If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
This is an okay trick to keep in mind when you need to use order by on a large table.
Of course, we care about order by for many very good reasons, especially when we don’t have an index to support the ordering.
Sorting data requires memory, and Sort operators particularly may ask for quite a bit of memory.
Why? Because you need to sort all the columns you’re selecting by the column you’re ordering by.
Sorts aren’t just for the column(s) in your order by — if you SELECT *, you need order to all the columns in the * by all the columns in the order by.
I know I basically repeated myself. That’s for emphasis. It’s something professional writers do.
Dig it.
Butheywhatabout
Let’s say, just for kicks, that we have a table in our database. And maybe it has a column called something like “Id” in it.
Pushing this tale further into glory, let’s also assume that this legendary “Id” column is the primary key and clustered index.
That means we have the entire table sorted by this one column. Cool.
Tighten those wood screws, because we’re about to go cat 5 here. Ready?
There’s a date or date time column in the table — let’s say it defines when the row was first inserted into the table.
It could be a creation date, or an order date. Doesn’t matter.
What does matter? That the “Id” and the “*Date” column increment at the same time, which means that they’re in the same order.
It may suit your queries better to order by the clustered index key column rather than another column in the table which may not be in a helpful index in a helpful order for you query.
Too Sort
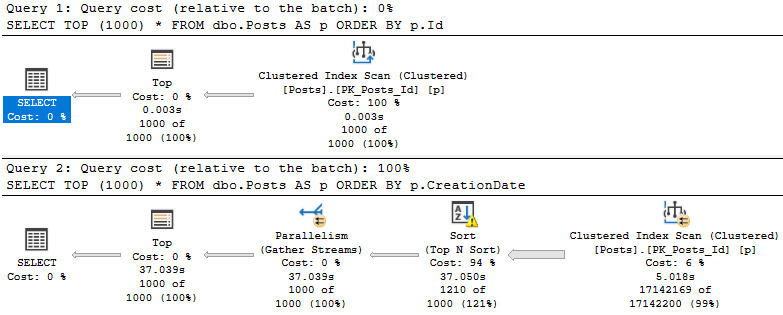
Take these two queries:
SELECT TOP (1000) *
FROM dbo.Posts AS p
ORDER BY p.Id;
SELECT TOP (1000) *
FROM dbo.Posts AS p
ORDER BY p.CreationDate;
I know, they’re terribly unrealistic. No one would ever. Not even close. Fine.
smh
Though both queries present the same data in the same order, the query that orders by the CreationDate column takes uh.
Considerably longer.
For reasons that should be apparent.
Of course, we could add an index to help. Just add all the indexes. What could go wrong?
If you have the type of application that lets users, say, dynamically filter and order by whatever columns they want, you’ve got a whole lot of index to create.
Better get started.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Yes, indexed view maintenance can be quite rough. I don’t mean like, rebuilding them. I will never talk about that.
I mean that, in some cases locks are serializable, and that if you don’t mind your indexes you may find run-of-the-mill modifications taking quite a long time.
Let’s go look!
Mill Town
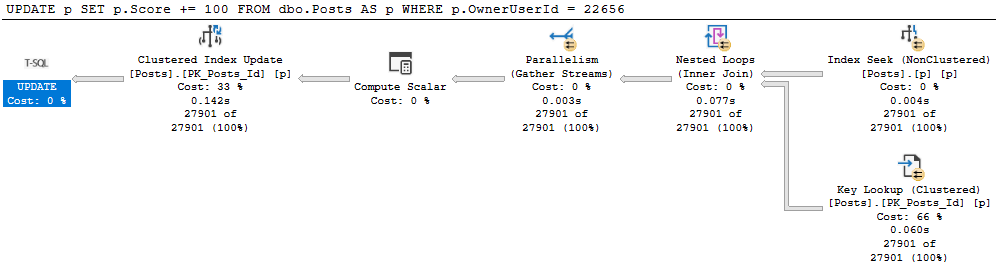
Let’s get update a small chunk of the Posts table.
