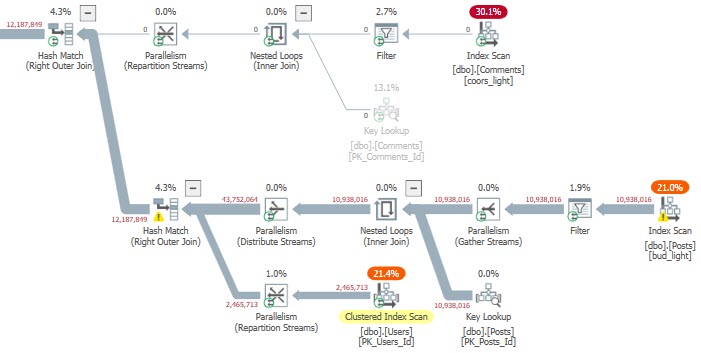
If we switch things up, the results are even worse. The bad plan runs for nearly a full minute.
teeeeeeeeen million
So uh, you know. Be careful out there, when you’re trying to be more cleverer than the optimizerer.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
This is always fun to talk to people about, because of all the misconceptions around the concept.
You need to find rows in one table that don’t have a match in another table. Maybe it’s a reconciliation process, maybe it’s part of ETL or something.
Doesn’t matter. Pay attention!
Choices
The way most people will write this query on the first try is like this:
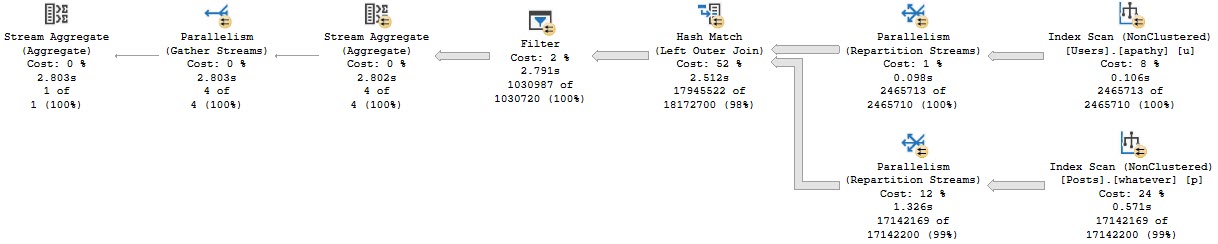
SELECT COUNT_BIG(u.Id) AS records
FROM dbo.Users AS u
LEFT JOIN dbo.Posts AS p
ON u.Id = p.OwnerUserId
WHERE p.Id IS NULL;
The query plan has one of my (generally) least favorite things in it: A filter.
2.8 seconds!
What’s the filter doing?
EZ-NULLZ
Looking for NULL values after the join. Yuck.
Better Choices
Expressed more SQL-y, we could use NOT EXISTS.
SELECT COUNT_BIG(u.Id) AS records
FROM dbo.Users AS u
WHERE NOT EXISTS ( SELECT 1/0
FROM dbo.Posts AS p
WHERE p.OwnerUserId = u.Id );
I mean, look, the Id column in the Posts table is the PK/CX. That means it can’t be NULL, unless it’s a non-matched row in a left join.
If that column is NULL, then every other column will be NULL too. You don’t ever need to select any data from the Posts table.
The query plan looks like this now:
1.6 seconds
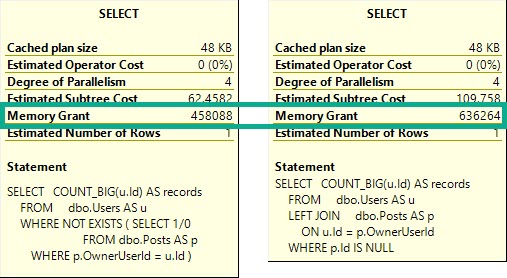
This performs better (under most circumstances), and gets some additional optimizations: A Bitmap, and a pre-aggregation of the OwnerUserId column in the Posts table.
Other Than Speed?
The Not Exists query will ask for around ~200MB less memory to run.
Every Penny
Why is this? Why is there such a difference between logically equivalent queries?
The Left Join version forces both tables to be fully joined together, which produces matches and non-matches.
