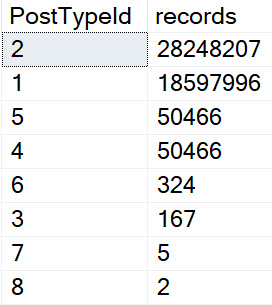
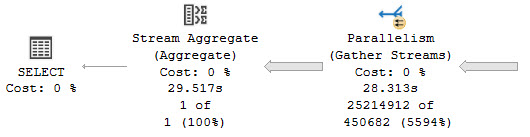In the Stack Overflow database, the biggest (and probably most important) table is Posts.
The Comments table should be truncated hourly. Comments were a mistake.
But the Posts table suffers from a serious design flaw in the public data dump: Questions and Answers are in the same table.
I’ve heard that it’s worse behind the scenes, but I don’t have any additional details on that.
Aspiring Aspirin
This ends up with some weird data distributions. Certain attributes can only ever be “true” for a question or an answer.
For example, only questions can have a non-zero AcceptedAnswerId, or AnswerCount. Some questions might have a ClosedDate, or a FavoriteCount, too. In the same way, only answers can have a ParentId. This ends up with some really weird patterns in the data.
breezy
Was it easier at first to design things this way? Probably. But introducing skew like this only makes dealing with parameter sniffing issues worse.
Even though questions and answers are the most common types of Posts, they’re not the only types of Posts. Even if you make people specify a type along with other things they’re searching for, you can end up with some really different query plans.
4:44
Designer Drugs
When you’re designing tables, try to keep this sort of stuff in mind. It might not be a big deal for small tables, but once you realize your data is getting big, it might be too late to make the change. It’s not just a matter of changes to the database, but the application, too.
Late stage redesigns often lead to the LET’S JUST REWRITE THE WHOLE APPLICATION FROM THE GROUND UP projects that take years and usually never make it.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Right off the bat, I want you to know that this is not a solution, and I’ll get to why in a minute. I’m writing this mainly because every once in a while I’ll try something different to get this working, and it always ends up disappointing.
I wish I had better news for you, here. Hell, I wish I had better news for me here. But alas we’re at the mercy of parameters.
And yeah, I know, recompile, recompile, recompile. All the live long day. But I’ve seen some weird stuff happen with that too under high concurrency.
So what’s the point? Let’s talk about that.
Dot Dot Dot
CREATE INDEX p1 ON dbo.Posts(OwnerUserId, CreationDate);
CREATE INDEX p2 ON dbo.Posts(Score, LastActivityDate);
We need some indexes. That’s a fact. I’m intentionally creating them in this way to show you that SQL Server can sometimes be smart about catch all queries.
And here’s the inline table valued function we’ll be working with:
CREATE OR ALTER FUNCTION
dbo.kitchen_sink
(
@OwnerUserId int,
@CreationDate datetime,
@Score int,
@LastActivityDate datetime
)
RETURNS table
AS
RETURN
SELECT
c = COUNT_BIG(*)
FROM dbo.Posts AS p
WHERE
(p.OwnerUserId = @OwnerUserId OR @OwnerUserId IS NULL)
AND (p.CreationDate >= @CreationDate OR @CreationDate IS NULL)
AND (p.Score >= @Score OR @Score IS NULL)
AND (p.LastActivityDate >= @LastActivityDate OR @LastActivityDate IS NULL);
This pattern usually eats the optimizer alive, and there’s a lot of posts about using dynamic SQL to fix it.
But when we call this function with literal values, it does just fine.
