I have sort of a love/hate relationship with wait stats scripts and analysis. Sometimes they’re great to correlate with larger performance problems or trends, and other times they’re totally useless.
When you’re looking at wait stats, some important things to figure out are:
How much of a wait happened compared to uptime
If the waits lasted a long time on average
And you can do that out of the box with SQL Server. What you can’t get are two very important things:
When the waits happened
Which queries caused the waits
This stuff is vitally important for figuring out if wait stats are benign overall to the workload.
For example, let’s say your server has been up for 100 hours, and you spent 50 hours waiting on PAGEIOLATCH_SH waits. Normally I’d be pretty worried about that, and I’d be looking at if the server has enough memory, if queries are asking for big memory grants, if important queries are missing any indexes, etc.
But if we knew that all 50 of those hours were outside of normal use activity, and maybe even happened in a separate database for warehousing or archiving off data, we might be able to ignore it and focus on other portions of the workload.
When this finishes running, you’ll get three results back:
Overall wait stats for the period of time
Wait stats broken down by database for the period of time
Wait stats broken down by database and query for the period of time
And because I don’t want to leave you hanging, you’ll also get details about the waits themselves, like
How much of a wait happened compared to sampled time
How long the waits lasted on average in the sampled time
If you need to figure out which queries are causing wait stats that you’re worried about, this is a great way to get started with that investigation.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Like query compilations, query recompilations can be annoying. The bigger difference is that even occasional recompiles can introduce a bad query plan.
If your monitoring tools or scripts are warning you about high compiles or recompiles, sp_HumanEvents can help you dig in further.
We talked about compilations yesterday (and, heck, maybe I should have added that point in there, but hey), so today we’ll talk about recompilations.
There are a lot of reasons why a query might recompile:
Schema changed
Statistics changed
Deferred compile
Set option change
Temp table changed
Remote rowset changed
For browse permissions changed
Query notification environment changed
PartitionView changed
Cursor options changed
Option (recompile) requested
Parameterized plan flushed
Test plan linearization
Plan affecting database version changed
Query Store plan forcing policy changed
Query Store plan forcing failed
Query Store missing the plan
Interleaved execution required recompilation
Not a recompile
Multi-plan statement required compilation of alternative query plan
Query Store hints changed
Query Store hints application failed
Query Store recompiling to capture cursor query
Recompiling to clean up the multiplan dispatcher plan
That list is from SQL Server 2022, so there are going to be some listed here that you might not see just yet.
But let’s face it, the reasons you’re gonna see most often is probably
Schema changed
Statistics changed
Temp table changed
Option (recompile) requested
Mad Dog
To capture which queries are recompiling in a certain window, I’ll usually do something like this:
Schema changed: use a new index that suits the query better
Statistics changed: use newer statistics that more accurately reflect column data
Temp table changed: use a new histogram for a temp table more relevant to the query
Option (recompile) requested: burn it flat, salt the earth
But of course, there’s always an element of danger, danger when a query starts using a new plan. What if it sucks?
To cut down on recompiles, you can use this stuff:
Plan Guides
Query Store forced plans
Keep Plan/KeepFixed Plan query hints
Stop using recompile hints?
One thing that can be a pretty big bummer about recompiles is that, if you’re relying solely on the plan cache to find problem queries, they can leave you with very little (or zero) evidence about what queries are getting up to.
Query Store and some monitoring tools will capture them, so you’re better off using those for more in-depth analysis.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
One thing that I have to recommend to clients on a fairly regular basis is to enable Forced Parameterization. Many vendor applications send over queries that aren’t parameterized, or without strongly typed parameters, and that can make things… awkward.
Every time SQL Server gets one of those queries, it’ll come up with a “new” execution plan, cache it, and blah blah blah. That’s usually not ideal for a lot of reasons.
There are potentially less tedious ways to figure out which queries are causing problems, by looking in the plan cache or query store.
One way to start getting a feel for which queries are compiling the most, along with some other details about compilation metrics and parameterization is to do this:
Newer versions of SQL Server have an event called query_parameterization_data.
Fired on compile for every query relevant for determining if forced parameterization would be useful for this database.
If you start monitoring compilations with sp_HumanEvents you’ll get details from this event back as well, as long as it’s available in your version of SQL Server.
