Let’s take a brief moment to talk about terminology here, so you don’t go getting yourself all tied up in knots:
Parameter Sniffing: When the optimizer creates and caches a plan based on a set of parameter(s) for reuse
Parameter Sensitivity: When a cached plan for one set of parameter(s) is not a good plan for other sets of parameter(s)
The first one is a usually-good thing, because your SQL Server won’t spend a lot of time compiling plans constantly. This is obviously more important for OLTP workloads than for data warehouses.
This can pose problems in either type of environment when data is skewed towards one or more values, because queries that need to process a lot of rows typically need a different execution plan strategy than queries processing a small number of rows.
This seems a good fit for the Intelligent Query Processing family of SQL Server features, because fixing it sometimes requires a certain level of dynamism.
Choice 2 Choice
The reason this sort of thing can happen often comes down to indexing. That’s obviously not the only thing. Even a perfect index won’t make nested loops more efficient than a hash join (and vice versa) under the right circumstances.
Probably the most classic parameter sensitivity issue, and why folks spend a long time trying to fix them, is the also-much-maligned Lookup.
But consider the many other things that might happen in a query plan that will hamper performance.
Join type
Join order
Memory grants
Parallelism
Aggregate type
Sort/Sort Placement
Batch Mode
The mind boggles at all the possibilities. This doesn’t even get into all the wacky and wild things that can mess SQL Server’s cost-based optimizer up a long the way.
With SQL Server 2022, we’ve finally got a starting point for resolving this issue.
In tomorrow’s post, we’ll talk a bit about how this new feature works to help with your parameter sensitivity issues, which are issues.
Not your parameter sniffing issues, which are not issues.
For the rest of the week, I’m going to dig deeper into some of the stuff that the documentation glosses over, where it helps, and show you a situation where it should kick in and help but doesn’t.
Keep in mind that these are early thoughts, and I expect things to evolve both as RTM season approaches, and as Cumulative Updates are released for SQL Server 2022.
Remember scalar UDF inlining? That thing morphed quite a bit.
Can’t wait for all of you to get on SQL Server 2019 and experience it.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
SQL Server 2022 has a new feature in it to help with parameter sensitive query plans.
That is great. Parameter sensitivity, sometimes just called parameter sniffing, can be a real bear to track down, reproduce, and fix.
In a lot of the client work I do, I end up using dynamic SQL like this to get things to behave:
But with this new feature, you get some of the same fixes without having to interfere with the query at all.
How It Works
You can read the full documentation here. But you don’t read the documentation, and the docs are missing some details at the moment anyway.
It only works on equality predicates right now
It only works on one predicate per query
It only gives you three query plan choices, based on stats buckets
There’s also some additional notes in the docs that I’m going to reproduce here, because this is where you’re gonna get tripped up, if your scripts associate statements in the case with calling stored procedures, or using object identifiers from Query Store.
For each query variant mapping to a given dispatcher:
The query_plan_hash is unique. This column is available in sys.dm_exec_query_stats, and other Dynamic Management Views and catalog tables.
The plan_handle is unique. This column is available in sys.dm_exec_query_stats, sys.dm_exec_sql_text, sys.dm_exec_cached_plans, and in other Dynamic Management Views and Functions, and catalog tables.
The query_hash is common to other variants mapping to the same dispatcher, so it’s possible to determine aggregate resource usage for queries that differ only by input parameter values. This column is available in sys.dm_exec_query_stats, sys.query_store_query, and other Dynamic Management Views and catalog tables.
The sql_handle is unique due to special PSP optimization identifiers being added to the query text during compilation. This column is available in sys.dm_exec_query_stats, sys.dm_exec_sql_text, sys.dm_exec_cached_plans, and in other Dynamic Management Views and Functions, and catalog tables. The same handle information is available in the Query Store as the last_compile_batch_sql_handle column in the sys.query_store_query catalog table.
The query_id is unique in the Query Store. This column is available in sys.query_store_query, and other Query Store catalog tables.
The problem is that, sort of like dynamic SQL, this makes each different plan/statement impossible to tie back to the procedure.
What I’ve Tried
Here’s a procedure that is eligible for parameter sensitivity training:
Plain text
Copy to clipboard
Open code in new window
EnlighterJS 3 Syntax Highlighter
CREATEORALTERPROCEDURE
dbo.SQL2022
(
@ParentId int
)
AS
BEGIN
SETNOCOUNT, XACT_ABORT ON;
SELECTTOP (10)
u.DisplayName,
p.*
FROM dbo.Posts AS p
JOIN dbo.Users AS u
ON p.OwnerUserId = u.Id
WHERE p.ParentId = @ParentId
ORDER BY u.Reputation DESC;
END;
GO
CREATE OR ALTER PROCEDURE
dbo.SQL2022
(
@ParentId int
)
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
SELECT TOP (10)
u.DisplayName,
p.*
FROM dbo.Posts AS p
JOIN dbo.Users AS u
ON p.OwnerUserId = u.Id
WHERE p.ParentId = @ParentId
ORDER BY u.Reputation DESC;
END;
GO
CREATE OR ALTER PROCEDURE
dbo.SQL2022
(
@ParentId int
)
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
SELECT TOP (10)
u.DisplayName,
p.*
FROM dbo.Posts AS p
JOIN dbo.Users AS u
ON p.OwnerUserId = u.Id
WHERE p.ParentId = @ParentId
ORDER BY u.Reputation DESC;
END;
GO
Here’s the cool part! If I run this stored procedure back to back like so, I’ll get two different query plans without recompiling or writing dynamic SQL, or anything else:
Plain text
Copy to clipboard
Open code in new window
EnlighterJS 3 Syntax Highlighter
EXEC dbo.SQL2022
@ParentId = 184618;
GO
EXEC dbo.SQL2022
@ParentId = 0;
GO
EXEC dbo.SQL2022
@ParentId = 184618;
GO
EXEC dbo.SQL2022
@ParentId = 0;
GO
EXEC dbo.SQL2022
@ParentId = 184618;
GO
EXEC dbo.SQL2022
@ParentId = 0;
GO
amazing!
