Sometimes simple changes to a query can lead to dramatic changes in performance. I often find it helpful to dig into the details as much as I can whenever this happens.
Test Data
All that’s needed is a table with a clustered key defined on both columns. The first column will always have a value of 1 and the second column will increment for each row. We need two identical tables and may change the number of rows inserted into both of them for some tests. Below is SQL to follow along at home:
DROP TABLE IF EXISTS dbo.outer_tbl; DROP TABLE IF EXISTS dbo.inner_tbl; CREATE TABLE dbo.outer_tbl ( ID1 BIGINT NOT NULL, ID2 BIGINT NOT NULL, PRIMARY KEY (ID1, ID2) ); CREATE TABLE dbo.inner_tbl ( ID1 BIGINT NOT NULL, ID2 BIGINT NOT NULL, PRIMARY KEY (ID1, ID2) ); INSERT INTO dbo.outer_tbl WITH (TABLOCK) SELECT TOP (20000) 1 , ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM master..spt_values t1 CROSS JOIN master..spt_values t2; INSERT INTO dbo.inner_tbl WITH (TABLOCK) SELECT TOP (20000) 1 , ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM master..spt_values t1 CROSS JOIN master..spt_values t2; UPDATE STATISTICS dbo.outer_tbl WITH FULLSCAN; UPDATE STATISTICS dbo.inner_tbl WITH FULLSCAN;
The Query
The following query will return one row from outer_tbl if there is at least one row in inner_tbl with a matching value for ID1 and ID2. For our initial data this query will return all 20000 rows. The query optimizer unsurprisingly picks a merge join and the query finishes with just 15 ms of CPU time:
SELECT * FROM dbo.outer_tbl o WHERE EXISTS ( SELECT 1 FROM dbo.inner_tbl i WHERE o.ID1 = i.ID1 AND o.ID2 = i.ID2 );
Query plan:
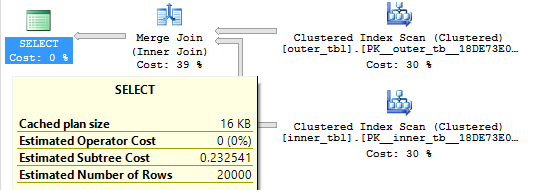
Now let’s make a small change:
SELECT * FROM dbo.outer_tbl o WHERE EXISTS ( SELECT 1 FROM dbo.inner_tbl i WHERE o.ID1 = i.ID1 AND o.ID2 IN (-1, i.ID2) );
Query plan:
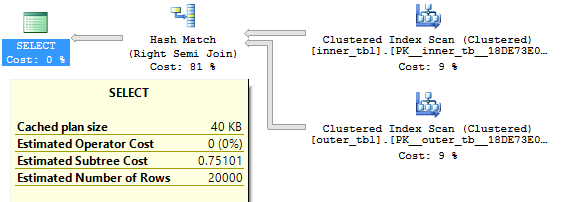
Now the query will return one row from outer_tbl if ID1 = -1 and there is at least one row in inner_tbl with a matching value for ID1 or if there is at least one row in inner_tbl with a matching value for ID1 and ID2. The query optimizer gives me a hash join and the query finishes with 11360 ms of CPU time. If I force a loop join the query finishes with 10750 ms of CPU time. If I force a merge join the query finishes with 112062 ms of CPU time. What happened?
The Problem
The problem becomes easier to see if we change both of the tables to have just one column. We know that ID1 always equals 1 for both tables so we don’t need it in the query for this data set. Here’s the new set of tables:
DROP TABLE IF EXISTS dbo.outer_tbl_single; DROP TABLE IF EXISTS dbo.inner_tbl_single; CREATE TABLE dbo.outer_tbl_single ( ID2 BIGINT NOT NULL, PRIMARY KEY (ID2) ); CREATE TABLE dbo.inner_tbl_single ( ID2 BIGINT NOT NULL, PRIMARY KEY (ID2) ); INSERT INTO dbo.outer_tbl_single WITH (TABLOCK) SELECT TOP (20000) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM master..spt_values t1 CROSS JOIN master..spt_values t2; INSERT INTO dbo.inner_tbl_single WITH (TABLOCK) SELECT TOP (20000) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM master..spt_values t1 CROSS JOIN master..spt_values t2; UPDATE STATISTICS dbo.outer_tbl_single WITH FULLSCAN; UPDATE STATISTICS dbo.inner_tbl_single WITH FULLSCAN;
If I try to force a hash join:
SELECT * FROM dbo.outer_tbl_single o WHERE EXISTS ( SELECT 1 FROM dbo.inner_tbl_single i WHERE o.ID2 IN (-1, i.ID2) ) OPTION (MAXDOP 1, HASH JOIN);
I get an error:
Msg 8622, Level 16, State 1, Line 27
Query processor could not produce a query plan because of the hints defined in this query. Resubmit the query without specifying any hints and without using SET FORCEPLAN.