SELECT
ks.c
FROM dbo.kitchen_sink(22656, '20130101', NULL, NULL) AS ks;
SELECT
ks.c
FROM dbo.kitchen_sink(NULL, NULL, 100, '20130101') AS ks;
SELECT
ks.c
FROM dbo.kitchen_sink(22656, NULL, NULL, '20130101') AS ks;
SELECT
ks.c
FROM dbo.kitchen_sink(NULL, '20131225', NULL, '20131225') AS ks;
SELECT
ks.c
FROM dbo.kitchen_sink(22656, NULL, NULL, '20131215') AS ks;
Das Plan
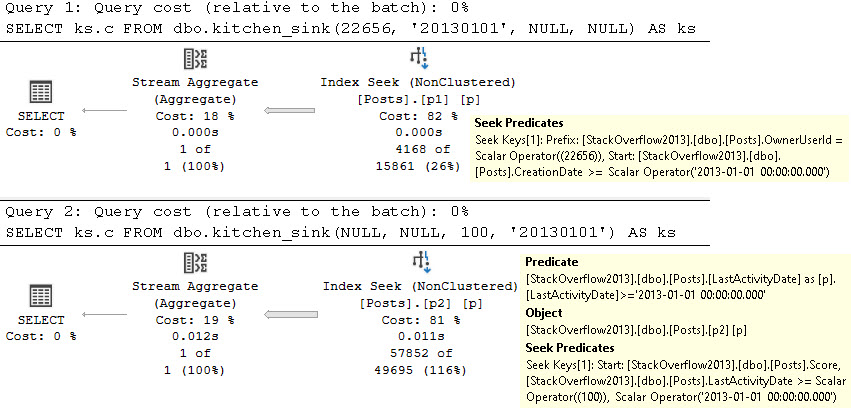
You can run those all yourself and look at the plans. I’m just gonna throw a couple of the more interesting examples in the post, though.
The first two queries do exactly what we’d hope to see.
sparkling
We use the right indexes, we get seeks. Cardinality estimation is about as reliable as ever with the “””””default””””” estimator in place 🙄
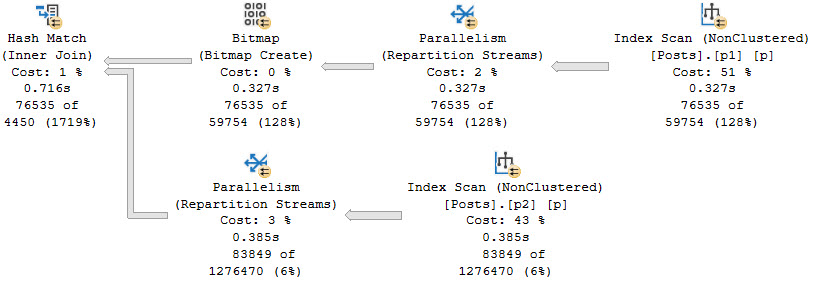
And at one point, we even get a really smart index intersection plan where the optimizer uses both of our nonclustered indexes.
units
Parameter Problem
The problem is that no one really makes database calls like that.
If you’re using an ORM, you could intentionally not parameterize your queries and get this to “work”, but there are downsides to that around the plan cache. Being honest, most plan caches are useless anyway.
Long Live Query Store, or something.
Most people have their catch all code parameterized, so the query looks like what’s in the function. I’m going to throw the function in a stored procedure now.
CREATE OR ALTER PROCEDURE
dbo.kitchen_wrapper
(
@OwnerUserId int,
@CreationDate datetime,
@Score int,
@LastActivityDate datetime
)
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
SELECT
ks.c
FROM dbo.kitchen_sink
(
@OwnerUserId,
@CreationDate,
@Score,
@LastActivityDate
) AS ks;
END;
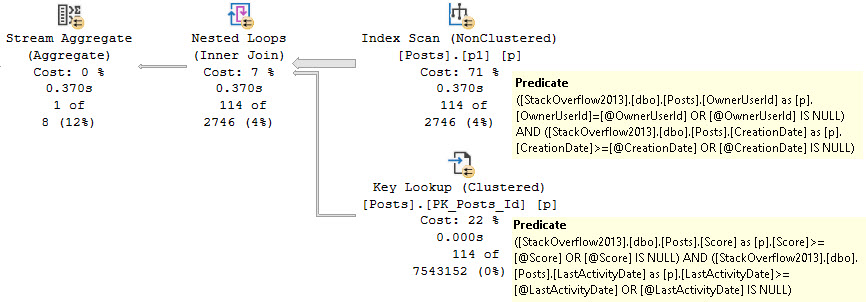
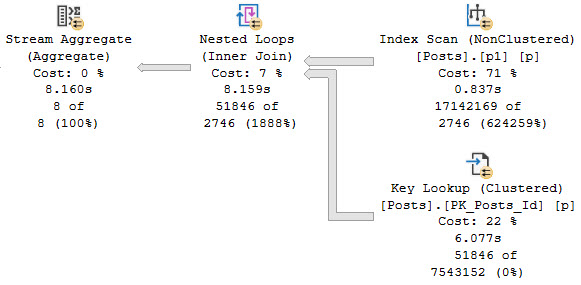
If we execute the procedure like this, everything goes to hell rather quickly.
