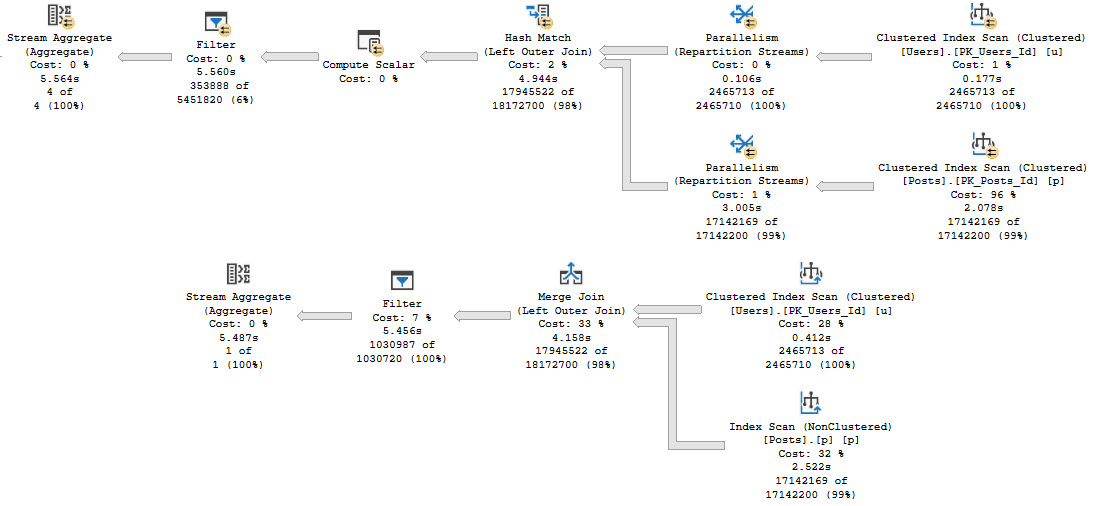
A lot of the time when I see queries that are written with all sorts of gymnastics in the join or where clause and I ask some questions about it, people usually start complaining about the design of the table.
That’s fine, but when I ask about changing the design, everyone gets quiet. Normalizing tables, especially for Applications Of A Certain Age™ can be a tremendously painful project. This is why it’s worth it to get things right the first time. Simple!
Rather than make someone re-design their schema in front of me, often times a temp table is a good workaround.
Egg Splat
Let’s say we have a query that looks like this. Before you laugh, and you have every right to laugh, keep in mind that I see queries like this all the time.
They don’t have to be this weird to qualify. You can try this if you have functions like ISNULL, SUBSTRING, REPLACE, or whatever in joins and where clauses, too.
SELECT
p.OwnerUserId,
SUM(p.Score) AS TotalScore,
COUNT_BIG(*) AS records
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON u.Id = CASE
WHEN p.PostTypeId = 1
THEN p.OwnerUserId
WHEN p.PostTypeId = 2
THEN p.LastEditorUserId
END
WHERE p.PostTypeId IN (1, 2)
AND p.Score > 100
GROUP BY p.OwnerUserId;
There’s not a great way to index for this, and sure, we could rewrite it as a UNION ALL, but then we’d have two queries to index for.
Sometimes getting people to add indexes is hard, too.
People are weird. All day weird.
Steak Splat
You can replace it with a query like this, which also allows you to index a single column in a temp table to do your correlation.
SELECT
p.OwnerUserId,
SUM(p.Score) AS TotalScore,
COUNT_BIG(*) AS records,
CASE WHEN p.PostTypeId = 1
THEN p.OwnerUserId
WHEN p.PostTypeId = 2
THEN p.LastEditorUserId
END AS JoinKey
INTO #Posts
FROM dbo.Posts AS p
WHERE p.PostTypeId IN (1, 2)
AND p.Score > 100
GROUP BY CASE
WHEN p.PostTypeId = 1
THEN p.OwnerUserId
WHEN p.PostTypeId = 2
THEN p.LastEditorUserId
END,
p.OwnerUserId;
SELECT *
FROM #Posts AS p
WHERE EXISTS
(
SELECT 1/0
FROM dbo.Users AS u
WHERE p.JoinKey = u.Id
);
Remember that temp tables are like a second chance to get schema right. Don’t waste those precious chances.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
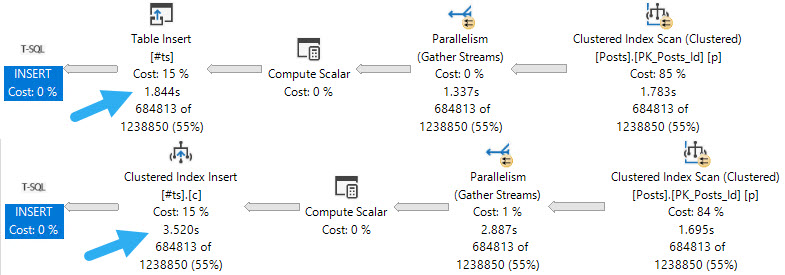
If you have a workload that uses #temp tables to stage intermediate results, and you probably do because you’re smart, it might be worth taking advantage of being able to insert into the #temp table in parallel.
If your code is already using the SELECT ... INTO #some_table pattern, you’re probably already getting parallel inserts. But if you’re following the INSERT ... SELECT ... pattern, you’re probably not, and, well, that could be holding you back.
