Instead, let’s talk about a different one: Editable Execution Plans.
We already have this to some degree via query hints and turning optimizer rules on and off.
The problem is that you have to remember all those crazy things, and some hints can affect multiple parts of the plan that you don’t want changed.
If the query you’re changing is in the middle of a big ol’ stored procedure, this process is even more tedious.
Glamorous
Let’s say you wanna experiment with different things, but not without re-running a query over and over to check on the plan with your written hints.
You could change:
Join order
Join types
Index choices
Aggregations
Seeks or Scans
Memory grants and fractions
Basically any element exposed in the XML would be up for grabs — I won’t list them all here, because I think you get the point.
Then you can run your query with your new plan.
If it’s a stunning success, you can force that plan.
Spool Removal
This has downsides, of course.
You could make things worse (but you could do that anyway — trust me, I do it all the time), you could get incorrect results, or errors if you remove certain operators (again, these are all things you can do by being silly anyway).
But, like query hints, this could be a really powerful tool in the hands of experienced query tuners, and people looking to get better at query tuning.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Indexes remind me of salt. And no, not because they’re fun to put on slugs.
More because it’s easy to tell when there’s too little or too much indexing going on. Just like when you taste food it’s easy to tell when there’s too much or too little salt.
Salt is also one of the few ingredients that is accepted across the board in chili.
To continue feeding a dead horse, the amount of indexing that each workload and system needs and can handle can vary quite a bit.
Appetite For Nonclustered
I’m not going to get into the whole clustered index thing here. My stance is that I’d rather take a chance having one than not having one on a table (staging tables aside). Sort of like a pocket knife: I’d rather have it and not need it than need it and not have it.
At some point, you’ve gotta come to terms with the fact that you need nonclustered indexes to help your queries.
But which ones should you add? Where do you even start?
Let’s walk through your options.
If Everything Is Awful
It’s time to review those missing index requests. My favorite tool for that is sp_BlitzIndex, of course.
Now, I know, those missing index requests aren’t perfect.
I’m gonna share an industry secret with you: No one else looking at your server for the first time is going to have a better idea. Knowing what indexes you need often takes time and domain/workload knowledge.
If you’re using sp_Blitzindex, take note of a few things:
How long the server has been up for: Less than a week is usually pretty weak evidence
The “Estimated Benefit” number: If it’s less than 5 million, you may wanna put it to the side in favor of more useful indexes in round one
Duplicate requests: There may be several requests for indexes on the same table with similar definitions that you can consolidate
Insane lists of Includes: If you see requests on (one or a few key columns) and include (every other column in the table), try just adding the key columns first
Of course, I know you’re gonna test all these in Dev first, so I won’t spend too much time on that aspect ?
If One Query Is Awful
You’re gonna wanna look at the query plan — there may be an imperfect missing index request in there.
Hip Hop Hooray
And yeah, these are just the missing index requests that end up in the DMVs added to the query plan XML.
They’re not any better, and they’re subject to the same rules and problems. And they’re not even ordered by Impact.
Cute. Real cute.
sp_BlitzCache will show them to you by Impact, but that requires you being able to get the query from the plan cache, which isn’t always possible.
If You Don’t Trust Missing Index Requests
And trust me, I’m with you there, think about the kind of things indexes are good at helping queries do:
Find data
Join data
Order data
Group data
Keeping those basic things in mind can help you start designing much smarter indexes than SQL Server can give you.
You can start finding all sorts of things in your query plans that indexes might change.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I use it often in my demo queries because I try to make the base query to show some behavior as simple as possible. That doesn’t always work out, but, whatever. I’m just a bouncer, after all.
The problem with very simple queries is that they may not trigger the parts of the optimizer that display the behavior I’m after. This is the result of them only reaching trivial optimization. For example, trivial plans will not go parallel.
If there’s one downside to making the query as simple as possible and using 1 = (SELECT 1), is that people get very distracted by it. Sometimes I think it would be less distracting to make the query complicated and make a joke about it instead.
The Trouble With Trivial
I already mentioned that trivial plans will never go parallel. That’s because they never reach that stage of optimization.
They also don’t reach the “index matching” portion of query optimization, which may trigger missing index requests, with all their fault and frailty.
