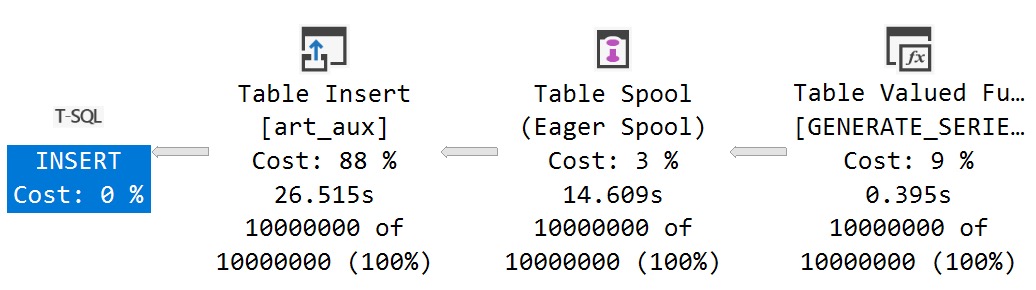
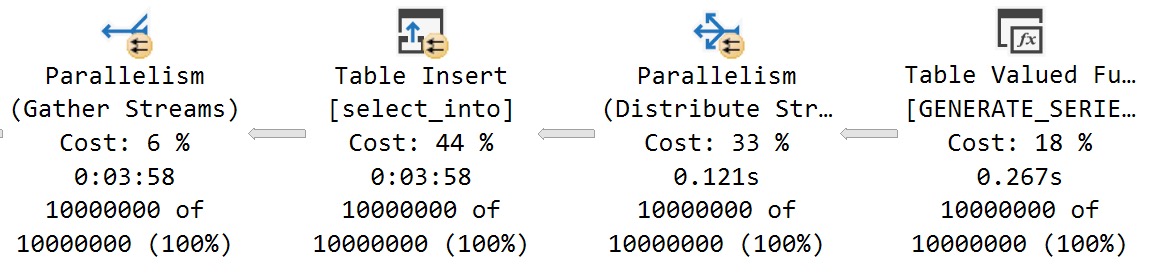
IndexOf
First, I want to advise you to avoid doing things as much as possible like this in T-SQL. Use CLR, if you can. Or do it outside of your really expensive database server.
You know, rational choices.
Recently, I had an interesting client problem where they had a variety of string formats, and different potential start and end points to get a substring from.
Normally, I love computed columns for this, but there was no way to get exactly what they wanted without using a whole bunch of them. It was sort of annoying.
Because it was easier to get across in T-SQL, we ended up using a trigger.
Don’t look at me like that.
CharindexOf
First, let’s load up a small temp table with some different string values.
CREATE TABLE
#strings
(
string varchar(4)
);
INSERT
#strings
(
string
)
SELECT '1234'
UNION ALL
SELECT '2341'
UNION ALL
SELECT '3412'
UNION ALL
SELECT '4123';
Now, let’s say that there was a need to figure out which number came first in the string. You can use the CHARINDEX function to do that, but it’s a little difficult to make it “dynamic”.
To make things easy, let’s create a helper table of search patterns.
CREATE TABLE
#searches
(
search varchar(1)
);
INSERT
#searches
(
search
)
SELECT '1'
UNION ALL
SELECT '2'
UNION ALL
SELECT '3'
UNION ALL
SELECT '4';
ApplyOf
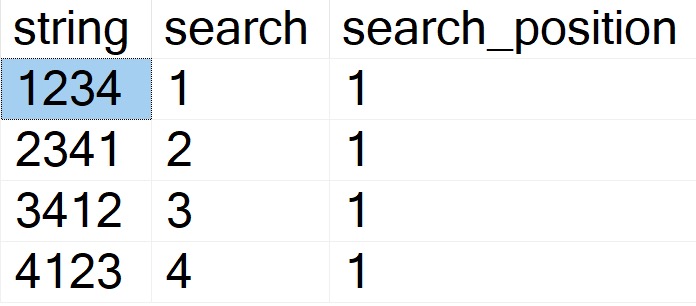
Now we can use a little bit of apply and derived table magic to figure out which of our search values appear first in our strings.