You can find all sorts of tricky application problems with this event setup.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
In yesterday’s post, I talked through how I capture blocking using sp_HumanEvents. Today I’m going to talk about a couple different ways I use it to capture query performance issues.
One thing I want to stress is that you shouldn’t use yesterday’s technique to gather query performance issues. One thing sp_HumanEvents does is capture actual execution plans, and that can really bog a server down if it’s busy.
I tend to use it for short periods of time, or for very targeted data collection against a single stored procedure or session id running things.
I’ve occasionally toyed with the idea of adding a flag to not get query plans, or to use a different event to get them.
I just don’t think there’s enough value in that to be worthwhile since the actual execution plan has so many important details that other copies do not.
So anyway, let’s do a thing.
Whole Hog
You can totally use sp_HumanEvents to grab absolutely everything going on like this:
You may need to do this in some cases when you’re first getting to know a server and need to get a feeling for what’s going on. This will show you any query that takes 5 seconds or longer in the 20 second window the session is alive for.
If you’re on a really busy server, it can help to cut down on how much you’re pulling in:
This will only pull in data from sessions if their spid is divisible by 5. The busier your server is, the weirder you might want to make this number, like 15/17/19 or something.
Belly
Much more common for me is to be on a development server, and want to watch my spid as I execute some code:
This is especially useful if you’re running a big long stored procedure that calls a bunch of other stored procedures, and you want to find all the statements that take a long time without grabbing every single query plan.
If you’ve ever turned on Actual Execution Plans and tried to do this, you might still be waiting for SSMS to become responsive again. It’s really painful.
By only grabbing query details for things that run a long time, you cut out all the little noisy queries that you can’t really tune.
I absolutely adore this, because it lets me focus in on just the parts that take a long time.
Shoulder
One pretty common scenario is for clients to give me a list of stored procedures to fix. If they don’t have a monitoring tool, it can be a challenge to understand things like:
How users call the stored procedure normally
If the problem is parameter sniffing
Which queries in the stored procedure cause the biggest problems
This will only collect sessions executing a single procedure. I’ll sometimes do this and work through the list.
Hoof
There are some slight differences in how I call the procedure in different circumstances.
When I use the @seconds_sample parameter, sp_HumanEvents will run for that amount of time and then spit out a result
When I use the @keep_alive parameter, all that happens is a session gets created and you need to go watch live data like this:
viewme
Just make sure you do that before you start running your query, or you might miss something important.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Unlike most people who left links in the comments, I read the entire post and decided to use the whole darn month to write about scripts I maintain and how I use them in my work.
Lest I be accused of not being able to read a calendar, I know that these are dropping a little earlier than the 1st of September. I do apologize for September not starting on a Monday.
There are other great tools and utilities out there, like Andy Mallon’s DBA Utility Database, but I don’t use them enough personally to be able to write about them fluently.
My goal here is to help you use each script with more confidence and understanding. Or even any confidence and understanding, if none existed beforehand.
Oral Board
First up is (well, I think) my most ambitious script: sp_HumanEvents. If you’re wondering why I think it’s so ambitious, it’s because the goal is to make Extended Events usable by Humans.
At present, that’s around 4000 lines of T-SQL. Now, sp_HumanEvents can do a lot of stuff, including logging event data to tables for a bunch of different potential performance issues.
When I was first writing this thing, I wanted it to be able to capture data in a few different ways to fit different monitoring scenarios. In this post, I’m going to show you how I most often use it on systems that have are currently experiencing blocking.
First, you need to have the Blocked Process Report enabled, which is under advanced options:
If you want to flip the advanced options setting back, you can. I usually leave it set to 1.
The second command turns on the blocked process report, and tells SQL Server to log any instances of blocking going on for 5 or more seconds. You can adjust that to meet your concerns with blocking duration, but I wouldn’t set it too low because there will be overhead, like with any type of monitoring.
Blockeroos
The way I usually set up to look at blocking that’s currently happening on a system — which is what I most often have to do — is to set up a semi-permanent session and watch what data comes in.
When I want to parse that data, I use sp_HumanEventsBlockViewer to do that. At first, I just want to see what kind of stuff starts coming in.
What this will do is set up an Extended Event session to capture blocking from the Blocked Process Report. That’s it.