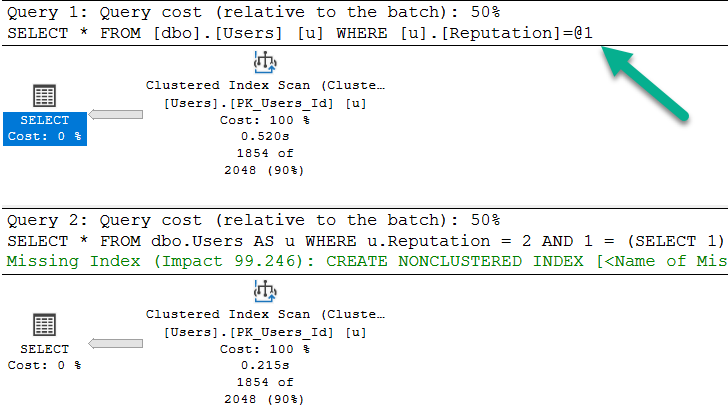
/*Nothing for you*/
SELECT *
FROM dbo.Users AS u
WHERE u.Reputation = 2;
/*Missing index requests*/
SELECT *
FROM dbo.Users AS u
WHERE u.Reputation = 2
AND 1 = (SELECT 1);
>greentext
Note that the bottom query gets a missing index request, and is not simple parameterized. The only reason the first query takes ~2x as long as the second query is because the cache was cold. In subsequent runs, they’re equal enough.
What Gets Fully Optimized?
Generally, things that introduce cost based decisions, and/or inflate the cost of a query > Cost Threshold for Parallelism.
Joins
Subqueries
Aggregations
Ordering without a supporting index
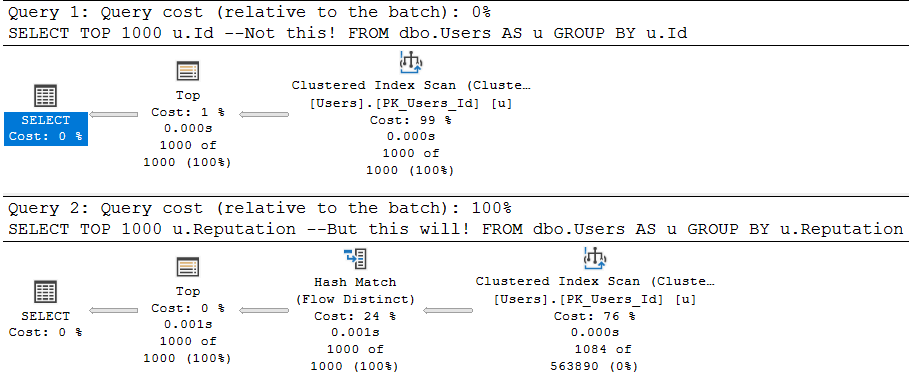
As a quick example, these two queries are fairly similar, but…
/*Unique column*/
SELECT TOP 1000 u.Id --Not this!
FROM dbo.Users AS u
GROUP BY u.Id;
/*Non-unique column*/
SELECT TOP 1000 u.Reputation --But this will!
FROM dbo.Users AS u
GROUP BY u.Reputation;
One attempts to aggregate a unique column (the pk of the Users table), and the other aggregates a non-unique column.
The optimizer is smart about this:
Flowy
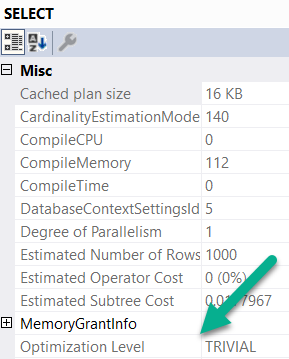
The first query is trivially optimized. If you want to see this, hit F4 when you’re looking at a query plan. Highlight the root operator (select, insert, update, delete — whatever), and look at the optimization level.
wouldacouldashoulda
Since aggregations have no effect on unique columns, the optimizer throws the group by away. Keep in mind, the optimizer has to know a column is unique for that to happen. It has to be guaranteed by a uniqueness constraint of some kind: primary key, unique index, unique constraint.
The second query introduces a choice, though! What’s the cheapest way to aggregate the Reputation column? Hash Match Aggregate? Stream Aggregate? Sort Distinct? The optimizer had to make a choice, so the optimization level is full.
What About Indexes?
Another component of trivial plan choice is when the choice of index is completely obvious. I typically see it when there’s either a) only a clustered index or b) when there’s a covering nonclustered index.
If there’s a non-covering nonclustered index, the choice of a key lookup vs. clustered index scan introduces that cost based decision, so trivial plans go out the window.
Here’s an example:
CREATE INDEX ix_creationdate
ON dbo.Users(CreationDate);
SELECT u.CreationDate, u.Id
FROM dbo.Users AS u
WHERE u.CreationDate >= '20131229';
SELECT u.Reputation, u.Id
FROM dbo.Users AS u
WHERE u.Reputation = 2;
SELECT u.Reputation, u.Id
FROM dbo.Users AS u WITH(INDEX = ix_creationdate)
WHERE u.Reputation = 2;
With an index only on CreationDate, the first query gets a trivial plan. There’s no cost based decision, and the index we created covers the query fully.