It happens because the queries look like this under the covers:
SELECT TOP (10)
u.DisplayName,
p.*
FROM dbo.Posts AS p
JOIN dbo.Users AS u
ON p.OwnerUserId = u.Id
WHERE p.ParentId = @ParentId
ORDER BY u.Reputation DESC
OPTION (PLAN PER VALUE(QueryVariantID = 1, predicate_range([StackOverflow2010].[dbo].[Posts].[ParentId] = @ParentId, 100.0, 1000000.0)))
SELECT TOP (10)
u.DisplayName,
p.*
FROM dbo.Posts AS p
JOIN dbo.Users AS u
ON p.OwnerUserId = u.Id
WHERE p.ParentId = @ParentId
ORDER BY u.Reputation DESC
OPTION (PLAN PER VALUE(QueryVariantID = 3, predicate_range([StackOverflow2010].[dbo].[Posts].[ParentId] = @ParentId, 100.0, 1000000.0)))
SELECT TOP (10)
u.DisplayName,
p.*
FROM dbo.Posts AS p
JOIN dbo.Users AS u
ON p.OwnerUserId = u.Id
WHERE p.ParentId = @ParentId
ORDER BY u.Reputation DESC
OPTION (PLAN PER VALUE(QueryVariantID = 1, predicate_range([StackOverflow2010].[dbo].[Posts].[ParentId] = @ParentId, 100.0, 1000000.0)))
SELECT TOP (10)
u.DisplayName,
p.*
FROM dbo.Posts AS p
JOIN dbo.Users AS u
ON p.OwnerUserId = u.Id
WHERE p.ParentId = @ParentId
ORDER BY u.Reputation DESC
OPTION (PLAN PER VALUE(QueryVariantID = 3, predicate_range([StackOverflow2010].[dbo].[Posts].[ParentId] = @ParentId, 100.0, 1000000.0)))
Where Things Break Down
Normally, sp_BlitzCache will go through whatever statements it picks up and associate them with the parent object:
JOIN sys.dm_exec_procedure_stats s ON p.SqlHandle = s.sql_handle
WHERE QueryType = 'Statement'
ANDSPID = @@SPID
OPTION (RECOMPILE);
RAISERROR(N'Attempting to get stored procedure name for individual statements', 0, 1) WITH NOWAIT;
UPDATE p
SET QueryType = QueryType + ' (parent ' +
+ QUOTENAME(OBJECT_SCHEMA_NAME(s.object_id, s.database_id))
+ '.'
+ QUOTENAME(OBJECT_NAME(s.object_id, s.database_id)) + ')'
FROM ##BlitzCacheProcs p
JOIN sys.dm_exec_procedure_stats s ON p.SqlHandle = s.sql_handle
WHERE QueryType = 'Statement'
AND SPID = @@SPID
OPTION (RECOMPILE);
RAISERROR(N'Attempting to get stored procedure name for individual statements', 0, 1) WITH NOWAIT;
UPDATE p
SET QueryType = QueryType + ' (parent ' +
+ QUOTENAME(OBJECT_SCHEMA_NAME(s.object_id, s.database_id))
+ '.'
+ QUOTENAME(OBJECT_NAME(s.object_id, s.database_id)) + ')'
FROM ##BlitzCacheProcs p
JOIN sys.dm_exec_procedure_stats s ON p.SqlHandle = s.sql_handle
WHERE QueryType = 'Statement'
AND SPID = @@SPID
OPTION (RECOMPILE);
Since SQL handles no longer match, we’re screwed. I also looked into doing something like this, but there’s nothing here!
Plain text
Copy to clipboard
Open code in new window
EnlighterJS 3 Syntax Highlighter
SELECT
p.plan_handle,
pa.attribute,
object_name =
OBJECT_NAME(CONVERT(int, pa.value)),
pa.value
FROM
(
SELECT 0x05000600B7F6C349E0824C498D02000001000000000000000000000000000000000000000000000000000000 --Proc plan handle
UNIONALL
SELECT 0x060006005859A71BB0304D498D02000001000000000000000000000000000000000000000000000000000000 --Query plan handle
UNIONALL
SELECT 0x06000600DCB1FC11A0224D498D02000001000000000000000000000000000000000000000000000000000000 --Query plan handle
) AS p (plan_handle)
CROSSAPPLY sys.dm_exec_plan_attributes (p.plan_handle) AS pa
WHERE pa.attribute = 'objectid';
SELECT
p.plan_handle,
pa.attribute,
object_name =
OBJECT_NAME(CONVERT(int, pa.value)),
pa.value
FROM
(
SELECT 0x05000600B7F6C349E0824C498D02000001000000000000000000000000000000000000000000000000000000 --Proc plan handle
UNION ALL
SELECT 0x060006005859A71BB0304D498D02000001000000000000000000000000000000000000000000000000000000 --Query plan handle
UNION ALL
SELECT 0x06000600DCB1FC11A0224D498D02000001000000000000000000000000000000000000000000000000000000 --Query plan handle
) AS p (plan_handle)
CROSS APPLY sys.dm_exec_plan_attributes (p.plan_handle) AS pa
WHERE pa.attribute = 'objectid';
SELECT
p.plan_handle,
pa.attribute,
object_name =
OBJECT_NAME(CONVERT(int, pa.value)),
pa.value
FROM
(
SELECT 0x05000600B7F6C349E0824C498D02000001000000000000000000000000000000000000000000000000000000 --Proc plan handle
UNION ALL
SELECT 0x060006005859A71BB0304D498D02000001000000000000000000000000000000000000000000000000000000 --Query plan handle
UNION ALL
SELECT 0x06000600DCB1FC11A0224D498D02000001000000000000000000000000000000000000000000000000000000 --Query plan handle
) AS p (plan_handle)
CROSS APPLY sys.dm_exec_plan_attributes (p.plan_handle) AS pa
WHERE pa.attribute = 'objectid';
The object identifiers are 0 for these two queries.
One Giant Leap
This isn’t a complaint as much as it is a warning. If you’re a monitoring tool vendor, script writer, or script relier, this is gonna make things harder for you.
Perhaps it’s something that can or will be fixed in a future build, but I have no idea at all what’s going to happen with it.
Maybe we’ll have to figure out a different way to do the association, but stored procedures don’t get query hashes or query plan hashes, only the queries inside it do.
This is gonna be a tough one!
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
When people hear the words “parameter sniffing”, there’s almost a universally bad reaction. They lose their minds and start raving about how to “fix” it.
Recompiling everything
Using optimize for unknown hints
Using local variables
Clearing the plan cache
In today’s post, I’m gonna show you two videos from my paid training:
Intro to parameter sniffing
Parameter sniffing recap
Those explain why parameter sniffing is so tough to deal with, and why all the stuff up there in that list isn’t really the greatest idea.
There’s a whole bunch of stuff in between those two videos where I’ll teach you specifics about fixing parameter sniffing problems.
If that’s the content you’re after, hit the link at the very end of the post for 75% off my entire training catalog.
Intro To Parameter Sniffing
Parameter Sniffing Recap
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
In the Stack Overflow database, the biggest (and probably most important) table is Posts.
The Comments table should be truncated hourly. Comments were a mistake.
But the Posts table suffers from a serious design flaw in the public data dump: Questions and Answers are in the same table.
I’ve heard that it’s worse behind the scenes, but I don’t have any additional details on that.
Aspiring Aspirin
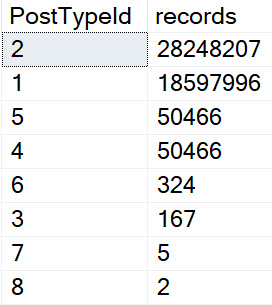
This ends up with some weird data distributions. Certain attributes can only ever be “true” for a question or an answer.
For example, only questions can have a non-zero AcceptedAnswerId, or AnswerCount. Some questions might have a ClosedDate, or a FavoriteCount, too. In the same way, only answers can have a ParentId. This ends up with some really weird patterns in the data.
breezy
Was it easier at first to design things this way? Probably. But introducing skew like this only makes dealing with parameter sniffing issues worse.
