Kendra, Kendra, Kendra
My dear friend Kendra asked… Okay, look, I might have dreamed this. But I maybe dreamed that she asked what people’s Cost Threshold For Blogging™ is. Meaning, how many times do you have to get asked a question before you write about it.
I have now heard people talking and asking about in-memory table variables half a dozen times, so I guess here we are.
Talking about table variables.
In memory.
Yes, Have Some
First, yes, they do help relieve tempdb contention if you have code that executes under both high concurrency and frequency. And by high, I mean REALLY HIGH.
Like, Snoop Dogg high.
Because you can’t get rid of in memory stuff, I’m creating a separate database to test in.
Here’s how I’m doing it!
CREATE DATABASE trash;
ALTER DATABASE trash
ADD FILEGROUP trashy
CONTAINS MEMORY_OPTIMIZED_DATA ;
ALTER DATABASE trash
ADD FILE
(
NAME=trashcan,
FILENAME='D:\SQL2019\maggots'
)
TO FILEGROUP trashy;
USE trash;
CREATE TYPE PostThing
AS TABLE
(
OwnerUserId int,
Score int,
INDEX o HASH(OwnerUserId)
WITH(BUCKET_COUNT = 100)
) WITH
(
MEMORY_OPTIMIZED = ON
);
GO
Here’s how I’m testing things:
CREATE OR ALTER PROCEDURE dbo.TableVariableTest(@Id INT)
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
DECLARE @t AS PostThing;
DECLARE @i INT;
INSERT @t
( OwnerUserId, Score )
SELECT
p.OwnerUserId,
p.Score
FROM Crap.dbo.Posts AS p
WHERE p.OwnerUserId = @Id;
SELECT
@i = SUM(t.Score)
FROM @t AS t
WHERE t.OwnerUserId = 22656
GROUP BY t.OwnerUserId;
SELECT
@i = SUM(t.Score)
FROM @t AS t
GROUP BY t.OwnerUserId;
END;
GO
Hot Suet
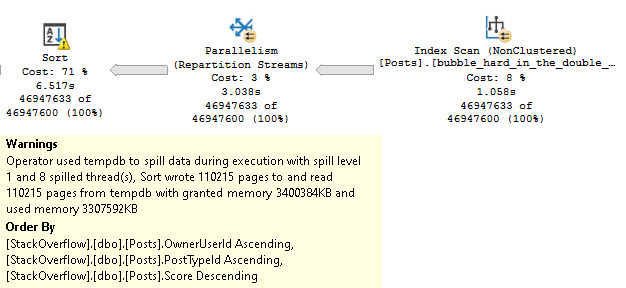
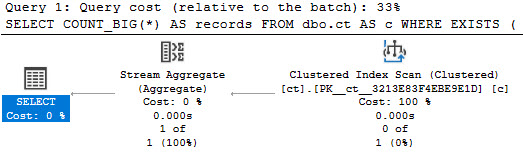
So like, the first thing I did was use SQL Query Stress to run this on a bunch of threads, and I didn’t see any tempdb contention.
So that’s cool. But now you have a bunch of stuff taking up space in memory. Precious memory. Do you have enough memory for all this?
Marinate on that.
Well, okay. Surely they must improve on all of the issues with table variables in some other way:
- Modifications can’t go parallel
- Bad estimates
- No column level stats
But, nope. No they don’t. It’s the same crap.
Minus the tempdb contetion.
Plus taking up space in memory.
But 2019
SQL Server 2019 does offer the same table level cardinality estimate for in-memory table variables as regular table variables.
If we flip database compatibility levels to 150, deferred compilation kicks in. Great. Are you on SQL Server 2019? Are you using compatibility level 150?
Don’t get too excited.
Let’s give this a test run in compat level 140:
DECLARE @i INT = 22656; EXEC dbo.TableVariableTest @Id = @i;
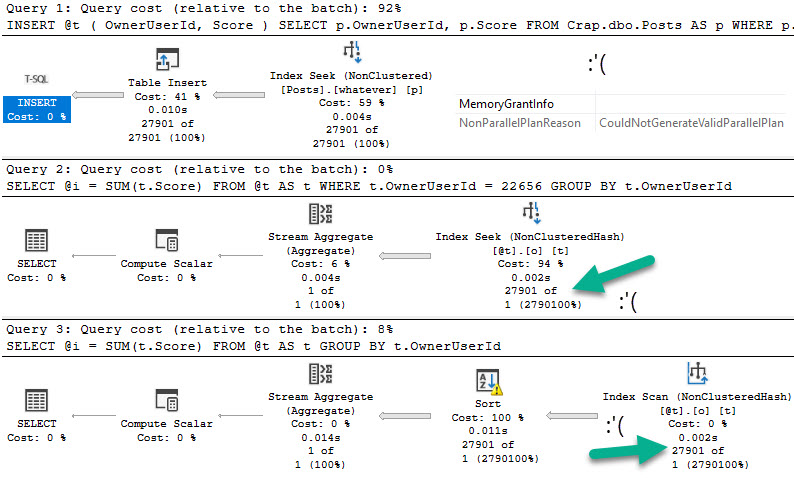
Switching over to compat level 150:
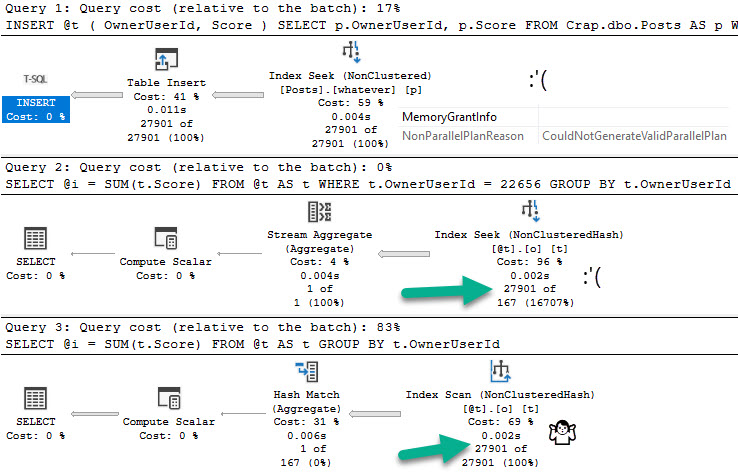
Candy Girl
So what do memory optimized table variables solve?
Not the problem that table variables in general cause.
They do help you avoid tempdb contention, but you trade that off for them taking up space in memory.
Precious memory.
Do you have enough memory?
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.