While helping someone tame a bunch of rather unfortunate scalar valued functions, we eventually hit a point where they were able to do some of the rewrites themselves. During testing, they ran into a situation where performance got worse when they made the switch over, and it wasn’t because an Eager Index Spool popped up.
I was able to come up with a demo that shows a reasonable enough performance difference in a couple queries using the same technique as I gave them to fix things.
So uh, here goes that.
Muppet
The query they were tuning had a couple OUTER APPLYs already written into it, and so they added the function on as another.
SELECT
u.DisplayName,
b.Name,
nbi.AvgPostsPerDay
FROM dbo.Users AS u
OUTER APPLY
(
SELECT
CreationDate =
MIN(p.CreationDate)
FROM dbo.Posts AS p
JOIN dbo.Votes AS v
ON v.PostId = p.Id
AND v.VoteTypeId = 1
WHERE p.OwnerUserId = u.Id
) AS p
OUTER APPLY
(
SELECT TOP (1)
b.Name
FROM dbo.Badges AS b
WHERE b.UserId = u.Id
ORDER BY b.Date DESC
) AS b
OUTER APPLY dbo.no_bueno_inline(u.Id, p.CreationDate) AS nbi
WHERE u.Reputation >= 100000
ORDER BY u.Reputation DESC;
Since they didn’t want to lose rows to the function, they couldn’t use CROSS APPLY. Good enough.
Moutarde
But what they really wanted was to move the function up into the select list, like this:
SELECT
u.DisplayName,
b.Name,
AvgPostsPerDay =
(
SELECT
nbi.AvgPostsPerDay
FROM dbo.no_bueno_inline
(
u.Id,
p.CreationDate
) AS nbi
)
FROM dbo.Users AS u
OUTER APPLY
(
SELECT
CreationDate =
MIN(p.CreationDate)
FROM dbo.Posts AS p
JOIN dbo.Votes AS v
ON v.PostId = p.Id
AND v.VoteTypeId = 1
WHERE p.OwnerUserId = u.Id
) AS p
OUTER APPLY
(
SELECT TOP (1)
b.Name
FROM dbo.Badges AS b
WHERE b.UserId = u.Id
ORDER BY b.Date DESC
) AS b
WHERE u.Reputation >= 100000
ORDER BY u.Reputation DESC;
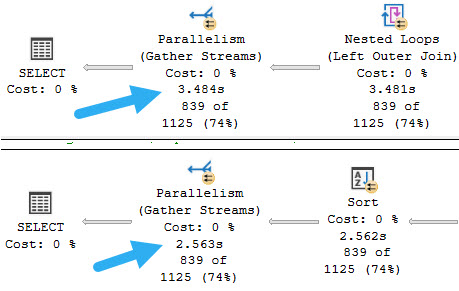
That way you don’t lose any rows like you could with CROSS APPLY, and the optimizer is more likely to holler at the function later on in the query plan, since the values from it are only being projected — that’s fancy for selected.
Mapperoo
The full query plan is a bit much to untangle quickly in this post, but the timing difference is noticeable enough for my purposes:
tootin
So if you ever end up rewriting a scalar valued function as an inline table valued function, make sure you test calling it in the same way. Moving query syntax around may produce logically equivalent results, but won’t always produce equivalent performance.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I see people do things like this fairly often with UDFs. I don’t know why. It’s almost like they read a list of best practices and decided the opposite was better.
This is a quite simplified function, but it’s enough to show the bug behavior.
While writing this, I learned that you can’t create a recursive (self-referencing) scalar UDF with the schemabinding option. I don’t know why that is either.
Please note that this behavior has been reported to Microsoft and will be fixed in a future update, though I’m not sure which one.
Swallowing Flies
Let’s take this thing. Let’s take this thing and throw it directly in the trash where it belongs.