Even though questions and answers are the most common types of Posts, they’re not the only types of Posts. Even if you make people specify a type along with other things they’re searching for, you can end up with some really different query plans.
4:44
Designer Drugs
When you’re designing tables, try to keep this sort of stuff in mind. It might not be a big deal for small tables, but once you realize your data is getting big, it might be too late to make the change. It’s not just a matter of changes to the database, but the application, too.
Late stage redesigns often lead to the LET’S JUST REWRITE THE WHOLE APPLICATION FROM THE GROUND UP projects that take years and usually never make it.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Despite the many metric tons of blog posts warning people about this stuff, I still see many local variables and optimize for unknown hints. As a solution to parameter sniffing, it’s probably the best choice 1/1000th of the time. I still end up having to fix the other 999/1000 times, though.
In this post, I want to show you how using either optimize for unknown or local variables makes my job — and the job of anyone trying to fix this stuff — harder than it should be.
Passenger
Like most things, we’re going to start with an index:
Plain text
Copy to clipboard
Open code in new window
EnlighterJS 3 Syntax Highlighter
CREATEINDEX r ON dbo.Users(Reputation);
GO
CREATE INDEX r ON dbo.Users(Reputation);
GO
CREATE INDEX r ON dbo.Users(Reputation);
GO
I’m going to have a stored procedure that uses three different ways to pass a value to a where clause:
Plain text
Copy to clipboard
Open code in new window
EnlighterJS 3 Syntax Highlighter
CREATEORALTERPROCEDURE
dbo.u
(
@r int,
@u int
)
AS
BEGIN
/* Regular parameter */
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
WHERE u.Reputation = @r
AND u.UpVotes = @u;
/* Someone who saw someone else do it at their last job */
DECLARE
@LookMom int = @r,
@IDidItAgain int = @u;
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
WHERE u.Reputation = @LookMom
AND u.UpVotes = @IDidItAgain;
/* Someone who read the blog post URL wrong */
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
WHERE u.Reputation = @r
AND u.UpVotes = @u
OPTION(OPTIMIZEFORUNKNOWN);
END;
GO
CREATE OR ALTER PROCEDURE
dbo.u
(
@r int,
@u int
)
AS
BEGIN
/* Regular parameter */
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
WHERE u.Reputation = @r
AND u.UpVotes = @u;
/* Someone who saw someone else do it at their last job */
DECLARE
@LookMom int = @r,
@IDidItAgain int = @u;
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
WHERE u.Reputation = @LookMom
AND u.UpVotes = @IDidItAgain;
/* Someone who read the blog post URL wrong */
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
WHERE u.Reputation = @r
AND u.UpVotes = @u
OPTION(OPTIMIZE FOR UNKNOWN);
END;
GO
CREATE OR ALTER PROCEDURE
dbo.u
(
@r int,
@u int
)
AS
BEGIN
/* Regular parameter */
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
WHERE u.Reputation = @r
AND u.UpVotes = @u;
/* Someone who saw someone else do it at their last job */
DECLARE
@LookMom int = @r,
@IDidItAgain int = @u;
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
WHERE u.Reputation = @LookMom
AND u.UpVotes = @IDidItAgain;
/* Someone who read the blog post URL wrong */
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
WHERE u.Reputation = @r
AND u.UpVotes = @u
OPTION(OPTIMIZE FOR UNKNOWN);
END;
GO
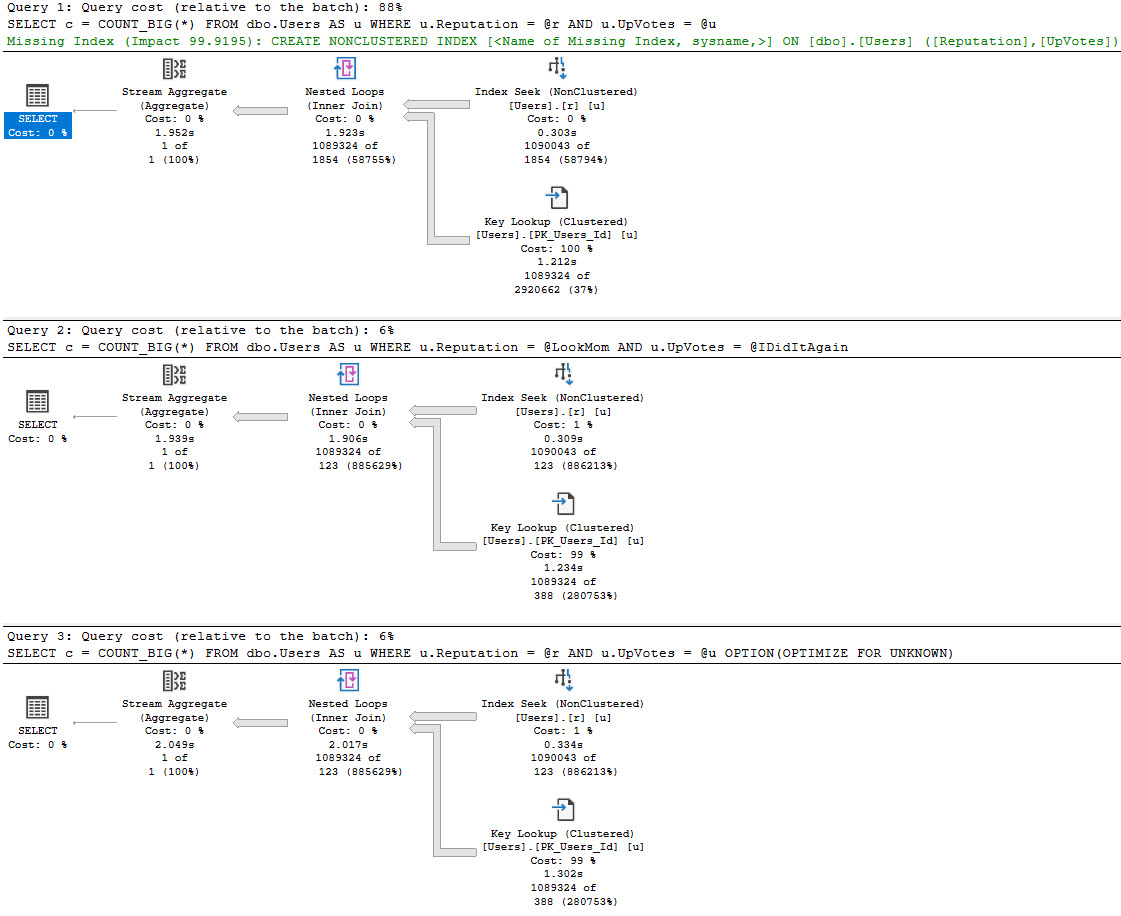
First Way
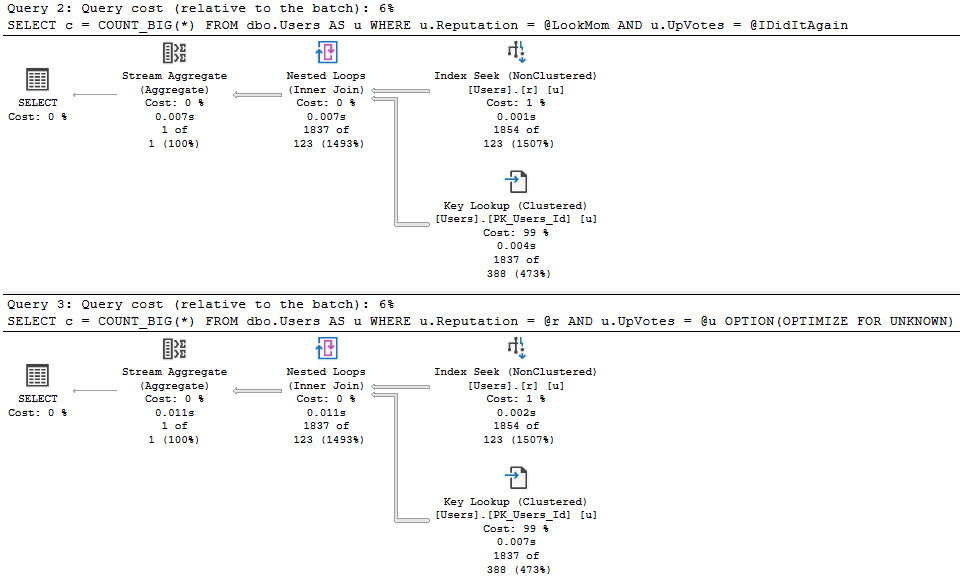
The best case is we run this for a small number of rows, and no one really notices. Even though we get bad guesses for the second two queries, it’s not a huge deal.