BEGIN TRAN
UPDATE p
SET p.Score += 100
FROM dbo.Posts AS p
WHERE p.OwnerUserId = 22656;
ROLLBACK
Let’s all digress from the main point of this post for a moment!
It’s generally useful to give modifications an easy path to find data they need to update. For example:
Uh no
This update takes 1.6 seconds because we have no useful index on OwnerUserId. But we get a daft missing index request, because it wants to include Score, which would mean we’d need to then update that index as well as read from it. Locking leads to NOLOCK hints. I tend to want to introduce as little of it as possible.
With an index on just OwnerUserId, our situation improves dramatically.
100000X IMPROVEMENT
Allow Me To Reintroduce Myself
Let’s see what happens to our update with an indexed view in place.
CREATE OR ALTER VIEW dbo.PostScoresVotes
WITH SCHEMABINDING
AS
SELECT p.Id,
SUM(p.Score * 1.0) AS ScoreSum,
COUNT_BIG(v.Id) AS VoteCount,
COUNT_BIG(*) AS OkayThen
FROM dbo.Posts AS p
JOIN dbo.Votes AS v
ON p.Id = v.PostId
WHERE p.PostTypeId = 2
AND p.CommunityOwnedDate IS NULL
GROUP BY p.Id;
GO
CREATE UNIQUE CLUSTERED INDEX c_Id
ON dbo.PostScoresVotes(Id);
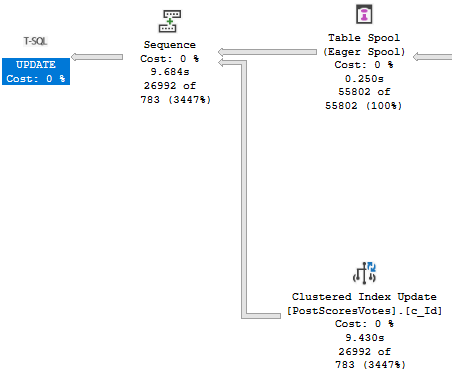
Our update query now takes about 10 seconds…
Oof dawg
With the majority of the time being spent assembling the indexed view for maintenance.
Yikes dawg
The Problem Of Course
Is that our indexes are bad. We’ve got no helpful index between Posts and Votes to help with the assembly.
Our first clue may have been when creating the indexed view took a long time, but hey.
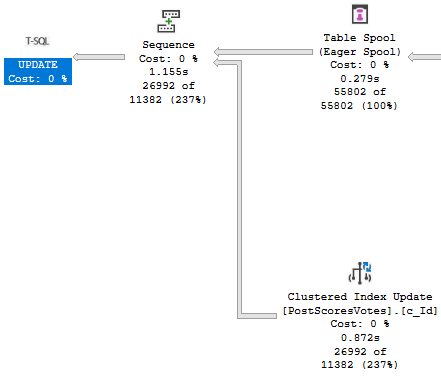
Let’s fix it.
CREATE INDEX v ON dbo.Votes(PostId);
Now our update finishes in about a second!
Cleant Up
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Sometimes I think it’s interesting how adding a seemingly useless or harmless thing to a query can change the query plan.
Here’s a quick example using an Order By on an indexed column.
Top 1
I understand that without an ORDER BY, any TOP query will be non-deterministic. In this case, that’s okay. I only want to know if any Id exists in the Votes table for votes types that aren’t 5 or 8. Order doesn’t matter to me.
SELECT TOP (1) u.Id
FROM dbo.Users AS u
WHERE EXISTS
(
SELECT 1 / 0
FROM dbo.Votes AS v
WHERE v.UserId = u.Id
AND v.VoteTypeId NOT IN ( 5, 8 )
);
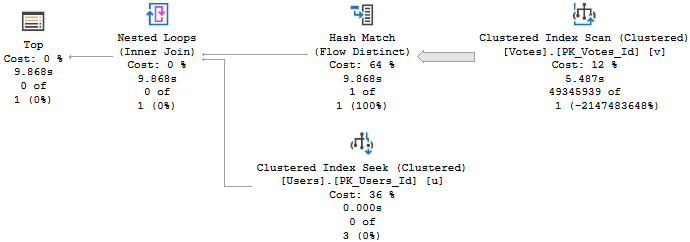
The trouble is that this query runs for about 10 seconds to find nothing.