The first execution uses the “right” index, but we lose our nice index seek into the p1 index.
barfbag
We also end up with Predicates on the Key Lookup, just in case they end up not being NULL. And boy, when they end up not being NULL, we end up with a really slow query.
me one too
We re-use the execution plan we saw before, because that’s how SQL Server works. But since we don’t filter any rows from p1 since those parameters are NULL now, we pass all 17 million rows to the key lookup to filter them there, but since it’s a Nested Loops Join, we do it… one row at a time.
Fun.
Floss Too Much
There’s no great fix for this, either. This is a problem we’re stuck with when we write queries this way without using dynamic SQL, or a recompile hint.
I’ve seen people try all sorts of things to “fix” this problem. Case expressions, ISNULL and COALESCE, magic values, and more. They all have this exact same issue.
And I know, recompile, recompile, recompile.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
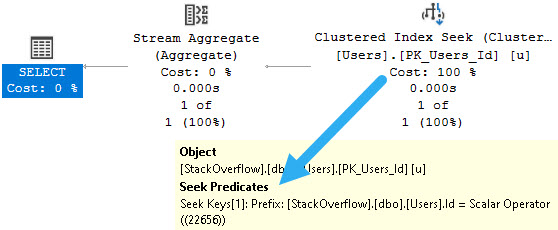
I had a RABID FAN ask me an interesting question about a query. I can’t use theirs, but I can repro the question.
The question was: if using ISNULL in a where clause isn’t SARGable, how come I can use a FORCESEEK hint in this query?
Formatting and linking my own, of course.
The query looked something like this:
SELECT
c =
COUNT_BIG(*)
FROM dbo.Users AS u WITH(FORCESEEK)
WHERE ISNULL(u.Id, 0) = 22656;
GO
seekable!
What Gives?
The first thing you should notice is that the optimizer throws out ISNULL, here.
Why? Because the Id column isn’t NULL-able, and since ISNULL is Microsoft’s special non-ANSI baby, it can do this one special thing.
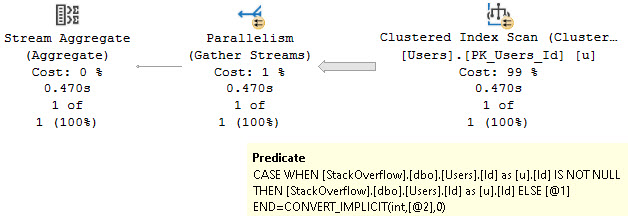
If we use COALESCE instead, we’ll get an error.
SELECT
c =
COUNT_BIG(*)
FROM dbo.Users AS u WITH(FORCESEEK)
WHERE COALESCE(u.Id, 0) = 22656;
GO
Msg 8622, Level 16, State 1, Line 8
Query processor could not produce a query plan because of the hints defined in this query. Resubmit the query without specifying any hints and without using SET FORCEPLAN.
And if we try to use ISNULL on a NULL-able column like Age, we’ll get the same error:
SELECT
c =
COUNT_BIG(*)
FROM dbo.Users AS u WITH(FORCESEEK)
WHERE ISNULL(u.Age, 0) = 22656;
GO
Coacase? Caselesce?
Under the covers, COALESCE is just a crappy band CASE expression.
Without the FORCESEEK hint, we can get the query to actually run.
SELECT
c =
COUNT_BIG(*)
FROM dbo.Users AS u
WHERE COALESCE(u.Id, 0) = 22656;
GO
southa
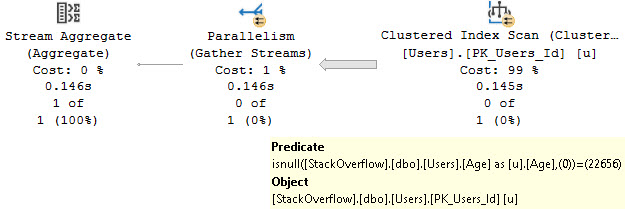
And ISNULL is just… ISNULL.
SELECT
c =
COUNT_BIG(*)
FROM dbo.Users AS u
WHERE ISNULL(u.Age, 0) = 22656;
GO
ribs
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
As a counterpart to yesterday’s post, I have a list of Great Ideas™ that sometimes it’s hard to get people on board with, for some reason.