CREATE OR ALTER FUNCTION dbo.how_high
(
@i int,
@h int
)
RETURNS int
WITH
RETURNS NULL ON NULL INPUT
AS
BEGIN
SELECT
@i += 1;
IF @i < @h
BEGIN
SET
@i = dbo.how_high(@i, @h);
END;
RETURN @i;
END;
GO
Seriously. You’re asking for a bad time. Don’t do things like this.
Unless you want to pay me to fix them later.
Froided
In SQL Server 2019, under compatibility level 150, this is what the behavior looks like currently:
/*
Works
*/
SELECT
dbo.how_high(0, 36) AS how_high;
GO
/*
Fails
*/
SELECT
dbo.how_high(0, 37) AS how_high;
GO
The first execution returns 36 as the final result, and the second query fails with this message:
Msg 217, Level 16, State 1, Line 40
Maximum stored procedure, function, trigger, or view nesting level exceeded (limit 32).
A bit odd that it took 37 loops to exceed the nesting limit of 32.
This is the bug.
Olded
With UDF inlining disabled, a more obvious number of loops is necessary to encounter the error.
/*
Works
*/
SELECT
dbo.how_high(0, 32) AS how_high
OPTION (USE HINT('DISABLE_TSQL_SCALAR_UDF_INLINING'));
GO
/*
Fails
*/
SELECT
dbo.how_high(0, 33) AS how_high
OPTION (USE HINT('DISABLE_TSQL_SCALAR_UDF_INLINING'));
GO
The first run returns 32, and the second run errors out with the same error message as above.
Does It Matter?
It’s a bit hard to imagine someone relying on that behavior, but I found it interesting enough to ask some of the nice folks at Microsoft about, and they confirmed that it shouldn’t happen. Again, it’ll get fixed, but I’m not sure when.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Let’s say at some point, you just didn’t know any better, and you wrote a scalar function to make some common thing you needed to do all “modular” and “portable” and stuff.
Good on you, not repeating yourself. Apparently I repeat myself for a living.
Anyway, you know what stinks? When you hit divide by zero errors. It’d be cool if math fixed that for us.
Does anyone know how I can get in touch with math?
Uncle Function
Since you’re a top programmer, you know about this sort of stuff. So you write a bang-up function to solve the problem.
Maybe it looks something like this.
CREATE OR ALTER FUNCTION dbo.safety_dance(@n1 INT, @n2 INT)
RETURNS INT
WITH SCHEMABINDING,
RETURNS NULL ON NULL INPUT
AS
BEGIN
RETURN
(
SELECT @n1 / NULLIF(@n2, 0)
);
END
GO
You may even be able to call it in queries about like this.
SELECT TOP (5)
u.DisplayName,
fudge = dbo.safety_dance(SUM(u.UpVotes), COUNT(*))
FROM dbo.Users AS u
GROUP BY u.DisplayName
ORDER BY fudge DESC;
The problem is that it makes this query take a long time.
you compute that scalar, sql server
At 23 seconds, this is probably unacceptable. And this is on SQL Server 2019, too. The function inlining thing doesn’t quite help us, here.
One feature restriction is this, so we uh… Yeah.
The UDF does not contain aggregate functions being passed as parameters to a scalar UDF
But we’re probably good query tuners, and we know we can write inline functions.
Ankle Fraction
This is a simple enough function. Let’s get to it.
CREATE OR ALTER FUNCTION dbo.safety_dance_inline(@n1 INT, @n2 INT)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT @n1 / NULLIF(@n2, 0) AS safety
);
Will it be faster?