For the next two queries, the optimization level is full. The optimizer had a choice, illustrated by the third query. Thankfully it isn’t one that gets chosen unless we force the issue with a hint. It’s a very bad choice, but it exists.
When It’s Wack
Let’s say you create a constraint, because u loev ur datea.
ALTER TABLE dbo.Users
ADD CONSTRAINT cx_rep CHECK
( Reputation >= 1 AND Reputation <= 2000000 );
When we run this query, our newly created and trusted constraint should let it bail out without doing any work.
SELECT u.DisplayName, u.Age, u.Reputation
FROM dbo.Users AS u
WHERE u.Reputation = 0;
But two things happen:
my name is bogus
The plan is trivial, and it’s auto-parameterized.
The auto-parameterization means a plan is chosen where the literal value 0 is replaced with a parameter by SQL Server. This is normally “okay”, because it promotes plan reuse. However, in this case, the auto-parameterized plan has to be safe for any value we pass in. Sure, it was 0 this time, but next time it could be one within the range of valid reputations.
Since we don’t have an index on Reputation, we have to read the entire table. If we had an index on Reputation, it would still result in a lot of extra reads, but I’m using the clustered index here for ~dramatic effect~
Table 'Users'. Scan count 1, logical reads 44440
Of course, adding the 1 = (SELECT 1) thing to the end introduces full optimization, and prevents this.
The query plan without it is just a constant scan, and it does 0 reads.
Rounding Down
So there you have it. When you see me (or anyone else) use 1 = (SELECT 1), this is why. Sometimes when you write demos, a trivial plan or auto-parameterization can mess things up. The easiest way to get around it is to add that to the end of a query.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
After a while tuning a query, sometimes it’s fun to mess with the DOP it’s run at to see how things change.
I wouldn’t consider this a query tuning technique, more like a point of interest.
For a long time, when I’d look at a serial plan, and then a parallel plan for a query, the shape would be the same.
But that’s not always true.
DOP 1
At DOP 1, the plan looks like this:
Mergey-Toppy
DOP 2
At DOP 2, the plan looks like this:
Tutu
Mo’ DOP
At DOP 3-8, the plan looks like this:
Shapewear
No DOP
The DOP 2 plan has a significantly different shape than the serial, or more parallel plans.
It also chooses different types of joins.
Of course, we can use a merge join hint to have it pick the same plan as higher DOPs, but where’s the fun in that?
Anyway, the reason I found this interesting is because I always thought the general optimization process was:
Come up with a serial plan
If the plan cost is > CTFP, look at the parallel version of the serial plan
If the parallel version is cheaper, go with it
Though it appears like there’s an extra step where the optimizer considers multiple parallel alternatives to the serial plan, and not just the parallel version of the serial plan.
The process is closer to:
Come up with a serial plan
If the plan cost is > CTFP, create a *NEW* plan using parallelism
If the parallel version is cheaper, go with it
In many cases, the *NEW* plan will be the “same” as the serial plan, just using parallelism. The optimizer is a creature of habit, and applies the same rules and transformations.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
A lot of people still expect odd things from CTEs.
Performance fences
Cached results
There’s no clue in how they’re written that you won’t get those.
I’ve gone back and forth on whether or not this would be worthwhile. It totally could be, but it’d have to be pretty thoughtful.
Materialization vs. Fencing
The difference here is subtle but necessary. Right now, people will use TOP, which sets a row goal, and provides some logical isolation of the query in your CTE.
The problem remains that if that CTE is referenced via join > 1 time, the internal syntax is re-run each time.
Even if your query is fenced off, it is not materialized.
Fencing could leverage existing NOEXPAND hints, but materialization would likely require a new hint that performed the equivalent of SELECT… INTO #t, and then replaced references to the CTE alias with a pointer to the temporary object.
Indexing
One appeal of temp tables is that there is additional indexing flexibility, so any syntax would have to allow existing inline index syntax of temp tables to be used.
In other words, an index that may not make sense on a real table given your existing workload might make sense on a temp table. Or like, if a temp table is the result of joining two tables together, there could be a compound index you could create on the temp table that’s otherwise impossible to create.
Next feature request: multi-table indexes ?
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Often when query tuning, I’ll try a change that I think makes sense, only to have it backfire.
It’s not that the query got slower, it’s that the results that came back were wrong different.
Now, this can totally happen because of a bug in previously used logic, but that’s somewhat rare.
And wrong different results make testers nervous. Especially in production.