Pile On
Of course, there are some limitations. If your temp table has indexes, primary keys, or an identity column, you won’t get the parallel insert no matter how hard you try.
The first thing to note is that inserting into an indexed temp table, parallel or not, does slow things down. If your goal is the fastest possible insert, you may want to create the index later.
No Talent
When it comes to parallel inserts, you do need the TABLOCK, or TABLOCKX hint to get it, e.g. INSERT #tp WITH(TABLOCK) which is sort of annoying.
But you know. It’s the little things we do that often end up making the biggest differences. Another little thing we may need to tinker with is DOP.
little pigs
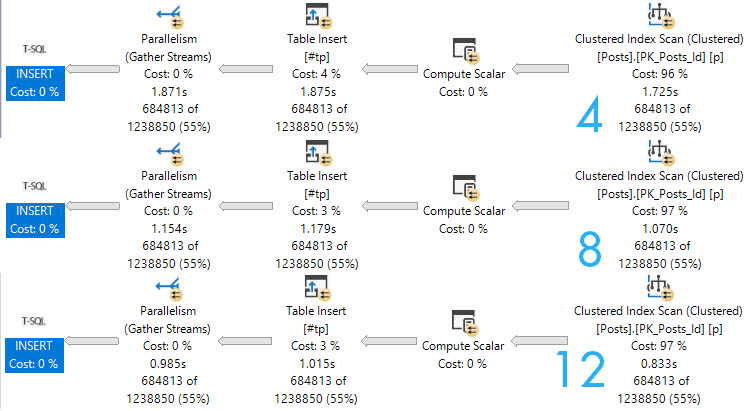
Here are the query plans for 3 fully parallel inserts into an empty, index-less temp #table. Note the execution times dropping as DOP increases. At DOP 4, the insert really isn’t any faster than the serial insert.
If you start experimenting with this trick, and don’t see noticeable improvements at your current DOP, you may need to bump it up to see throughput increases.
Though the speed ups above at higher DOPs are largely efficiency boosters while reading from the Posts table, the speed does stay consistent through the insert.
If we crank one of the queries that gets a serial insert up to DOP 12, we lose some speed when we hit the table.
oops
Next time you’re tuning a query and want to drop some data into a temp table, you should experiment with this technique.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
If your columns aren’t nullable, you’ll run into far fewer problems and ambiguities.
I’d like a new data type called ABYSS. Or maybe VOID.
The Problem: Wrong Data Type And NULL Checks
DECLARE @d date = '20170601';
DECLARE @sql nvarchar(MAX) = N'
SELECT
COUNT_BIG(*) AS records
FROM dbo.Posts AS p
WHERE p.LastEditDate > @d
AND p.LastEditDate IS NOT NULL;'
EXEC sp_executesql @sql,
N'@d date',
@d;
GO
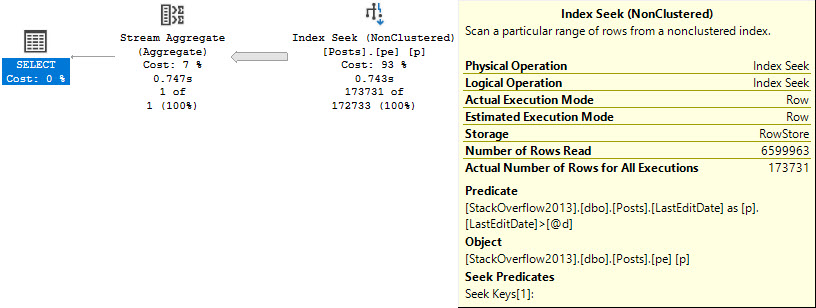
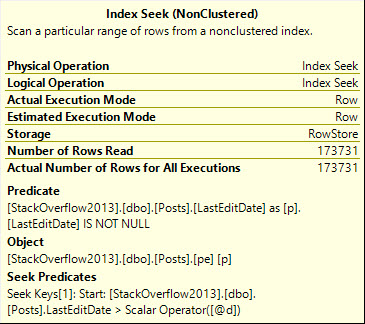
If we pass in a parameter that has a date datatype, rather than date time, an odd thing will happen if we add in a redundant IS NOT NULL check.
yortsed
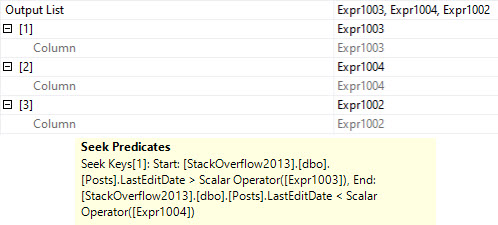
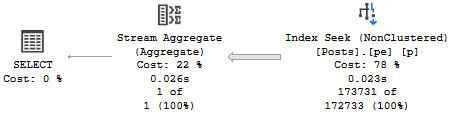
The seek predicate will only seek to the first non-NULL value, rather than immediately to the start of the range of dates we care about, which means we end up reading a lot more rows than necessary.
Note the query runtime of 743 milliseconds, and that we end up reading quite a few more rows than we return.
And here I was told Seeks are always efficient ?
Solution One: Stop Checking For NULLs
If we either stop checking for NULLs, we’ll get around the issue.