That makes sense. Hash join requires an equality condition and there isn’t one. Attempting to force a merge join throws the same error. A loop join is valid but there’s a scan on the inner side of the loop:
SELECT * FROM dbo.outer_tbl_single o WHERE EXISTS ( SELECT 1 FROM dbo.inner_tbl_single i WHERE o.ID2 IN (-1, i.ID2) ) OPTION (MAXDOP 1, NO_PERFORMANCE_SPOOL);
Query plan:
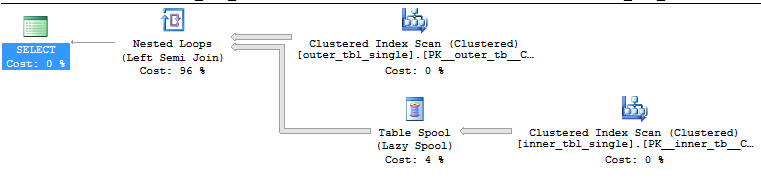
Note that we don’t need to read the 400 million (20000 * 20000) rows from the inner table. This is a semi join so the loop stops as soon as it finds a matching row. On average we should read (1 + 20000) / 2 rows from the inner table before finding a match so the query should need to read 20000 * (1 + 20000) / 2 = 200010000 rows from the inner table. This is indeed what happens:
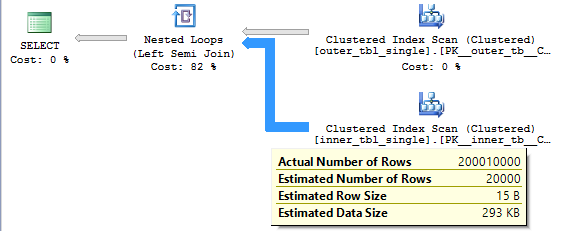
Hash Join Performance
Let’s go back to the initial slow query with two columns. Why is the query eligible for a hash join? Looking at the details of the hash join we can see that the hash probe is only on the ID1 column:
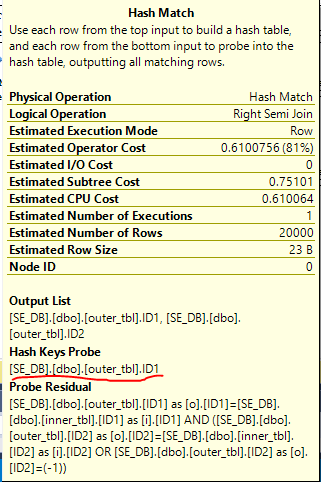
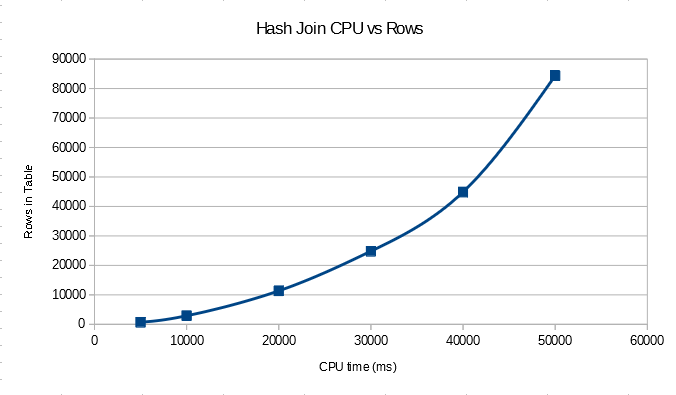
With this data set we end up with the worst possible case for a hash join. All of the rows from the build will hash to the same value and no rows from the probe will be eliminated. It’s still a semi join, so while we don’t know what the order of the hash table is we can still expect to need to (1 + 20000) / 2 entries of the hash table on average before finding the first match. This means that we’ll need to check 200010000 entries in the hash table just for this query. Since all of the work is happening in the hash join we should also expect quadratic performance for this query compared to the number of the rows in the table. If we change the number of rows in the table we see the quadratic relationship:
For the table scans in the query we’re likely to do allocation order scans so the data may not be fed into the hash join in index order. However I just created the tables and data is returned in order in other queries, so I’m going to assume that data is fed into the join in order in this case. You may voice your objections to this assumption in the comments. Of course, the final output of the join may not be in order. We can monitor the progress of the query in a lightweight way using sys.dm_exec_query_profiles with trace flag 7412 enabled. I tested with 40k rows in each table to get a longer running join. The number of rows processed every quarter second was not constant:
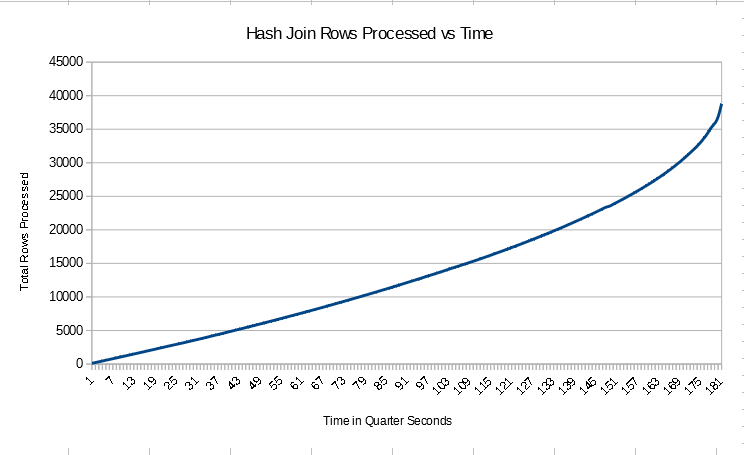
In fact, the query seemed to speed up as time went on. This was unexpected. Perhaps the hash table is built in such a way that the earliest rows for a hash value are at the end of the linked list and the last values processed are at the start? That would explain why the beginning of the query had the lowest number of rows processed per second and the number of rows processed per second increased over time. This is complete speculation on my part and is very likely to be wrong.
The costing for the hash join with the new CE is disappointing. All of the information is available in the statistics to suggest that we’ll get the worst case for the hash join but the total query cost is only 0.75 optimizer units. The legacy CE does better with a total query cost of 100.75 optimizer units but the hash join is still selected.
Merge Join Performance
For merge join the data is only sorted by ID1 for the join:
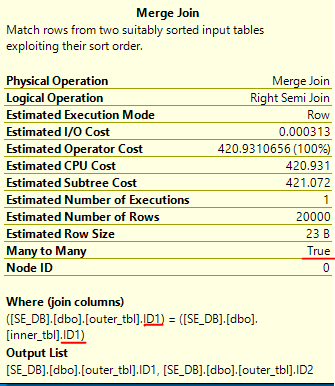
The other part of the join involving the ID2 column is processed as a residual. This is also a many-to-many join. Craig Freedman has a good explanation of how many-to-many joins can lead to a lot of extra work in the join operator:
Merge join can also support many-to-many merge joins. In this case, we must keep a copy of each row from input 2 whenever we join two rows. This way, if we later find that we have a duplicate row from input 1, we can play back the saved rows. On the other hand, if we find that the next row from input 1 is not a duplicate, we can discard the saved rows. We save these rows in a worktable in tempdb. The amount of disk space we need depends on the number of duplicates in input 2.
We have the maximum number of duplicates per possible. It seems reasonable to expect very bad performance along with lots of tempdb activity. Since we’re reading the data in order we might expect to see the maximum rate of rows processed per second to be at the beginning and for the query to slow down as time goes on. As ID2 increases we need to read through more and more previous rows in tempdb. My intuition does not match reality at all in this case. There’s some silly bug with sys.dm_exec_query_profiles that needs to be worked around (merge join always reports 0 rows returned), but the rows processed per second was linear:
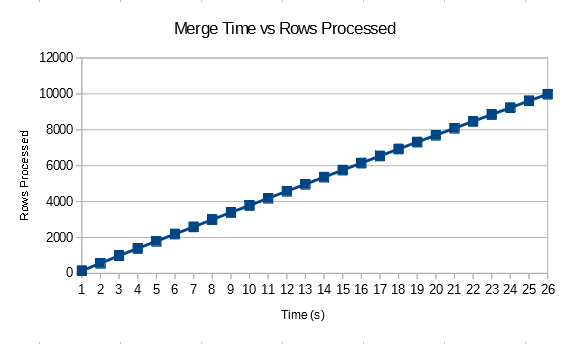
The logical reads for the join is also linear and stabilizes to 49 reads per row returned with 10k rows in the base table.