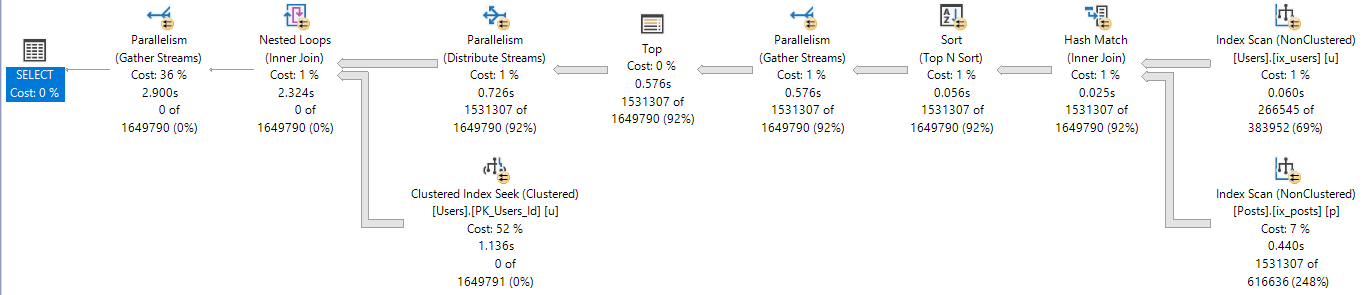
Here’s a Very Cheeky™ example.
Spread’em
This is my starting query. If I run it enough times, I’ll get a billion missing index requests.
WITH topusers AS
(
SELECT TOP (1)
u.Id, u.DisplayName
FROM dbo.Users AS u
ORDER BY u.Reputation DESC
)
SELECT u.Id,
u.DisplayName,
SUM(p.Score * 1.0) AS PostScore,
SUM(c.Score * 1.0) AS CommentScore,
COUNT_BIG(*) AS CountForSomeReason
FROM topusers AS u
JOIN dbo.Posts AS p
ON p.OwnerUserId = u.Id
JOIN dbo.Comments AS c
ON c.UserId = u.Id
WHERE p.Score >= 5
AND c.Score >= 1
GROUP BY u.Id, u.DisplayName;
For the sake of argument, I’ll add them all. Here they are:
CREATE INDEX ix_tabs
ON dbo.Users ( Reputation DESC, Id )
INCLUDE ( DisplayName );
CREATE INDEX ix_spaces
ON dbo.Users ( Id, Reputation DESC )
INCLUDE ( DisplayName );
CREATE INDEX ix_coke
ON dbo.Comments ( Score) INCLUDE( UserId );
CREATE INDEX ix_pepsi
ON dbo.Posts ( Score ) INCLUDE( OwnerUserId );
CREATE NONCLUSTERED INDEX ix_tastes_great
ON dbo.Posts ( OwnerUserId, Score );
CREATE NONCLUSTERED INDEX ix_less_filling
ON dbo.Comments ( UserId, Score );
With all those indexes, the query is still dog slow.
Maybe It’s Me
I’ll take my own advice. Let’s break the query up a little bit.
DROP TABLE IF EXISTS #topusers;
WITH topusers AS
(
SELECT TOP (1)
u.Id, u.DisplayName
FROM dbo.Users AS u
ORDER BY u.Reputation DESC
)
SELECT *
INTO #topusers
FROM topusers;
CREATE UNIQUE CLUSTERED INDEX ix_whatever
ON #topusers(Id);
SELECT u.Id,
u.DisplayName,
SUM(p.Score * 1.0) AS PostScore,
SUM(c.Score * 1.0) AS CommentScore,
COUNT_BIG(*) AS CountForSomeReason
FROM #topusers AS u
JOIN dbo.Posts AS p
ON p.OwnerUserId = u.Id
JOIN dbo.Comments AS c
ON c.UserId = u.Id
WHERE p.Score >= 5
AND c.Score >= 1
GROUP BY u.Id, u.DisplayName;
Still dog slow.
Variability
Alright, I’m desperate now. Let’s try this.
DECLARE @Id INT,
@DisplayName NVARCHAR(40);
SELECT TOP (1)
@Id = u.Id,
@DisplayName = u.DisplayName
FROM dbo.Users AS u
ORDER BY u.Reputation DESC;
SELECT @Id AS Id,
@DisplayName AS DisplayName,
SUM(p.Score * 1.0) AS PostScore,
SUM(c.Score * 1.0) AS CommentScore,
COUNT_BIG(*) AS CountForSomeReason
FROM dbo.Posts AS p
JOIN dbo.Comments AS c
ON c.UserId = p.OwnerUserId
WHERE p.Score >= 5
AND c.Score >= 1
AND (c.UserId = @Id OR @Id IS NULL)
AND (p.OwnerUserId = @Id OR @Id IS NULL);
Let’s get some worst practices involved. That always goes well.
Except here.
Getting the right results seemed like it was destined to be slow.