SELECT
s.string,
x1.search,
x1.search_position
FROM #strings AS s
CROSS APPLY
(
SELECT TOP (1)
x0.search,
x0.search_position
FROM
(
SELECT
s2.search,
search_position =
CHARINDEX(s2.search, s.string)
FROM #searches AS s2
) AS x0
ORDER BY x0.search_position
) AS x1;
The results look like this:
SubstringOf
Now we can add in the LEN and SUBSTRING functions in order to parse out the part of the column we’re interested in.
SELECT
s.string,
x1.search,
x1.search_position,
x1.search_length,
sub =
SUBSTRING
(
x1.search,
x1.search_position,
x1.search_length
)
FROM #strings AS s
CROSS APPLY
(
SELECT TOP (1)
x0.search,
x0.search_position,
x0.search_length
FROM
(
SELECT
s2.search,
search_position =
CHARINDEX(s2.search, s.string),
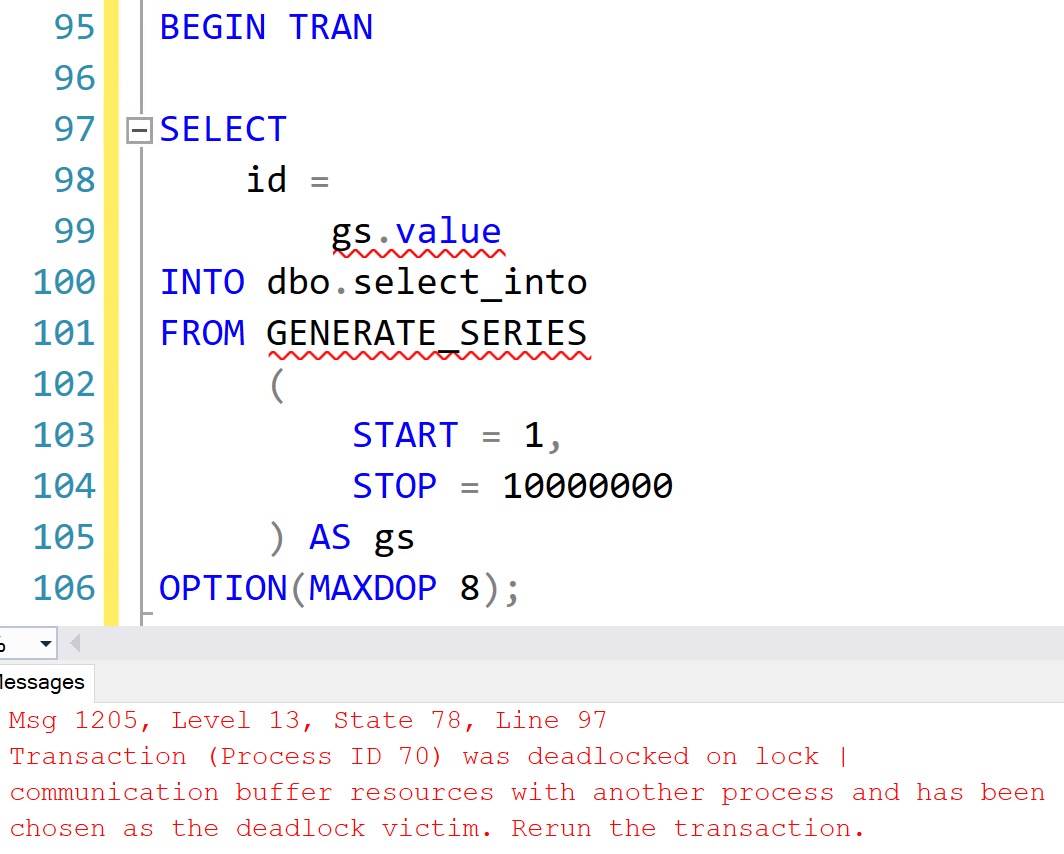
search_length =
LEN(s2.search)
FROM #searches AS s2
) AS x0
ORDER BY x0.search_position
) AS x1;
Now the results look like this:

This is an admittedly pretty rudimentary example, but it’s tough to make this complicated without making it overly so.
From here, you can use a second APPLY with CHARINDEX ordered descending to find an end position, and use more advanced SUBSTRING techniques to locate the text between two positions.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.