To Taste
Indexes remind me of salt. And no, not because they’re fun to put on slugs.
More because it’s easy to tell when there’s too little or too much indexing going on. Just like when you taste food it’s easy to tell when there’s too much or too little salt.
Salt is also one of the few ingredients that is accepted across the board in chili.
To continue feeding a dead horse, the amount of indexing that each workload and system needs and can handle can vary quite a bit.
Appetite For Nonclustered
I’m not going to get into the whole clustered index thing here. My stance is that I’d rather take a chance having one than not having one on a table (staging tables aside). Sort of like a pocket knife: I’d rather have it and not need it than need it and not have it.
At some point, you’ve gotta come to terms with the fact that you need nonclustered indexes to help your queries.
But which ones should you add? Where do you even start?
Let’s walk through your options.
If Everything Is Awful
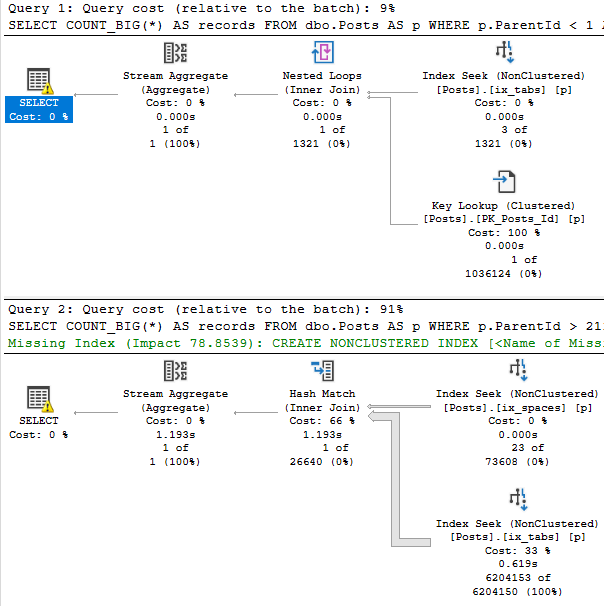
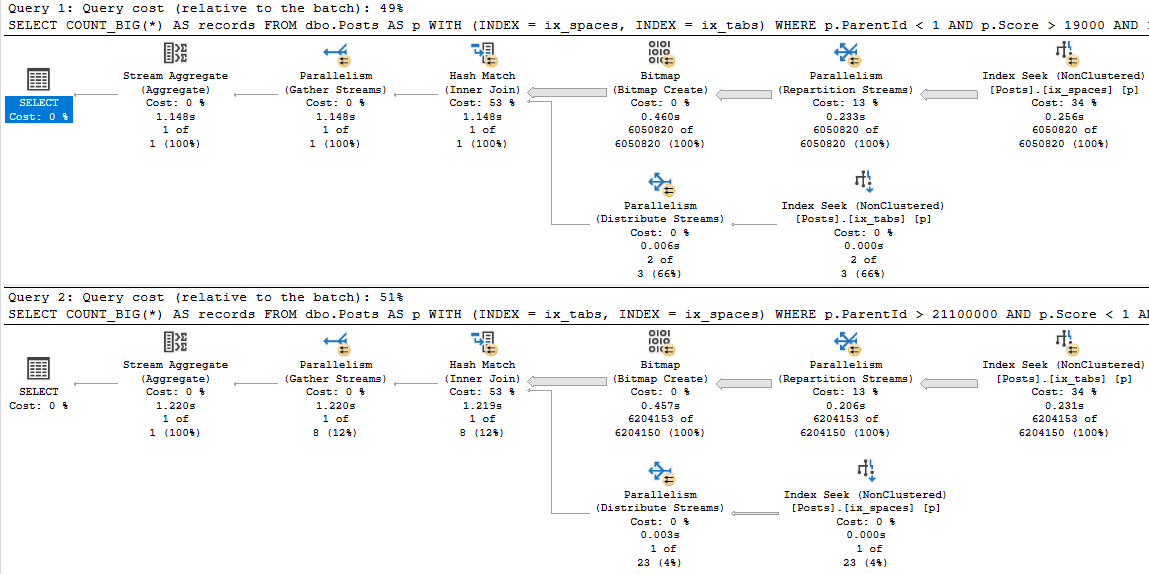
It’s time to review those missing index requests. My favorite tool for that is sp_BlitzIndex, of course.
Now, I know, those missing index requests aren’t perfect.
There are oodles of limitations, the way they’re presented is weird, and there are lots of reasons they may not be there. But if everything is on fire and you have no idea what to do, this is often a good-enough bridge until you’ve got more experience, or more time to figure out better indexes.