DECLARE @d date = '20170601';
DECLARE @sql nvarchar(MAX) = N'
SELECT
COUNT_BIG(*) AS records
FROM dbo.Posts AS p
WHERE p.LastEditDate > @d;'
EXEC sp_executesql @sql,
N'@d date',
@d;
GO
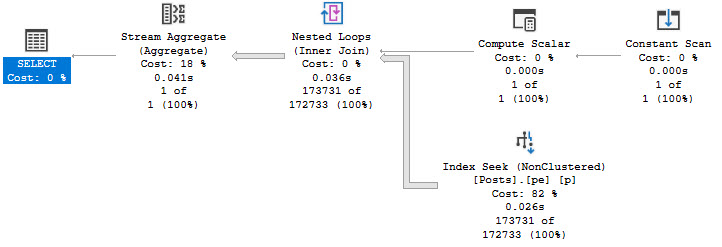
The plan for this query looks a bit different, but performance is no worse for the wear.
still using the wrong datatype
Note the 25 millisecond execution time. A clear improvement over the 743 milliseconds above. Though the query plan does look a bit odd.
The compute scalar gins up a date range, which is checked in the seek:
HELLO COMPUTER
I wonder what Expr1002 is up to.
Solution Two: Just Use The Right Datatype To Begin With
In reality, this is what we should have done from the start, but the whole point of this here blog post is to show you what can happen when you Do The Wrong Thing™
When we use the right datatype, we get a simple plan that executes quickly, regardless of the redundant NULL check.
DECLARE @d date = '20170601';
DECLARE @sql nvarchar(MAX) = N'
SELECT
COUNT_BIG(*) AS records
FROM dbo.Posts AS p
WHERE p.LastEditDate > @d
AND p.LastEditDate IS NOT NULL;'
EXEC sp_executesql @sql,
N'@d datetime',
@d;
no fuss, no muss
Here, the NULL check is a residual predicate rather than the Seek predicate, which results in a seek that really seeks instead of just meandering past some NULLs.
gerd jerb
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
We looked at a couple examples of when SQL Server might need to filter out rows later in the plan than we’d like, and why that can cause performance issues.
Now it’s time to look at a few more examples, because a lot of people find them surprising.
As much as I love surprising people, sometimes I’d much rather… not have to explain this stuff later.
Since all my showering and errands are out of the way, we should be able to get through this list uninterrupted.
Unless I get thirsty.
Max Datatypes
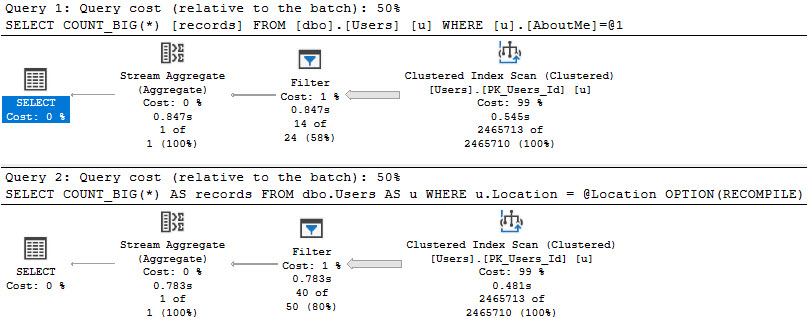
If we need to search a column that has a MAX datatype, or if we define a parameter as being a MAX datatype and search a more sanely typed column with it, both will result in a later filter operation than we may care for.
SELECT
COUNT_BIG(*) AS records
FROM dbo.Users AS u
WHERE u.AboutMe = N'Hi';
DECLARE @Location nvarchar(MAX) = N'here';
SELECT
COUNT_BIG(*) AS records
FROM dbo.Users AS u
WHERE u.Location = @Location
OPTION(RECOMPILE);
Even with a recompile hint!
opportunity knocked
Here we can see the value of properly defining string widths! If we don’t, we may end up reading entire indexes, and doing the work to weed out rows later.
Probably something that should be avoided.
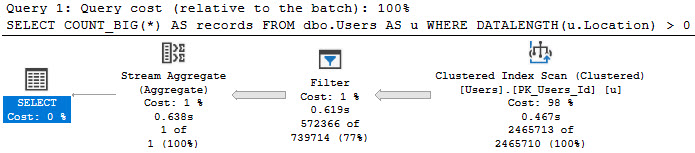
Functions
There are some built-in functions, like DATALENGTH, which can’t be pushed when used in a where clause.
Of course, if you’re going to do this regularly, you should be using a computed column to get around the issue, but whatever!
SELECT
COUNT_BIG(*) AS records
FROM dbo.Users AS u
WHERE DATALENGTH(u.Location) > 0;
measuring up
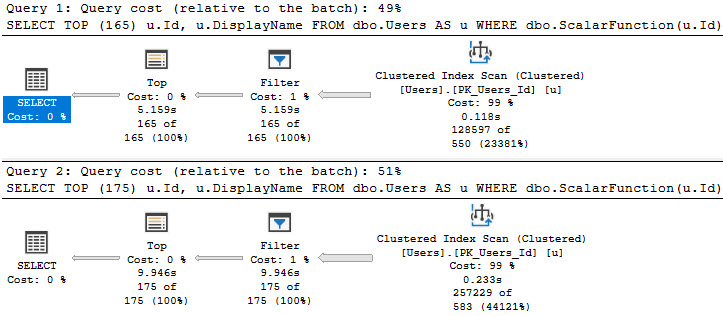
And of course, everyone’s favorite love-to-hate, the scalar UDF.
