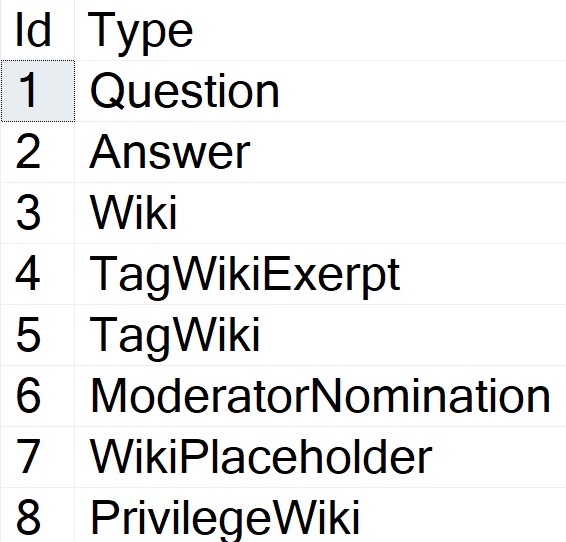
Smack Dab
Aggregates can be useful for all sorts of things in a query plan, and can show up in many different forms.
It would be tough to cover all of them in a single post, but what I’d like to do is help all you nice folks out there understand some of their finer points.
Streaming and Hashing
The two main types of aggregates you’ll see in SQL Server query plans are:
- Stream Aggregate (expect ordered data)
- Hash Aggregate (don’t care about order)
Of course, they break down into more specific types, too.
- Partial aggregates (an early attempt to reduce rows)
- Scalar aggregates (returning a sum or count without a group by, for example)
- Vector aggregates (with a group by)
And if you want to count more analytical/windowing functions, you might also see:
- Segment/Sequence project (row mode windowing functions)
- Window Aggregates (batch mode windowing functions)
To learn more about partial aggregates, check out this post.
Aggregation Ruling The Nation
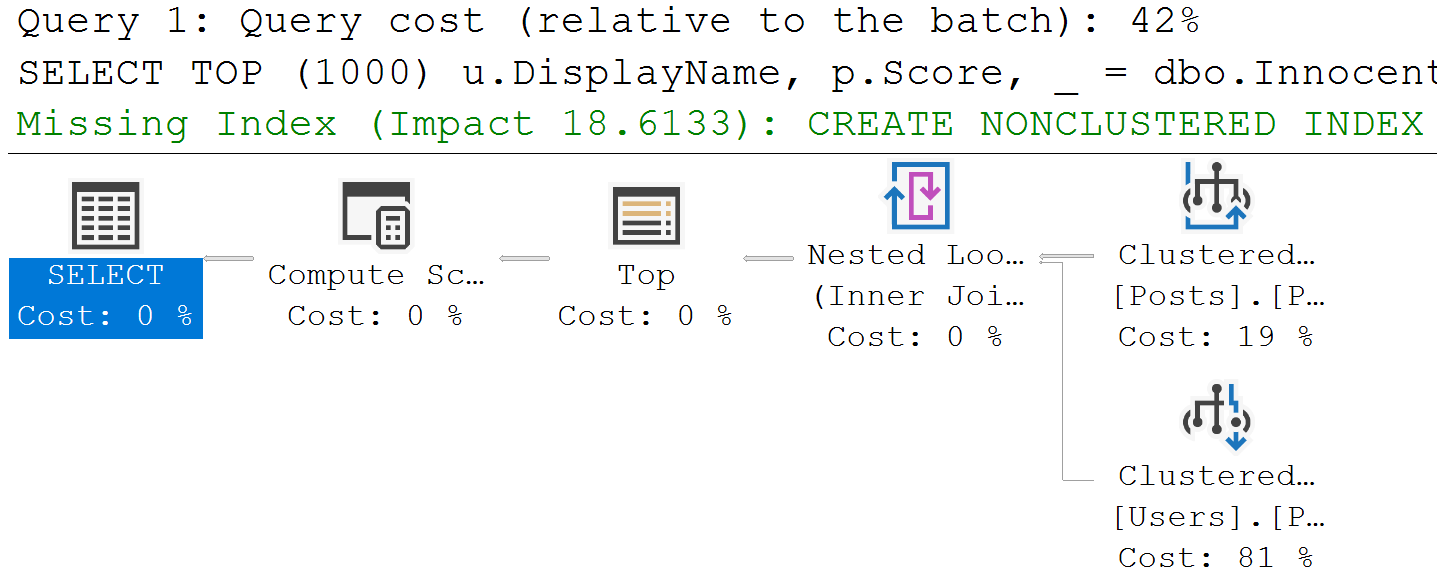
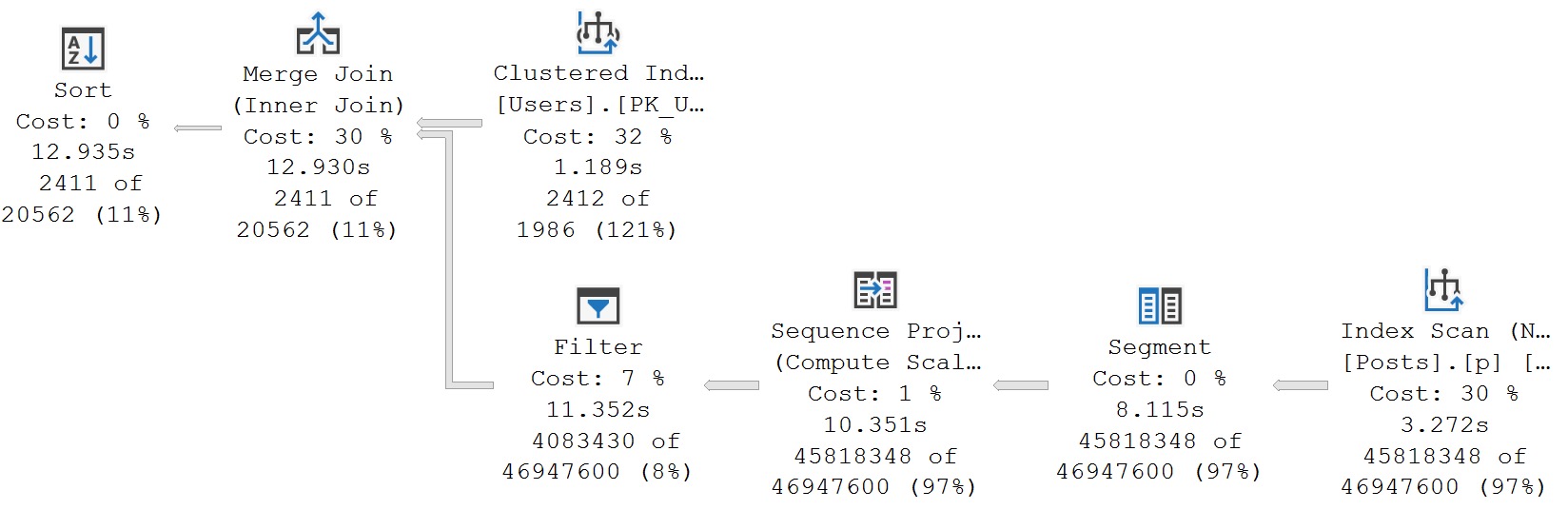
One of the big benefits of aggregates is, of course, making a set of values distinct. This can be particularly help around joins, especially Merge Joins where the many to many type can cause a whole lot of performance issues.
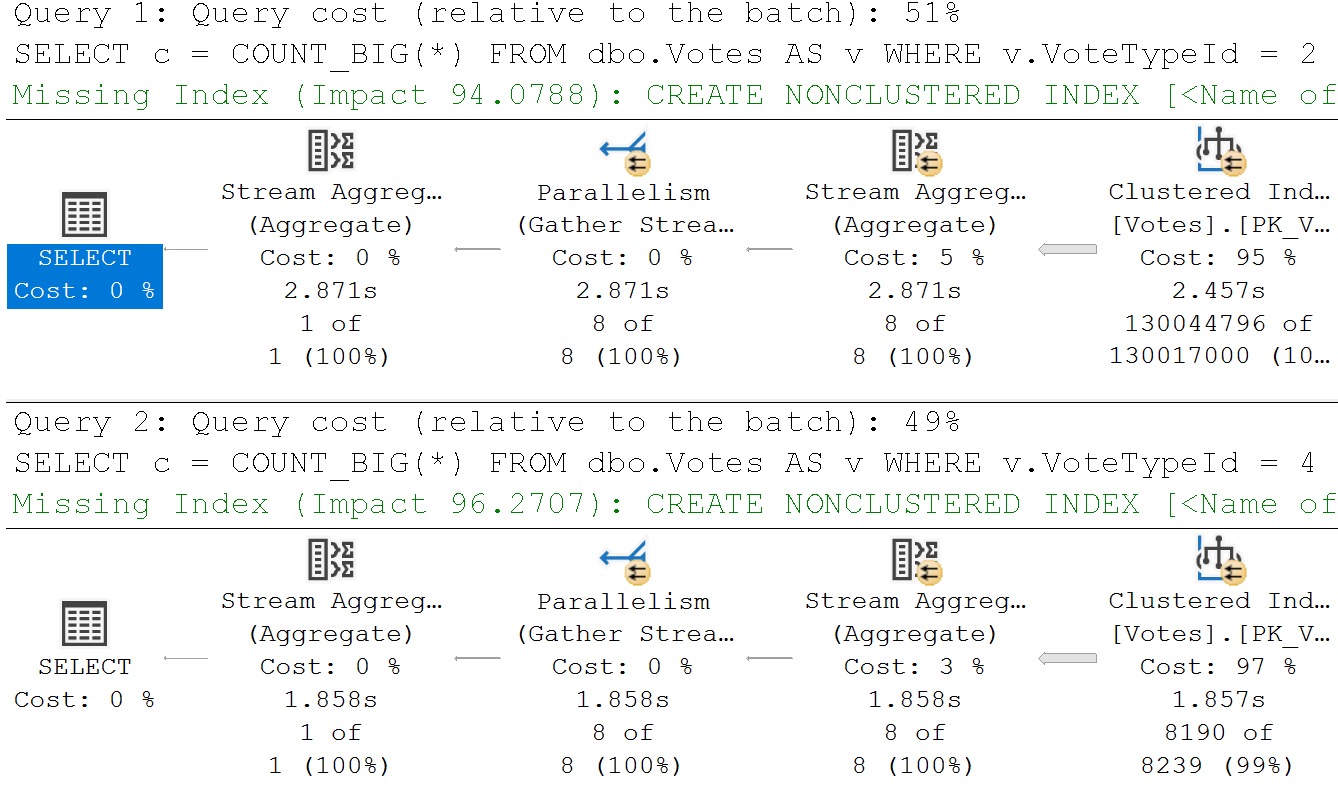
That being said, not every aggregation is productive. For example, some aggregations might happen because the optimizer misjudges the number of distinct values in a set. When this happens, often other misestimates will follow.
