Pattern Baldness
I see this pattern quite a bit in stored procedures, where the front end accepts an integer which gets passed to a query.
That integer is used to specify some time period — days, months, whatever — and the procedure then has to search some date column for the relevant values.
Here’s a simplified example using plain ol’ queries.
Still Alive
Here are my queries. The recompile hints are there to edify people who are hip to local variable problems.
DECLARE @months_back INT = 1; SELECT COUNT(*) AS records FROM dbo.Posts AS p WHERE DATEADD(MONTH, @months_back * -1, p.CreationDate) <= '20100101' --Usually GETDATE() is here OPTION(RECOMPILE); GO DECLARE @months_back INT = 1; SELECT COUNT(*) AS records FROM dbo.Posts AS p WHERE p.CreationDate <= DATEADD(MONTH, @months_back, '20100101') --Usually GETDATE() is here OPTION(RECOMPILE); GO
The problem with the first query is that the function is applied to the column, rather than to the variable.
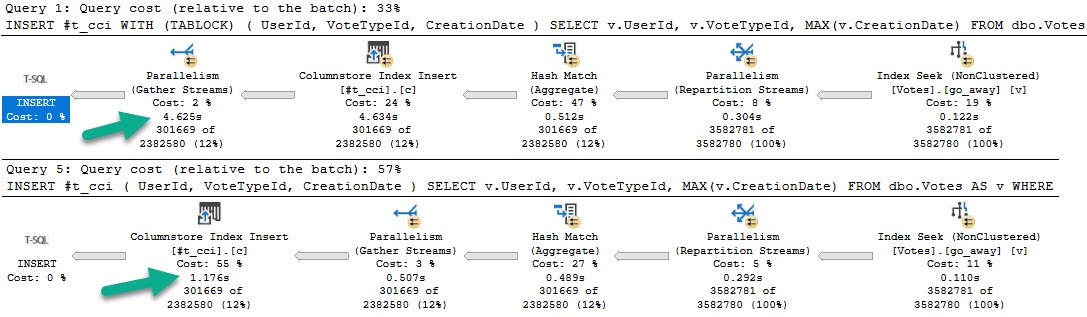
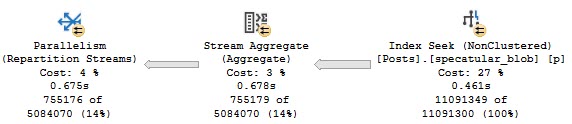
If we look at the plans for these, the optimizer only thinks one of them is special enough for an index request.
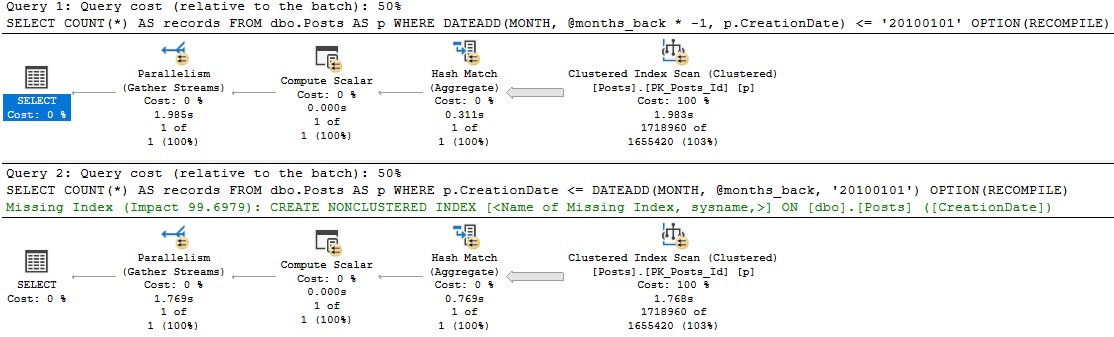
Sure, there’s also a ~200ms difference between the two, which is pretty repeatable.