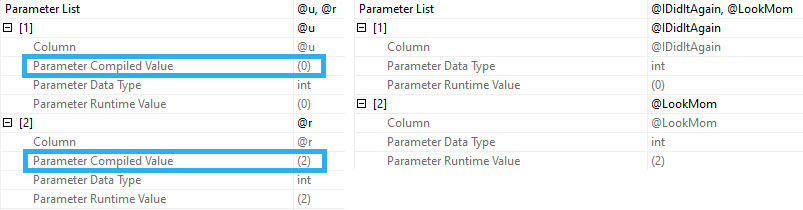
hands on
When you run procedures like this, SQL Server doesn’t cache the compile time values the same way it does when you use parameters. Granted, this is because it technically shouldn’t matter, but if you’re looking for a way to execute the procedure again to reproduce the issue, it’s up to you to go figure out what someone did.
? vs ?
Since I’m getting the actual plans here, I get the runtime values for both, but those don’t show up in the plan cache or query store version of plans.
That’s typically a huge blind spot when you’re trying to fix performance issues of any kind, but it’s up to you to capture that stuff.
Just, you know, good luck doing it in a way that doesn’t squash performance.
Second Way
In this example, our index is only on the Reputation column, but our where clause is also on the UpVotes column.
In nearly every situations, it’s better to have your query do all the filtering it can from one index source — there are obviously exceptions — but the point here is that the optimizer doesn’t bother with a missing index request for the second two queries, only for the first one.
That doesn’t matter a ton if you’re looking at the query and plan right in front of you, but if you’re also using the missing index DMVs to get some idea about how useful overall a new index might be, you’re out of luck.
mattered
In this case, the optimizer doesn’t think the second two plans are costly enough to warrant anything, but it does for the first plan.
I’m not saying that queries with local variables or optimize for unknown hints always do this, or that parameterized plans will always ask for (good) indexes. There are many issues with costing and SARGability that can prevent them from showing up, including getting a trivial plan.
This is just a good example of how Doing Goofy Things™ can backfire on you.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I talk to a lot of people about performance tuning. It seems like once someone is close enough to a database for long enough, they’ll have some impression of parameter sniffing. Usually a bad one.
You start to hear some funny stuff over and over again:
We should always recompile
We should always use local variables
We should always recompile and use local variables
Often, even if it means writing unsafe dynamic SQL, people will be afraid to parameterize things.
Between Friends
To some degree, I get it. You’re afraid of incurring some new performance problem.
You’ve had the same mediocre performance for years, and you don’t wanna make something worse.
The thing is, you could be making things a lot better most of the time.
Fewer compiles and recompiles, fewer single-use plans, fewer queries with multiple plans
Avoiding the local variable nonsense is, more often than not, going to get you better performance
A Letter To You
I’m going to tell you something that you’re not going to like, here.
Most of the time when I see a parameter sniffing problem, I see a lot of other problems.
Shabbily written queries, obvious missing indexes, and a whole list of other things.
It’s not that you have a parameter sniffing problem, you have a general negligence problem.
After all, the bad kind of parameter sniffing means that you’ve got variations of a query plan that don’t perform well on variations of parameters.
Once you start taking care of the basics, you’ll find a whole lot less of the problems that keep you up at night.
If that’s the kind of thing you need help with, drop me a line.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
While I was answering a question, I had to revisit what happens when using different flavors of recompile hints with stored procedure when they call inner stored procedures. I like when this happens, because there are so many little details I forget.
Anyway, the TL;DR is that if you have nested stored procedures, recompiling only recompiles the outer one. The inner procedures — really, I should say modules, because it includes other objects that compile query plans — but hey. Now you know what I should have said.
If you want to play around with the tests, you’ll need to grab sp_BlitzCache. I’m too lazy to write plan cache queries from scratch.
