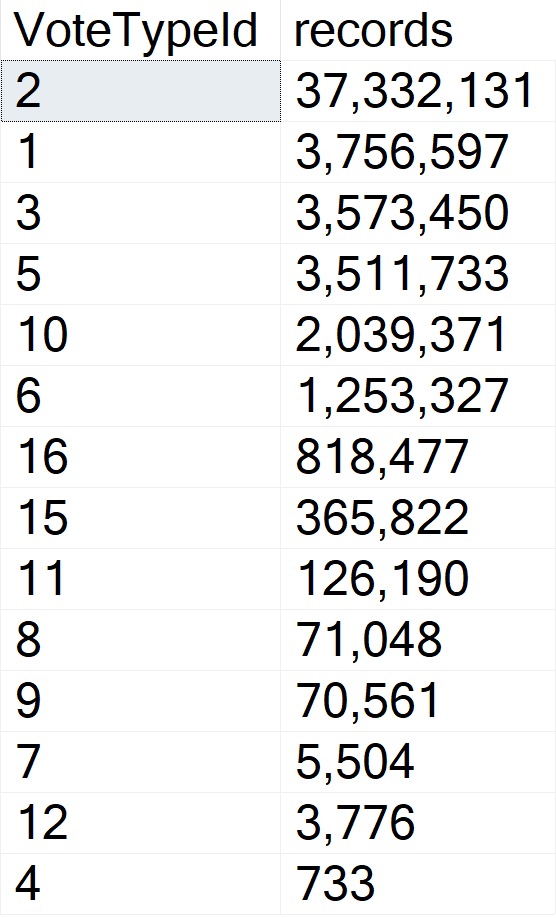
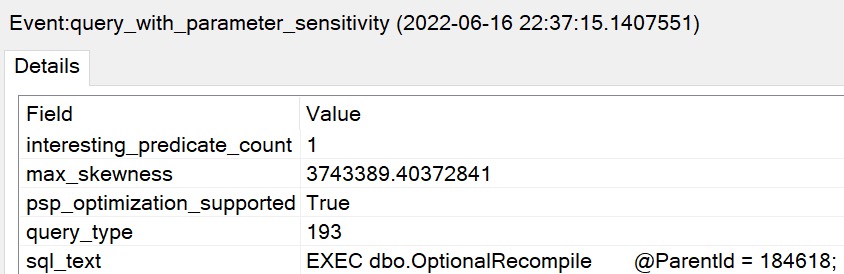
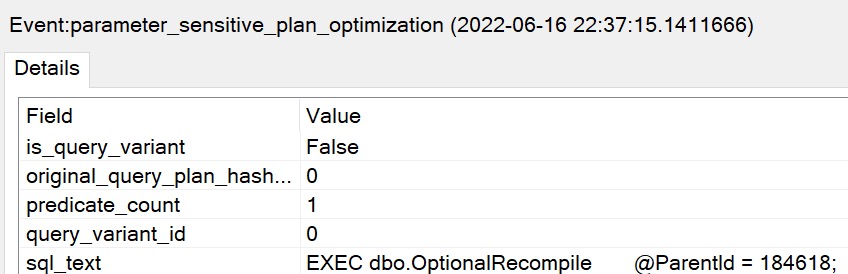
First Things First
The first SQL Server blog posts that I ever read while trying to solve a specific problem here these two:
They sort of changed my life a little, despite the author’s aversion to the letter Z. So that’s cool. Can’t have everything.
To this day, though, I see people screw up paging queries in numerous ways.
- Selecting all the columns in one go
- Adding in joins when exists will do
- Sticking a DISTINCT on there just because
- Thinking a view will solve some problem
- Piles and piles of UDFs
- Local variables for TOP or OFFSET/FETCH
- Not paying attention to indexing
It’s sort of like every other query I see, except with additional complications.
Especially cute for a query slathered in NOLOCK hints is the oft-accompanying concern that “data might change and people might see something weird when they query for the next page”.
Okay, pal. Now you’re concerned.
Modern Love
A while back I recorded a video about using nonclustered column store indexes to improve the performance of paging queries:
While a lot of the details in there are still true, I want to talk about something slightly different today. While nonclustered column store indexes make great data sources for queries with unpredictable search predicates, they’re not strictly necessary to get batch mode anymore.
With SQL Server 2019, you can get batch mode on row store indexes, as long as you’re on Enterprise Edition, and in compatibility level 150.
Deal with it.
The thing is, how you structure your paging queries can definitely hurt your chances of getting that optimization.
Saddened Face
The bummer here is that the paging technique that I learned from Paul’s articles (linked above) doesn’t seem to qualify for batch mode on row store without a column store index in place, so they don’t make the demo cut here.
The good news is that if you’re going to approach this with any degree of hope for performance, you’re gonna be using a column store index anyway.
The two methods we’re going to look at are OFFSET/FETCH and a more traditional ROW_NUMBER query.
As you may have picked up from the title, one will turn out better, and it’s not the OFFSET/FETCH variety. Especially as you get larger, or go deeper into results, it becomes a real boat anchor.
