Checklist
This is always fun to talk to people about, because of all the misconceptions around the concept.
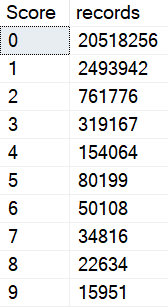
You need to find rows in one table that don’t have a match in another table. Maybe it’s a reconciliation process, maybe it’s part of ETL or something.
Doesn’t matter. Pay attention!
Choices
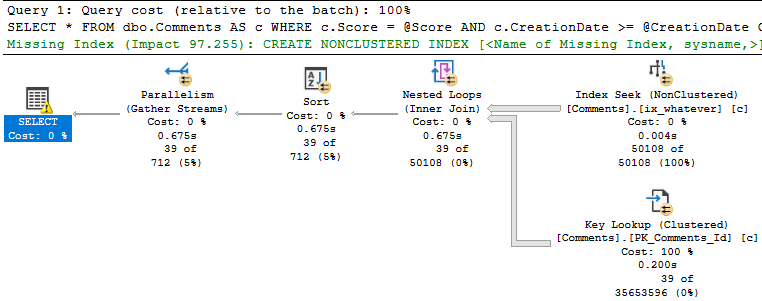
The way most people will write this query on the first try is like this:
SELECT COUNT_BIG(u.Id) AS records
FROM dbo.Users AS u
LEFT JOIN dbo.Posts AS p
ON u.Id = p.OwnerUserId
WHERE p.Id IS NULL;
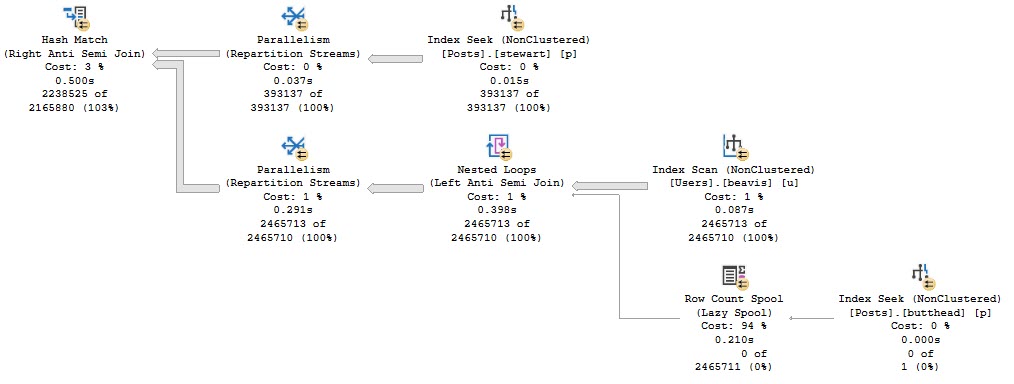
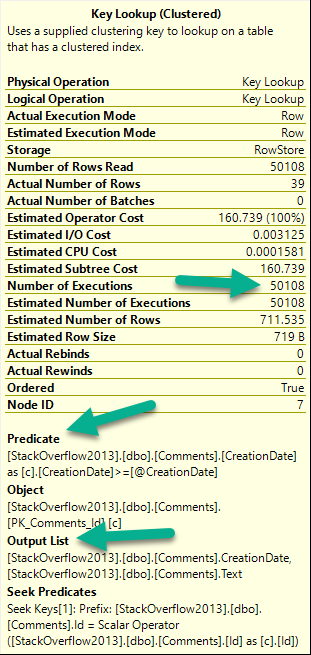
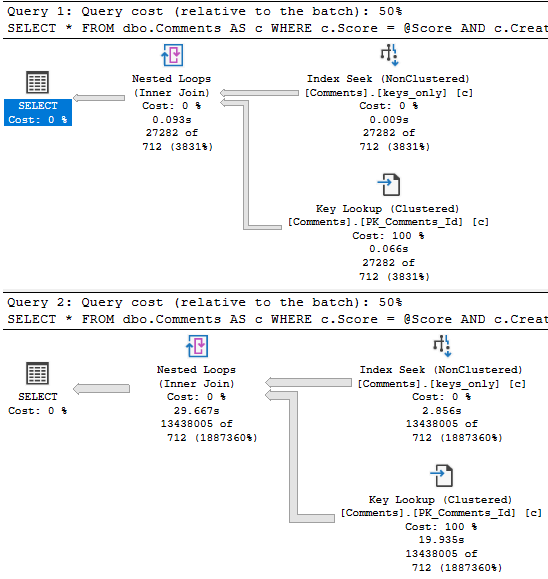
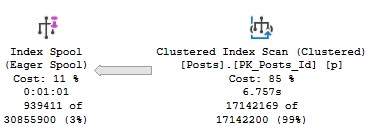
The query plan has one of my (generally) least favorite things in it: A filter.