Differently Resulted
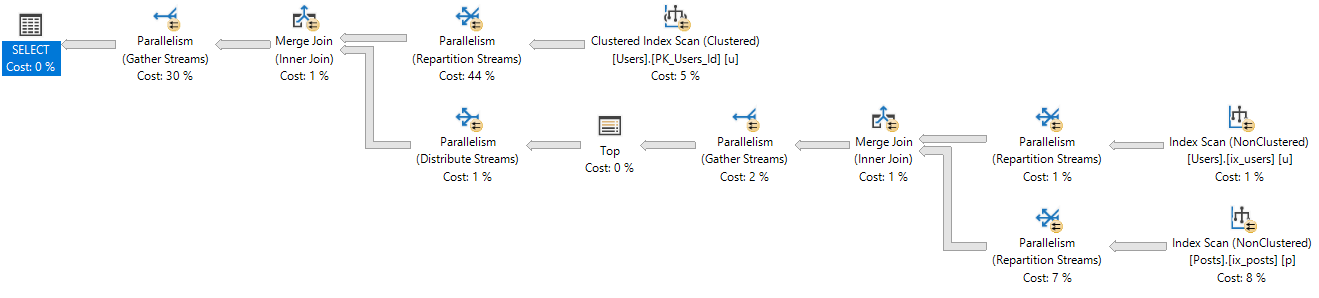
At this point, I tried several rewrites that were fast, but wrong.
What I had missed, and what Joe Obbish pointed out to me, is that I needed a cross join and some math to make it all work out.
WITH topusers AS
(
SELECT TOP (1)
u.Id, u.DisplayName
FROM dbo.Users AS u
ORDER BY u.Reputation DESC
)
SELECT t.Id AS Id,
t.DisplayName AS DisplayName,
p_u.PostScoreSub * c_u.CountCSub AS PostScore,
c_u.CommentScoreSub * p_u.CountPSub AS CommentScore,
c_u.CountCSub * p_u.CountPSub AS CountForSomeReason
FROM topusers AS t
JOIN ( SELECT p.OwnerUserId,
SUM(p.Score * 1.0) AS PostScoreSub,
COUNT_BIG(*) AS CountPSub
FROM dbo.Posts AS p
WHERE p.Score >= 5
GROUP BY p.OwnerUserId ) AS p_u
ON p_u.OwnerUserId = t.Id
CROSS JOIN ( SELECT c.UserId, SUM(c.Score * 1.0) AS CommentScoreSub, COUNT_BIG(*) AS CountCSub
FROM dbo.Comments AS c
WHERE c.Score >= 1
GROUP BY c.UserId ) AS c_u
WHERE c_u.UserId = t.Id;
This finishes instantly, with the correct results.
The value of a college education!
Realizations and Slowness
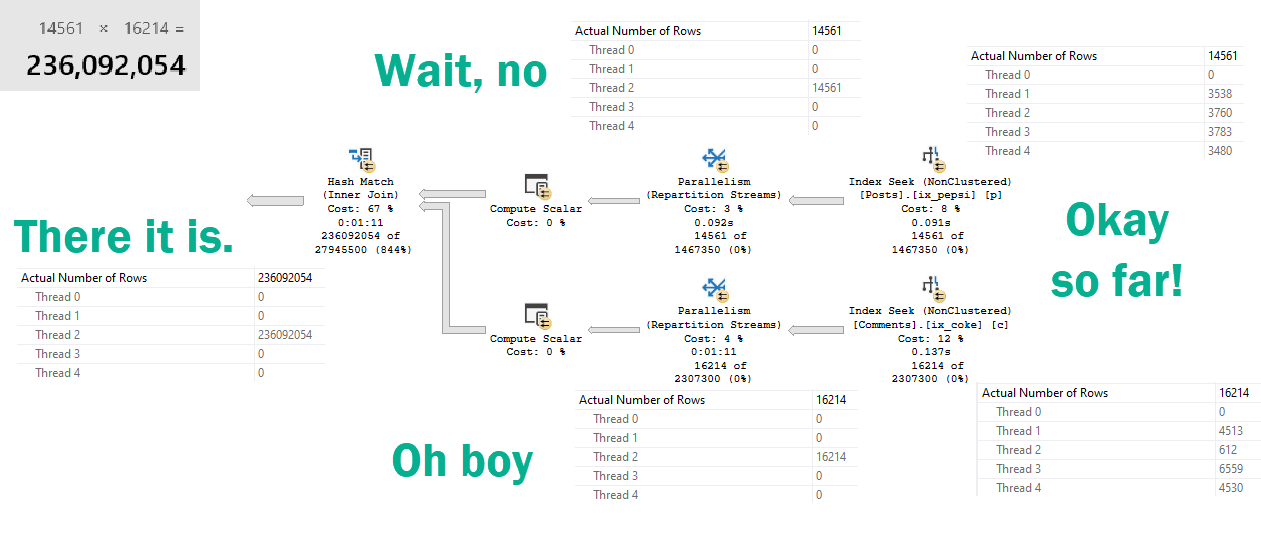
After thinking about Joe’s rewrite, I had a terrible thought.