Funny thing about these, is that sometimes tiny bumps in the number of rows you’re after can make for big jumps in time.
SELECT TOP (165)
u.Id,
u.DisplayName
FROM dbo.Users AS u
WHERE dbo.ScalarFunction(u.Id) > 475
ORDER BY u.Id;
SELECT TOP (175)
u.Id,
u.DisplayName
FROM dbo.Users AS u
WHERE dbo.ScalarFunction(u.Id) > 475
ORDER BY u.Id;
10 more rows, 5 more seconds
Complexity
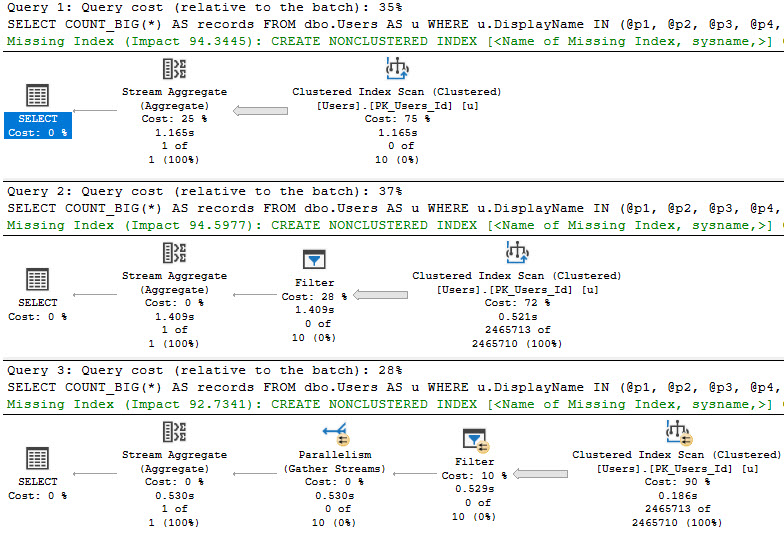
Sometimes people (and ORMs) will build up long parameter lists, and use them to build up a long list IN clause list, and even sometimes a long OR clause list.
To replicate that behavior, I’m using code I’m keeping on GitHub in order to keep this blog post a little shorter.
To illustrate where things can get weird, aside from the Filter, I’m going to run this with a few different numbers of parameters.
This will generate queries with different length IN clauses:
bigger than others
Which will result in slightly different query plans:
THREE!
We can see some tipping points here.
At 15 parameters, we get a scan with a stream aggregate
At 18 parameters, we get a scan with a filter
At 19 parameters, we get a parallel scan with a filter
Parallelism to the rescue, again, I suppose.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
When we write queries that need to filter data, we tend to want to have that filtering happen as far over to the right in a query plan as possible. Ideally, data is filtered when we access the index.
Whether it’s a seek or a scan, or if it has a residual predicate, and if that’s all appropriate isn’t really the question.
In general, those outcomes are preferable to what happens when SQL Server is unable to do any of them for various reasons. The further over to the right in a query plan we can reduce the number of rows we need to contend with, the better.
There are some types of filters that contain something called a “startup expression”, which are usually helpful. This post is not about those.
Ain’t Nothin’ To Do
There are some cases when you have no choice but to rely on a Filter to remove rows, because we need to calculate some expression that we don’t currently store the answer to.
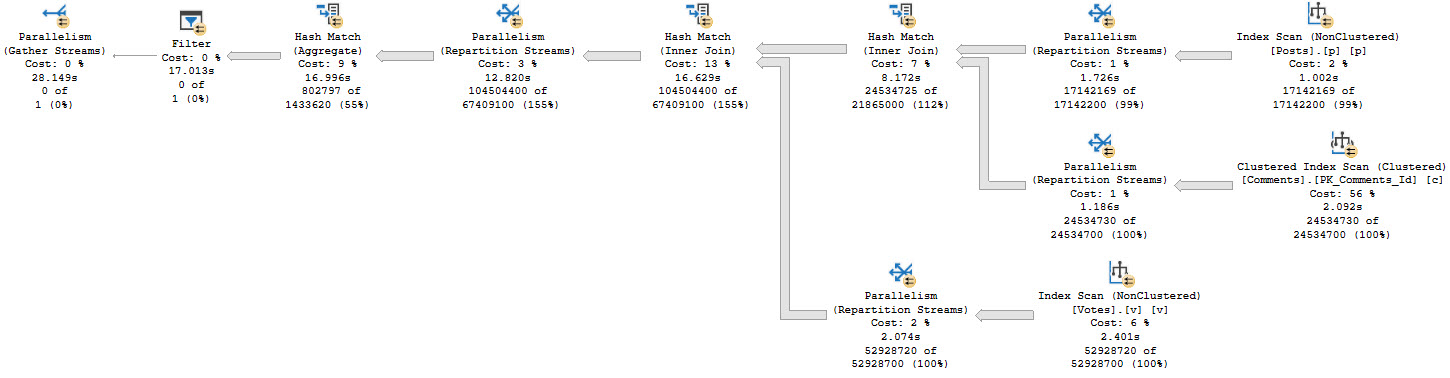
For example, having:
SELECT
p.OwnerUserId,
COUNT_BIG(*) AS records
FROM dbo.Posts AS p
JOIN dbo.Comments AS c
ON c.PostId = p.Id
JOIN dbo.Votes AS v
ON v.PostId = p.Id
GROUP BY p.OwnerUserId
HAVING COUNT_BIG(*) > 2147483647;
We don’t know which rows might qualify for the count filter up front, so we need to run the entire query before filtering things out:
this cold night
There’s a really big arrow going into that Filter, and then nothing!