You don’t stop
Yes, there are many other ways to express this query — you might even use a COUNT, which would bypass the problem — but hey, some people love TOPs.
Hors d’Oeuvres By
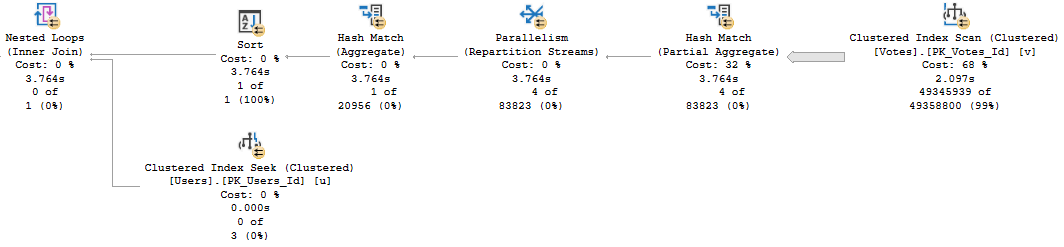
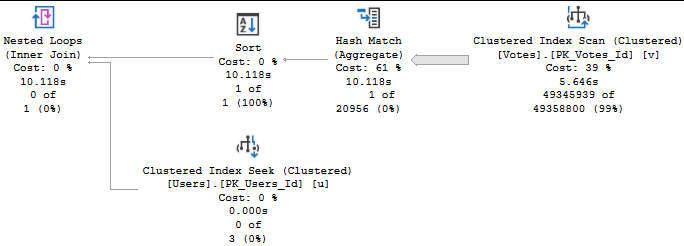
Adding an order by here has a rather significant impact on the query plan, even though the column I’m asking to be ordered is the PK/CX of the Users table, meaning it’s already in order.
SELECT TOP (1) u.Id
FROM dbo.Users AS u
WHERE EXISTS
(
SELECT 1 / 0
FROM dbo.Votes AS v
WHERE v.UserId = u.Id
AND v.VoteTypeId NOT IN ( 5, 8 )
)
ORDER BY u.Id;
The query plan now looks like this:
You won’t stop
Who’s That Sort?
Why did that happen? Let’s take a look!
Notice that the Sort isn’t taking place for the Users table, but rather the Votes table.
Udderly
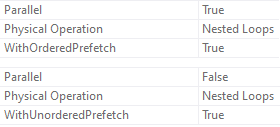
We’re putting the UserId column in order now. This is to help us with the Nested Loops operator, which has slightly different properties now.
Fetch HAPPENED
Notice how one Nested Loops join used an Ordered Prefetch, and the other uses an Unordered Prefetch?
That’s a side effect of the ORDER BY.
And, yeah, the plan with the Order By is “faster” because it went parallel. That won’t always be the case, and when it’s not, any efficiency is lost.
Das Bumer
Something To Keep In Mind
Asking for ordered data can change a lot of things about a query. More superficial things, like indexes used, joins and aggregates chosen, parallelism or serial(ism?). It can also change less obvious things, like memory grants, the type of prefetch used, etc.
Sometimes you don’t have a choice in the matter — you need data in a specific order at some point in the query for correctness — but quite often presentation layer ordering is best left out of your queries. Unless of course you have indexes that store data in the order you want, so there’s no extra work incurred.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
If you have selective predicates earlier in the index that filter a lot of rows, the SARGability of trailing predicates matters less.
CREATE INDEX shorty ON dbo.a_table(selective_column, non_selective_column);
SELECT COUNT(*) AS records
FROM dbo.a_table AS a
WHERE selective_column = 1
AND ISNULL(non_selective_column, 'whatever') = 'whatever';
Am I saying you should do this? Am I saying that it’s a good example to set?
No. I’m just saying you can get away with it in this situation.
Longer Answer
The less selective other predicates are, the less you can get away with it.