All the rewrites that were correct but slow had gone parallel.
“Parallel”
Allow me to illustrate.
In a row?
Repartition Streams usually does the opposite.
But here, it puts all the rows on a single thread.
“For correctness”
Which ends up in a 236 million row parallel-but-single-threaded-cross-hash-join.
SQL Server uses the correct join (inner or outer) and adds projections where necessary to honour all the semantics of the original query when performing internal translations between apply and join.
The differences in the plans can all be explained by the different semantics of aggregates with and without a group by clause in SQL Server.
What’s amazing and frustrating about the optimizer is that it considers all sorts of different ways to rewrite your query.
In milliseconds.
It may have even thought about a plan that would have been very fast.
But we ended up with this one, because it looked cheap.
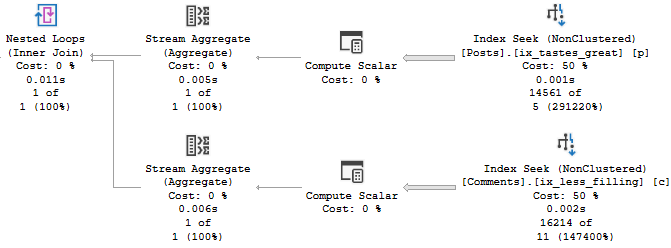
Untuneable
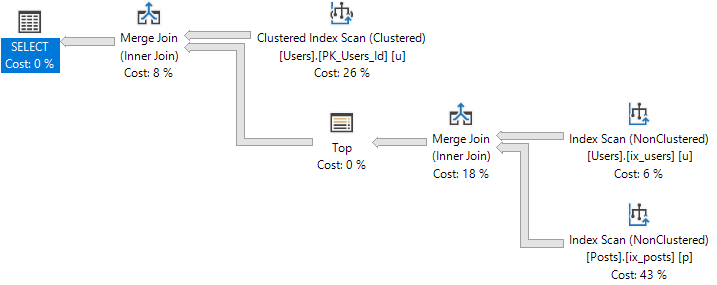
The plan for Joe’s version of the query is amazingly simple.
Bruddah.
Sometimes giving the optimizer a different query to work with helps, and sometimes it doesn’t.
Rewriting queries is tough business. When you change things and still get the same plan, it can be really frustrating.
Just know that behind the scenes the optimizer is working hard to rewrite your queries, too.
If you really want to change the execution plan you end up with, you need to present the logic to the optimizer in different ways, and often with different indexes to use.
Other times, you just gotta ask Joe.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
In SQL Server 2019, a few cool performance features under the intelligent query processing umbrella depend on cardinality estimation.
Batch Mode For Row Store (which triggers the next two things)
Adaptive Joins
Memory Grant Feedback
If SQL Server doesn’t estimate > 130k(ish) rows are gonna hop on through your query, you don’t get the Batch Mode processing that allows for Adaptive Joins and Memory Grant feedback. If you were planning on those things helping with parameter sniffing, you now have something else to contend with.
Heft
Sometimes you might get a plan with all that stuff in it. Sometimes you might not.
The difference between a big plan and little plan just got even more confusing.
Let’s say you have a stored procedure that looks like this:
CREATE OR ALTER PROCEDURE dbo.lemons(@PostTypeId INT)
AS
BEGIN
SELECT OwnerUserId,
PostTypeId,
SUM(Score * 1.0) AS TotalScore,
COUNT_BIG(*) AS TotalPosts
FROM dbo.Posts AS p
JOIN dbo.Users AS u
ON p.OwnerUserId = u.Id
WHERE PostTypeId = @PostTypeId
AND u.Reputation > 1
GROUP BY OwnerUserId,
PostTypeId
HAVING COUNT_BIG(*) > 100;
END
GO
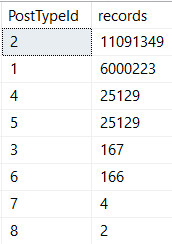
There’s quite a bit of skew between post types!
Working my way down
Which means different parameters will get different plans, depending on which one comes first.
At 12 seconds, one might accuse our query of sub-par performance.