SELECT
COUNT_BIG(*) AS records
FROM dbo.Users AS u
LEFT JOIN dbo.Posts AS p
ON p.OwnerUserId = u.Id
WHERE DATEDIFF(YEAR, p.CreationDate, p.LastActivityDate) > 5;
SELECT
COUNT_BIG(*) AS records
FROM dbo.Users AS u
LEFT JOIN dbo.Posts AS p
ON p.OwnerUserId = u.Id
WHERE p.Id IS NULL;
But what you get is disappointing!
not a gif
What we care about here is that, rather than filtering rows out when we touch indexes or join the tables, we have to fully join the tables together, and then eliminate rows afterwards.
This is generally considered “less efficient” than filtering rows earlier. Remember when I said that before? It’s still true.
Click the links above to see some solutions, so you don’t feel left hanging by your left joins.
The Message
If you see Filters in query plans, they might be for a good reason, like calculating things you don’t currently know the answer to.
They might also be for bad reasons, like you writing a query in a silly way.
There are other reasons they might show up too, that we’ll talk about tomorrow.
Why tomorrow? Why not today? Because if I keep writing then I won’t take a shower and run errands for another hour and my wife will be angry.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Look, I’m not saying there’s only one thing that the “Default” cardinality estimator does better than the “Legacy” cardinality estimator. All I’m saying is that this is one thing that I think it does better.
What’s that one thing? Ascending keys. In particular, when queries search for values that haven’t quite made it to the histogram yet because a stats update hasn’t occurred since they landed in the mix.
I know what you’re thinking, too! On older versions of SQL Server, I’ve got trace flag 2371, and on 2016+ that became the default behavior.
Sure it did — only if you’re using compat level 130 or better — which a lot of people aren’t because of all the other strings attached.
And that’s before you go and get 2389 and 2390 involved, too. Unless you’re on compatibility level 120 or higher! Then you need 4139.
Changes the fixed update statistics threshold to a linear update statistics threshold. For more information, see this AUTO_UPDATE_STATISTICS Option.
Note: Starting with SQL Server 2016 (13.x) and under the database compatibility level 130 or above, this behavior is controlled by the engine and trace flag 2371 has no effect.
Scope: global only
2389
Enable automatically generated quick statistics for ascending keys (histogram amendment). If trace flag 2389 is set, and a leading statistics column is marked as ascending, then the histogram used to estimate cardinality will be adjusted at query compile time.
Note: Please ensure that you thoroughly test this option, before rolling it into a production environment.
Note: This trace flag does not apply to CE version 120 or above. Use trace flag 4139 instead.
Scope: global or session or query (QUERYTRACEON)
2390
Enable automatically generated quick statistics for ascending or unknown keys (histogram amendment). If trace flag 2390 is set, and a leading statistics column is marked as ascending or unknown, then the histogram used to estimate cardinality will be adjusted at query compile time. For more information, see this Microsoft Support article.
Note: Please ensure that you thoroughly test this option, before rolling it into a production environment.
Note: This trace flag does not apply to CE version 120 or above. Use trace flag 4139 instead.
Scope: global or session or query (QUERYTRACEON)
4139
Enable automatically generated quick statistics (histogram amendment) regardless of key column status. If trace flag 4139 is set, regardless of the leading statistics column status (ascending, descending, or stationary), the histogram used to estimate cardinality will be adjusted at query compile time. For more information, see this Microsoft Support article.
Starting with SQL Server 2016 (13.x) SP1, to accomplish this at the query level, add the USE HINT ‘ENABLE_HIST_AMENDMENT_FOR_ASC_KEYS’ query hint instead of using this trace flag.
Note: Please ensure that you thoroughly test this option, before rolling it into a production environment.
Note: This trace flag does not apply to CE version 70. Use trace flags 2389 and 2390 instead.
Scope: global or session or query (QUERYTRACEON)
I uh. I guess. ?
Why Not Just Get Cardinality Estimation Right The First Time?
Great question! Hopefully someone knows the answer. In the meantime, let’s look at what I think this new-fangled cardinality estimator does better.
The first thing we need is an index with literally any sort of statistics.
CREATE INDEX v ON dbo.Votes_Beater(PostId);
Next is a query to help us figure out how many rows we can modify before an auto stats update will kick in, specifically for this index, though it’s left as an exercise to the reader to determine which one they’ve got in effect.
There are a lot of possible places this can kick in. Trace Flags, database settings, query hints, and more.
SELECT TOP (1)
OBJECT_NAME(s.object_id) AS table_name,
s.name AS stats_name,
p.modification_counter,
p.rows,
CONVERT(bigint, SQRT(1000 * p.rows)) AS [new_auto_stats_threshold],
((p.rows * 20) / 100) + CASE WHEN p.rows > 499 THEN 500 ELSE 0 END AS [old_auto_stats_threshold]
FROM sys.stats AS s
CROSS APPLY sys.dm_db_stats_properties(s.object_id, s.stats_id) AS p
WHERE s.name = 'v'
ORDER BY p.modification_counter DESC;
Edge cases aside, those calculations should get you Mostly Accurate™ numbers.
We’re going to need those for what we do next.