Don’t get me wrong, some people can’t jump on this stuff fast enough — I’ve had people take “unscheduled maintenance” during engagements to flip the right switches — but other times there’s a hem and a haw and a whole lot of’em to go along with the plan.
Somehow people who have auto close and Priority Boost turned on and haven’t checked for corruption since 30 Rock went off the air want a full-bore fisking of every change and every assurance that no edge case exists that could ever cross their path.
Okay pal. You go on with your bad 2012 RTM self.
Lock Pages In Memory
“Please don’t pop my balloon animals.”
To say that this setting only lets SQL Server hang onto memory is a grand injustice. It also lets SQL Server use completely different APIs to access memory through Windows, including skipping over virtual memory space. That can be an awesome benefit for servers with gobs of memory.
What are people worried about, here? Usually some article they read about balloon drivers in 2011, or something.
But the same people aren’t afraid to set min server memory to max server memory, and then wonder why they have no plan cache.
I love this setting though, and if you can also get away with turning on trace flag 834, there are some nice additional benefits.
DBCC CHECKDB
“Well, our index maintenance job runs for 9 hours, so we don’t have time for this. Besides, won’t it cause a lot of blocking?”
Lord have mercy, the foot dragging on this. Part of your job as a DBA is to keep data safe and backed up. Running CHECKDB is part of that.
No DBA got fired over fragmented indexes. More than a few have for data going corrupt.
Granted, this can get a little more complicated for really big databases. Some people break it up into different steps, and other people offload the process.
Some third party backup tools from vendors like Quest and Red Gate allow you to automate processes like that, too. Full backup, restore to new server, run CHECKDB, tell us what happened.
How nice, you get a tested restore, too.
Query Store
“Won’t this catch my server on fire and leak PII to hackers?”
If you’re too cheap to spring for a proper monitoring tool, Query Store makes a pretty okay pseudo replacement. Especially in 2017 and up where you can track wait stats too, you can get some pretty good insights out of it.
Microsoft has also gotten pretty smart about better default settings for this thing, and in 2019 you have more knobs to set smarter standards for which plans get tracked in there.
It’d be really nice if you could choose to ignore queries, too, but you know. Can’t always get what you want, there.
I’d much rather look at Query Store than that unreliable old plan cache, too.
Read Committed Snapshot Isolation
“Why do I want tempdb to be full of old data?”
Remember yesterday? Me either. Nothing good happened, anyway. Do you remember what that row looked like before the update started? No?
Read Committed Snapshot Isolation does. And it wants you to, too. This setting solves so many dumb problems that people run headlong into because Microsoft committed to a garbage isolation level.
One complaint I hear all the time is that a particular application runs a lot better on Oracle with no other changes. This setting is usually the reason why: It’s not turned on.
Once you turn it on, reader/writer blocking and deadlocking goes away, and you don’t need to add a SSMS keyboard shortcut that inserts WITH NOLOCK.
Changing Indexes
“They’re fine the way they are, trust me. That burning smell is another server.”
Index tuning needs to be a process that starts with cleaning up indexes, and ends with adding in better ones.
What makes an index bad? When it’s unused, and/or duplicative.
What makes an index good? When it gets read from more than it’s written to, and it’s a usefully different way for queries to access data.
There are other index anti-patterns that are good to look for too, like lots of single key column indexes, but they usually get cleaned up when you start merging duplicates.
There’s a near fully eclipsed Venn Diagram of people who are worried about having too many indexes and people who have never dropped an index in their career.
Talk, Talk
These are the kinds of changes and processes people should be comfortable with making when they work with SQL Server.
Sure, there are a ton of others, but some of them have become part of the installer and get a little more leeway — parallelism settings, instant file initialization, tempdb etc. — I only wish that more of this stuff would follow suit.
One wonders quite loudly why setting MAXDOP made it into the installer, but setting Cost Threshold For Parallelism did not.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Consulting gives you a lot of opportunities to talk to a lot of people and deal with interesting issues.
Recently it occurred to me that a lot of people seem to confer magic button status to a lot of things that always seem to be If-I-Could-Only-Do-This features that would solve all their problems, and similarly a Thing-That-Solved-One-Problem-Once turned into something that got used everywhere.
Go figure, right?
Let’s talk about some of them, so maybe I won’t have to talk this over with you someday, dear reader.
Partitioning
How this ended up being everyone’s top unexplored performance feature is beyond me. I always seem to hear that someone really wants to partition dbo.tblSomeBigTable because queries would be faster if they could eliminate partitions.