SELECT TOP (5)
u.DisplayName,
fudge = (SELECT * FROM dbo.safety_dance_inline(SUM(u.UpVotes), COUNT(*)))
FROM dbo.Users AS u
GROUP BY u.DisplayName
ORDER BY fudge DESC;
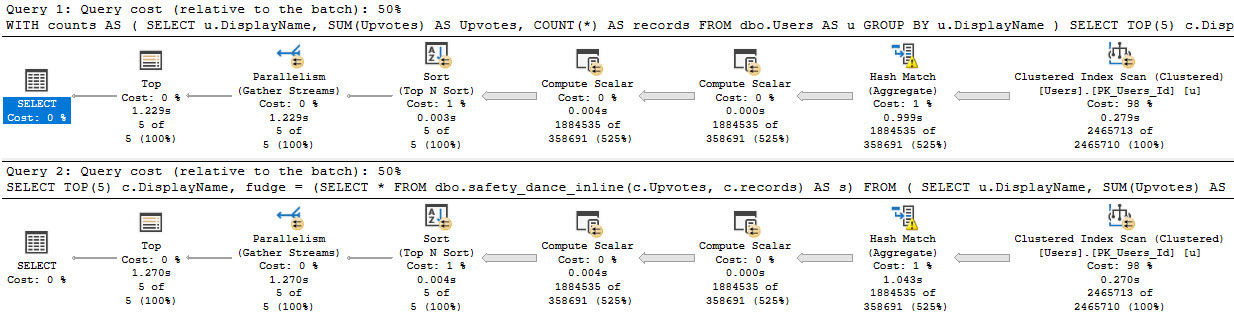
Well, yes. Mostly because it throws an error.
Msg 4101, Level 15, State 1, Line 35
Aggregates on the right side of an APPLY cannot reference columns from the left side.
Well that’s weird. Who even knows what that means? There’s no apply, here.
What’s your problem, SQL Server?
Fixing It
To get around this restriction, we need to also rewrite the query. We can either use a CTE, or a derived table.
--A CTE
WITH counts AS
(
SELECT
u.DisplayName,
SUM(Upvotes) AS Upvotes,
COUNT(*) AS records
FROM dbo.Users AS u
GROUP BY u.DisplayName
)
SELECT TOP(5)
c.DisplayName,
fudge = (SELECT * FROM dbo.safety_dance_inline(c.Upvotes, c.records) AS s)
FROM counts AS c
ORDER BY fudge DESC;
--A derived table
SELECT TOP(5)
c.DisplayName,
fudge = (SELECT * FROM dbo.safety_dance_inline(c.Upvotes, c.records) AS s)
FROM
(
SELECT
u.DisplayName,
SUM(Upvotes) AS Upvotes,
COUNT(*) AS records
FROM dbo.Users AS u
GROUP BY u.DisplayName
) AS c
ORDER BY fudge DESC;
Is it faster? Heck yeah it is.
you’re just so parallel, baby
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Yesterday we looked at where table variables can have a surprising! impact on performance. We’ll talk more about them later, because that’s not the only way they can stink. Not by a long shot. Even with 1 row in them.
Anyway, look, today’s post is sort of like yesterday’s post, except I’ve had two more drinks.
What people seem to miss about scalar valued functions is that there’s no distinction between ones that touch data and ones that don’t. That might be some confusion with CLR UDFs, which cause parallelism issues when they access data.
Beans and Beans
What I want to show you in this post is that it doesn’t matter if your scalar functions touch data or not, they’ll still have similar performance implications to the queries that call them.
Now look, this might not always matter. You could just use a UDF to assign a value to a variable, or you could call it in the context of a query that doesn’t do much work anyway. That’s probably fine.
But if you’re reading this and you have a query that’s running slow and calling a UDF, it just might be why.
If the UDF queries table data and is inefficient
If the UDF forces the outer query to run serially
They can be especially difficult on reporting type queries. On top of forcing them to run serially, the functions also run once per row, unlike inline-able constructs.
Granted, this once-per-row thing is worse for UDFs that touch data, because they’re more likely to encounter the slings and arrows of relational data. The reads could be blocked, or the query in the function body could be inefficient for a dozen reasons. Or whatever.
I’m Not Touching You
Here’s a function that doesn’t touch anything at all.