Two of the biggest factors for this going awry are:
- Memory grants for sorts and aggregations across the execution plan
- Other operators chosen based on estimated row counts being much lower
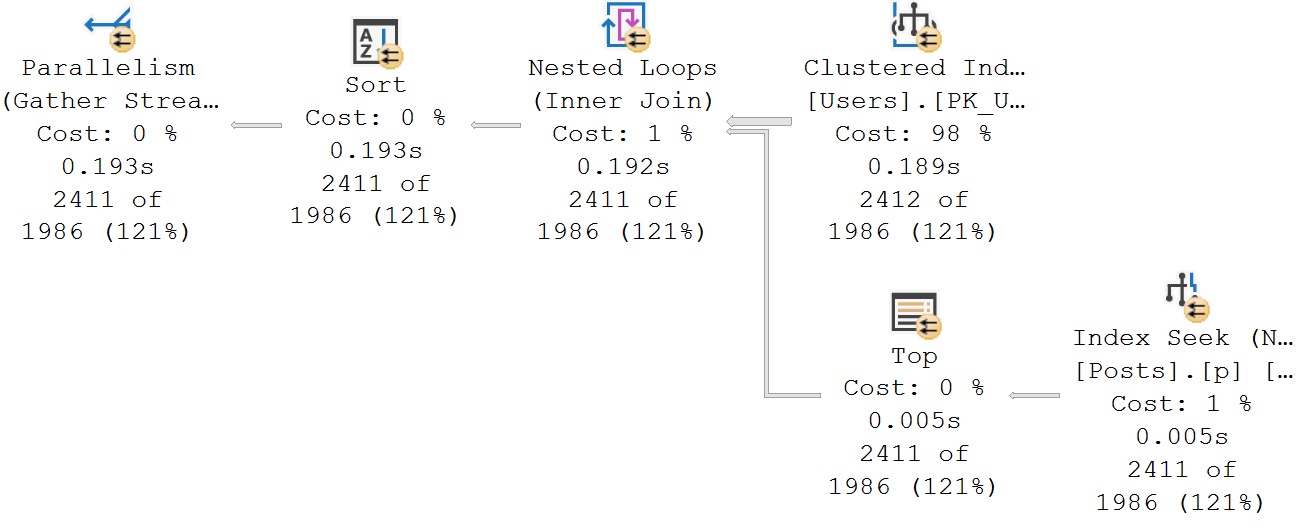