From there, you can either use my script (linked above), or watch data coming in via the GUI. Usually I watch the GUI until there’s some stuff in there to gawk at:
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
From query plans, you can get the plan handle and plan hash:
WITH XMLNAMESPACES(DEFAULT 'http://schemas.microsoft.com/sqlserver/2004/07/showplan')
SELECT
session_id,
query_plan,
additional_info,
query_hash =
q.n.value('@QueryHash', 'varchar(18)'),
query_plan_hash =
q.n.value('@QueryPlanHash', 'varchar(18)')
FROM dbo.WhoIsActive AS w
CROSS APPLY w.query_plan.nodes('//StmtSimple') AS q(n);
From additional info, you can get the SQL Handle and Plan Handle:
SELECT
session_id,
query_plan,
additional_info,
sql_handle =
w.additional_info.value('(//additional_info/sql_handle)[1]', 'varchar(131)'),
plan_handle =
w.additional_info.value('(//additional_info/plan_handle)[1]', 'varchar(131)')
FROM dbo.WhoIsActive AS w;
Causation
For the plan cache, you can use your favorite script. Mine is, of course, sp_BlitzCache.
You you can use the @OnlyQueryHashes or @OnlySqlHandles parameters to filter down to queries you’re interested in.
For Query Store, you can use my script sp_QuickieStore to do the same thing.
It has parameters for @include_query_hashes, @include_plan_hashes or @include_sql_handles.
You might want to add some other filtering or sorting to the queries up there to find what you’re interested in, but this should get you started.
I couldn’t find a quick or easy way to combine the two queries, since we’re dealing with two different columns of XML data, and the query plan XML needs a little special treatment to be queried.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Whew. That’s not even all of it. I should get out more.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Execution plans have come a long way over the years, gradually adding more and more details as computing power becomes less of a hurdle to collecting metrics.
The thing is, it’s not always obvious where to look or dig deeper into a query plan to figure out where problems are.
Right now, there are some warnings:
At the root operator for a few different things
For memory consuming operators when they spill
But there are some other things in query plans that should be loud and clear, because they’re not going to be obvious to folks just getting started out reading query plans.
Non-SARGable Predicates:
These can cause a lot of issues:
Unnecessary scans
Poor cardinality estimates
It’s primarily caused by:
function(column) = something
column + column = something
column + value = something
value + column = something
column = @something or @something IS NULL
column like ‘%something’
column = case when …
value = case when column…
Mismatching data types (implicit conversion)
The thing is, it’s hard to see where this stuff happens in a plan, unless the plan is very small, or you’re looking directly at the query text, which is often truncated when pulled from a query plan. It would be nice if we got a warning of some sort on operators where this happened.
Predicates That Result In Scans
If you write a where clause, but don’t have an index with a key that matches that where clause, sometimes you’ll get a missing index request and sometimes you won’t. It’s a bit of a gamble of course.
For large tables, this can be painful, burn a lot of CPU, and result in a parallel plan where you could get by without one if you had a better index in place.
bigscan4u
Of course, not every scan has a predicate: think joins without a where clause, or where only one table has a predicate against it. You don’t have much choice but to scan an index.
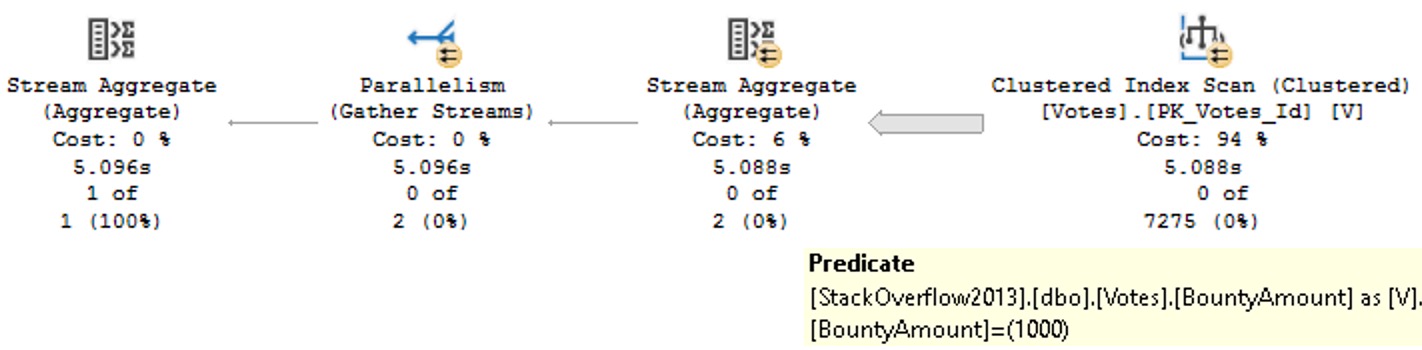
Eager Index Spools
Sometimes SQL Server wants an index so badly that it creates one on its own for you. When this happens on a large enough table, you can spend an awful lot of time waiting for it.