But that’s not the point — where things change quite a bit more is when we have a useful index. Those two queries above are just using the clustered index, which is on a column unrelated to our where clause.
CREATE INDEX etadnoitaerc ON dbo.Posts(CreationDate);
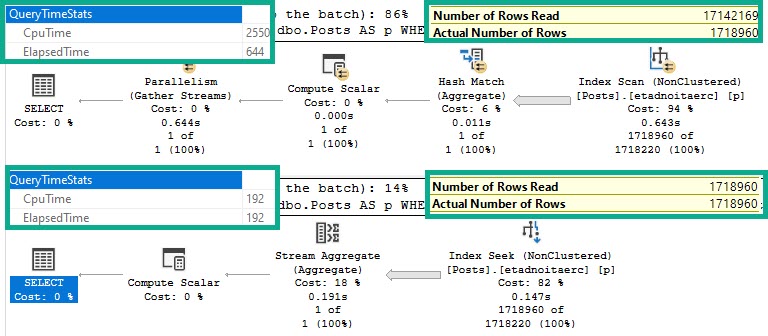
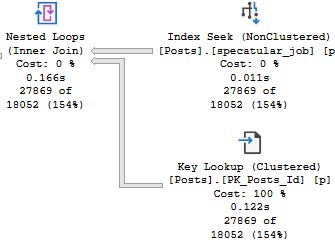
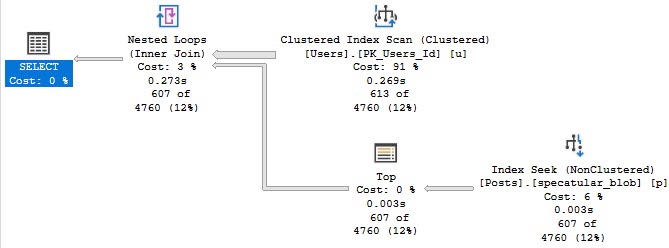
Side by side:
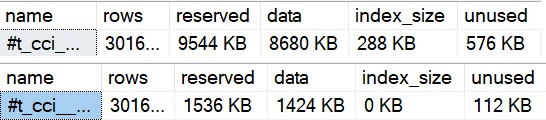
- The bad query uses >10x more CPU
- Still runs for >3x as long
- Scans the entire index
- Reads 10x more rows
- Has to go parallel to remain competitive
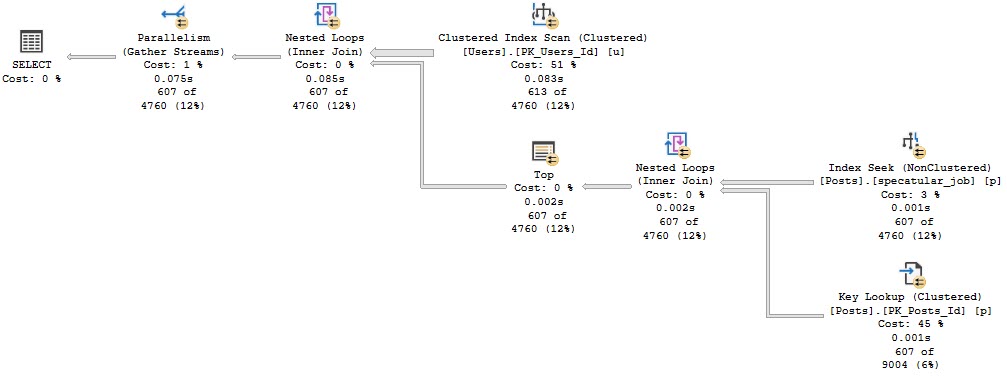
At MAXDOP 1, it runs for just about 2.2 seconds on a single thread. Bad news.
Qual
This is one example of misplacing logic, and why it can be bad for performance.
All these demos were run on SQL Server 2019, which unfortunately didn’t save us any trouble.
In the next post, I’m going to look at another way I see people make their own doom.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.