Maybe if you’re using clustered column store indexes it would, but for the rest of us, you’re no better off with a partitioned table than you are with a table that has decent indexing. In a lot of cases, partitioning can make things worse, or just more confusing.
Few people seem to consider the amount of work that goes into partitioning a really big table, either. It doesn’t matter if you want to do it in place, or use a batch process to copy data over.
Even fewer people talk about Partitioning for what it’s good for, which is managing partitions. Just make sure all those indexes are aligned.
Fill Factor
At this point, I’d expect everyone to understand why Flash and SSD storage is better than old spinning disks. Lack of moving parts, less pushing random I/O patterns, etc.
And yet, without a single page split being measured or compared, fill factor gets dropped down to 80 (or lower) just in case.
I call this Spinning Disk Mentality, and it hurts to see it out in the wild, especially when:
You’re on Standard Edition
You already have way more data than memory
You’re intentionally making data less compact
Your entire workload is stalled out on PAGEIOLATCH_XX waits
I truly appreciate the problem that lowering fill factor used to solve, but let’s join the CURRENT_CENTURY on this one.
Unless you have a good reason to add physical fragmentation to your indexes, how about we skip that?
In-Memory OLTP (Hekaton)
This is a hugely misunderstood feature. Everyone thinks it’s gonna make queries faster because tables will be in memory without reading the fine print.
If you have problems with throughput on very hot data, this might be a good solution for you.
If you’ve got a bunch of run-0f-the-mill queries that get blocked sometimes and performance generally stinks on, this isn’t really what you need to focus on.
I think the most common useful pattern I’ve seen for this feature is for “shock absorber” tables, where things like event betting, ticket sales, and online ordering all need to happen very quickly for a very small amount of data, and after the initial rush can be shuffled to regular disk-based tables.
If your table is already cached in memory when queries are hitting it, using this feature isn’t gonna make it any more in memory.
You’ve got other problems to solve.
Dirty Reads
Getting blocked sucks. It doesn’t matter if it’s in a database, at a bar, in traffic, or an artery. Everyone wants their reads instantly and they don’t wanna hear a darn word about it.
I’m not here to trample all over NOLOCK — I’ve defended people using it in the past — but I am here to ask you nicely to please reconsider dousing all your queries with it.
In many cases, READPASTis a better option, so your query can skip over locked rows rather than read a bunch of in-flight changes. This can be the wrong choice too, but it’s worth considering. It can be especially useful for modification queries that are just out looking for some work to do.
We’ll talk about my favorite option in tomorrow’s post.
Recompiling All The Things
Look, you wanna recompile a report or something, fine. I do, too. I love doing it, because then I don’t have one less random issue to think about.
Weirdly sniffed parameter? No mas, mon ami.
Magick.
Especially in cases where bigger code changes are hard/impossible, this can be sensible, like dealing with a million local variables.
Just be really careful using it everywhere, especially in code that executes a ton. You don’t wanna spend all your time constantly coming up with query plans any more than you wanna get parameter sniffed.
Plus, since Query Store captures plans with recompile hints, you can still keep track of performance over time. This can be a great way to figure out a parameter sniffing problem, too.
Gotcha
Basic understanding often is often just camouflage for complete confusion. Often, once you dig past the documentation marketing materials, you’ll find every feature has a whole lot of drawbacks, trade-offs, blind spots, and interoperability issues.
Databases being databases, often just getting your schema to a state where you can test new features is a heroic feat.
No wonder so many millions of hours have been spent trying to replace them.
This post is links to a series of articles that it’s a shame more people haven’t seen, because they describe why some index builds/rebuilds take a lot longer than others.
Hopefully Microsoft doesn’t black hole these, as they have so much other valuable material recently.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I do love appropriately applied uniqueness. It can be helpful not just for keeping bad data out, but also help the optimizer reason about how many rows might qualify when you join or filter on that data.
The thing is, I disagree a little bit with how most people set them up, which is by creating a unique constraint.
Unique constraints are backed by nonclustered indexes, but they’re far more limited in what you can do with them.
For example, you can’t apply a filter definition, or have any included columns in them. And a lot of the time, those things make the data you’re identifying as unique more useful.
Included Battery
Here’s what I see quite a bit: A unique constraint on a single key column, and then a nonclustered index on that column, plus included columns.
So now you have two indexes on that column, only one of them is unique, and only of them gets used in queries as a data source.