You know like when you put something in the microwave and you’re standing there staring at the timer and even though you set it for two minutes it seems to hang out at 1:30 forever? That’s what an Eager Index Spool is like. A Hungry Man Dinner that you microwave for an hour but still comes out with ice around the edges of your Salisbury Steak.
community
Okay, I stretched that one a bit. But here’s the thing: If SQL Server is gonna spend all that time creating a temporary index for you, it should tell you. Maybe a missing index request, maybe a warning on the spool itself. Just… anything that would help alert more casual execution plan observers to the fact that an index might not be the worst idea, here.
Why Indexes Weren’t Used
I know you. You create indexes all the time, then for some strange reason your queries don’t use them, or stop using them.
When SQL Server optimizes a query, part of the flow chart is a pit stop called index matching. At this point, SQL Server looks at available indexes and then chooses to use or not use them based on various pieces of feedback.
Sometimes it’s obvious why an index wasn’t used, like if it only covers a portion of the query, or if the key columns weren’t in the best order. Other times, it’s really unclear.
It would be nice if we had reasons for that available, even if it’s only in actual plans.
Louder Warnings For Deeper Problems
Right now, SQL Server buries some information that can be really important to why a query didn’t perform well:
When estimated and actual rows or executions are way off
When something forces a query to run serially
When operators execute more than once (including rebinds and rewinds)
When rows are badly skewed across parallel threads
The thing is, like a lot of these other items on this list, it takes real digging to figure out if any of them apply to you, and if they’re why your query slowed down. They just need some basic visual indicators to draw attention to them at the right times.
Different Per-Operator Details
When you look at each individual operator in an actual execution plan, you get sort of a confusing story:
Estimated cost
Wall clock time
Actual rows
Estimated rows
Percent of actual to estimated rows
I’d throw out some of that, and show:
CPU time
Wall clock time
Actual Rows
Actual Executions
Percent of actual to estimated
It would also be nice to have per-operator wait stats at this juncture, since we’d need to know why there’s a discrepancy between CPU and wall clock time, e.g. because of blocking or waiting on some other resource.
While we’re talking about all this, it might be helpful to consider the direction plans show their work. Right to left for data and left to right for logic are… fine. I guess. But up and down might make more sense. A lot of folks I know have a tough time understanding when things happen in horizontal execution plans, where vertical plans would be far more clear.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Note the series of single quotes and + operators (though the same would happen if you used the CONCAT function), and that square brackets alone won’t save you.
The most obvious way is to use a stored procedure.
CREATE OR ALTER PROCEDURE
dbo.Obvious
(
@ParameterOne int
)
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
SELECT
records = COUNT_BIG(*)
FROM dbo.Users AS u
WHERE u.Id = @ParameterOne;
END;
There are millions of upsides to stored procedures, but they can get out of hand quickly.
Also, the longer they get, the harder it can become to troubleshoot individual portions for performance or logical issues.
There are other kinds of functions in SQL Server, but these are far and away the least-full of performance surprises.
CREATE OR ALTER FUNCTION
dbo.TheOnlyGoodKindOfFunction
(
@ParameterOne int
)
RETURNS table
AS
RETURN
SELECT
records = COUNT_BIG(*)
FROM dbo.Users AS u
WHERE u.Id = @ParameterOne;
GO
Both scalar and multi-statement types of functions can cause lots of issues, and should generally be avoided when possible.
DECLARE
@sql nvarchar(MAX) = N'',
@ParameterOne int;
SELECT
@sql += N'
SELECT
records = COUNT_BIG(*)
FROM dbo.Users AS u
WHERE u.Id = @ParameterOne;
';
EXEC sys.sp_executesql
@sql,
N'@ParameterOne int',
@ParameterOne;
This kind of dynamic SQL is just as safe and reusable as stored procedures, but far less flexible. It’s not that you can’t cram a bunch of statements and routines into it, it’s just not advisable to get overly complicated in here.