After the join, we eliminate non-matches in the Filter. This is why I’m generally suspicious of Filter operators. They often mean we’ve some expression or complication in our logic that prevents the optimizer from eliminating rows earlier. This is to be expected when we do something like generate and filter on a row number — the row number doesn’t exist until the query runs, and has to be filtered later than existing data.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I’m not writing about how if you use NOT IN, and suffer from NULL values in a column you’re comparing, you’ll get an empty result.
That’s easy enough to show:
DECLARE @not_null TABLE ( id INT NOT NULL );
INSERT @not_null ( id )
VALUES ( 1 );
DECLARE @null TABLE ( id INT NULL );
INSERT @null ( id )
VALUES ( 1 );
INSERT @null ( id )
VALUES ( NULL );
SELECT *
FROM @not_null AS nn
WHERE nn.id NOT IN ( SELECT n.id FROM @null AS n );
What’s sort of more interesting to me is what happens in execution plans when you’re comparing NULL-able columns that don’t contain any NULLs.
Exampled!
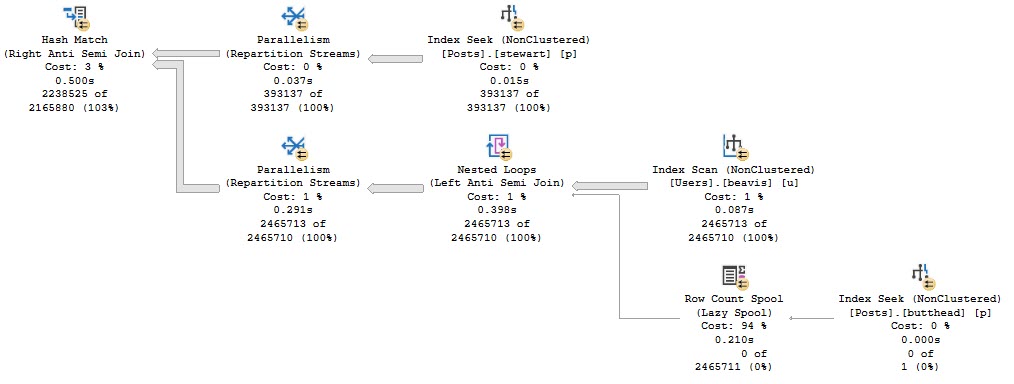
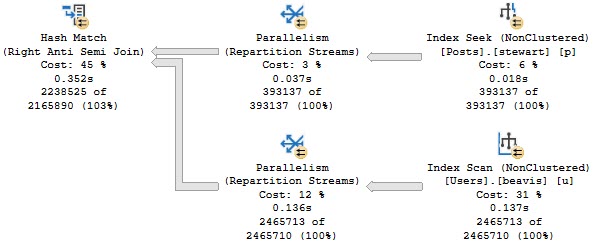
Here’s the first query I want to show you. In the Posts table, the OwnerUserId column is NULLable, but doesn’t have any NULLs in it. The Id column in the Users table is not NULLable — it’s the PK/CX on the table.
SELECT COUNT_BIG(*) AS records
FROM dbo.Users AS u
WHERE u.Id NOT IN ( SELECT p.OwnerUserId
FROM dbo.Posts AS p
WHERE p.Score < 0 );
Note that for all these queries, I’ve created these indexes:
CREATE INDEX beavis ON dbo.Users(AccountId);
CREATE INDEX butthead ON dbo.Posts(OwnerUserId, Score);
CREATE INDEX stewart ON dbo.Posts(Score, OwnerUserId);
The important part of the query looks like this:
Good thing I have great indexes.