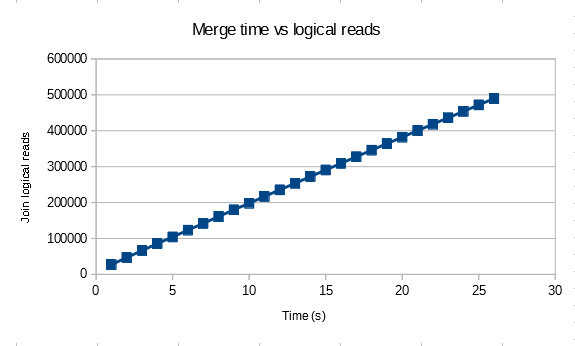
The number of logical reads per row returned stabilizes to 95 when there are 20k rows in the base table. This doesn’t appear to be a coincidence. Perhaps the data stored in tempdb is stored in a format that does not preserve the original ordering. We can look at the merge_actual_read_row_count column from the DMV for the merge join to see that the number of rows read per row processed from the inner table approaches the number of rows in the table. The ramp up happens very quickly. The measurements aren’t very precise, but for the 20k row test I saw that the merge join had processed 380000 rows after just reading 20 rows from the inner table. That would explain why the logical reads and runtime of the merge join grows quadratically with the number of rows in the table but the number of rows processed per second appears to be constant for a given table size.
For the merge join the query optimizer appears to be aware of the problem. Many-to-many joins seem to have quite a bit of a penalty from a costing perspective. With the new CE we get a total query cost of 421.072 optimizer units. The legacy CE gives a very similar cost.
Loop Join Performance
For the loop join we need to pay attention the clustered index seek in the inner part of the join:

The -1 predicate causes trouble here as well. A filter condition will only be used as a seek predicate if it can be safely applied to every row. With the -1 check we don’t have anything to seek against for the inner table, so we only seek against ID1. As before, we should expect to read 200010000 rows from the seek. Our expectations are met:
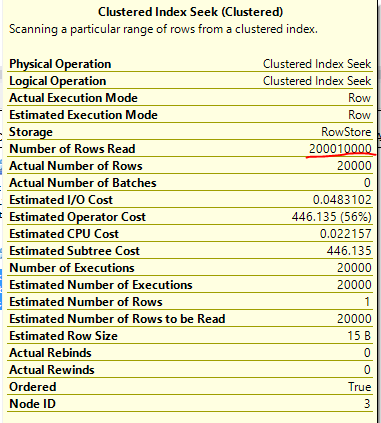
This is the first join which exposes the problem in a direct way in the XML for the actual plan which is nice. However, the performance will be quadratic with the number of rows in the table as with hash join and merge join. This is the first query that we have a shot at fixing. All that we need to do is to write the join in such a way that a seek can always be performed against the ID2 column in the inner table. The fact that the column cannot be NULL makes this possible. Consider the following query:
SELECT * FROM dbo.outer_tbl o WHERE EXISTS ( SELECT 1 FROM dbo.inner_tbl i WHERE o.ID1 = i.ID1 AND i.ID2 BETWEEN ( CASE WHEN o.ID2 = -1 THEN -9223372036854775808 ELSE o.ID2 END ) AND CASE WHEN o.ID2 = -1 THEN 9223372036854775807 ELSE o.ID2 END ) ) OPTION (MAXDOP 1, LOOP JOIN);
Note that I’m only using BETWEEN to work around a wordpress bug.