Note that even though we declared @ParameterOne as a local variable, we pass it to the dynamic SQL block as a parameter, which makes it behave correctly. This is also true if we were to pass it to another stored procedure.
Forced parameterization is a great setting. It’s unfortunate that everything thinks they want to turn on optimize for adhoc workloads, which is a pretty useless setting.
You can turn it on like so:
ALTER DATABASE [YourDatabase] SET PARAMETERIZATION FORCED;
Forced parameterization will take queries with literal values and replace them with parameters to promote plan reuse. It does have some limitations, but it’s usually a quick fix to constant-compiling and plan cache flushing from unparameterized queries.
SQL Server may attempt simple parameterization in some cases, but this is not a guaranteed or reliable way to get the majority of the queries in your workload parameterized.
In general, the brunt of the work falls on you to properly parameterize things. Parameters are lovely things, which can even be output and shared between code blocks. Right now, views don’t accept parameters as part of their definitions, so they won’t help you here.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
I admit that sp_prepare is an odd bird, and thankfully one that isn’t used a ton. I still run into applications that are unfortunate enough to have been written by people who hate bloggers and continue to use it, though, so here goes.
When you use sp_prepare, parameterized queries behave differently from normal: the parameters don’t get histogram cardinality estimates, they get density vector cardinality estimates.
Here’s a quick demo to show you that in action:
CREATE INDEX
p
ON dbo.Posts
(ParentId)
WITH
(
SORT_IN_TEMPDB = ON,
DATA_COMPRESSION = PAGE
);
DECLARE
@handle int =
NULL,
@parameters nvarchar(MAX) =
N'@ParentId int',
@sql nvarchar(MAX) =
N'
SELECT
c = COUNT_BIG(*)
FROM dbo.Posts AS p
WHERE p.ParentId = @ParentId;
';
EXEC sys.sp_prepare
@handle OUTPUT,
@parameters,
@sql;
EXEC sys.sp_execute
@handle,
184618;
EXEC sys.sp_execute
@handle,
0;
EXEC sys.sp_unprepare
@handle;
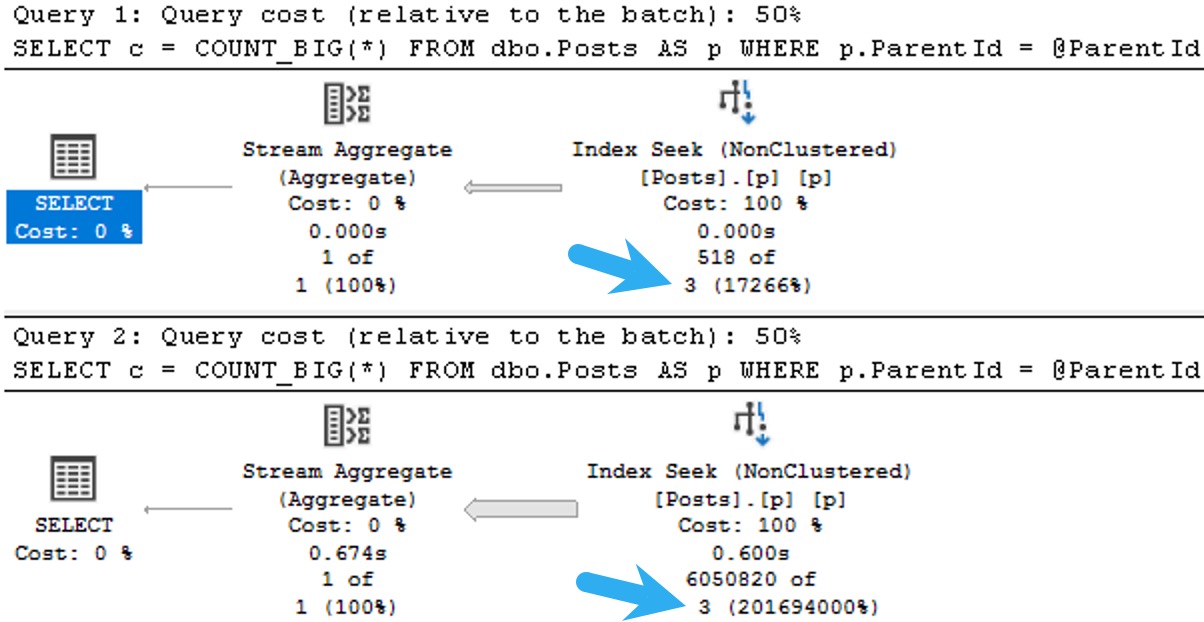
OldPlan
The plans for the two executions have the same poor cardinality estimate. In this case, since we have an ideal index and there’s no real complexity, there’s no performance issue.