Here are some examples:
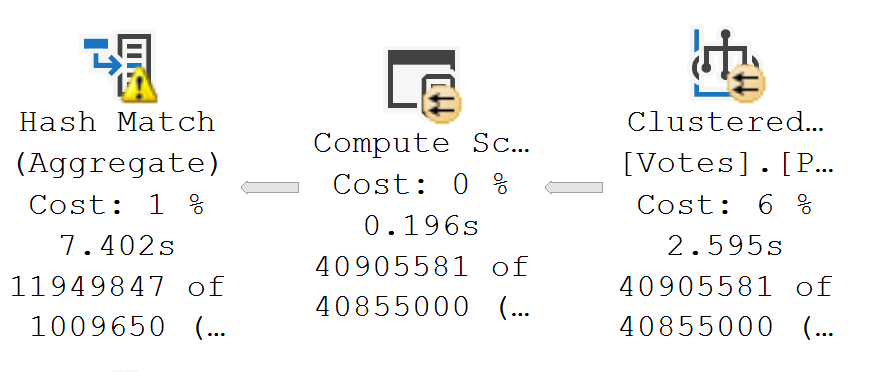
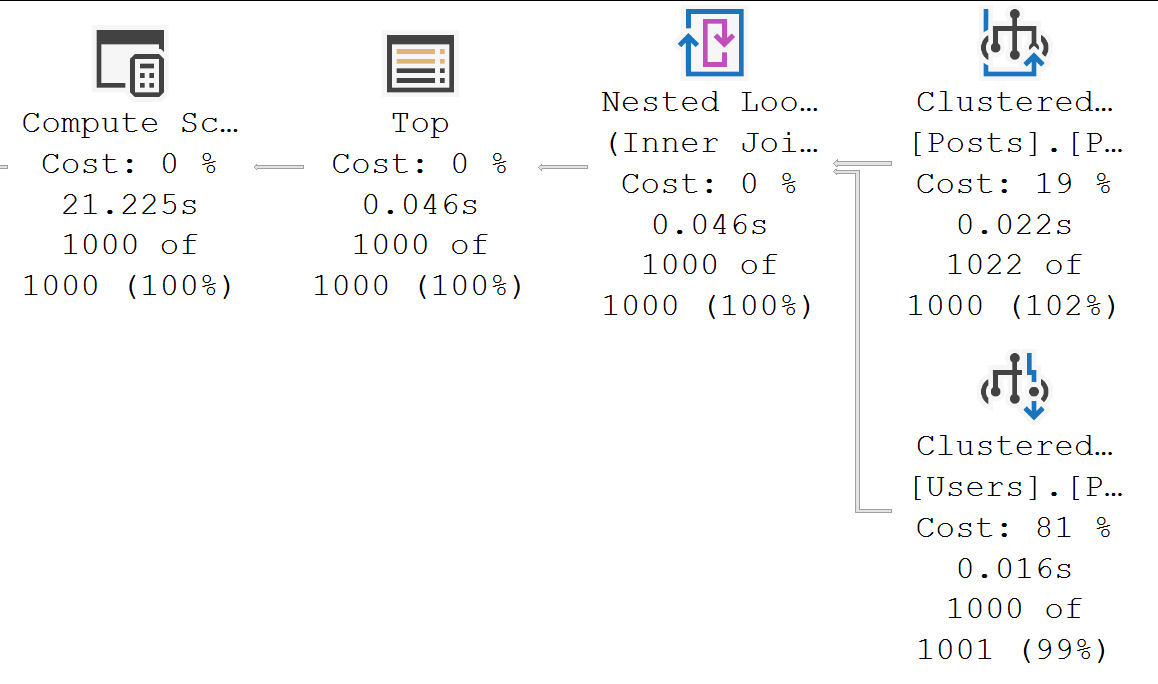
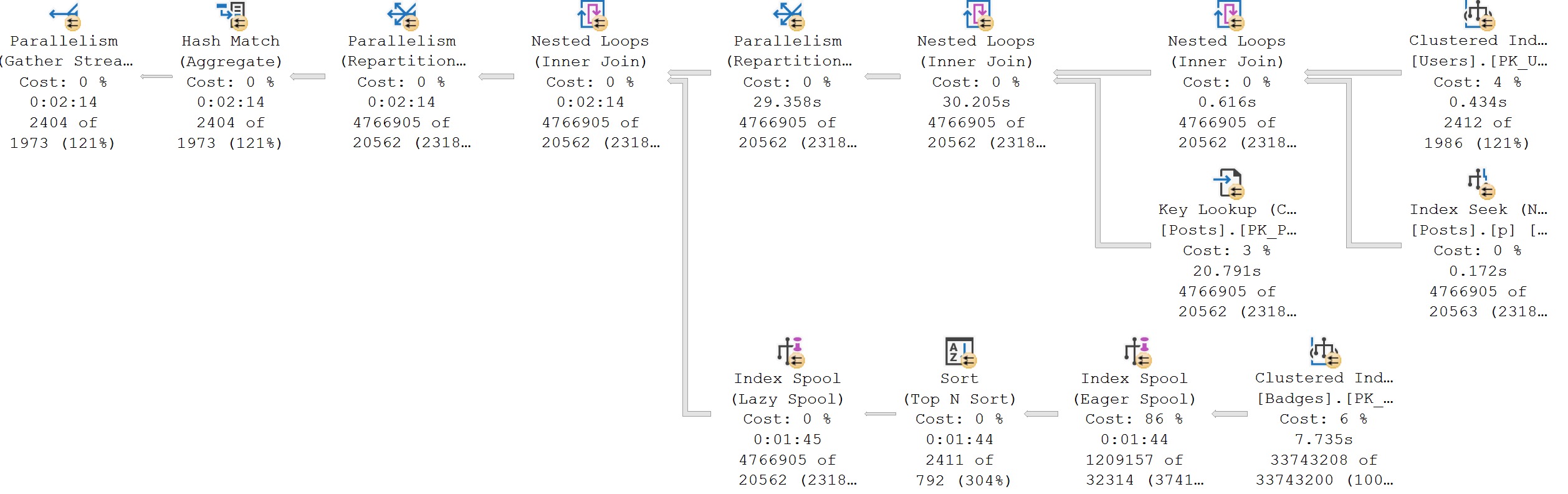
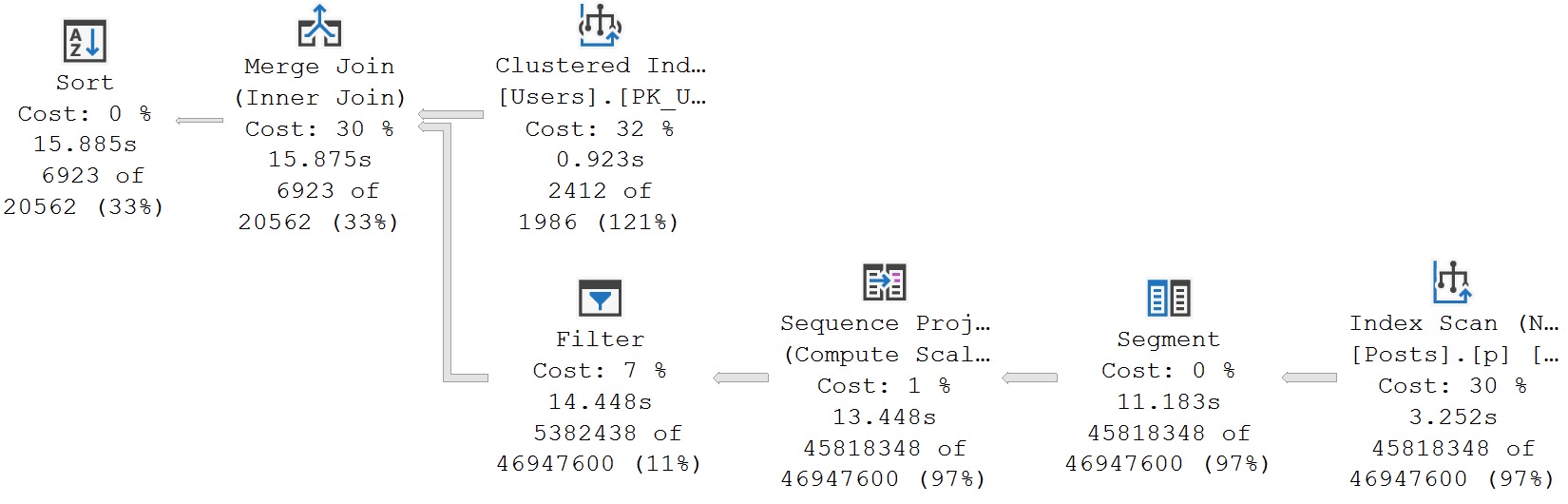
This hash match aggregate is the victim of a fairly large