Find Your Data First
Most queries will have a where clause. I’ve seen plenty that don’t. Some of’em have surprised the people who developed them far more than they surprised me.
But let’s start there, because it’s a pretty important factor in how you design your indexes. There are all sorts of things that indexes can help, but the first thing we want indexes to do in general is help us locate data.
Why? Because the easier we can locate data, the easier we can eliminate rows early on in the query plan. I’m not saying we always need to have an index seek, but we generally want to filter out rows we don’t care about when we’re touching the table they’re in.
Burdens
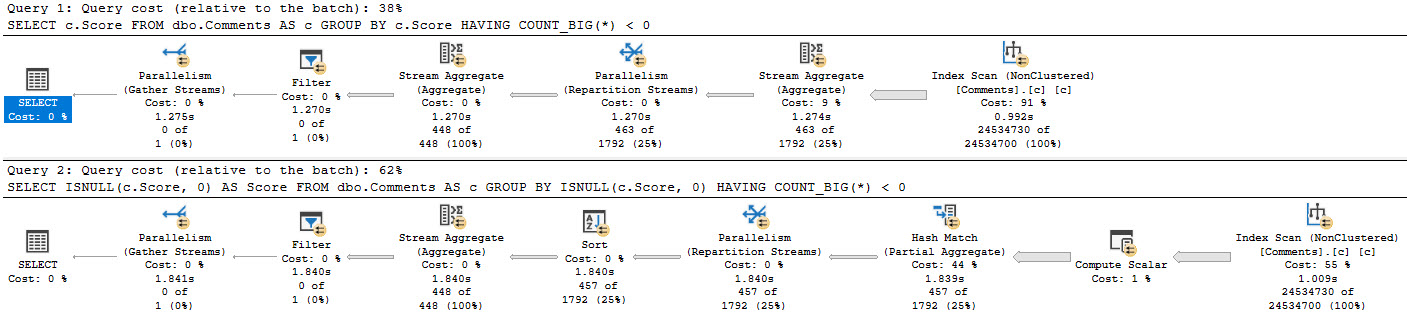
When we carry excess rows throughout the query plan, all sorts of things get impacted and can become less efficient. This goes hand in hand with cardinality estimation.
At the most severe, rows can’t be filtered when we touch tables, or even join them together, and we have to filter them out later.
I wrote about that here and here.
When that happens, it’s probably not your indexes that are the problem — it’s you.
You, specifically. You and your awful query.
We can take a page from the missing index request feature here: helping queries find the rows we care about should be a priority.
Sweet N’ Low
When people talk about the order predicates are evaluated in, the easiest way to influence that is with the order of columns in the key of your index.
Since that defines the sort order of the index, if you want a particular column to be evaluated first, put it first in the key of the index.
Selectivity is a decent attribute to consider, but not the end all be all of index design.
Equality predicates preserve ordering of other key columns in the index, which may or may not become important depending on what your query needs to accomplish.
Post Where
After the where clause, there are some rather uncontroversial things that indexes can help with:
Of course, they help with this because indexes put data in order.
Having rows in a deterministic order makes the above things either much easier (joining and grouping), or free (ordering).
How we decide on key column order necessarily has to take each part of the query involved into account.
If a query is so complicated that creating one index to help it would mean a dozen key columns, you probably need to break things down further.
Minnow
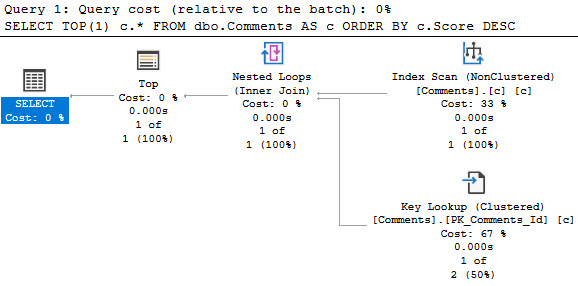
When you’re trying to figure out a good index for one query, you usually want to start with the where clause.
Not always, but it makes sense in most cases because it’s where you can find gains in efficiency.
If your index doesn’t support your where clause, you’re gonna see an index scan and freak out and go in search of your local seppuku parlor.
After that, look to other parts of your query that could help you eliminate rows. Joins are an obvious choice, and typically make good candidates for index key columns.
At this point, your query might be in good enough shape, and you can leave other things alone.
If so, great! You can make the check out to cache. I mean cash.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.