Mods Mods Mods
This script will allow us to delete and re-insert a bunch of rows back into a table, without messing up identity values.
--Create a temp table to hold rows we're deleting
DROP TABLE IF EXISTS #Votes;
CREATE TABLE #Votes (Id int, PostId int, UserId int, BountyAmount int, VoteTypeId int, CreationDate datetime);
--Get the current high PostId, for sanity checking
SELECT MAX(vb.PostId) AS BeforeDeleteTopPostId FROM dbo.Votes_Beater AS vb;
--Delete only as many rows as we can to not trigger auto-stats
WITH v AS
(
SELECT TOP (229562 - 1) vb.*
FROM dbo.Votes_Beater AS vb
ORDER BY vb.PostId DESC
)
DELETE v
--Output deleted rows into a temp table
OUTPUT Deleted.Id, Deleted.PostId, Deleted.UserId,
Deleted.BountyAmount, Deleted.VoteTypeId, Deleted.CreationDate
INTO #Votes;
--Get the current max PostId, for safe keeping
SELECT MAX(vb.PostId) AS AfterDeleteTopPostId FROM dbo.Votes_Beater AS vb;
--Update stats here, so we don't trigger auto stats when we re-insert
UPDATE STATISTICS dbo.Votes_Beater;
--Put all the deleted rows back into the rable
SET IDENTITY_INSERT dbo.Votes_Beater ON;
INSERT dbo.Votes_Beater WITH(TABLOCK)
(Id, PostId, UserId, BountyAmount, VoteTypeId, CreationDate)
SELECT v.Id, v.PostId, v.UserId, v.BountyAmount, v.VoteTypeId, v.CreationDate
FROM #Votes AS v;
SET IDENTITY_INSERT dbo.Votes_Beater OFF;
--Make sure this matches with the one before the delete
SELECT MAX(vb.PostId) AS AfterInsertTopPostId FROM dbo.Votes_Beater AS vb;
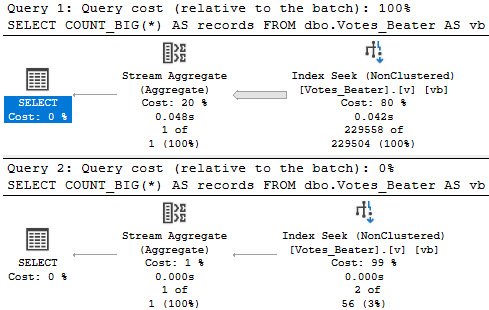
What we’re left with is a statistics object that’ll be just shy of auto-updating:
WE DID IT
Query Time
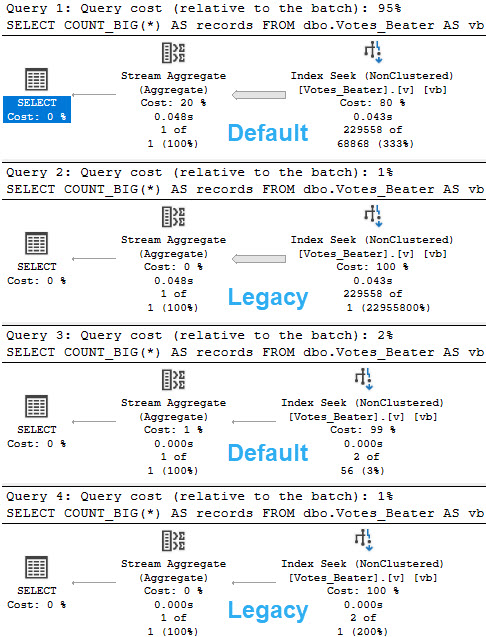
Let’s look at how the optimizer treats queries that touch values! That’ll be fun, eh?
--Inequality, default CE
SELECT
COUNT_BIG(*) AS records
FROM dbo.Votes_Beater AS vb
WHERE vb.PostId > 20671101
OPTION(RECOMPILE);
--Inequality, legacy CE
SELECT
COUNT_BIG(*) AS records
FROM dbo.Votes_Beater AS vb
WHERE vb.PostId > 20671101
OPTION(RECOMPILE, USE HINT('FORCE_LEGACY_CARDINALITY_ESTIMATION'));
--Equality, default CE
SELECT
COUNT_BIG(*) AS records
FROM dbo.Votes_Beater AS vb
WHERE vb.PostId = 20671101
OPTION(RECOMPILE);
--Equality, legacy CE
SELECT
COUNT_BIG(*) AS records
FROM dbo.Votes_Beater AS vb
WHERE vb.PostId = 20671101
OPTION(RECOMPILE, USE HINT('FORCE_LEGACY_CARDINALITY_ESTIMATION'));
For the record, > and >= produced the same guesses. Less than wouldn’t make sense here, since it’d hit mostly all values currently in the histogram.
hoodsy
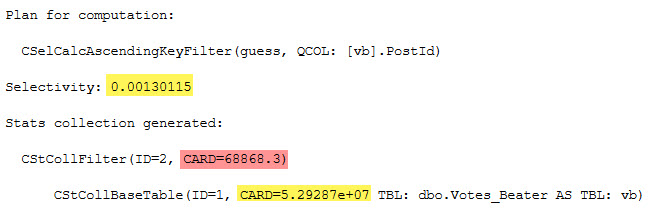
Inside Intel
For the legacy CE, there’s not much of an estimate. You get a stock guess of 1 row, no matter what.