The unique constraint may still get used for cardinality estimation, but the structure itself just sits around absorbing writes all the live long day.
In this case, you’re almost always better off using a unique nonclustered index with includes instead.
Sure, this doesn’t work if you have one column that needs to be unique, but you want multiple columns in the key of a nonclustered index, but that’s not what I’m talking about here.
Feelings Filter
That you can add a where clause to indexes is still news to some people, and that’s fine.
Often they’re used to isolate and index certain portions of your data that are frequently accessed, or that benefit from having a statistics histogram built specifically on and for them, which don’t have any of their 201 steps tainted or influenced by data outside of the filter.
The latter scenario is good for skewed or lumpy data that isn’t accurately depicted in a histogram on a full (probably rather large table) even with a full scan.
But another good use is filtering data down to just the portion of unique data that you care about. An example is if your table has multiple rows for a user’s sessions, but only one session can be active. Having a unique filtered index on users, filtered to just what’s active, can get you down to just the stuff you care about faster.
Clean Up
If you ever run sp_BlitzIndex and see duplicate or borderline duplicate indexes, some of them may be on unique constraints or indexes.
Don’t be afraid to merge semantically equivalent constraints or indexes together. Just be sure to obey the rules of key column order, and all that.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Whenever I see people using NOLOCK hints, I try to point out that they’re not a great idea, for various reasons explained in detail all across the internet.
At minimum, I want them to understand that the hint name is the same as setting the entire transaction isolation level to READ UNCOMMITTED, and that the hint name is quite misleading. It doesn’t mean your query takes no locks, it means your query ignores locks taken by other queries.
That’s how you can end up getting incorrect results.
That warning often comes with a lot of questions about how to fix blocking problems so you can get rid of those hints.
After all, if you get rid of them, your SQL Server queries will (most likely) go back to using the READ COMMITTED isolation level and we all know that read committed is a garbage isolation level, anyway.
Cause and Wrecked
An important thing to understand is why the hint was used in the first place. I’ve worked with some nice developers who slapped it on every query just in case.
There was no blocking or deadlocking. They just always used it, and never stopped.
Not that I blame them; the blocking that can occur under read committed the garbage isolation level is plain stupid, and no respectable database platform should use it as a default.
In many ways, it’s easier for a user to re-run a query and hopefully get the right result and shrug and mumble something about computers being awful, which is also true.
So, first step: ask yourself if there was ever really a blocking problem to begin with.
Bing Tutsby
Next, we need to understand where the blocking was coming from. Under read committed the garbage isolation level, writers can block readers, and readers can block writers.
In most cases though, people have added the hint to all of their queries, even ones that never participated in blocking.
If the problem was writers blocking writers, no isolation can help you.
If the problem was readers blocking writers, you may need to look at long running queries with Key Lookups
If the problem was writers blocking readers, you’d have to look at a few things:
Do they have good indexes in place to locate rows to update or delete?
If you have query store enabled, you can use sp_QuickieStore to search it for queries that do a lot of writes. If you don’t, you can use sp_BlitzCache to search the plan cache for them.
Best Case
Of course, you can avoid all of these problems, except for writers blocking writers, by using an optimistic isolation level like Read Committed Snapshot Isolation or Snapshot Isolation.
In the past, people made a lot of fuss about turning these on, because
You may not have tempdb configured correctly
You have queue type code that relied on blocking for correctness
But in reasonably new versions of SQL Server, tempdb’s setup is part of the install process, and the wacky trace flags you used to have to turn on are the default behavior.
If you do have code in your application that processes queues and relies on locking to correctly process them, you’re better off using locking hints in that code, and using an optimistic isolation level for the rest of your queries. This may also be true of triggers that are used to enforce referential integrity, which would need READCOMMITTEDLOCK hints.
The reason why they’re a much better choice than using uncommitted isolation levels is because rather than get a bunch of dirty reads from in-flight changes, you read the last known good version of the row before a modification started.
This may not be perfect, but it will prevent the absolute majority of your blocking headaches. It will even prevent deadlocks between readers and writers.
No, Lock
If your code has a lot of either NOLOCK hints or READ UNCOMITTED usage, you should absolutely be worried about incorrect results.
There are much better ways to deal with blocking, and I’ve outlined some of them in this post.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Most tables you encounter in SQL Server will have a clustered row store index on them, and probably some nonclustered row store indexes too.