misestimation, and ends up spilling out to disk. In this case, the spill is pretty costly from a performance perspective and ends up adding about 5 seconds to the query plan.
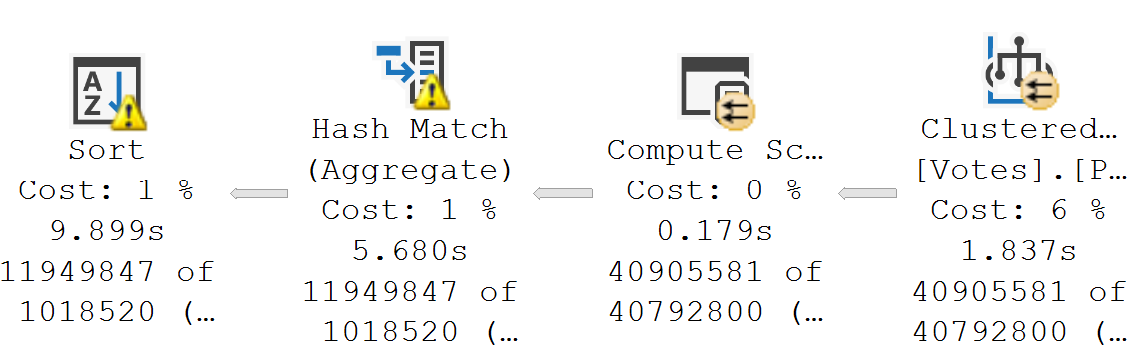
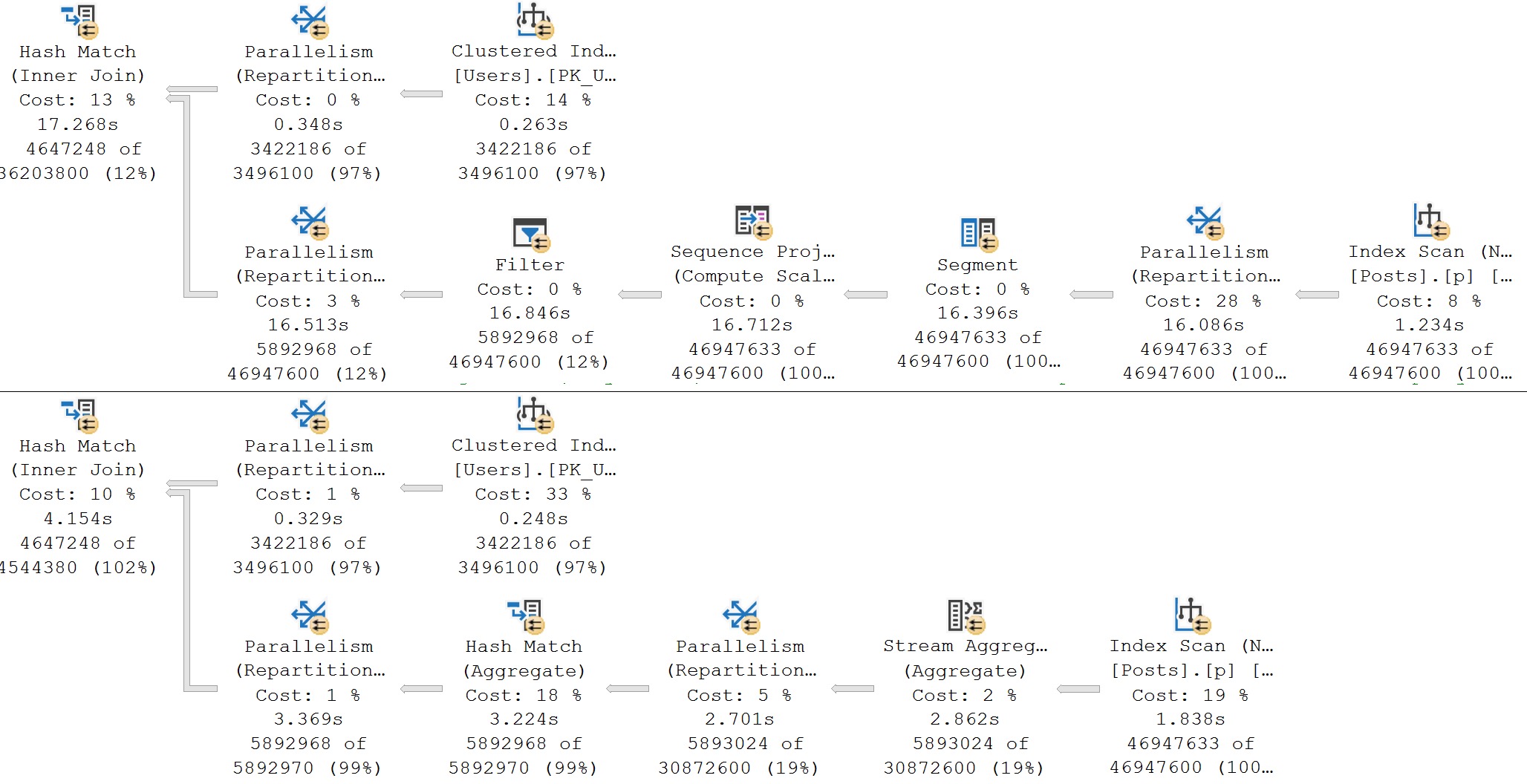
Here, a hash match aggregate misestimates again, but now you can see it impact the next operator over, too. The sort just didn’t have enough of a memory grant to avoid spilling. We add another few seconds onto this one.