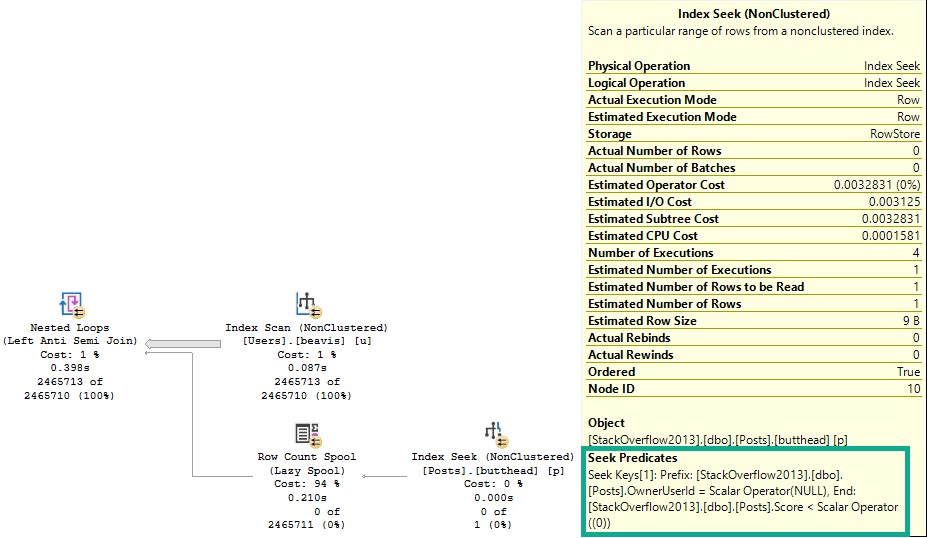
Zooming in to a sorta weird part of the query:
I’m in it
The optimizer spins up a Row Count Spool to make sure it’s right about the lack of NULLs. You can see the seek predicate doing so, and finding 0 rows, but taking ~200ms to do it. This time was much worse without those great indexes.
Explicitly Not NULL
If we change our query slightly, we can get a less exotic query plan:
SELECT COUNT_BIG(*) AS records
FROM dbo.Users AS u
WHERE u.Id NOT IN ( SELECT p.OwnerUserId
FROM dbo.Posts AS p
WHERE p.Score < 0
AND p.OwnerUserId IS NOT NULL );
Not Null’em
Which is a little bit faster overall, at ~350ms vs 550ms.
This is the equivalent of writing your query the way you should have written it in the first place, using NOT EXISTS.
SELECT COUNT_BIG(*) AS records
FROM dbo.Users AS u
WHERE NOT EXISTS ( SELECT 1 / 0
FROM dbo.Posts AS p
WHERE p.OwnerUserId = u.Id
AND p.Score < 0 )
Recap
The optimizer is a weird place. It’s the ultimate defensive driver. Dealing with NULLs can be quite odd and difficult.
I generally save IN and NOT IN for when I have short lists of literal values. Likely, EXISTS/NOT EXISTS when values are contained in other tables, or dumping values into a #temp table when there’s a lot of values can be more efficient, if only to make better indexing available.
While IN doesn’t have the same side effects as NOT IN with NULLs, I think using EXISTS instead is just a good habit.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
This is a somewhat complicated topic. There’s not a great TL;DR here, but I don’t want anyone to walk away from this post thinking that parallelism or indexes are “bad”.
What I do want to show is how uneven parallelism can exacerbate existing plan quality issues, and how some indexing can be unhelpful.
Query The First
This is the query we’ll be working with.
SELECT u.Id, u.DisplayName, u.Reputation, ca.*
FROM dbo.Users AS u WITH
CROSS APPLY ( SELECT c.*,
ROW_NUMBER()
OVER ( PARTITION BY c.PostId
ORDER BY c.Score DESC ) AS PostScoreRank
FROM dbo.Comments AS c
WHERE u.Id = c.UserId
AND c.Score > 0 ) AS ca
WHERE u.Reputation >= 100000
AND ca.PostScoreRank < 1
ORDER BY u.Reputation DESC
OPTION(RECOMPILE);
I’m using cross apply because the optimizer is likely to pick a Nested Loops join plan. These plans are unlikely to see a Redistribute Streams on the inner side of the join.
Within the apply, I’m making SQL Server do a more significant amount of work than outside of it. This will make more sense later on.
Outside of the apply, I’m doing a little bit of work against a few columns in the Users table, columns that would probably make good candidates for indexing.