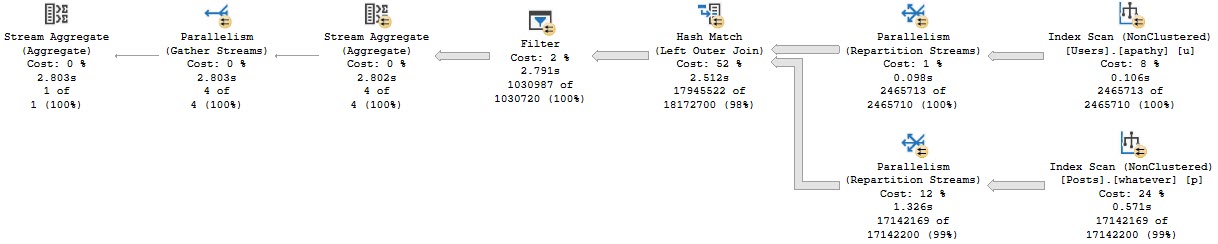
What’s the filter doing?

Looking for NULL values after the join. Yuck.
Better Choices
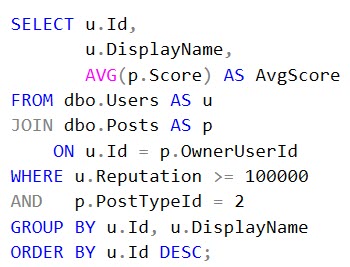
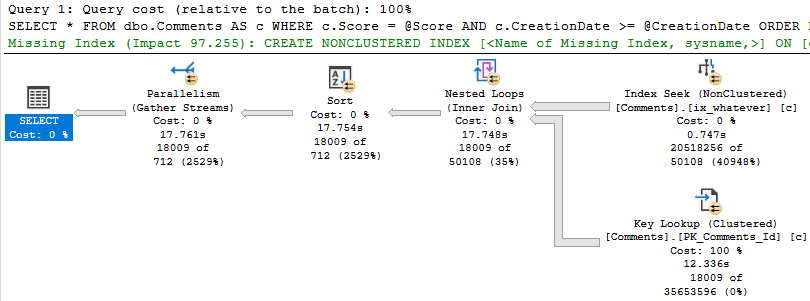
Expressed more SQL-y, we could use NOT EXISTS.
SELECT COUNT_BIG(u.Id) AS records
FROM dbo.Users AS u
WHERE NOT EXISTS ( SELECT 1/0
FROM dbo.Posts AS p
WHERE p.OwnerUserId = u.Id );
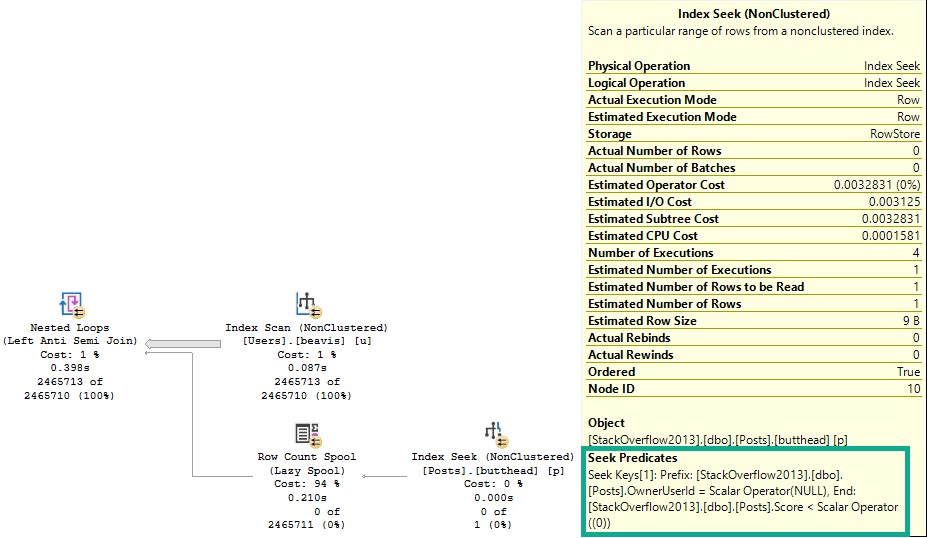
I mean, look, the Id column in the Posts table is the PK/CX. That means it can’t be NULL, unless it’s a non-matched row in a left join.
If that column is NULL, then every other column will be NULL too. You don’t ever need to select any data from the Posts table.