Testament
The procedures:
Plain text
Copy to clipboard
Open code in new window
EnlighterJS 3 Syntax Highlighter
CREATEORALTERPROCEDURE dbo.inner_sp
AS
BEGIN
SELECT
COUNT_BIG(*) AS records
FROM sys.master_files AS mf;
END;
GO
CREATEORALTERPROCEDURE dbo.outer_sp
--WITH RECOMPILE /*toggle this to see different behavior*/
AS
BEGIN
SELECT
COUNT_BIG(*) AS records
FROM sys.databases AS d;
EXEC dbo.inner_sp;
END;
GO
CREATE OR ALTER PROCEDURE dbo.inner_sp
AS
BEGIN
SELECT
COUNT_BIG(*) AS records
FROM sys.master_files AS mf;
END;
GO
CREATE OR ALTER PROCEDURE dbo.outer_sp
--WITH RECOMPILE /*toggle this to see different behavior*/
AS
BEGIN
SELECT
COUNT_BIG(*) AS records
FROM sys.databases AS d;
EXEC dbo.inner_sp;
END;
GO
CREATE OR ALTER PROCEDURE dbo.inner_sp
AS
BEGIN
SELECT
COUNT_BIG(*) AS records
FROM sys.master_files AS mf;
END;
GO
CREATE OR ALTER PROCEDURE dbo.outer_sp
--WITH RECOMPILE /*toggle this to see different behavior*/
AS
BEGIN
SELECT
COUNT_BIG(*) AS records
FROM sys.databases AS d;
EXEC dbo.inner_sp;
END;
GO
The tests:
Plain text
Copy to clipboard
Open code in new window
EnlighterJS 3 Syntax Highlighter
--It's helpful to run this before each test to clear out clutter
DBCCFREEPROCCACHE;
--Look at this with and without
--WITH RECOMPILE in the procedure definition
EXEC dbo.outer_sp;
--Take out the proc-level recompile and run this
EXEC dbo.outer_sp WITHRECOMPILE;
--Take out the proc-level recompile and run this
EXEC sp_recompile 'dbo.outer_sp';
EXEC dbo.outer_sp;
--You should run these between each test to verify behavior
--If you just run them here at the end, you'll be disappointed
EXEC sp_BlitzCache
@DatabaseName = 'Crap',
@QueryFilter = 'procedure',
@SkipAnalysis = 1,
@HideSummary = 1;
EXEC sp_BlitzCache
@DatabaseName = 'Crap',
@QueryFilter = 'statement',
@SkipAnalysis = 1,
@HideSummary = 1;
--It's helpful to run this before each test to clear out clutter
DBCC FREEPROCCACHE;
--Look at this with and without
--WITH RECOMPILE in the procedure definition
EXEC dbo.outer_sp;
--Take out the proc-level recompile and run this
EXEC dbo.outer_sp WITH RECOMPILE;
--Take out the proc-level recompile and run this
EXEC sp_recompile 'dbo.outer_sp';
EXEC dbo.outer_sp;
--You should run these between each test to verify behavior
--If you just run them here at the end, you'll be disappointed
EXEC sp_BlitzCache
@DatabaseName = 'Crap',
@QueryFilter = 'procedure',
@SkipAnalysis = 1,
@HideSummary = 1;
EXEC sp_BlitzCache
@DatabaseName = 'Crap',
@QueryFilter = 'statement',
@SkipAnalysis = 1,
@HideSummary = 1;
--It's helpful to run this before each test to clear out clutter
DBCC FREEPROCCACHE;
--Look at this with and without
--WITH RECOMPILE in the procedure definition
EXEC dbo.outer_sp;
--Take out the proc-level recompile and run this
EXEC dbo.outer_sp WITH RECOMPILE;
--Take out the proc-level recompile and run this
EXEC sp_recompile 'dbo.outer_sp';
EXEC dbo.outer_sp;
--You should run these between each test to verify behavior
--If you just run them here at the end, you'll be disappointed
EXEC sp_BlitzCache
@DatabaseName = 'Crap',
@QueryFilter = 'procedure',
@SkipAnalysis = 1,
@HideSummary = 1;
EXEC sp_BlitzCache
@DatabaseName = 'Crap',
@QueryFilter = 'statement',
@SkipAnalysis = 1,
@HideSummary = 1;
Whatchalookinat?
After each of these where a recompile is applied, you should see the inner proc/statement in the BlitzCache results, but not the outer procedure.
It’s important to understand behavior like this, because recompile hints are most often used to help investigate parameter sniffing issues. If it’s taking place in nested stored procedure calls, you may find yourself with a bunch of extra work to do or needing to re-focus your use of recompile hints.
Of course, this is why I much prefer option recompile hints on problem statements. You get much more reliable behavior.
For instances running at least SQL Server 2008 build 2746 (Service Pack 1 with Cumulative Update 5), using OPTION (RECOMPILE) has another significant advantage over WITH RECOMPILE: Only OPTION (RECOMPILE) enables the Parameter Embedding Optimization.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
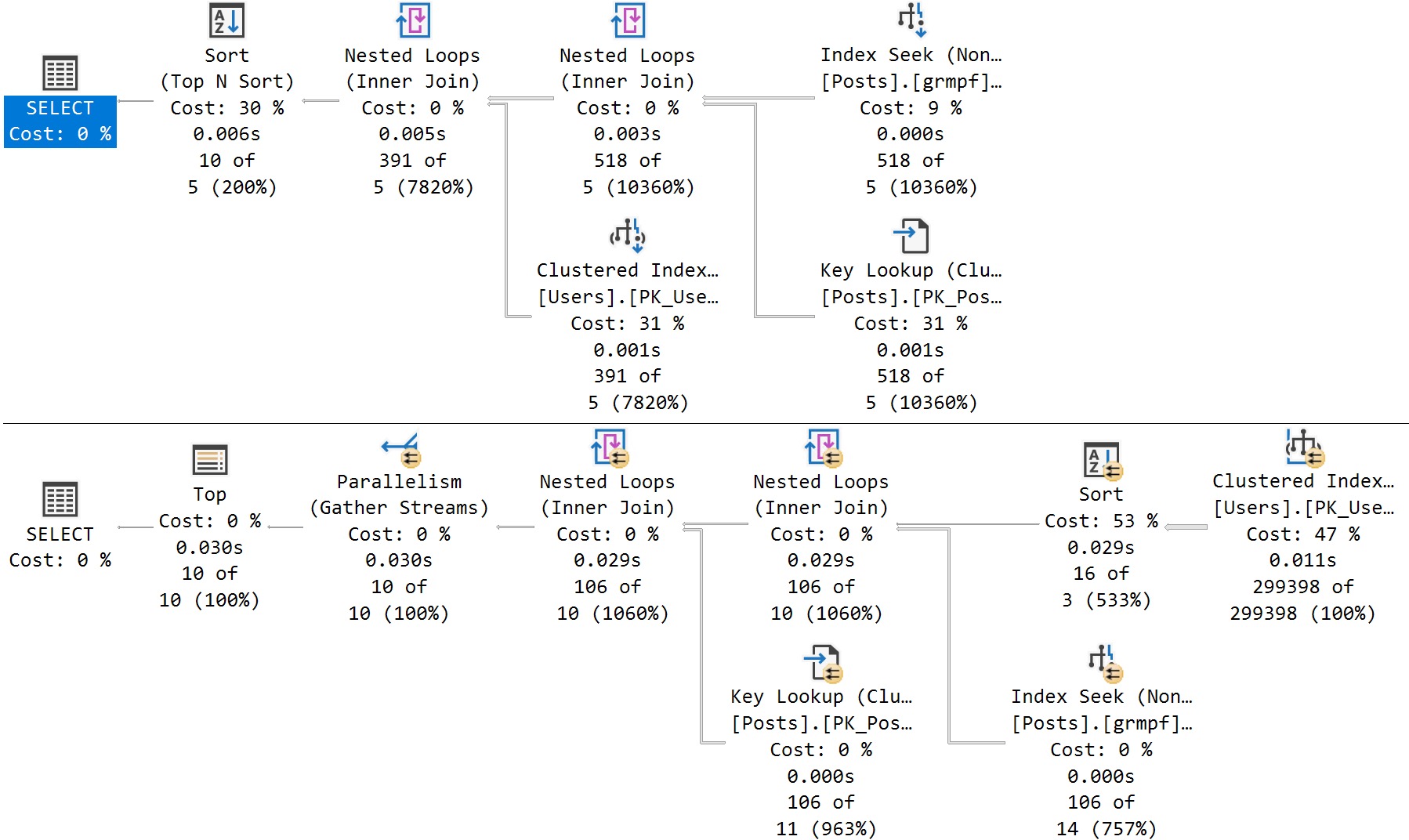
One problem with Lookups, aside from the usual complaints, is that the optimizer has no options for when the lookup happens.