If you live in the data warehouse world, you’ll probably see more and more column store indexes (hopefully), and if you need to report straight from your OLTP tables, you might even see some nonclustered column store indexes.
If your non-staging tables are heaps, you’ve probably got other things you should be doing than reading this post, like figuring out a good clustered index for them.
But anyway! Let’s focus on the most common types of tables, so that most everyone can happily follow along.
Drown Out
When you’ve got a table with a row store clustered index, all of your nonclustered indexes will “inherit” the keys of the clustered index. Where they end up depends on if the nonclustered index is defined as unique or not.
Non unique nonclustered row store indexes will store them in the key
Unique nonclustered row store indexes will store them as includes
There are times when a single key column index can be useful, like for a unique constraint.
But for the most part, outside of the occasional super-critical query that needs to be tuned, single key column indexes either get used in super-confusing ways, or don’t get used at all and just sit around hurting your buffer pool and transaction log, and increasing the likelihood of lock escalation.
Expansive
I can hear a lot of you saying that you use them to help foreign keys, and while a single key column index may get used for those processes, you most likely have many other queries that join tables with foreign key relationships together.
Those queries aren’t gonna sit around with just join columns. You’re gonna select, filter, group, and order those columns too, and wider indexes are gonna be way more helpful for that, and wider indexes are just as useful for helping foreign keys do their job.
If you have a single key column index, and a wider index that leads with the same key column, you really need to ask yourself why you have that single key column index around anymore.
In extreme cases, I see people create a single key column index on every column in a table. That’s beyond absurd, and a recipe for disaster in all of the ways listed above.
If you truly need an index on every single column, then you need a column store index.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
When you’re looking for queries to tune, it’s important to understand which part is causing the slowdown.
That’s why Actual Execution plans are so valuable in newer versions of SQL Server and SSMS. Getting to see operator timing and wait stats for a query can tell you a lot about what kind of problem you’re facing.
Let’s take a look at some examples.
Diskord
If you’re looking at a query plan, and all the time is spent way to the right, when you’re reading from indexes, it’s usually a sign of one or two things:
You’re missing a good index for the query
You don’t have enough memory to cache data relevant to the query
If you run the query a second time, and it has the same characteristics — meaning we should now have the data cached in the buffer pool but we don’t — then one or both of those two things is true.
If you run the query a second time and it’s fast because all the data we care about is cached, then it’s more likely that only the second thing is true.
wasabi
For example, every time I run this query it takes 20 seconds because every time it has to read the clustered index from disk into memory to get a count. That’s because my VM has 96 GB of RAM, and the clustered index of the Posts table is about 120 GB. I can’t fit the whole thing into the buffer pool, so each time I run this query has the gas station sushi effect on the buffer pool.
If I add a nonclustered index — and keep in mind I don’t really condone adding single key column nonclustered indexes like this — the query finishes much faster, because the smaller nonclustered index takes less time to read, and it fits into the buffer pool.
CREATE INDEX pr ON dbo.Posts
(
Id
);
birthday
If our query had different characteristics, like a where clause, join, group by, order by, or windowing function, I’d consider all of those things for the index definition. Just grabbing a count can still benefit from a smaller index, but there’s nothing relational that we need to account for here.
Proc Rock
Let’s say you already have ideal indexes for a query, but it’s still slow. Then what?
There are lots of possible reasons, but we’re going to examine what a CPU bound query looks like. A good example is one that needs to process a lot of rows, though not necessarily return a lot of rows, like a count or other aggregate.
splish splash
While this query runs, CPUs are pegged like suburban husbands.
in the middle of the street
For queries of this stature, inducing batch mode is often the most logical choice. Why? Because CPU instructions are run over batches of rows at once, rather than a single row at a time.
With a small number of rows — like in an OLTP workload — you probably won’t notice any real gains. But for this query that takes many millions of rows and produces an aggregate, it’s Hammer Time™
known as such
Rather than ~30 seconds, we can get our query down to ~8 seconds without making a single other change to the indexes or written form.
Under Compression
For truly large data sets, compression indexes is a great choice for further reducing I/O bound portions of queries. In SQL Server, you have row, page, and column store (clustered and nonclustered) compression available to you based on the type of workload you’re running.
When you’re tuning a query, it’s important to keep the type of bottleneck you’re facing in mind. If you don’t, you can end up trying to solve the wrong problem and getting nowhere.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.