Take these two queries:
SELECT COUNT(*) AS records
FROM dbo.Users AS u
WHERE u.Id = 8
AND ISNULL(u.Location, N'') = N'';
SELECT COUNT(*) AS records
FROM dbo.Users AS u
WHERE u.Id BETWEEN 8 AND 9693617
AND ISNULL(u.Location, N'') = N'';
The first one has an equality predicate on the Id, the primary key of the table. It’s going to touch one row, and then evaluate the residual predicate on Location.
The second query has a very non-selective range predicate on Id — still a selective column, just not a selective predicate anymore — so, we do a lot more work (relatively).
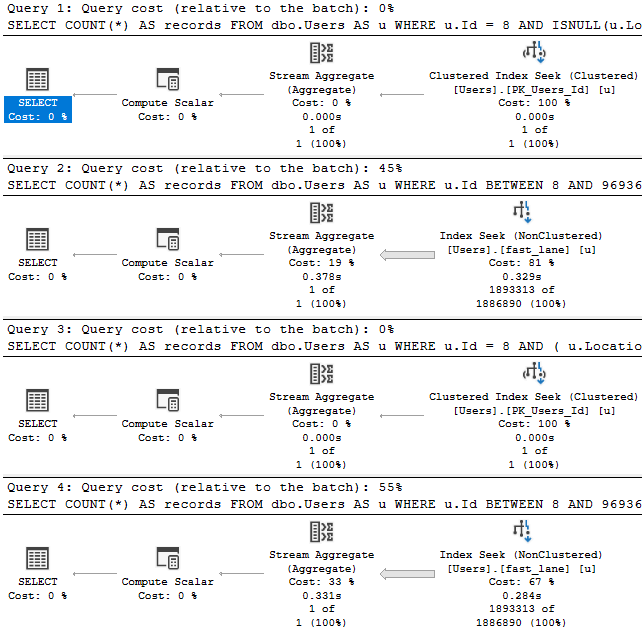
If we have this index, and we look at how four logically equivalent queries perform:
CREATE UNIQUE INDEX fast_lane ON dbo.Users(Id, Location);
SELECT COUNT(*) AS records
FROM dbo.Users AS u
WHERE u.Id = 8
AND ISNULL(u.Location, N'') = N'';
SELECT COUNT(*) AS records
FROM dbo.Users AS u
WHERE u.Id BETWEEN 8 AND 9693617
AND ISNULL(u.Location, N'') = N'';
SELECT COUNT(*) AS records
FROM dbo.Users AS u
WHERE u.Id = 8
AND ( u.Location = N''
OR u.Location IS NULL );
SELECT COUNT(*) AS records
FROM dbo.Users AS u
WHERE u.Id BETWEEN 8 AND 9693617
AND ( u.Location = N''
OR u.Location IS NULL );
The query plans tell us enough:
Toasty
It really doesn’t matter if we obey the laws of SARGability here.
Expect Depression
There have been many times when explaining SARGability to people that they went back and cleaned up code like this to find it didn’t make much of a difference to performance. That’s because SARGability depends on indexes that can support seekable predicates. Without those indexes, it makes no practical difference how you write these queries.
Again, I’m not condoning writing Fast Food Queries when you can avoid it. Like I said earlier, it sets a bad example.
Once this kind of code creeps into your development culture, it’s hard to keep it contained.
There’s no reason to not avoid it, but sometimes it hurts more than others. For instance, if Location were the first column in the index, we’d have a very different performance profile across all of these queries, and other rewrites might start to make more sense.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I see people using OUTPUT to audit modifications from time to time, often because “triggers are bad” or “triggers are slow”.
Well, sometimes, sure. But using OUTPUT can be a downer, too.
Let’s look at how.
A Process Emerges
Say we’ve got a table that we’re using to track user high scores for their questions.