If the optimizer decides to use a nonclustered index to satisfy some part of the query, but the nonclustered index doesn’t have all of the columns needed to cover what the query is asking for, it has to do a lookup.
Whether the lookup is Key or RID depends on if the table has a clustered index, but that’s not entirely the point.
The point is that there’s no way for the optimizer to decide to defer the lookup until later in the plan, when it might be more opportune.
Gastric Acid
Let’s take one index, and two queries.
Plain text
Copy to clipboard
Open code in new window
EnlighterJS 3 Syntax Highlighter
CREATEINDEX p
ON dbo.Posts(PostTypeId, Score, CreationDate)
INCLUDE(OwnerUserId);
CREATE INDEX p
ON dbo.Posts(PostTypeId, Score, CreationDate)
INCLUDE(OwnerUserId);
CREATE INDEX p
ON dbo.Posts(PostTypeId, Score, CreationDate)
INCLUDE(OwnerUserId);
Stop being gross.
Plain text
Copy to clipboard
Open code in new window
EnlighterJS 3 Syntax Highlighter
SELECTTOP (1000)
u.DisplayName,
p.*
FROM dbo.Posts AS p
JOIN dbo.Users AS u
ON p.OwnerUserId = u.Id
WHERE p.PostTypeId = 1
AND p.Score > 5
ORDER BY p.CreationDate DESC;
SELECTTOP (1000)
u.DisplayName,
p.*
FROM dbo.Posts AS p
JOIN dbo.Users AS u
ON p.OwnerUserId = u.Id
WHERE p.PostTypeId = 1
AND p.Score > 6
ORDER BY p.CreationDate DESC;
SELECT TOP (1000)
u.DisplayName,
p.*
FROM dbo.Posts AS p
JOIN dbo.Users AS u
ON p.OwnerUserId = u.Id
WHERE p.PostTypeId = 1
AND p.Score > 5
ORDER BY p.CreationDate DESC;
SELECT TOP (1000)
u.DisplayName,
p.*
FROM dbo.Posts AS p
JOIN dbo.Users AS u
ON p.OwnerUserId = u.Id
WHERE p.PostTypeId = 1
AND p.Score > 6
ORDER BY p.CreationDate DESC;
SELECT TOP (1000)
u.DisplayName,
p.*
FROM dbo.Posts AS p
JOIN dbo.Users AS u
ON p.OwnerUserId = u.Id
WHERE p.PostTypeId = 1
AND p.Score > 5
ORDER BY p.CreationDate DESC;
SELECT TOP (1000)
u.DisplayName,
p.*
FROM dbo.Posts AS p
JOIN dbo.Users AS u
ON p.OwnerUserId = u.Id
WHERE p.PostTypeId = 1
AND p.Score > 6
ORDER BY p.CreationDate DESC;
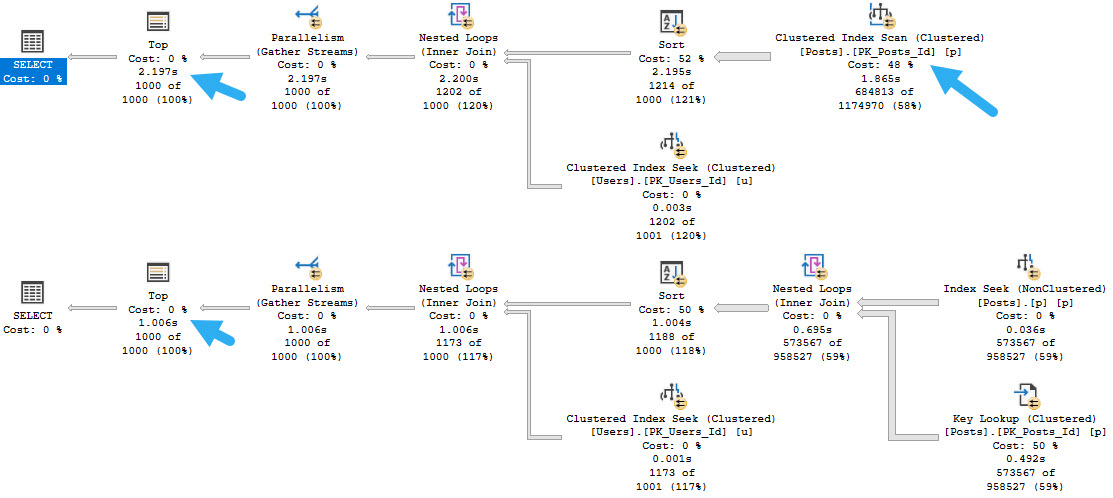
The main point here is not that the lookup is bad; it’s actually good, and I wish both queries would use one.
odd choice
If we hint the first query to use the nonclustered index, things turn out better.
Plain text
Copy to clipboard
Open code in new window
EnlighterJS 3 Syntax Highlighter
SELECTTOP (1000)
u.DisplayName,
p.*
FROM dbo.Posts AS p WITH(INDEX = p)
JOIN dbo.Users AS u
ON p.OwnerUserId = u.Id
WHERE p.PostTypeId = 1
AND p.Score > 5
ORDER BY p.CreationDate DESC;
SELECT TOP (1000)
u.DisplayName,
p.*
FROM dbo.Posts AS p WITH(INDEX = p)
JOIN dbo.Users AS u
ON p.OwnerUserId = u.Id
WHERE p.PostTypeId = 1
AND p.Score > 5
ORDER BY p.CreationDate DESC;
SELECT TOP (1000)
u.DisplayName,
p.*
FROM dbo.Posts AS p WITH(INDEX = p)
JOIN dbo.Users AS u
ON p.OwnerUserId = u.Id
WHERE p.PostTypeId = 1
AND p.Score > 5
ORDER BY p.CreationDate DESC;
woah woah woah you can’t use hints here this is a database
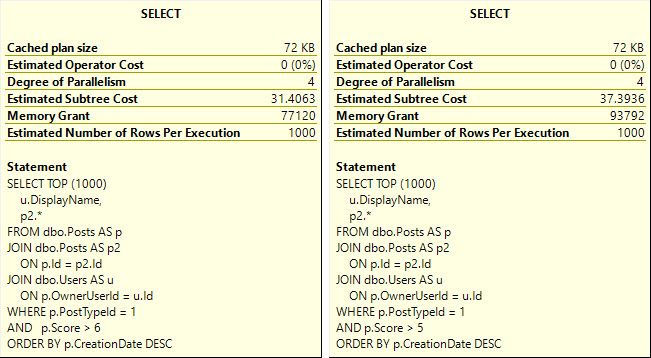
Running a full second faster seems like a good thing to me, but there’s a problem.