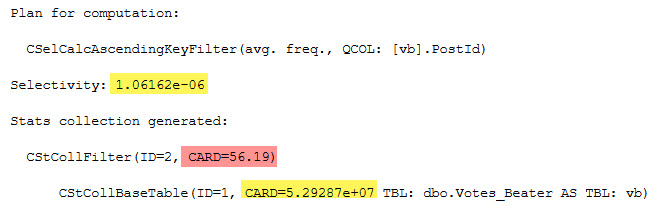
For the default CE, there’s a little more to it.
inequality
SELECT (0.00130115 * 5.29287e+07) AS inequality_computation;
equality
SELECT (1.06162e-06 * 5.29287e+07) AS equality_computation;
And of course, the CARD for both is the number of rows in the table:
SELECT CONVERT(bigint, 5.29287e+07) AS table_rows;
I’m not sure why the scientific notation is preferred, here.
A Little Strange
Adding in the USE HINT mentioned earlier in the post (USE HINT ('ENABLE_HIST_AMENDMENT_FOR_ASC_KEYS')) only seems to help with estimation for the inequality predicate. The guess for the equality predicate remains the same.
well okay
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
On the one hand, I don’t think the optimizer uses them enough. There are times when hinting a nonclustered index, or re-writing a query to get it to use a nonclustered index can really help performance.
On the other hand, they can really exacerbate parameter sniffing problems, and can even lead to read queries blocking write queries. And quite often, they lead to people creating very wide indexes to make sure particular queries are covered.
It’s quite a tedious dilemma, and in the case of blocking and, as we’ll see, deadlocks, one that can be avoided with an optimistic isolation level Read Committed Snapshot Isolation, or Snapshot Isolation.
Bigger Deal
There are ways to repro this sort of deadlock that rely mostly on luck, but the brute force approach is easiest.
First, create an index that will only partially help out some of our queries:
CREATE INDEX dethklok ON dbo.Votes(VoteTypeId);
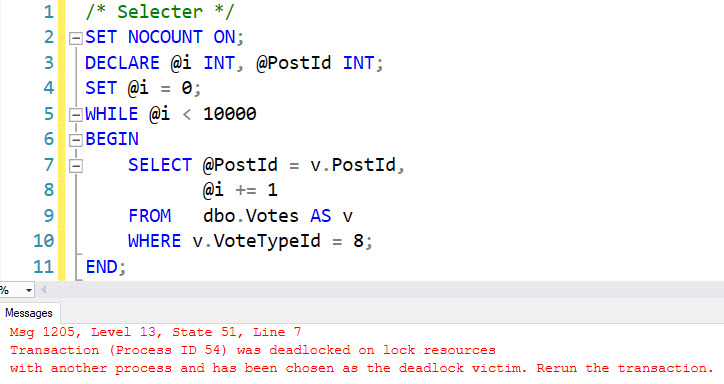
Next, get a couple queries that should be able to co-exist ready to run in a loop.
A select:
/* Selecter */
SET NOCOUNT ON;
DECLARE @i INT, @PostId INT;
SET @i = 0;
WHILE @i < 10000
BEGIN
SELECT
@PostId = v.PostId,
@i += 1
FROM dbo.Votes AS v
WHERE v.VoteTypeId = 8;
END;
An update:
/* Updater */
SET NOCOUNT ON;
DECLARE @i INT = 0;
WHILE @i < 10000
BEGIN
UPDATE v
SET v.VoteTypeId = 8 - v.VoteTypeId,
@i += 1
FROM dbo.Votes AS v
WHERE v.Id = 55537618;
END;
After several seconds, the select query will hit a deadlock.
i see you
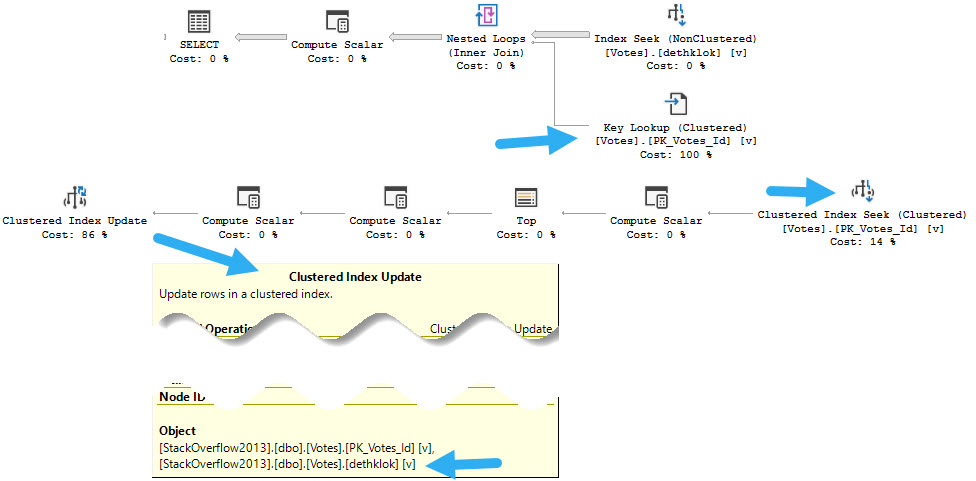
But Why?