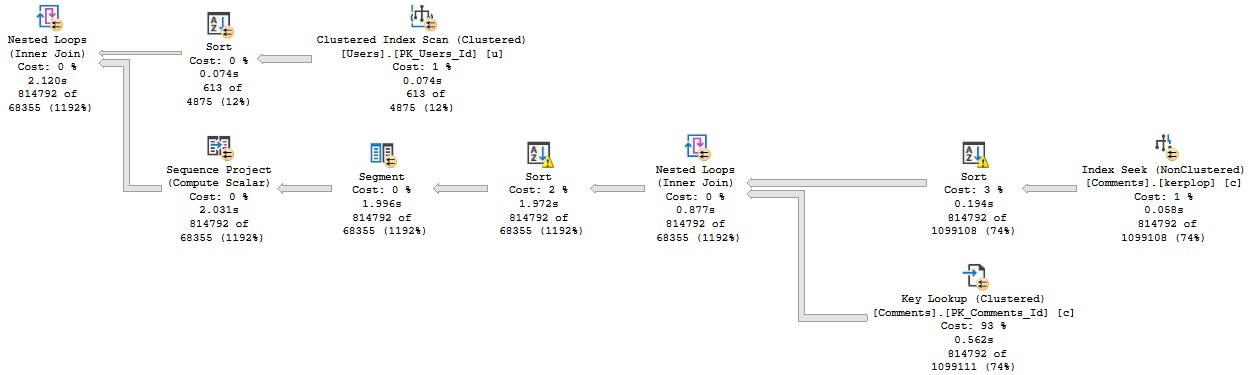
The index that I currently have on the Comments table looks like this:
CREATE INDEX kerplop
ON dbo.Comments(UserId, PostId, Score DESC)
WHERE Score > 0
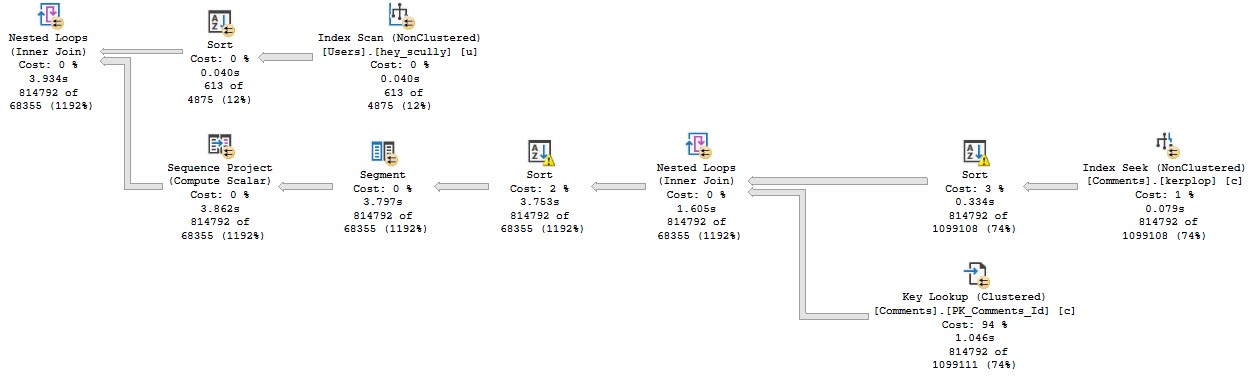
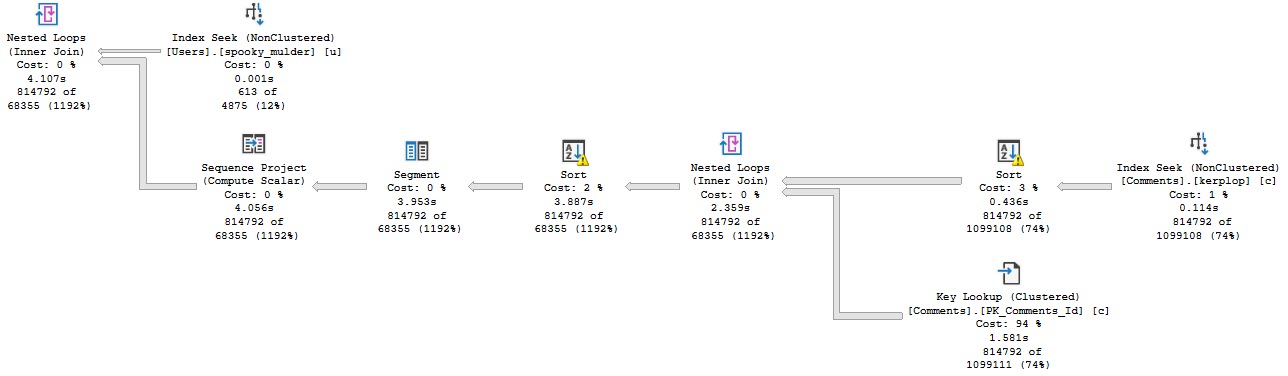
Anyway, the query plan for this run looks like this:
Stevenage overspill
The part I want to focus on are the spills.