CREATE TABLE dbo.HighQuestionScores
(
Id INT PRIMARY KEY CLUSTERED,
DisplayName NVARCHAR(40) NOT NULL,
Score BIGINT NOT NULL
);
To test the process, let’s put a single user in the table:
INSERT dbo.HighQuestionScores WITH (TABLOCK)
(Id, DisplayName, Score)
SELECT u.Id, u.DisplayName, p.Score
FROM dbo.Users AS u
JOIN
(
SELECT p.OwnerUserId,
MAX(p.Score) AS Score
FROM dbo.Posts AS p
WHERE p.PostTypeId = 1
GROUP BY p.OwnerUserId
) AS p ON p.OwnerUserId = u.Id
WHERE u.Id = 22656;
To exacerbate the problem, I’m not going to create any helpful indexes here. This is a good virtual reality simulator, because I’ve seen your indexes.
Yes you. Down in front.
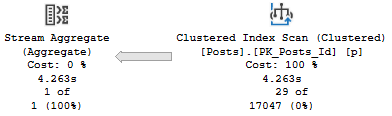
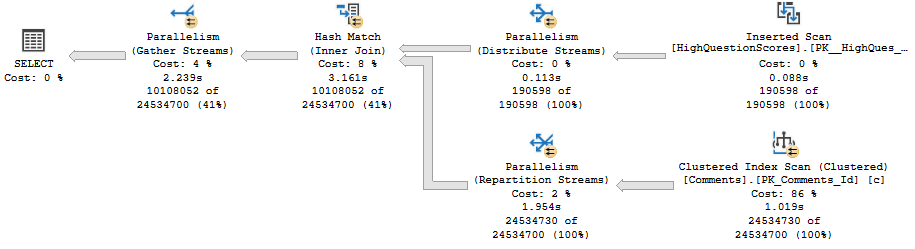
The relevant part of the query plan is the scan of the Posts table:
Practice
It’s parallel, and takes 1.8 seconds.
Aw, dit
Now let’s add in an OUTPUT clause.
I’m going to skip over inserting the output into any structure, because I want you to understand that the target doesn’t matter.
INSERT dbo.HighQuestionScores WITH (TABLOCK)
(Id, DisplayName, Score)
OUTPUT Inserted.Id,
Inserted.DisplayName,
Inserted.Score
SELECT u.Id, u.DisplayName, p.Score
FROM dbo.Users AS u
JOIN
(
SELECT p.OwnerUserId, MAX(p.Score) AS Score
FROM dbo.Posts AS p
WHERE p.PostTypeId = 1
GROUP BY p.OwnerUserId
) AS p ON p.OwnerUserId = u.Id
WHERE u.Id = 22656;
The relevant part of the plan now looks like this:
Golf Coach
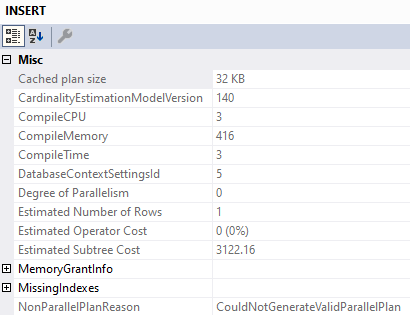
We’ve lost parallelism, and inspecting the properties of the Insert operator tells us why:
Less Successful
We’ve got a Non Parallel Plan Reason. Why aren’t there any spaces? I don’t know.
Why can’t that go parallel? I also don’t know.
What About Triggers?
If we create a minimal trigger on the table, we can see if it has the same overhead.
CREATE OR ALTER TRIGGER dbo.hqs_insert ON dbo.HighQuestionScores
AFTER INSERT
AS
BEGIN
SET NOCOUNT ON;
SELECT Inserted.Id,
Inserted.DisplayName,
Inserted.Score
FROM Inserted;
END
Let’s go back to the original insert, without the output! We care about two things:
Is the parallel portion of the insert plan still there?
Is there any limitation on parallelism with the Inserted (and by extension, Deleted) virtual tables?
The answers are mostly positive, too. The insert plan can still use parallelism.
I’m not gonna post the same picture here, you can scroll back fondly.
Though the select from the Inserted table within the trigger doesn’t go parallel, it doesn’t appear to limit parallelism for the entire plan. It does appear that reads from the Inserted table can’t use parallelism (sort of like the table variable in a MSTVF).