CREATE OR ALTER FUNCTION dbo.little_function (@UserId INT)
RETURNS BIGINT
WITH SCHEMABINDING,
RETURNS NULL ON NULL INPUT
AS
BEGIN
DECLARE @d DATETIME = GETDATE();
RETURN
(
(
SELECT @UserId
)
)
END
GO
I have the declared variable in there set to GETDATE() to disable UDF inlining in SQL Server 2019.
Yes, I know there’s a function definition to do the same thing, but I want you to see just how fragile a feature it is right now. Again, I love where it’s going, but it can’t solve every single UDF problem.
Anyway, back to the story! Let’s call that function that doesn’t do anything in our query.
SELECT TOP (1000)
c.Id,
dbo.little_function(c.UserId)
FROM dbo.Comments AS c
ORDER BY c.Score DESC;
The query plan looks like so, with the warning in properties about not being able to generate a valid parallel plan.
what’s so great about you?
In this plan, we see the same slowdown as the insert to the table variable. There’s no significant overhead from the function, it’s just slower in this case because the query is forced to run serially by the function.
This is because of the presence of a scalar UDF, which can’t be inlined in 2019. The serial plan represents, again, a significant slowdown over the parallel plan.
Bu-bu-bu-but wait it gets worse
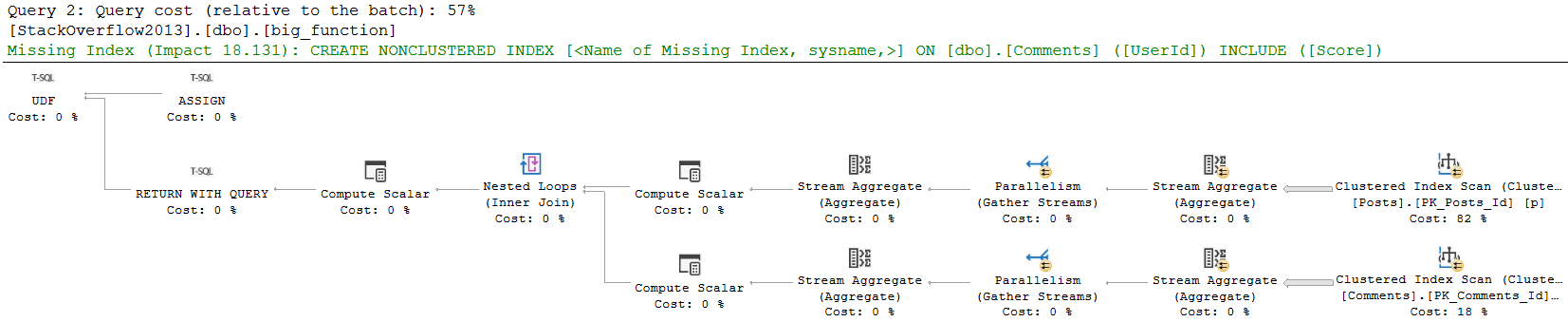
Let’s look at a worse function.
CREATE OR ALTER FUNCTION dbo.big_function (@UserId INT)
RETURNS BIGINT
WITH SCHEMABINDING,
RETURNS NULL ON NULL INPUT
AS
BEGIN
DECLARE @d DATETIME = GETDATE();
RETURN
(
(
SELECT SUM(p.Score)
FROM dbo.Posts AS p
WHERE p.OwnerUserId = @UserId
) -
(
SELECT SUM(c.Score)
FROM dbo.Comments AS c
WHERE c.UserId = @UserId
)
)
END
GO
Not worse because it’s a different kind of function, just worse because it goes out and touches tables that don’t have any helpful indexes.
Getting to the point, if there were helpful indexes on the tables referenced in the function, performance wouldn’t behave as terribly. I’m intentionally leaving it without indexes to show you a couple funny things though.
Because this will run a very long time with a top 1000, I’m gonna shorten it to a top 1.
