Or “Default”, If That’s Your Kink
Look, I’m not saying there’s only one thing that the “Default” cardinality estimator does better than the “Legacy” cardinality estimator. All I’m saying is that this is one thing that I think it does better.
What’s that one thing? Ascending keys. In particular, when queries search for values that haven’t quite made it to the histogram yet because a stats update hasn’t occurred since they landed in the mix.
I know what you’re thinking, too! On older versions of SQL Server, I’ve got trace flag 2371, and on 2016+ that became the default behavior.
Sure it did — only if you’re using compat level 130 or better — which a lot of people aren’t because of all the other strings attached.
And that’s before you go and get 2389 and 2390 involved, too. Unless you’re on compatibility level 120 or higher! Then you need 4139.
Arduous
Anyway, look, it’s all documented.
| 2371 | Changes the fixed update statistics threshold to a linear update statistics threshold. For more information, see this AUTO_UPDATE_STATISTICS Option.
Note: Starting with SQL Server 2016 (13.x) and under the database compatibility level 130 or above, this behavior is controlled by the engine and trace flag 2371 has no effect. Scope: global only |
| 2389 | Enable automatically generated quick statistics for ascending keys (histogram amendment). If trace flag 2389 is set, and a leading statistics column is marked as ascending, then the histogram used to estimate cardinality will be adjusted at query compile time.
Note: Please ensure that you thoroughly test this option, before rolling it into a production environment. Note: This trace flag does not apply to CE version 120 or above. Use trace flag 4139 instead. Scope: global or session or query (QUERYTRACEON) |
| 2390 | Enable automatically generated quick statistics for ascending or unknown keys (histogram amendment). If trace flag 2390 is set, and a leading statistics column is marked as ascending or unknown, then the histogram used to estimate cardinality will be adjusted at query compile time. For more information, see this Microsoft Support article.
Note: Please ensure that you thoroughly test this option, before rolling it into a production environment. Note: This trace flag does not apply to CE version 120 or above. Use trace flag 4139 instead. Scope: global or session or query (QUERYTRACEON) |
| 4139 | Enable automatically generated quick statistics (histogram amendment) regardless of key column status. If trace flag 4139 is set, regardless of the leading statistics column status (ascending, descending, or stationary), the histogram used to estimate cardinality will be adjusted at query compile time. For more information, see this Microsoft Support article.
Starting with SQL Server 2016 (13.x) SP1, to accomplish this at the query level, add the USE HINT ‘ENABLE_HIST_AMENDMENT_FOR_ASC_KEYS’ query hint instead of using this trace flag. Note: Please ensure that you thoroughly test this option, before rolling it into a production environment. Note: This trace flag does not apply to CE version 70. Use trace flags 2389 and 2390 instead. Scope: global or session or query (QUERYTRACEON) |
I uh. I guess. ?
Why Not Just Get Cardinality Estimation Right The First Time?
Great question! Hopefully someone knows the answer. In the meantime, let’s look at what I think this new-fangled cardinality estimator does better.
The first thing we need is an index with literally any sort of statistics.
CREATE INDEX v ON dbo.Votes_Beater(PostId);
Next is a query to help us figure out how many rows we can modify before an auto stats update will kick in, specifically for this index, though it’s left as an exercise to the reader to determine which one they’ve got in effect.
There are a lot of possible places this can kick in. Trace Flags, database settings, query hints, and more.
SELECT TOP (1)
OBJECT_NAME(s.object_id) AS table_name,
s.name AS stats_name,
p.modification_counter,
p.rows,
CONVERT(bigint, SQRT(1000 * p.rows)) AS [new_auto_stats_threshold],
((p.rows * 20) / 100) + CASE WHEN p.rows > 499 THEN 500 ELSE 0 END AS [old_auto_stats_threshold]
FROM sys.stats AS s
CROSS APPLY sys.dm_db_stats_properties(s.object_id, s.stats_id) AS p
WHERE s.name = 'v'
ORDER BY p.modification_counter DESC;
Edge cases aside, those calculations should get you Mostly Accurate™ numbers.
We’re going to need those for what we do next.
Mods Mods Mods
This script will allow us to delete and re-insert a bunch of rows back into a table, without messing up identity values.