Let’s modify the trigger slightly:
CREATE OR ALTER TRIGGER dbo.hqs_insert ON dbo.HighQuestionScores
AFTER INSERT
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Id INT
DECLARE @DisplayName NVARCHAR(40)
DECLARE @Score BIGINT
SELECT @Id = Inserted.Id,
@DisplayName = Inserted.DisplayName,
@Score = Inserted.Score
FROM Inserted
JOIN dbo.Comments AS c
ON c.UserId = Inserted.Id;
END
And for variety, let’s insert a lot more data into our table:
TRUNCATE TABLE dbo.HighQuestionScores;
INSERT dbo.HighQuestionScores WITH (TABLOCK)
(Id, DisplayName, Score)
SELECT u.Id, u.DisplayName, p.Score
FROM dbo.Users AS u
JOIN
(
SELECT p.OwnerUserId, MAX(p.Score) AS Score
FROM dbo.Posts AS p
WHERE p.PostTypeId = 1
GROUP BY p.OwnerUserId
) AS p ON p.OwnerUserId = u.Id
WHERE u.Id < 500000;
Here’s the query plan:
Wrecking Ball
The read from Inserted is serial, but the remainder of the plan fully embraces parallelism like a long lost donut.
Togetherness
Given a well-tuned workload, you may not notice any particular overhead from using OUTPUT to audit certain actions.
Of course, if you’re using them alongside large inserts, and those large inserts happen to run for longer than you’d like, it might be time to see how long they take sans the OUTPUT clause. It’s entirely possible that using a trigger instead would cause fewer performance issues.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I had a client recently with, wait for it, a performance problem. Or rather, two problems.
The OLTP part was working fine, but there was a reporting element that was dog slow, and would cause all sorts of problems on the server.
When we got into things, I noticed something rather funny: All of their reporting queries had very high estimated costs, and all the plans were totally serial.
The problem came down to two functions that were used in the OLTP portion, which were reused in the reporting portion.
Uh Ohs
I know what you’re thinking: 2019 would have fixed it.
Buuuuuuuuuuut.
No.
As magnificent and glorious as FROID is, there are a couple limitations that are pretty big gotchas:
The UDF does not invoke any intrinsic function that is either time-dependent (such as GETDATE()) or has side effects3 (such as NEWSEQUENTIALID()).
And
1SELECT with variable accumulation/aggregation (for example, SELECT @val += col1 FROM table1) is not supported for inlining.
Which is what both were doing. One was doing some date math based on GETDATE, the other was assembling a string based on some logic, and not the kind of thing that STRING_AGG would have helped with, unfortunately.
They could both be rewritten with a little bit of work, and once we did that and fixed up the queries using them, things looked a lot different.
Freeee
For these plans, it wasn’t just that they were forced to run on one CPU that was harming performance. In some cases, these functions were in WHERE clauses. They were being used to filter data from tables with many millions of rows.
Yes, there was a WHERE clause that looked like AND dbo.function(somecol) LIKE ‘%thing%’, which was… Brave?
Getting rid of those bottlenecks relieved quite a lot of pain.
If you want to find stuff like this on your own, here’s what you can do:
Looking at the execution plan, hit get the properties of the select operator and look for a “NonParallelPlanReason”
Run sp_BlitzCache and look for “Forced Serialization” warnings
Inspect Filter operators in your query plans (I’m almost always suspicious of these things)
Review code for scalar valued function calls
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Our job now is to figure out how to even things out. To do that, we’re gonna need to mess with out index a little bit.
Right now, we have this one:
CREATE INDEX whatever
ON dbo.Posts(PostTypeId, LastActivityDate)
INCLUDE(Score, ViewCount);
Which is fine when we need to Sort a small amount of data.