But you can probably guess (at least for the second query) how being off by 201,694,000% might cause issues in queries that ask a bit more of the optimizer.
The point here is that both queries get the same incorrect estimate of 3 rows. If you add a recompile hint, or execute the same code using sp_executesql, the first query will get a histogram cardinality estimate, and the second query will reuse it.
one up
Given the historical behavior of sp_prepare, I was a little surprised that the Parameter Sensitive Plan (PSP) optimization available in SQL Server 2022 kicked in.
NewDifferent
If we change the database compatibility level to 160, the plans change a bit.
ALTER DATABASE StackOverflow2013 SET COMPATIBILITY_LEVEL = 160;
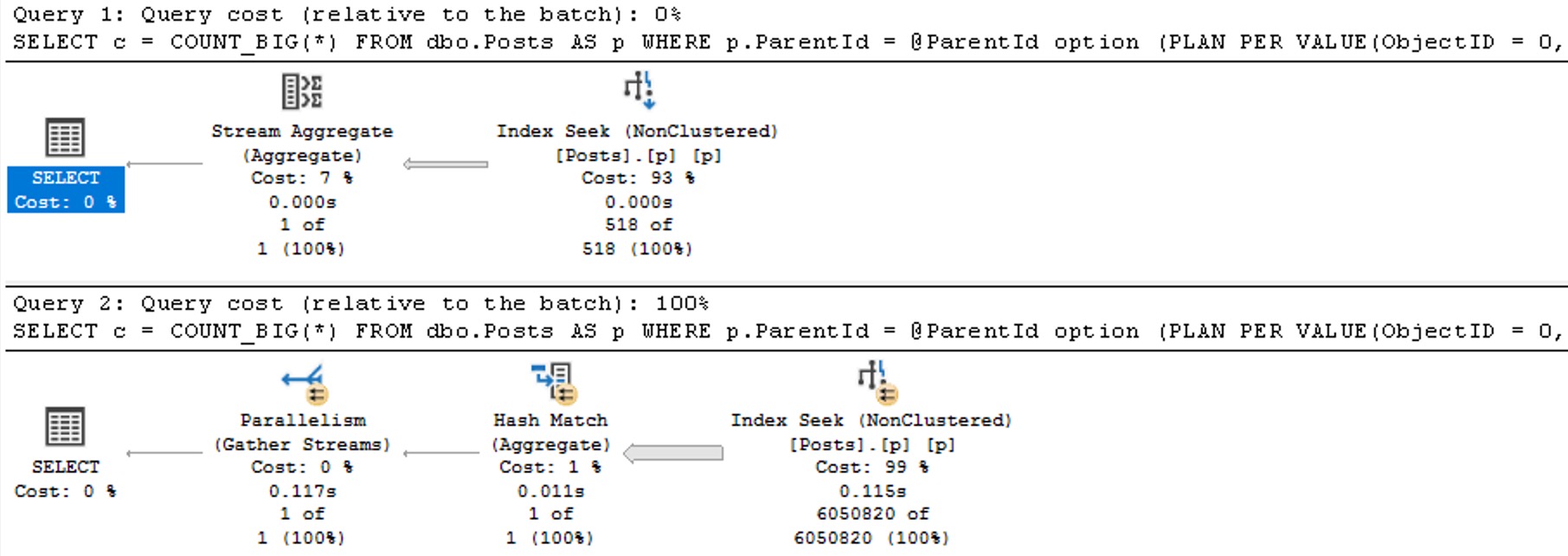
Now we see two different plans without a recompilation, as well as the plan per value option text at the end of the queries, indicating the PSP optimization kicked in.
two up
The differences here are fairly obvious, but…
Each plan gets accurate cardinality
The second plan goes parallel to make processing ~6 million rows faster
Different aggregates more suited to the amount of data in play are chosen (the hash match aggregate is eligible for batch mode)
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.