Goes on…
What you should keep in mind is that while all 4 threads spill, they all spill pretty evenly.
Thread distribution is pretty good across parallel workers. Not perfect, but hey.
All together now
If you want perfect, go be disappointed in what you get for $47k per .75 cores of Oracle Enterprise Edition.
Query The Second
Knowing what we know about stuff, we may wanna add this index:
CREATE UNIQUE INDEX hey_scully
ON dbo.Users (Id, Reputation DESC)
INCLUDE(DisplayName);
But when we do, performance gets much worse.
If only.
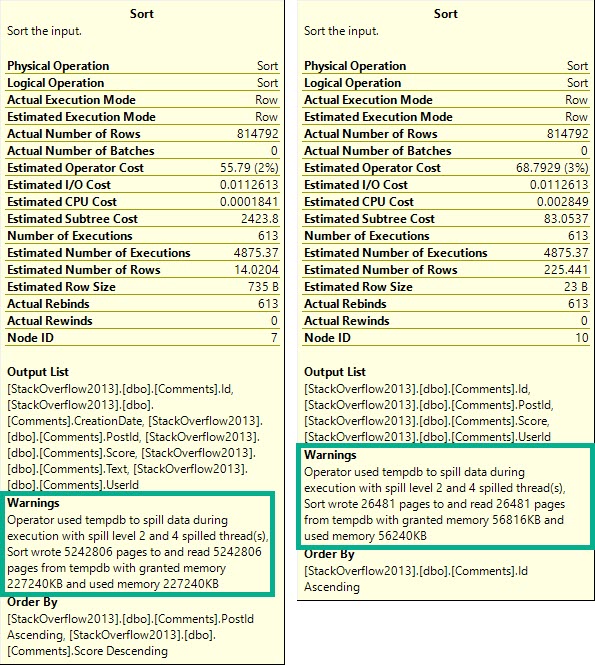
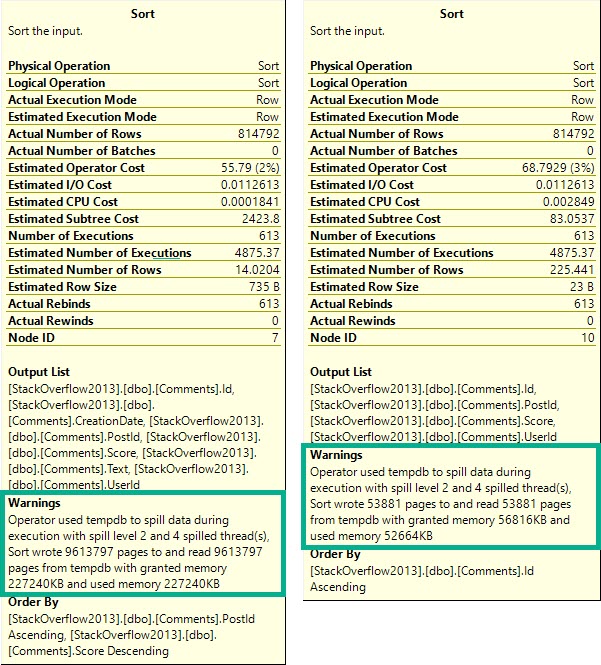
Zooming back in on the Sorts…
Happening in mine.
Each spill was about ~2x as bad, because thread distribution got much worse.
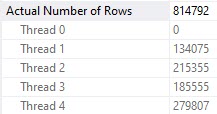
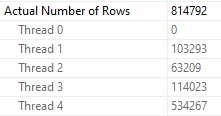
Fall down
Poor thread 4 got stuck with ~534k rows. The problem here is that each thread in a parallel plan gets an even cut of the memory grant. That doesn’t rebalance if parallelism is skewed. Threads may rebalance if a Redistribute Streams operator appears, but we don’t have one of those here. We will sometimes get one on the outer side of nested loops joins, if the optimizer decides it’s needed.
But since we don’t, things get all screwy.
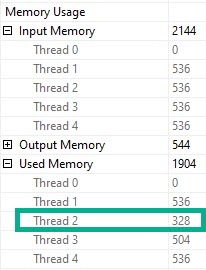
Underage
Thread 2, which had only 63k rows assigned to it didn’t use the full amount of memory it got, though it still apparently spilled. Same with thread 3, but to a lesser extent (get it?).
But why did this happen when we added an index?