SELECT TOP (1)
c.Id,
dbo.big_function(c.UserId)
FROM dbo.Comments AS c
ORDER BY c.Score DESC;
Notice that in this plan, the compute scalar takes up a more significant portion of query execution time. We don’t see what the compute scalar does, or what the function itself does in the actual query plan.
got yourself a function
The compute scalar operator is what’s responsible for the scalar UDF being executed. In this case, it’s just once. If I had a top that asked for more than one row, It would be responsible for more executions.
We don’t see the function’s query plan in the actual query, because it could generate a different query plan on each execution. Would you really want to see 1000 different query plans?
Anyway, it’s quite easy to observe with operator times where time is spent here. Most people read query plans from right to left, and that’s not wrong.
In that same spirit, we can add operator times up going from right to left. Each operator not only account for its own time, but for the time of all operators that come before it.
The clustered index scan takes 7.5 seconds, the Sort takes 3.3 seconds, and the compute scalar takes 24.9 seconds. Wee.
Step Inside
If you get an actual plan for this query, you won’t see what the function does. If you get an estimated plan, you can get a picture of what the function is up to.
monster things
This is what I meant by the function body being allowed to go parallel. This may lead to additional confusion when the calling query accrues parallel query waits but shows no parallel operators, and has a warning that a parallel plan couldn’t be generated.
hi my name is
It’s Not As Funny As It Sounds
If you look at a query plan’s properties and see a non-parallel plan reason, table variable modifications and scalar UDFs will be the most typical cause. They may not always be the cause of your query’s performance issues, and there are certainly many other local factors to consider.
It’s all a bit like a game of Clue. You might find the same body in the same room with the same bashed in head, but different people and blunt instruments may have caused the final trauma.
Morbid a bit, sure, but if query tuning were always a paint by numbers, no one would stay interested.
Anyway.
In the next posts? we’ll look at when SQL Server tells you it needs an index, and when it doesn’t.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Yesterday we created an index, and things went pretty well. Good for us. By next week we’ll have six pack abs.
Today we’re going to look at things that I see happen pretty often in queries that mess with effciency.
If one were to sit and think carefully about the way B-Tree indexes are implemented, where key columns define order, one may see these problems coming a mile away.
Then again, one might expect a full formed datababby system to be able to figure some of these things out and use indexes appropriately anyway.
General Anti-Patterns
I’ve posted this on here a number of times, but here it goes again.
Things that keep SQL Server from being able to seek:
Function(Column) = …
Column + Column = …
Column + Value = …
Value + Column = …
Column = @Value or @Value IS NULL
Column LIKE ‘%…’
Some implicit conversions (data type mismatches)
Seeks aren’t always necessary, or even desirable, and likewise scans aren’t always bad or undesirable. But if we’re going to give our queries the best chance of running well, our job is most often to give the optimizer every opportunity to make the right decisions. Being the optimizer is hard enough without us grabbing it by the nose and poking it in the eyes.
To fix code, or make code that looks like that tolerable to The Cool DBA Kids™, there are some options like:
Computed columns
Dynamic SQL
Rewrites
Different options work well in different scenarios, of course. And since we’re here, I might as well foreshadow a future post: These patterns are most harmful when applied to the leading key column of an index. When they’re residual predicates that follow seek predicates, they generally make less of a difference. But we’re not quite there yet.
The general idea, though, is that as soon as we write queries in a way that obscure column data, or introduce uncertainty about what we’re searching for, the optimizer has a more difficult time of things.
Do It Again
Let’s compare a couple different ways of writing yesterday’s query. One good, one bad (in that order).
SELECT p.CreationDate,
COUNT_BIG(*) AS records
FROM dbo.Posts AS p
WHERE p.CreationDate >= '20131225'
GROUP BY p.CreationDate;
SELECT p.CreationDate,
COUNT_BIG(*) AS records
FROM dbo.Posts AS p
WHERE YEAR(p.CreationDate) = 2013
AND MONTH(p.CreationDate) = 12
AND DAY(p.CreationDate) >= 25
GROUP BY p.CreationDate;
The mistake people often make here is that they think these presentation layer functions have some relational meaning. They don’t.