When o.ID2 = -1 the code simplifies to the following:
WHERE o.ID1 = i.ID1 AND i.ID2 BETWEEN -9223372036854775808 AND 9223372036854775807
When o.ID2 <> -1 the code simplifies to the following:
WHERE o.ID1 = i.ID1 AND i.ID2 BETWEEN o.ID2 AND o.ID2
In other words, can we use the bounds of the BIGINT to create a seek on ID2 that can always be done:
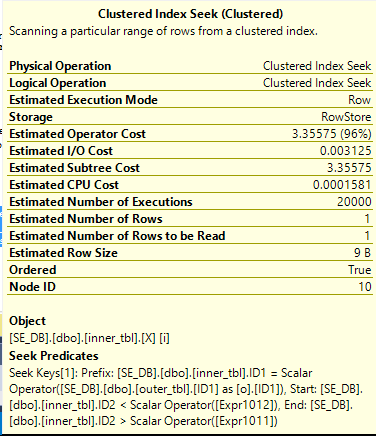
The improved query returns the results with just 47 ms of CPU time. Only 20000 rows are read from the index seek which is the best possible result for our data set. The estimated cost of the query is dramatically reduced to 3.51182 for the new CE, but that isn’t enough for it to be naturally chosen over the much less efficient hash join. That is unfortunate. As you might have guessed the LOOP JOIN hint is not necessary when using the legacy CE.
Manual Rewrites
We can avoid the problem all together by changing the join condition to allow joins to work in a much more natural way. Splitting it up with a UNION finishes very quickly with our sample data set:
SELECT * FROM dbo.outer_tbl o WHERE EXISTS ( SELECT 1 FROM dbo.inner_tbl i WHERE o.ID1 = i.ID1 AND o.ID2 = i.ID2 ) UNION SELECT * FROM dbo.outer_tbl o WHERE o.ID2 = -1 AND EXISTS ( SELECT 1 FROM dbo.inner_tbl i WHERE o.ID1 = i.ID1 );
Query plan:
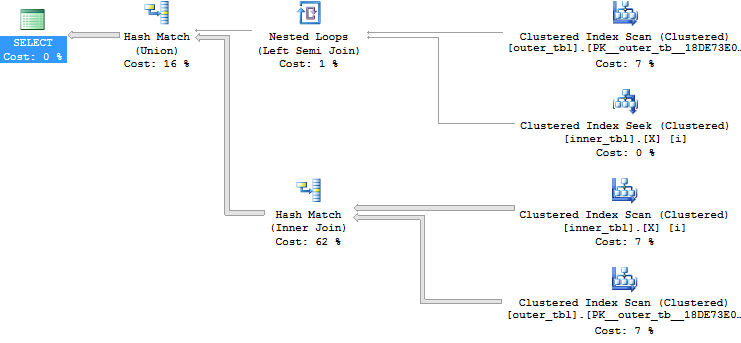
Splitting it into two semijoins does fine as well, although the hash match (aggregate) at the end is a bit more expensive for this data set than the hash match (union) employed by the other query:
SELECT * FROM dbo.outer_tbl o WHERE EXISTS ( SELECT 1 FROM dbo.inner_tbl i WHERE o.ID1 = i.ID1 AND o.ID2 = -1 ) OR EXISTS ( SELECT 1 FROM dbo.inner_tbl i WHERE o.ID1 = i.ID1 AND o.ID2 = i.ID2 );
Query plan:
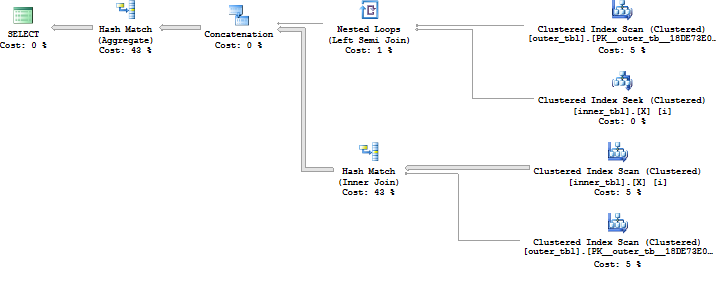
Fully optimizing the above query is an interesting exercise but Paul White already covered the problem quite well here.
Final Thoughts
At first glance the following query is a little suspicious but the worst case performance scenario wasn’t immediately obvious (at least to me):
SELECT * FROM dbo.outer_tbl o WHERE EXISTS ( SELECT 1 FROM dbo.inner_tbl i WHERE o.ID1 = i.ID1 AND o.ID2 IN (-1, i.ID2) );
In fact, it will even perform well for some data sets. However, as the number of duplicate rows for a single ID grows we can end up with a triangular join. I found it interesting that all three join types scaled in the same way. Thanks for reading!