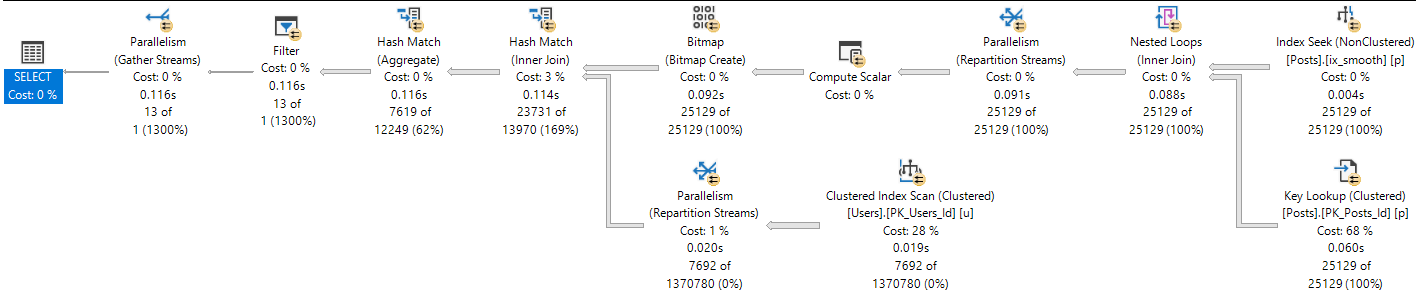
One and Lonely
When one runs first, the plan is insanely different.
22 2s
It’s about 10 seconds faster. And the four plan?
Not too shabby.
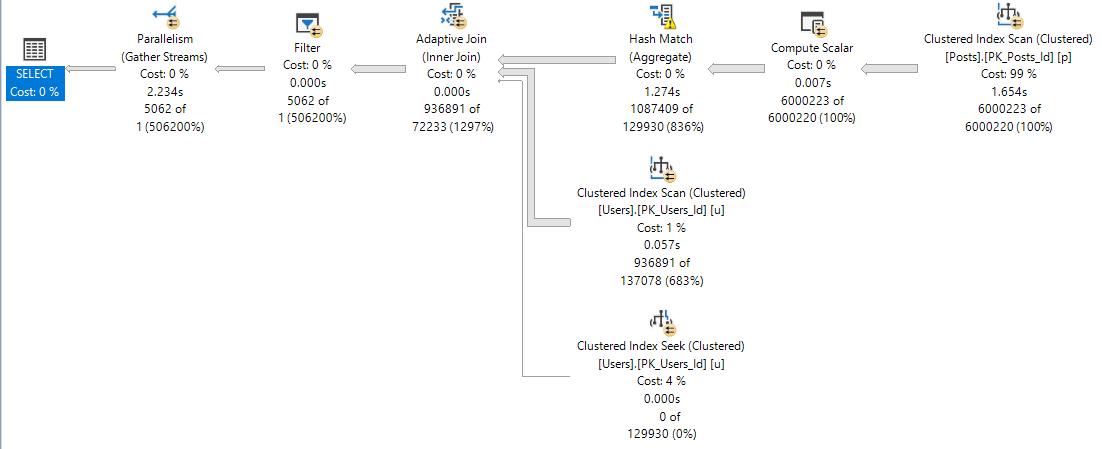
Four play
We notice the difference between 116ms and 957ms in SSMS.
Are application end users aware of ~800ms? Sometimes I wonder.
Alma Matters
The adaptive join plan with batch mode operators is likely a better plan for a wider range of values than the small plan.
Batch mode is generally more efficient with larger row counts. The adaptive join means no one who doesn’t belong in nested loops hell will get stuck there (probably), and SQL Server will take a look at the query in between runs to try to find a happy memory grant medium (this doesn’t always work splendidly, but I like the effort).
Getting to the point, if you’re going to SQL Server 2019, and you want to get all these new goodies to help you avoid parameter sniffing, you’re gonna have to start getting used to those OPTIMIZE FOR hints, and using a value that results in getting the adaptive plan.
I wish there was a query hint that pushed the optimizer towards picking this sort of plan, so we don’t have to rely on potentially changing values to optimize for.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Rounding out a few posts about SQL Server’s choice of one or more indexes depending on the cardinality estimates of literal values.
Today we’re going to look at how indexes can contribute to parameter sniffing issues.
It’s Friday and I try to save the real uplifting stuff for these posts.
Procedural
Here’s our stored procedure! A real beaut, as they say.
CREATE OR ALTER PROCEDURE dbo.lemons(@Score INT)
AS
BEGIN
SELECT TOP (1000)
p.Id,
p.AcceptedAnswerId,
p.AnswerCount,
p.CommentCount,
p.CreationDate,
p.LastActivityDate,
DATEDIFF( DAY,
p.CreationDate,
p.LastActivityDate
) AS LastActivityDays,
p.OwnerUserId,
p.Score,
u.DisplayName,
u.Reputation
FROM dbo.Posts AS p
JOIN dbo.Users AS u
ON u.Id = p.OwnerUserId
WHERE p.PostTypeId = 1
AND p.Score > @Score
ORDER BY u.Reputation DESC;
END
GO
Here are the indexes we currently have.