--Create a temp table to hold rows we're deleting
DROP TABLE IF EXISTS #Votes;
CREATE TABLE #Votes (Id int, PostId int, UserId int, BountyAmount int, VoteTypeId int, CreationDate datetime);
--Get the current high PostId, for sanity checking
SELECT MAX(vb.PostId) AS BeforeDeleteTopPostId FROM dbo.Votes_Beater AS vb;
--Delete only as many rows as we can to not trigger auto-stats
WITH v AS
(
SELECT TOP (229562 - 1) vb.*
FROM dbo.Votes_Beater AS vb
ORDER BY vb.PostId DESC
)
DELETE v
--Output deleted rows into a temp table
OUTPUT Deleted.Id, Deleted.PostId, Deleted.UserId,
Deleted.BountyAmount, Deleted.VoteTypeId, Deleted.CreationDate
INTO #Votes;
--Get the current max PostId, for safe keeping
SELECT MAX(vb.PostId) AS AfterDeleteTopPostId FROM dbo.Votes_Beater AS vb;
--Update stats here, so we don't trigger auto stats when we re-insert
UPDATE STATISTICS dbo.Votes_Beater;
--Put all the deleted rows back into the rable
SET IDENTITY_INSERT dbo.Votes_Beater ON;
INSERT dbo.Votes_Beater WITH(TABLOCK)
(Id, PostId, UserId, BountyAmount, VoteTypeId, CreationDate)
SELECT v.Id, v.PostId, v.UserId, v.BountyAmount, v.VoteTypeId, v.CreationDate
FROM #Votes AS v;
SET IDENTITY_INSERT dbo.Votes_Beater OFF;
--Make sure this matches with the one before the delete
SELECT MAX(vb.PostId) AS AfterInsertTopPostId FROM dbo.Votes_Beater AS vb;
What we’re left with is a statistics object that’ll be just shy of auto-updating:

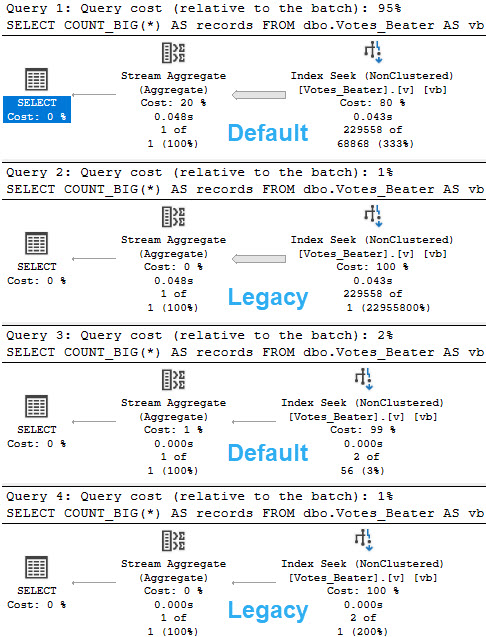
Query Time
Let’s look at how the optimizer treats queries that touch values! That’ll be fun, eh?
--Inequality, default CE
SELECT
COUNT_BIG(*) AS records
FROM dbo.Votes_Beater AS vb
WHERE vb.PostId > 20671101
OPTION(RECOMPILE);
--Inequality, legacy CE
SELECT
COUNT_BIG(*) AS records
FROM dbo.Votes_Beater AS vb
WHERE vb.PostId > 20671101
OPTION(RECOMPILE, USE HINT('FORCE_LEGACY_CARDINALITY_ESTIMATION'));
--Equality, default CE
SELECT
COUNT_BIG(*) AS records
FROM dbo.Votes_Beater AS vb
WHERE vb.PostId = 20671101
OPTION(RECOMPILE);
--Equality, legacy CE
SELECT
COUNT_BIG(*) AS records
FROM dbo.Votes_Beater AS vb
WHERE vb.PostId = 20671101
OPTION(RECOMPILE, USE HINT('FORCE_LEGACY_CARDINALITY_ESTIMATION'));
For the record, > and >= produced the same guesses. Less than wouldn’t make sense here, since it’d hit mostly all values currently in the histogram.
Inside Intel
For the legacy CE, there’s not much of an estimate. You get a stock guess of 1 row, no matter what.
For the default CE, there’s a little more to it.
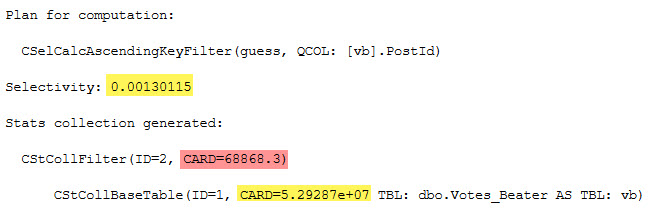
SELECT (0.00130115 * 5.29287e+07) AS inequality_computation;
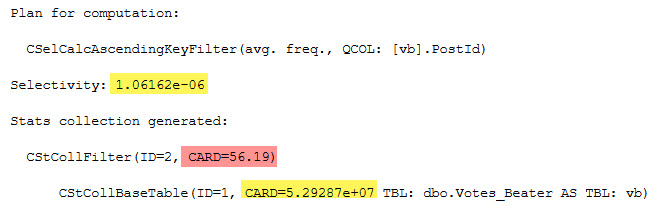
SELECT (1.06162e-06 * 5.29287e+07) AS equality_computation;
And of course, the CARD for both is the number of rows in the table:
SELECT CONVERT(bigint, 5.29287e+07) AS table_rows;
I’m not sure why the scientific notation is preferred, here.
A Little Strange
Adding in the USE HINT mentioned earlier in the post (USE HINT ('ENABLE_HIST_AMENDMENT_FOR_ASC_KEYS')) only seems to help with estimation for the inequality predicate. The guess for the equality predicate remains the same.
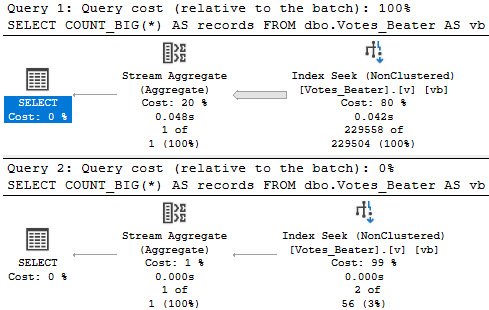
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.