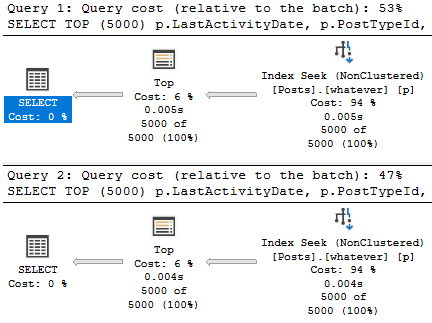
SELECT TOP (5000)
p.LastActivityDate,
p.PostTypeId,
p.Score,
p.ViewCount
FROM dbo.Posts AS p
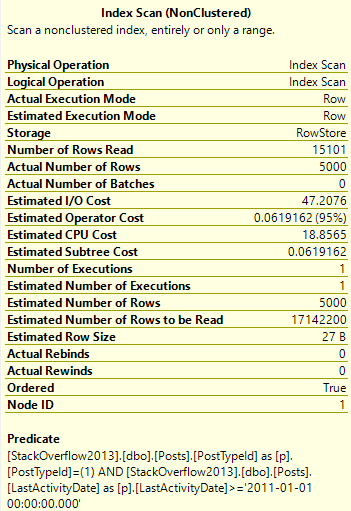
WHERE p.PostTypeId = 4
AND p.LastActivityDate >= '20120101'
ORDER BY p.Score DESC;
There’s only about 25k rows with a PostTypeId of 4. That’s easy to deal with.
The problem is here:
SELECT TOP (5000)
p.LastActivityDate,
p.PostTypeId,
p.Score,
p.ViewCount
FROM dbo.Posts AS p
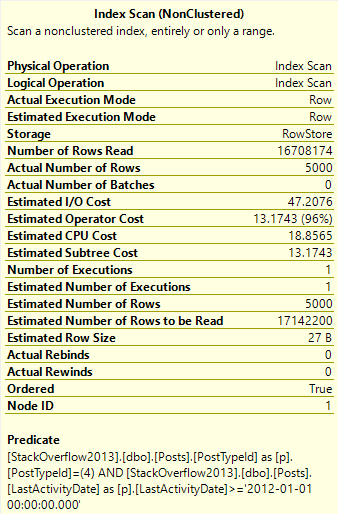
WHERE p.PostTypeId = 1
AND p.LastActivityDate >= '20110101'
ORDER BY p.Score DESC;
Theres 6,000,223 rows with a PostTypeId of 1 — that’s a question.
Don’t get me started on PostTypeId 2 — that’s an answer — which has 11,091,349 rows.
Change Management
What a lot of people try first is an index that leads with Score. Even though it’s not in the WHERE clause to help us find data, the index putting Score in order first seems like a tempting fix to our problem.
CREATE INDEX whatever
ON dbo.Posts(Score DESC, PostTypeId, LastActivityDate)
INCLUDE(ViewCount)
The result is pretty successful. Both plans are likely fast enough, and we could stop here, but we’d miss a key point about B-Tree indexes.
It’s not so bad.
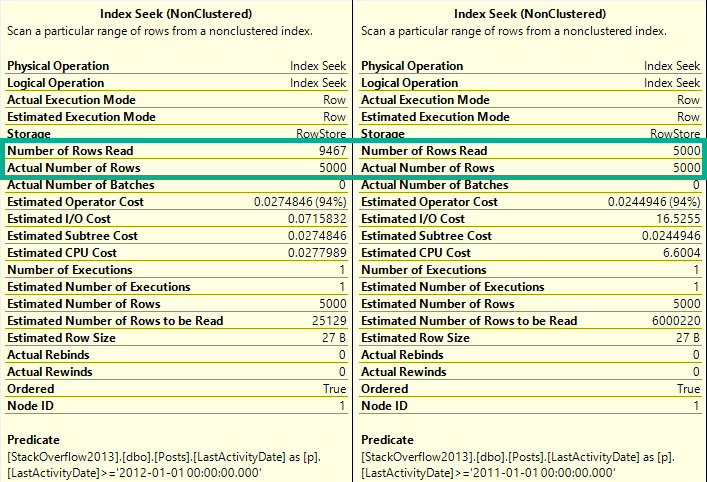
What’s a bit deceptive about the speed is the amount of reads we do to locate our data.