CREATE INDEX smooth
ON dbo.Posts(Score, OwnerUserId);
CREATE INDEX chunky
ON dbo.Posts(OwnerUserId, Score)
INCLUDE(AcceptedAnswerId, AnswerCount, CommentCount, CreationDate, LastActivityDate);
Looking at these, it’s pretty easy to imagine scenarios where one or the other might be chosen.
Heck, even a dullard like myself could figure it out.
Rare Score
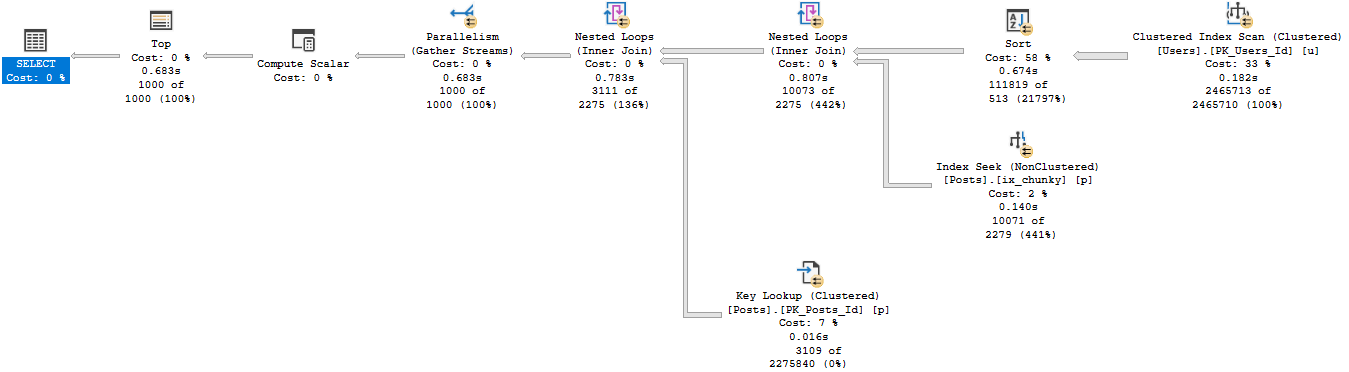
Running the procedure for an uncommon score, we get a tidy little loopy little plan.
EXEC dbo.lemons @Score = 385;
It’s hard to hate a plan that sinishes in 59ms
Of course, that plan applied to a less common score results in tomfoolery of the highest order.
Lowest order?
I’m not sure.
Except when it takes 14 seconds.
In both of these queries, we used our “smooth” index.
Who created that thing? We don’t know. It’s been there since the 90s.
Sloane Square
If we recompile, and start with 0 first, we get a uh…
Well darnit
We get an equally little loopy little plan.
The difference? Join order, and now we use our chunky index.
Running our proc for the uncommon value…
Don’t make fun of me later.
Well, that doesn’t turn out so bad either.
Pound Sand
When you’re troubleshooting parameter sniffing, the plans might not be totally different.
Sometimes a subtle change of index usage can really throw gas on things.
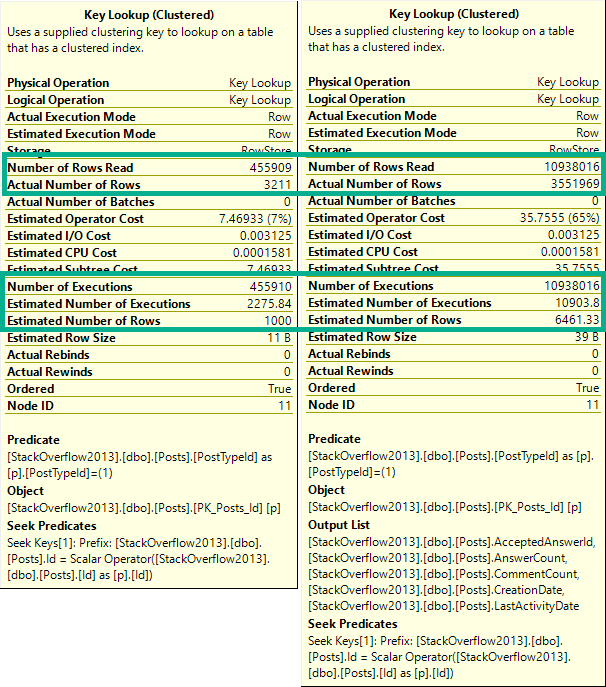
It’s also a good example of how Key Lookups aren’t always a huge problem.
Both plans had them, just in different places.
Which one is bad?
It would be hard to figure out if one is good or bad in estimated or cached plans.
Especially because they only tell you compile time parameters, and not runtime parameters.
Neither one is a good time parameter.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.