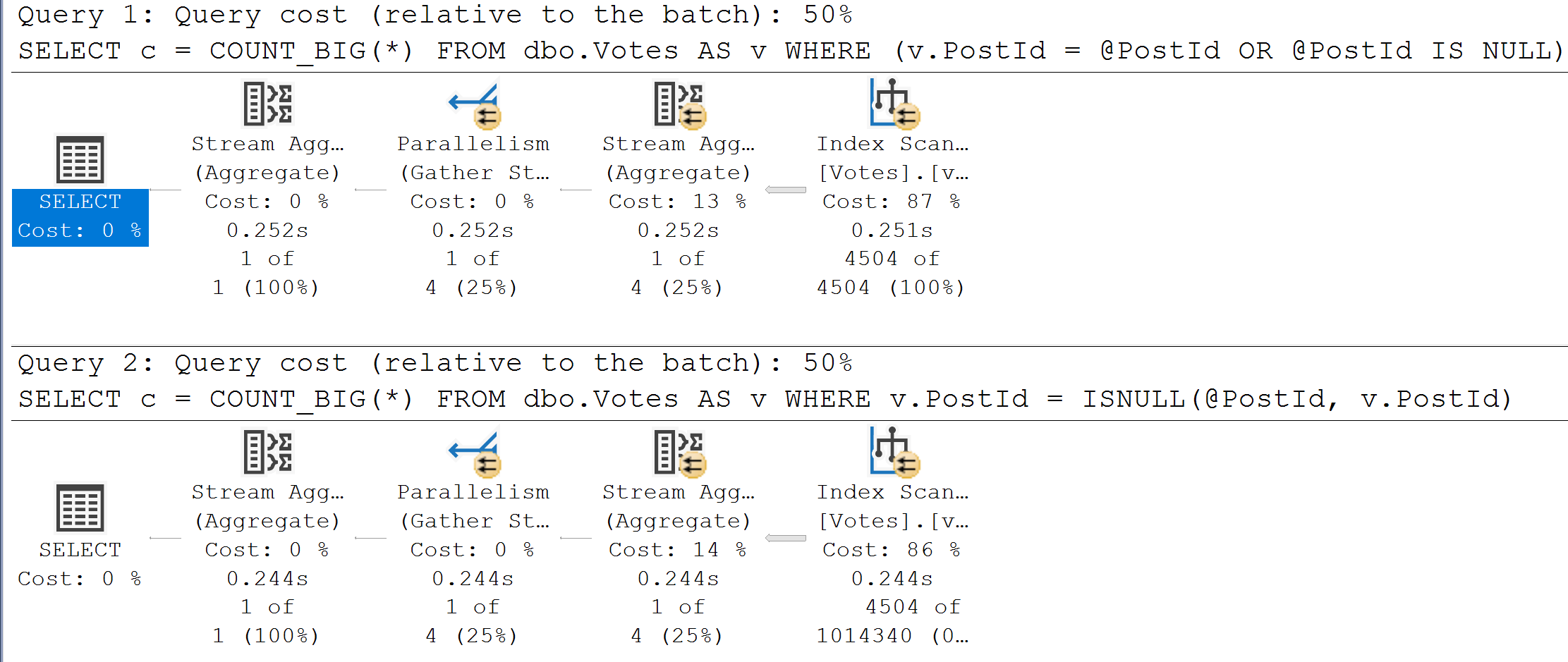
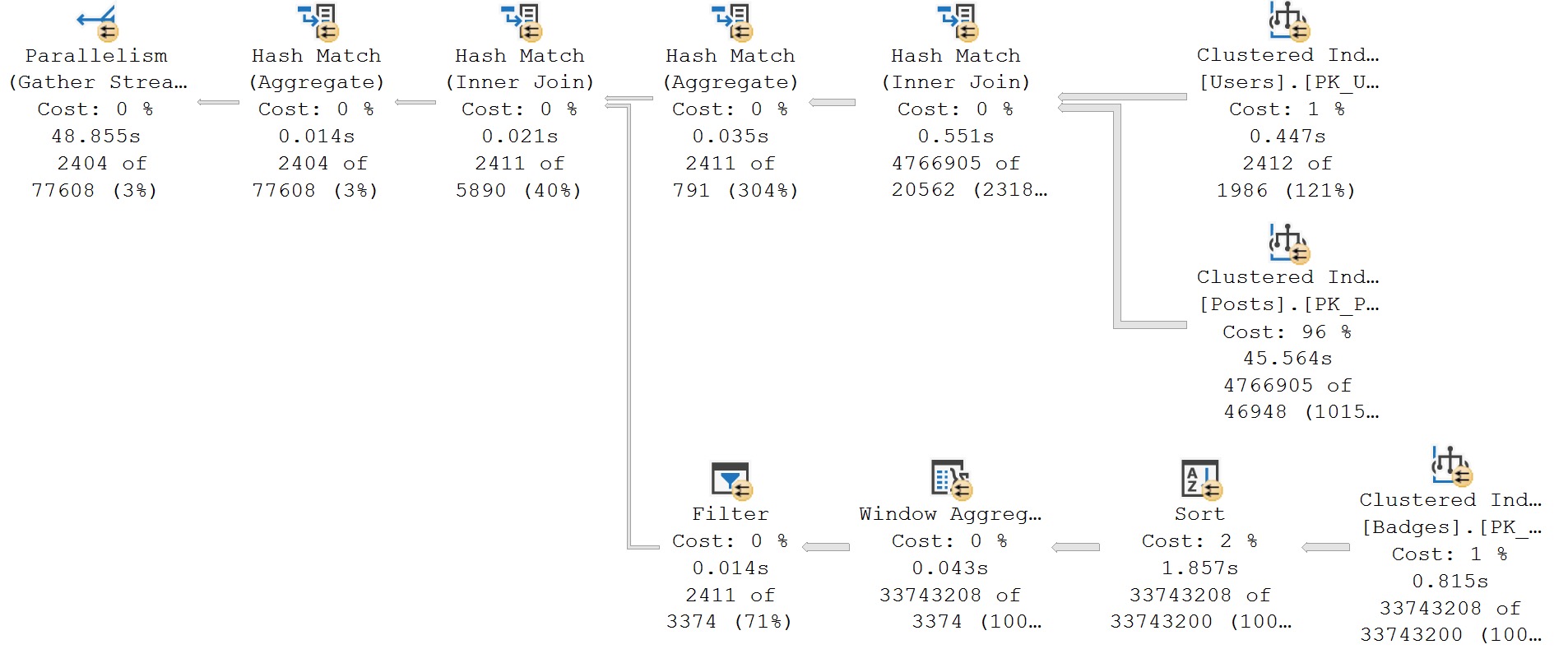
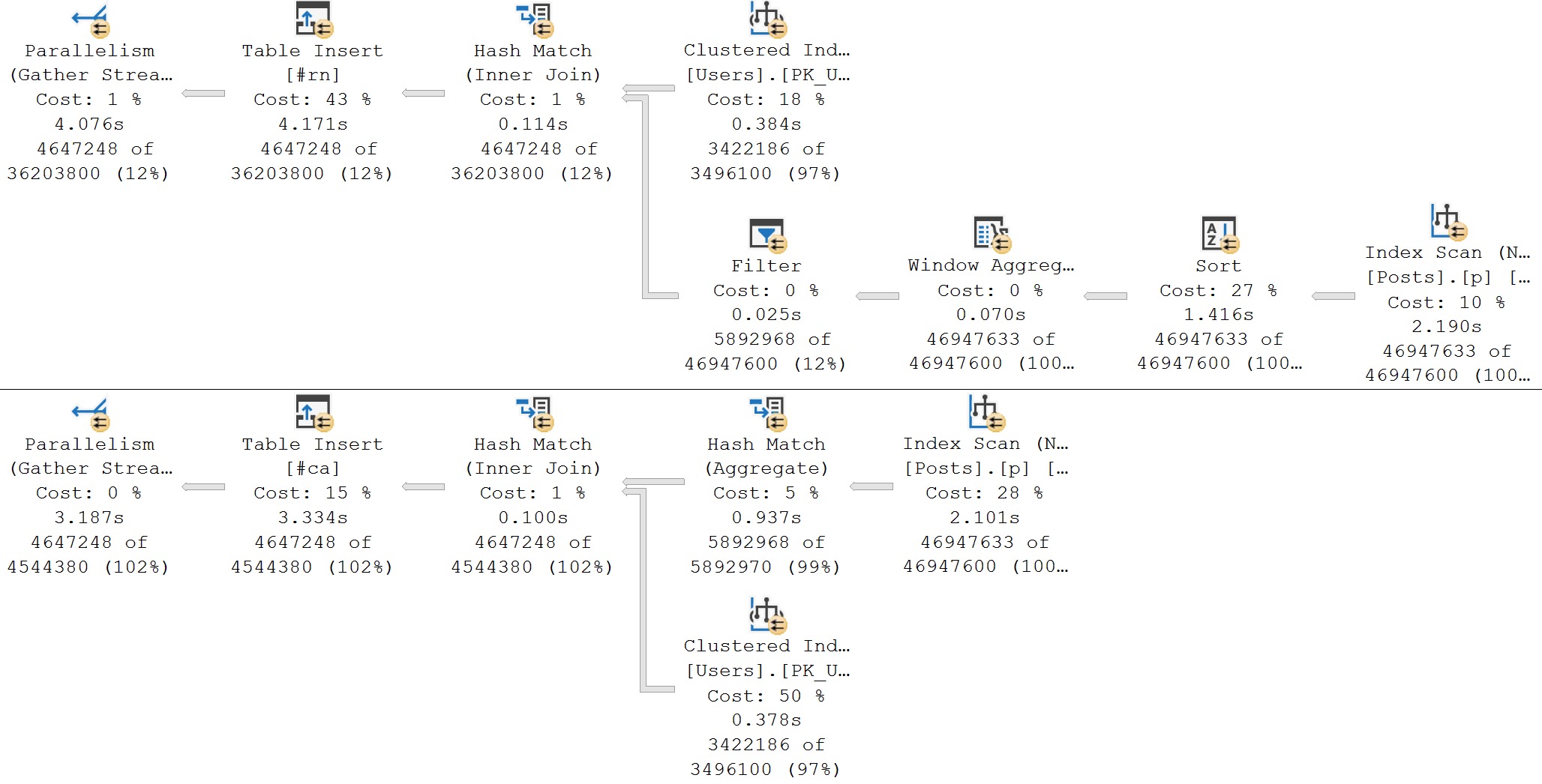
In extreme cases, those spills can really mess things up. This one carries on for a couple minutes, doing nothing but hashing, spilling, and having a bad time.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.