Scan-Some
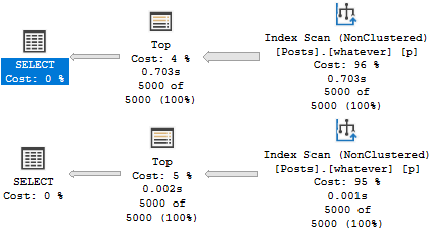
We only need to read 15k rows to find the top 5000 Questions — remember that these are very common.
We need to read many more rows to find the top 5000… Er… Whatever a 4 means.
Imaginary Readers
Nearly the entire index is read to locate these Post Types.
Meet In The Middle
The point we’d miss if we stopped tuning there is that when we add key columns to a B-Tree index, the index is first ordered by the leading key column. If it’s not unique, then the second column is ordered within each range of values.
Pale Coogi Wave
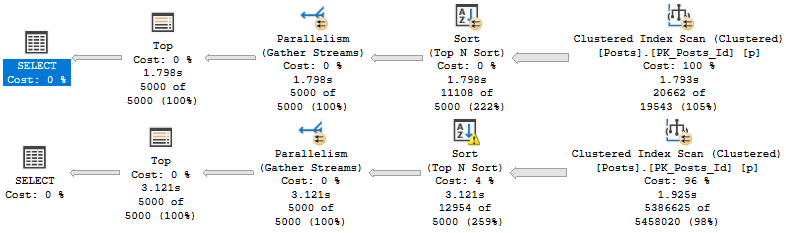
Putting this together, let’s change our index a little bit:
CREATE INDEX whatever
ON dbo.Posts(PostTypeId, Score DESC, LastActivityDate)
INCLUDE(ViewCount) WITH (DROP_EXISTING = ON);
With the understanding that seeking to a single PostTypeId column will bring us to an ordered Sort column for that range of values.
Now our plans look like this:
???
Which allows us to both avoid the Sort and keep reads to a minimum.
reed les
Interior Design
When designing indexes, it’s important to keep the goal of queries in mind. Often, predicates should be the primary consideration.
Other times, we need to take ordering and grouping into account. For example, if we’re using window functions, performance might be unacceptable without indexing the partition by and order by elements, and we may need to move other columns to parts of the index that may not initially seem ideal.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I asked you to design one index to make two queries fast.
If we look at the plans with no supporting indexes, we’ll see why they need some tuning.
Get a job
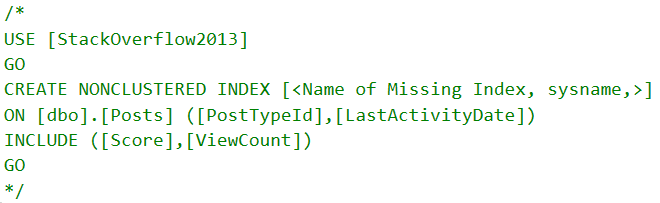
In both queries, the optimizer will ask for a “missing index”. That’s in quotes because, gosh darnit, I wouldn’t miss this index.
Green Screen
Nauseaseated
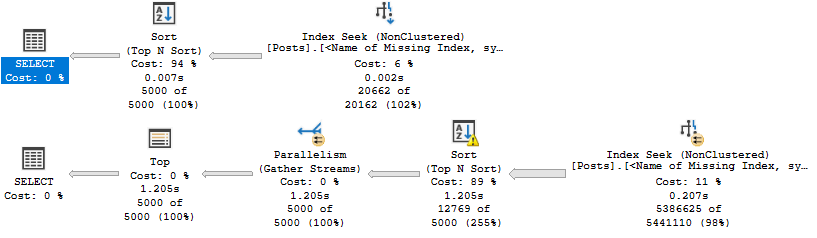
If we add it, results are mixed, like cheap scotch.
Keep Walking
Sure, there’s some improvement, but both aren’t fast. The second query does a lot of work to sort data.
We have an inkling that if we stopped doing that, our query may get quicker.
Let’s stop and think here: What are we ordering by?
Of course, it’s the thing in the order by: Score DESC.
Where Do We Go Now?
It looks like that missing index request was wrong. Score shouldn’t have been an included column.
Columns in the include list are only ordered by columns in the key of the index.
If we wanna fix that Sort, we need to make it a key column.
But where?
Get to work.
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.