They’re presentation layer functions. Let’s see those execution plans. Maybe then you’ll believe me.
horse and carriage
Things are not so hot when we pile a Mess Of Functions™ into the where clause, are they?
I mean, our CPUs are hot, but that’s generally not what we’re after.
The Use Of Indexes
We could still use our index. Many people will talk about functions preventing the use of indexes, but more precisely we just can’t seek into them.
But you know what can prevent the use of nonclustered indexes? Long select lists.
Next time, we’ll look at that.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
There’s a lot of terrible advice out there about how to do this. It’s terrible because it involves the kinds of functions that really hurt performance: the scalar and multi-statement variety.
Worse, they’re usually full of while loops that build strings. These kinds of scalar functions aren’t currently eligible for inlining in 2019 either, so don’t think you’re going to get helped there, because they build strings.
SELECT with variable accumulation/aggregation (for example, SELECT @val += col1 FROM table1) is not supported for inlining.
Ain’t Perfect
I don’t think my solutions are perfect. Heck, doing this with T-SQL at all is a bad idea. You should be using CLR for this, but CLR has had so little support or betterment over the years, I don’t blame you for not embracing it. My dear friend Josh has taken the liberty of doing this part for you.
It would be nice if SQL Server had the kind of native support for writing in other languages that free databases do (especially since SQL Server supports Python, R, and Java now). But you know, we really needed uh… Well, just pick any dead-end feature that’s been added since 2005 or so.
My solutions use a numbers table. You’re free to try replacing that aspect of them with an inlined version like Jeff Moden uses in his string splitter, but I found the numbers table approach faster. Granted, it’s also less portable, but that’s a trade-off I’m willing to make.
What I don’t like about either solution is that I have to re-assemble the string using XML PATH. If you’ve got another way to do that, I’m all ears. I know 2017 has STRING_AGG, but that didn’t turn out much better, and it wouldn’t be usable in other supported versions.
Both scripts are hosted on my GitHub repo. I don’t want to set the example of using a blog post as version control.
SELECT u.DisplayName, gl.*
FROM dbo.Users AS u
CROSS APPLY dbo.get_letters(u.DisplayName) AS gl
WHERE u.Reputation = 11;
Complaint Department
If you’ve got ideas, bugs, or anything else, please let me know on GitHub. I realize that both scripts have holes in them, but you may find them good enough to get you where you’re going.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I’ve posted quite a bit about how cached plans can be misleading.
I’m gonna switch that up and talk about how an actual plan can be misleading, too.
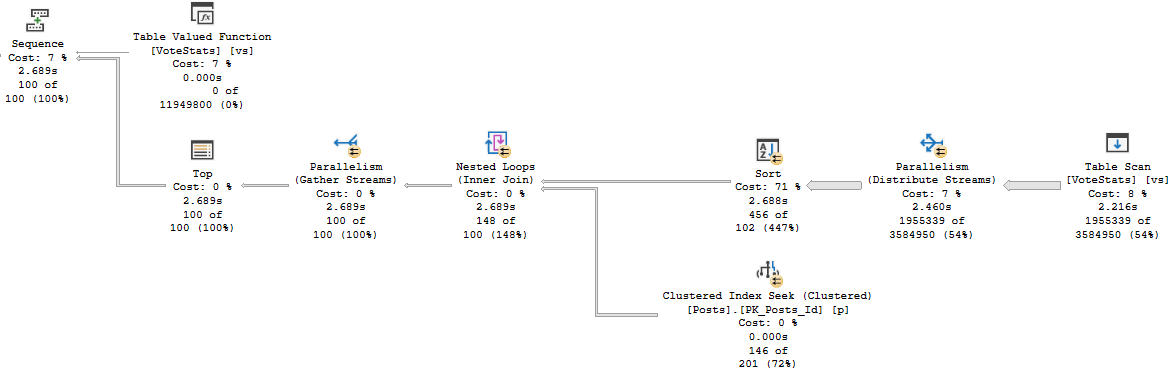
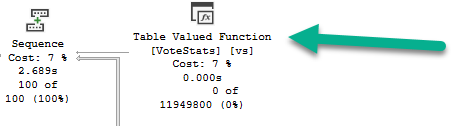
In plans that include calling a muti-statement table valued function, no operator logs the time spent in the function.