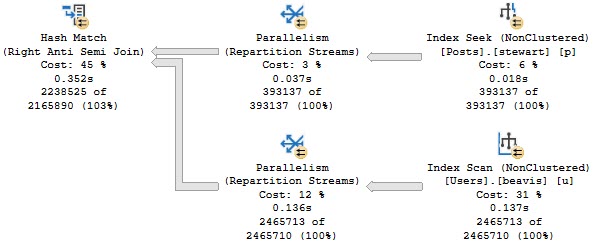
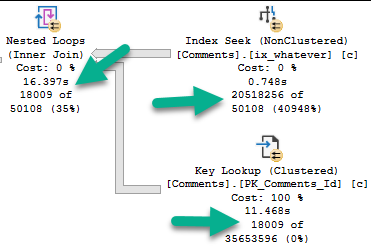
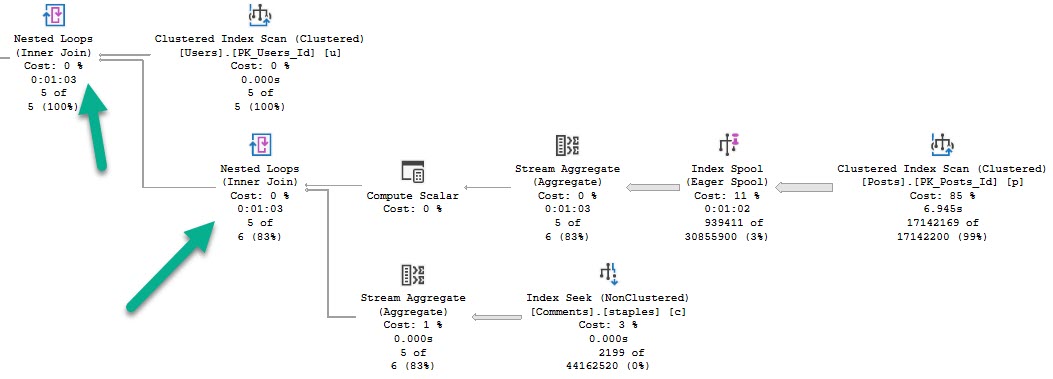
The query plan looks like this now:

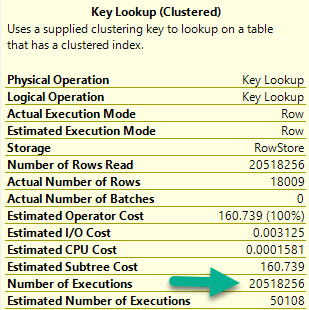
This performs better (under most circumstances), and gets some additional optimizations: A Bitmap, and a pre-aggregation of the OwnerUserId column in the Posts table.
Other Than Speed?
The Not Exists query will ask for around ~200MB less memory to run.
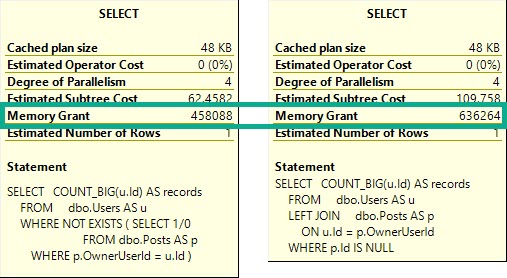
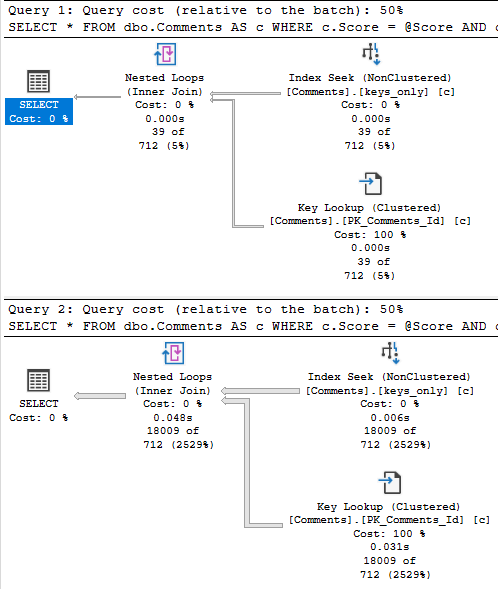
Why is this? Why is there such a difference between logically equivalent queries?
The Left Join version forces both tables to be fully joined together, which produces matches and non-matches.
After the join, we eliminate non-matches in the Filter. This is why I’m generally suspicious of Filter operators. They often mean we’ve some expression or complication in our logic that prevents the optimizer from eliminating rows earlier. This is to be expected when we do something like generate and filter on a row number — the row number doesn’t exist until the query runs, and has to be filtered later than existing data.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.