Ingest
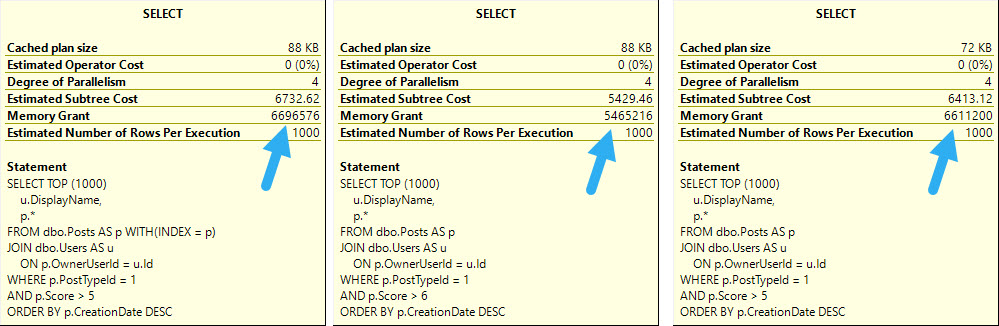
Whether we use the lookup or scan the clustered index, all of these queries ask for rather large memory grants, between 5.5 and 6.5 GB
bigsort4u
The operator asking for memory is the Sort — and while I’d love it if we could index for every sort — it’s just not practical.
So like obviously changing optimizer behavior is way more practical. Ahem.
The reason that the Sort asks for so much memory in each of these cases is that it’s forced to order the entire select output from the Posts table by the CreationDate column.
donk
Detach
If we rewrite the query a bit, we can get the optimizer to sort data long before we go get all the output columns:
Plain text
Copy to clipboard
Open code in new window
EnlighterJS 3 Syntax Highlighter
SELECTTOP (1000)
u.DisplayName,
p2.*
FROM dbo.Posts AS p
JOIN dbo.Posts AS p2
ON p.Id = p2.Id
JOIN dbo.Users AS u
ON p.OwnerUserId = u.Id
WHERE p.PostTypeId = 1
AND p.Score > 5
ORDER BY p.CreationDate DESC;
SELECTTOP (1000)
u.DisplayName,
p2.*
FROM dbo.Posts AS p
JOIN dbo.Posts AS p2
ON p.Id = p2.Id
JOIN dbo.Users AS u
ON p.OwnerUserId = u.Id
WHERE p.PostTypeId = 1
AND p.Score > 6
ORDER BY p.CreationDate DESC;
SELECT TOP (1000)
u.DisplayName,
p2.*
FROM dbo.Posts AS p
JOIN dbo.Posts AS p2
ON p.Id = p2.Id
JOIN dbo.Users AS u
ON p.OwnerUserId = u.Id
WHERE p.PostTypeId = 1
AND p.Score > 5
ORDER BY p.CreationDate DESC;
SELECT TOP (1000)
u.DisplayName,
p2.*
FROM dbo.Posts AS p
JOIN dbo.Posts AS p2
ON p.Id = p2.Id
JOIN dbo.Users AS u
ON p.OwnerUserId = u.Id
WHERE p.PostTypeId = 1
AND p.Score > 6
ORDER BY p.CreationDate DESC;
SELECT TOP (1000)
u.DisplayName,
p2.*
FROM dbo.Posts AS p
JOIN dbo.Posts AS p2
ON p.Id = p2.Id
JOIN dbo.Users AS u
ON p.OwnerUserId = u.Id
WHERE p.PostTypeId = 1
AND p.Score > 5
ORDER BY p.CreationDate DESC;
SELECT TOP (1000)
u.DisplayName,
p2.*
FROM dbo.Posts AS p
JOIN dbo.Posts AS p2
ON p.Id = p2.Id
JOIN dbo.Users AS u
ON p.OwnerUserId = u.Id
WHERE p.PostTypeId = 1
AND p.Score > 6
ORDER BY p.CreationDate DESC;
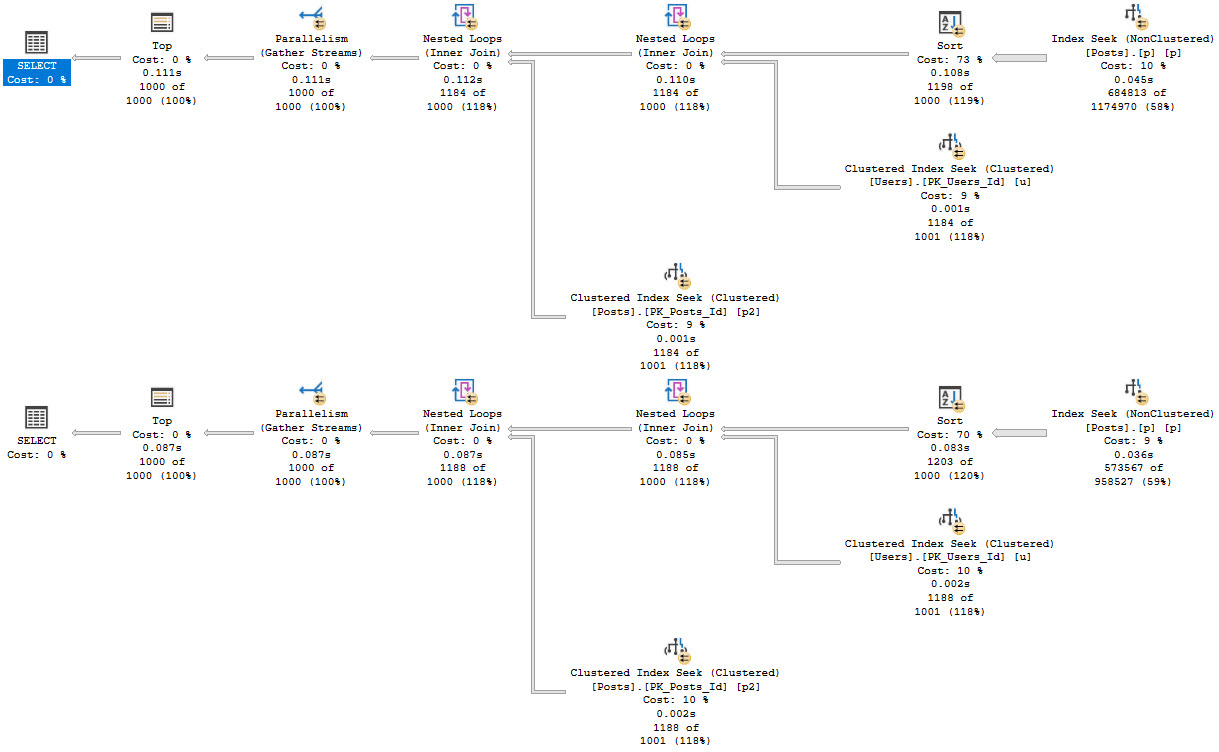
In both cases, we get the same query plan shape, which is what we’re after:
Seek into the nonclustered index on Posts
Sort data by CreationDate
Join Posts to Users first
Join back to Posts for the select list columns
weeeeeeeeee
Because the Sort happens far earlier on in the plan, there’s less of a memory grant needed, and by quite a stretch from the 5+ GB before.
turn down
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Anyway, I got back to thinking about it recently because a couple things had jogged in my foggy brain around table valued functions and parameter sniffing.