I’m gonna share an industry secret with you: No one else looking at your server for the first time is going to have a better idea. Knowing what indexes you need often takes time and domain/workload knowledge.
If you’re using sp_Blitzindex, take note of a few things:
- How long the server has been up for: Less than a week is usually pretty weak evidence
- The “Estimated Benefit” number: If it’s less than 5 million, you may wanna put it to the side in favor of more useful indexes in round one
- Duplicate requests: There may be several requests for indexes on the same table with similar definitions that you can consolidate
- Insane lists of Includes: If you see requests on (one or a few key columns) and include (every other column in the table), try just adding the key columns first
Of course, I know you’re gonna test all these in Dev first, so I won’t spend too much time on that aspect ?
If One Query Is Awful
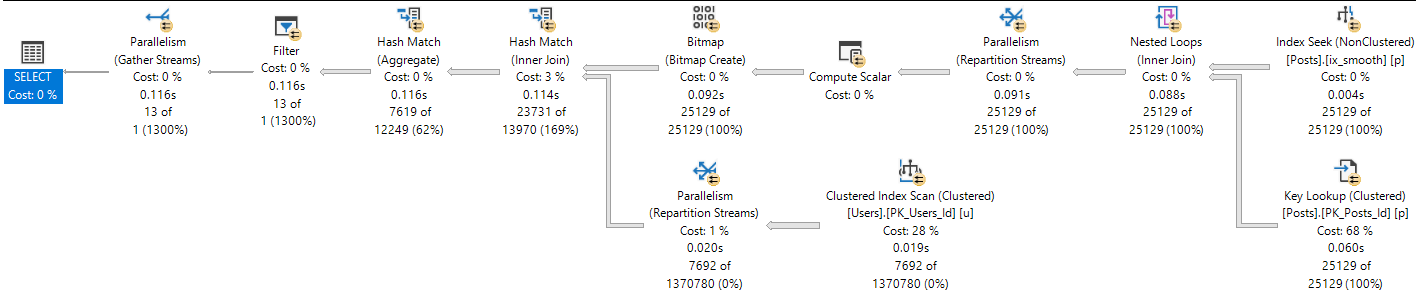
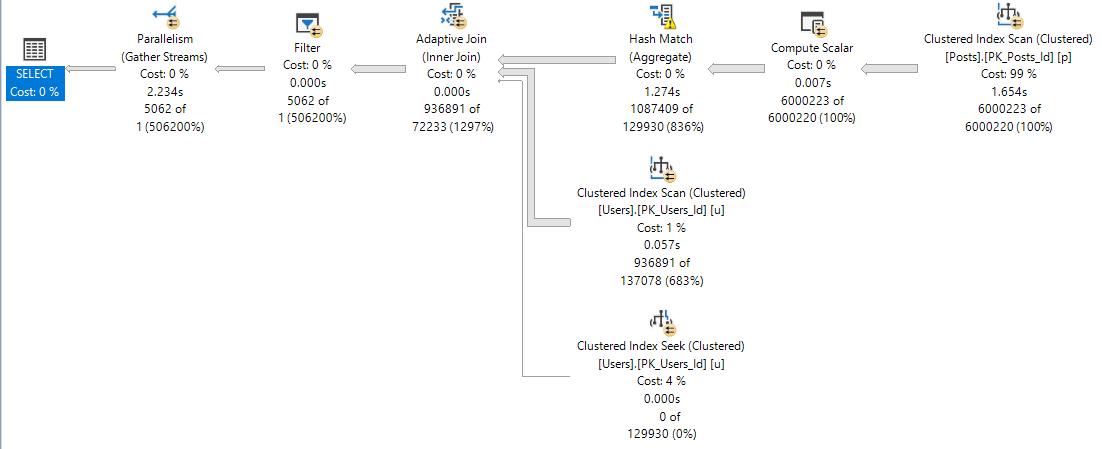
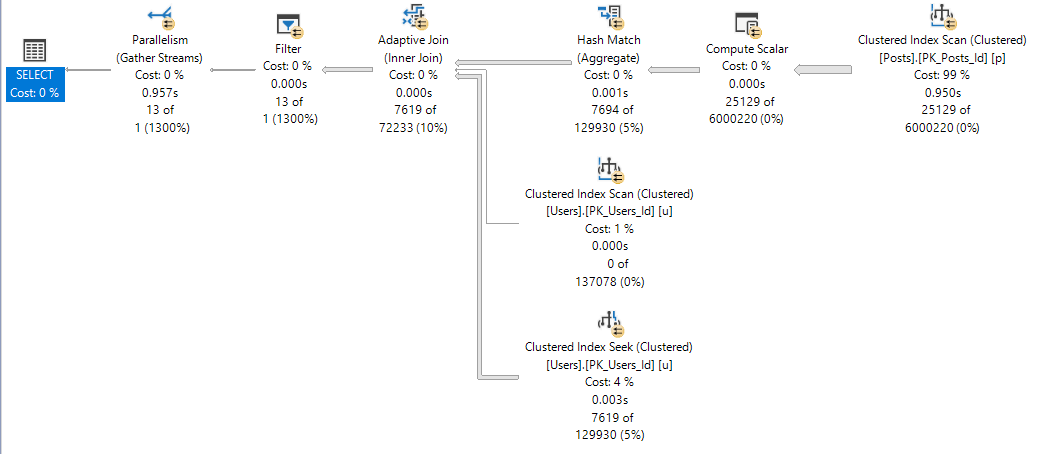
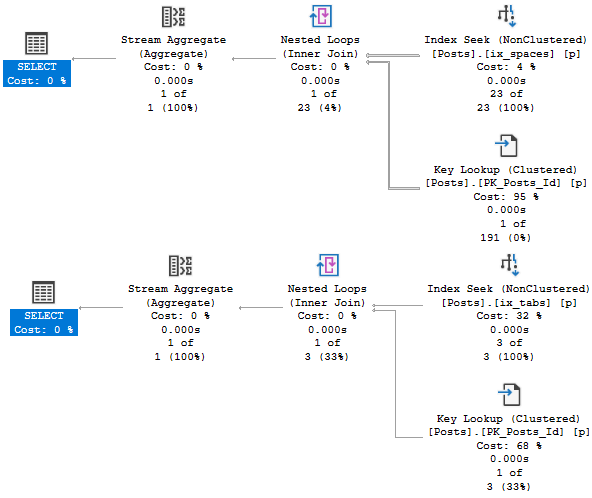
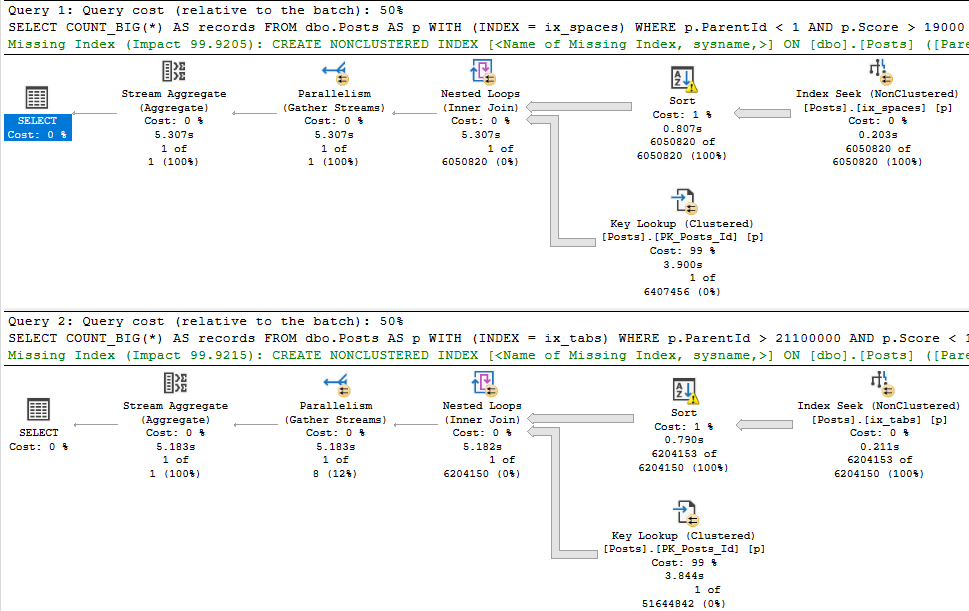
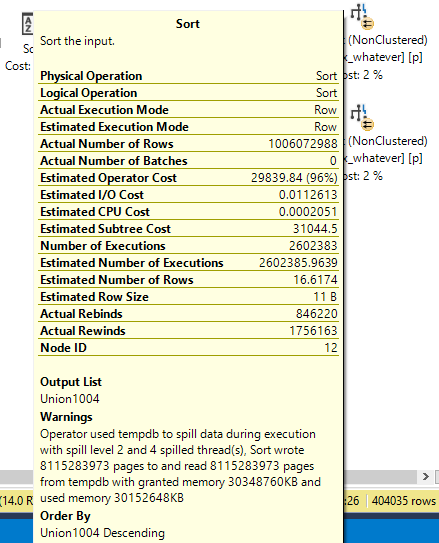
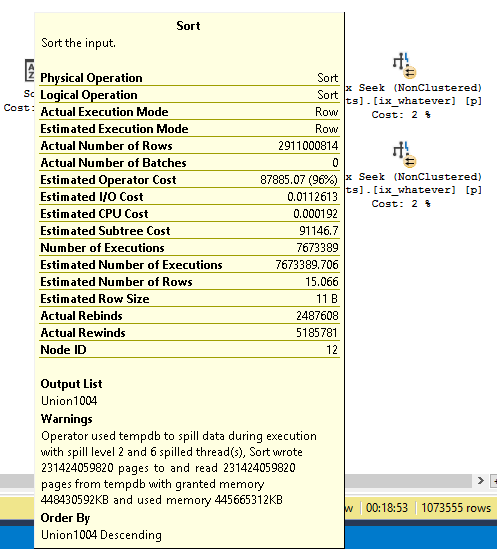
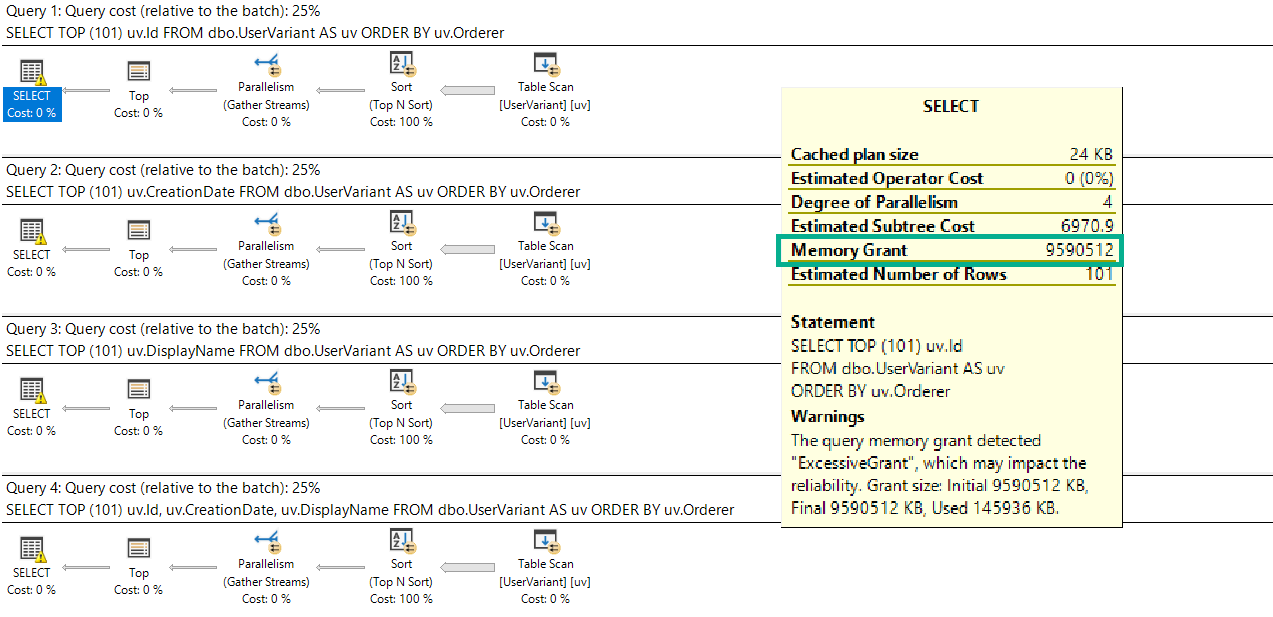
You’re gonna wanna look at the query plan — there may be an imperfect missing index request in there.

And yeah, these are just the missing index requests that end up in the DMVs added to the query plan XML.
They’re not any better, and they’re subject to the same rules and problems. And they’re not even ordered by Impact.
Cute. Real cute.
sp_BlitzCache will show them to you by Impact, but that requires you being able to get the query from the plan cache, which isn’t always possible.
If You Don’t Trust Missing Index Requests
And trust me, I’m with you there, think about the kind of things indexes are good at helping queries do:
- Find data
- Join data
- Order data
- Group data
Keeping those basic things in mind can help you start designing much smarter indexes than SQL Server can give you.
You can start finding all sorts of things in your query plans that indexes might change.
Check out my talk at SQLBits about indexes for some cool examples.
And of course, if you need help doing it, I’m here for just that sort of thing.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.