The reason, of course, if that these two queries compete for the same indexes:
who’s who
The update query needs to update both indexes on the table, the read query needs to read from both indexes on the table, and they end up blocking each other:
kriss kross
We could fix this by expanding the index to also have PostId in it:
CREATE INDEX dethklok ON dbo.Votes(VoteTypeId, PostId);
Using an optimistic isolation level:
ALTER DATABASE StackOverflow2013
SET READ_COMMITTED_SNAPSHOT ON WITH ROLLBACK IMMEDIATE;
Or rewriting the select query to use a hash or merge join:
/* Selecter */
SET NOCOUNT ON;
DECLARE @i INT, @PostId INT;
SET @i = 0;
WHILE @i < 10000
BEGIN
SELECT @PostId = v2.PostId,
@i += 1
FROM dbo.Votes AS v
INNER /*MERGE OR HASH*/ JOIN dbo.Votes AS v2
ON v.Id = v2.Id
WHERE v.VoteTypeId = 8
END;
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Class Title: The Beginner’s Guide To Advanced Performance Tuning
Abstract: You’re new to SQL Server, and your job more and more is to fix performance problems, but you don’t know where to start.
You’ve been looking at queries, and query plans, and puzzling over indexes for a year or two, but it’s still not making a lot of sense.
Beyond that, you’re not even sure how to measure if your changes are working or even the right thing to do.
In this full day performance tuning extravaganza, you’ll learn about all the most common anti-patterns in T-SQL querying and indexing, and how to spot them using execution plans. You’ll also leave knowing why they cause the problems that they do, and how you can solve them quickly and painlessly.
If you want to gain the knowledge and confidence to tune queries so they’ll never be slow again, this is the training you need.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
None of your stored procedures are a single statement. They’re long. Miles long. Ages long.
If you’re troubleshooting performance for one of those, you could end up really causing yourself some headaches if you turn on actual execution plans and fire away.
Not only is there some overhead to collecting all the information for those plans, but then SSMS has to get all artsy and draw them from the XML.
Good news, though. If you’ve got some idea about which statement(s) are causing you problems, you can use an often-overlooked SET command.
Blitzing
One place I use this technique a lot is with the Blitz procedures.
For example, if I run sp_BlitzLock without plans turned on, it’s done in about 7 seconds.
If I run it with plans turned on, it runs for a minute and 7 seconds.
Now, a while back I had added a bit of feedback in there to help me understand which statements might be running the longest. You can check out the code I used over in the repo, but it produces some output like this:
Why is it always the XML?
If I’m not patient enough to, let’s say, wait a minute for this to run every time, I can just do something like this:
SET STATISTICS XML ON;
/*Problem queries here*/
SET STATISTICS XML OFF;
That’ll return just the query plans you’re interested in.
Using a screenshot for a slightly different example that I happened to have handy:
click me, click me, yeah
You’ll get back the normal results, plus a clickable line that’ll open up the actual execution plan for a query right before your very eyes.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
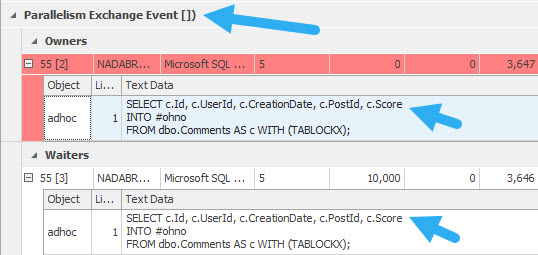
If you have a copy of the StackOverflow2013 database, this query should produce a parallel deadlock.
SELECT c.Id, c.UserId, c.CreationDate, c.PostId, c.Score
INTO #ohno
FROM dbo.Comments AS c WITH (TABLOCKX);
If you want an easy way to track down deadlocks, I can’t recommend sp_BlitzLock enough.
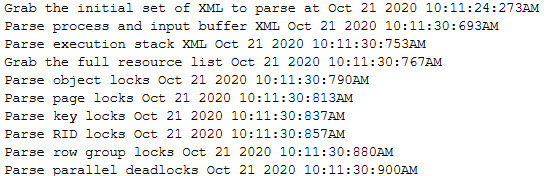
It doesn’t render the deadlock graph for you, but it does get you the deadlock XML, which you can save as an XDL file.
For viewing them, Sentry One’s Plan Explorer tool is way better than SSMS. It doesn’t just explore plans — it also explores deadlocks.
Graphed Out
The way it’ll look is something like this:
ow my face
You’ll see the exchange event, and you’ll also see the same query deadlocking itself.
This is an admittedly odd situation, but one I’ve had to troubleshoot a bunch of times.
You might see query error messages something like this:
Msg 1205, Level 13, State 18, Line 3
Transaction (Process ID 55) was deadlocked on lock | communication buffer resources with another process and has been chosen as the deadlock victim. Rerun the transaction.
Options For Fixing It
If you start running into these, it can be for a number of reasons, but the root cause is a parallel query. That doesn’t mean you should change MAXDOP to 1, though you should check your parallelism settings to make sure they’re not at the defaults.
You may want to try setting the query you’re having a problem with to DOP 1. Sure, performance might suffer, but at least it won’t error out.
If that’s not possible, you might need to look at other things in the query. For example, you might be missing a helpful index that would make the query fast without needing to go parallel.
Another issue you might spot in query plans is around order preserving operators. I wrote a whole bunch about that with an example here. You might see it around operators like Sorts, Merges, and Stream Aggregates when they’re surrounding parallel exchange operators. In those cases, you might need to hint HASH joins or aggregations.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.