Here’s an example:
SELECT TOP (100)
p.Id AS [Post Link],
vs.up,
vs.down
FROM dbo.VoteStats() AS vs --The function
JOIN dbo.Posts AS p
ON vs.postid = p.Id
WHERE vs.down > vs.up_multiplier
AND p.CommunityOwnedDate IS NULL
AND p.ClosedDate IS NULL
ORDER BY vs.up DESC
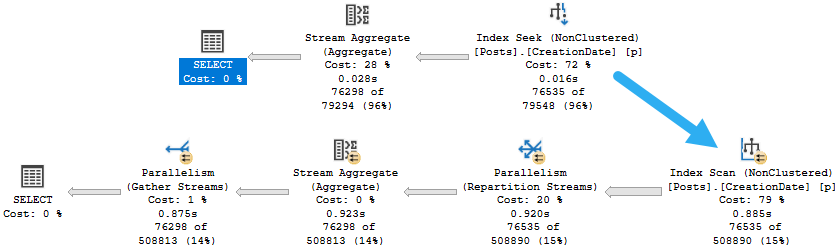
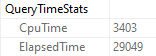
When I run the query, it drags on for 30-ish seconds, but the plan says that it only ran for about 2.7 seconds.
As we proceed
But there it is in Query Time Stats! 29 seconds. What gives?
Hi there!
Estimations
If we look at the estimated plan for the function, we can see quite a thick arrow pointing to the table variable we populate for our results.
Meatballs
That process is all part of the query, but it doesn’t show up in any of the operators. It really should.
More specifically, I think it should show up right here.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I had a client recently with, wait for it, a performance problem. Or rather, two problems.
The OLTP part was working fine, but there was a reporting element that was dog slow, and would cause all sorts of problems on the server.
When we got into things, I noticed something rather funny: All of their reporting queries had very high estimated costs, and all the plans were totally serial.
The problem came down to two functions that were used in the OLTP portion, which were reused in the reporting portion.
Uh Ohs
I know what you’re thinking: 2019 would have fixed it.
Buuuuuuuuuuut.
No.
As magnificent and glorious as FROID is, there are a couple limitations that are pretty big gotchas:
The UDF does not invoke any intrinsic function that is either time-dependent (such as GETDATE()) or has side effects3 (such as NEWSEQUENTIALID()).
And
1SELECT with variable accumulation/aggregation (for example, SELECT @val += col1 FROM table1) is not supported for inlining.
Which is what both were doing. One was doing some date math based on GETDATE, the other was assembling a string based on some logic, and not the kind of thing that STRING_AGG would have helped with, unfortunately.
They could both be rewritten with a little bit of work, and once we did that and fixed up the queries using them, things looked a lot different.
Freeee
For these plans, it wasn’t just that they were forced to run on one CPU that was harming performance. In some cases, these functions were in WHERE clauses. They were being used to filter data from tables with many millions of rows.
Yes, there was a WHERE clause that looked like AND dbo.function(somecol) LIKE ‘%thing%’, which was… Brave?
Getting rid of those bottlenecks relieved quite a lot of pain.
If you want to find stuff like this on your own, here’s what you can do:
Looking at the execution plan, hit get the properties of the select operator and look for a “NonParallelPlanReason”
Run sp_BlitzCache and look for “Forced Serialization” warnings
Inspect Filter operators in your query plans (I’m almost always suspicious of these things)
Review code for scalar valued function calls
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.