Paper Boy
Reading the plan from right to left, top to bottom, we start with a scan of the Users table. This is when something called the parallel page supplier kicks in and starts handing out rows as threads ask for them. Its job is to make sure that parallel workers get rows when they ask for them, and that different threads don’t get the same rows. To do that, it uses key ranges from the statistics histogram.
It makes for a rather dull screenshot, but both histograms are identical for the clustered and nonclustered indexes in this demo. It’s not a statistical issue.
Nor are indexes fragmented, so, like, don’t get me started.
According to my Dear Friend, the parallel page supplier aims for 64k chunks. The smaller index just happens to end up with a more unfortunate key range distribution across its fewer pages.
Feuer
What About A Different Index?
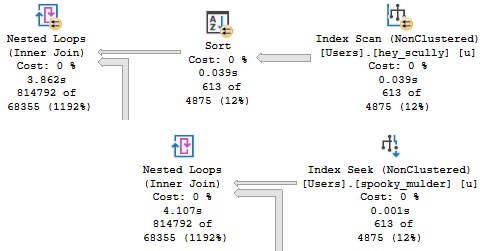
Let’s switch our indexes up and add this one:
CREATE UNIQUE INDEX spooky_mulder
ON dbo.Users (Reputation DESC, Id)
INCLUDE(DisplayName);
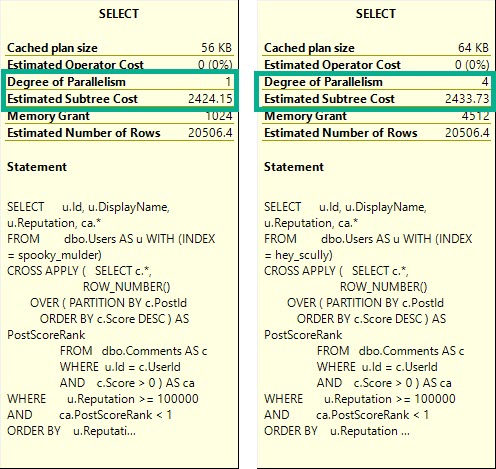
The plan no longer goes parallel, and it runs for about 4 seconds.
First Resort, Last Resort
We’re doing the same amount of work on the inner side of the nested loops join. The only part of the plan that changed is on the outer side.
Monkey Bread
This is more of an aside than anything, but in parallel nested loops plans, the optimizer only considers if parallelism will reduce the cost of the outer side of the join.
The plan changing to use a cheaper seek with no need to sort data means the outer side is rather cheap to execute, but the inner side is just as expensive.
Not to brag but
The DOP 1 plan is only slightly cheaper, here. You may expect a plan that “costs” this much to go parallel, but alas, it was not meant to be.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
There are many good reasons to parameterize queries.
There are, of course, downsides, too. Parameter sensitivity, AKA parameter sniffing, being the prime one.
But let’s say you consult the internet, or find a consultant on the internet, and they tell you that you ought to parameterize your queries.
It all sounds like a grand idea — you’ll get better plan reuse, and hopefully the plan cache will stop clearing itself out like a drunken ourobouros.
You could even use a setting called forced parameterization, which doesn’t always work.
Apart from the normal rules about when parameteriztion, forced or not, may not work, there’s another situation that can make things difficult.
Client Per Thing
Let’s assume for a second that you have a client-per-database, or client-per-schema model.
If I execute parameterized code like this:
DECLARE @i INT = 2
DECLARE @sql NVARCHAR(MAX) = N'
SELECT COUNT(*) AS records
FROM dbo.Users AS u
WHERE u.Reputation = @ii
'
EXEC sys.sp_executesql @sql, N'@ii INT', @ii = @i;
But from different database contexts (I have a few different versions of StackOverflow on my server, but I’m going to show results from 2013 and 2010), we’ll get separate cached plans, despite them having identical:
Costs
Query Plans
SQL Handles
Query Hashes
Frida Fredo
The same thing would happen with any parameterized code executed in a different context — stored procedures, functions… well. You get the idea.
Forced parameterization may help queries within the same context with plan reuse, but there are certain boundaries they won’t cross.
Don’t get me wrong, here. I’m not complaining. There’s so much that could be different, I wouldn’t want plan reuse across these boundaries. Heck, I may even separate stuff specifically to get different plans. As usual, I don’t want you, dear reader, to be surprised by this behavior.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.