Go figure.
Reading Rainbow
One technique you could use to avoid this would be to use an inline table valued function, like so:
Plain text
Copy to clipboard
Open code in new window
EnlighterJS 3 Syntax Highlighter
CREATEORALTERFUNCTION dbo.TopParam(@Top bigint)
RETURNSTABLE
WITHSCHEMABINDING
AS
RETURN
SELECTTOP (@Top)
u.DisplayName,
b.Name
FROM dbo.Users AS u
CROSSAPPLY
(
SELECTTOP (1)
b.Name
FROM dbo.Badges AS b
WHERE b.UserId = u.Id
ORDER BY b.Date DESC
) AS b
WHERE u.Reputation > 10000
ORDER BY u.Reputation DESC;
GO
CREATE OR ALTER FUNCTION dbo.TopParam(@Top bigint)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
SELECT TOP (@Top)
u.DisplayName,
b.Name
FROM dbo.Users AS u
CROSS APPLY
(
SELECT TOP (1)
b.Name
FROM dbo.Badges AS b
WHERE b.UserId = u.Id
ORDER BY b.Date DESC
) AS b
WHERE u.Reputation > 10000
ORDER BY u.Reputation DESC;
GO
CREATE OR ALTER FUNCTION dbo.TopParam(@Top bigint)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
SELECT TOP (@Top)
u.DisplayName,
b.Name
FROM dbo.Users AS u
CROSS APPLY
(
SELECT TOP (1)
b.Name
FROM dbo.Badges AS b
WHERE b.UserId = u.Id
ORDER BY b.Date DESC
) AS b
WHERE u.Reputation > 10000
ORDER BY u.Reputation DESC;
GO
When we select from the function, the top parameter is interpreted as a literal.
Plain text
Copy to clipboard
Open code in new window
EnlighterJS 3 Syntax Highlighter
SELECT
tp.*
FROM dbo.TopParam(1) AS tp;
SELECT
tp.*
FROM dbo.TopParam(38) AS tp;
SELECT
tp.*
FROM dbo.TopParam(1) AS tp;
SELECT
tp.*
FROM dbo.TopParam(38) AS tp;
SELECT
tp.*
FROM dbo.TopParam(1) AS tp;
SELECT
tp.*
FROM dbo.TopParam(38) AS tp;
genius!
Performance is “fine” for both in that neither one takes over a minute to run. Good good.
Departures
This is, of course, not what happens in a stored procedure or parameterized dynamic SQL.
Plain text
Copy to clipboard
Open code in new window
EnlighterJS 3 Syntax Highlighter
EXEC dbo.ParameterTop @Top = 1;
EXEC dbo.ParameterTop @Top = 1;
EXEC dbo.ParameterTop @Top = 1;
doodad
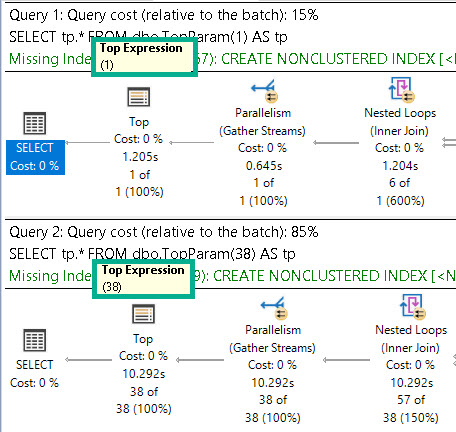
Keen observers will note that this query runs for 1.2 seconds, just like the plan for the function above.
That is, of course, because this is the stored procedure’s first execution. The @Top parameter has been sniffed, and things have been optimized for the sniffed value.
If we turn around and execute it for 38 rows right after, we’ll get the “fine” performance noted above.
Plain text
Copy to clipboard
Open code in new window
EnlighterJS 3 Syntax Highlighter
EXEC dbo.ParameterTop @Top = 38;
EXEC dbo.ParameterTop @Top = 38;
EXEC dbo.ParameterTop @Top = 38;
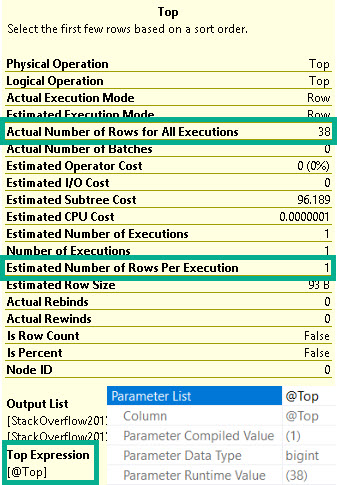
Looking at the plan in a slightly different way, here’s what the Top operator is telling us, along with what the compile and runtime values in the plan are:
snort
It may make sense to make an effort to cache a plan with @Top = 1 initially to get the “fine” performance. That estimate is good enough to get us back to sending the buffers quickly.
Buggers
Unfortunately, putting the inline table valued function inside the stored procedure doesn’t offer us any benefit.
Without belaboring the point too much:
Plain text
Copy to clipboard
Open code in new window
EnlighterJS 3 Syntax Highlighter
CREATEPROCEDURE dbo.ParameterTopItvf(@Top BIGINT)
AS
BEGIN
SETNOCOUNT, XACT_ABORT ON;
SELECT
tp.*
FROM dbo.TopParam(@Top) AS tp;
END;
GO
EXEC dbo.ParameterTopItvf @Top = 1;
EXEC dbo.ParameterTopItvf @Top = 38;
EXEC sp_recompile 'dbo.ParameterTopItvf';
EXEC dbo.ParameterTopItvf @Top = 38;
EXEC dbo.ParameterTopItvf @Top = 1;
CREATE PROCEDURE dbo.ParameterTopItvf(@Top BIGINT)
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
SELECT
tp.*
FROM dbo.TopParam(@Top) AS tp;
END;
GO
EXEC dbo.ParameterTopItvf @Top = 1;
EXEC dbo.ParameterTopItvf @Top = 38;
EXEC sp_recompile 'dbo.ParameterTopItvf';
EXEC dbo.ParameterTopItvf @Top = 38;
EXEC dbo.ParameterTopItvf @Top = 1;
CREATE PROCEDURE dbo.ParameterTopItvf(@Top BIGINT)
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
SELECT
tp.*
FROM dbo.TopParam(@Top) AS tp;
END;
GO
EXEC dbo.ParameterTopItvf @Top = 1;
EXEC dbo.ParameterTopItvf @Top = 38;
EXEC sp_recompile 'dbo.ParameterTopItvf';
EXEC dbo.ParameterTopItvf @Top = 38;
EXEC dbo.ParameterTopItvf @Top = 1;
If we do this, running for 1 first gives us “fine” performance, but running for 38 first gives us the much worse performance.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.