Anyway, let’s examine, as they say in France.
Barfset Wretch
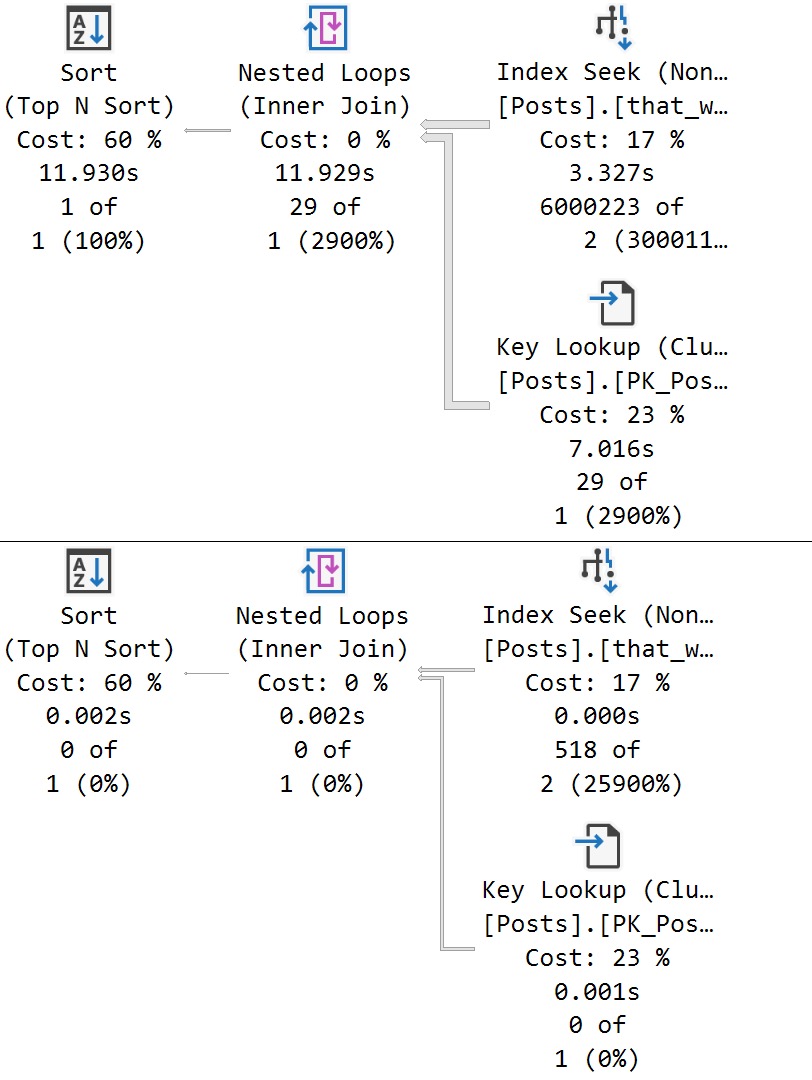
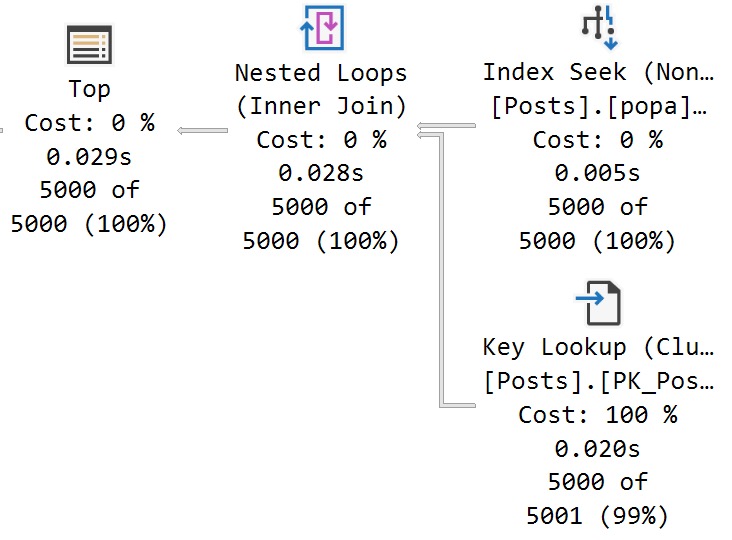
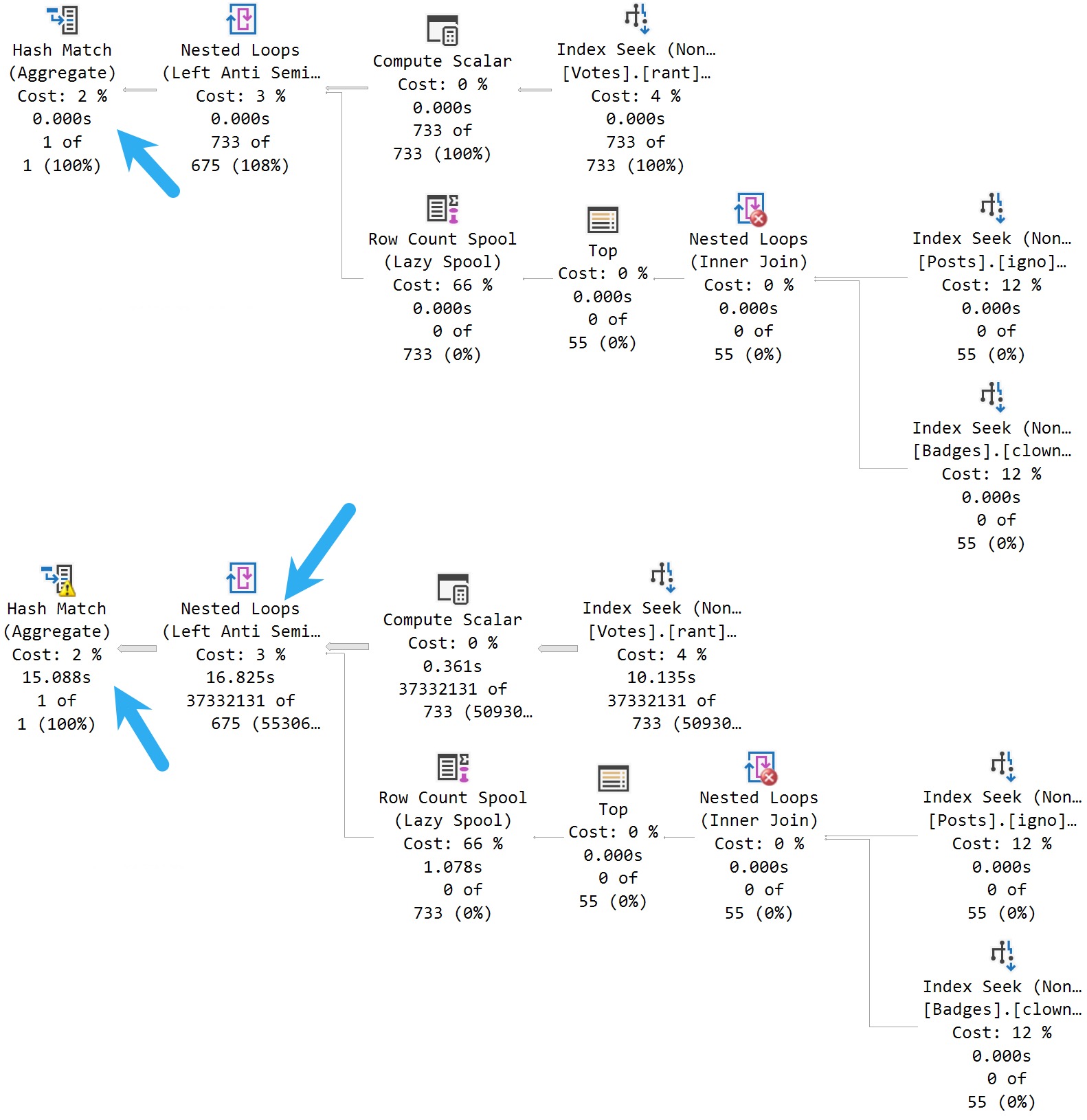
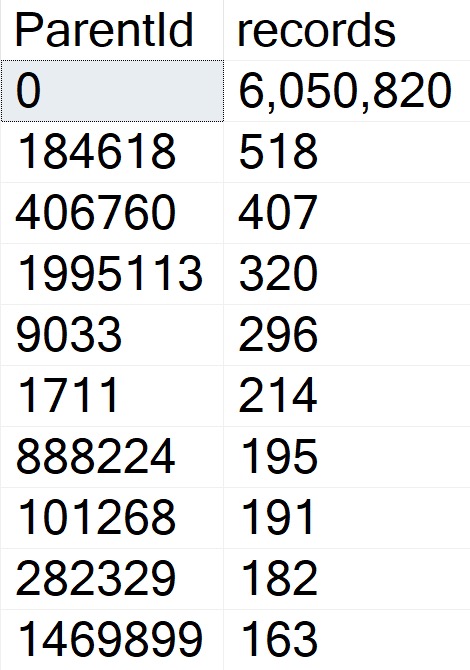
This is the best way of writing this query that I can come up with.
DECLARE
@page_number int = 1,
@page_size int = 1000;
WITH
paging AS
(
SELECT
p.Id
FROM dbo.Posts AS p
ORDER BY
p.LastActivityDate,
p.Id
OFFSET ((@page_number - 1) * @page_size)
ROW FETCH NEXT (@page_size) ROWS ONLY
)
SELECT
p.*
FROM paging AS pg
JOIN dbo.Posts AS p
ON pg.id = p.Id
ORDER BY
p.LastActivityDate,
p.Id
OPTION (RECOMPILE);
Note that the local variables don’t come into play so much here because of the recompile hint.
Still, just to grab 1000 rows, this query takes just about 4 seconds.

This is not so good.
Examine!
Hero Number
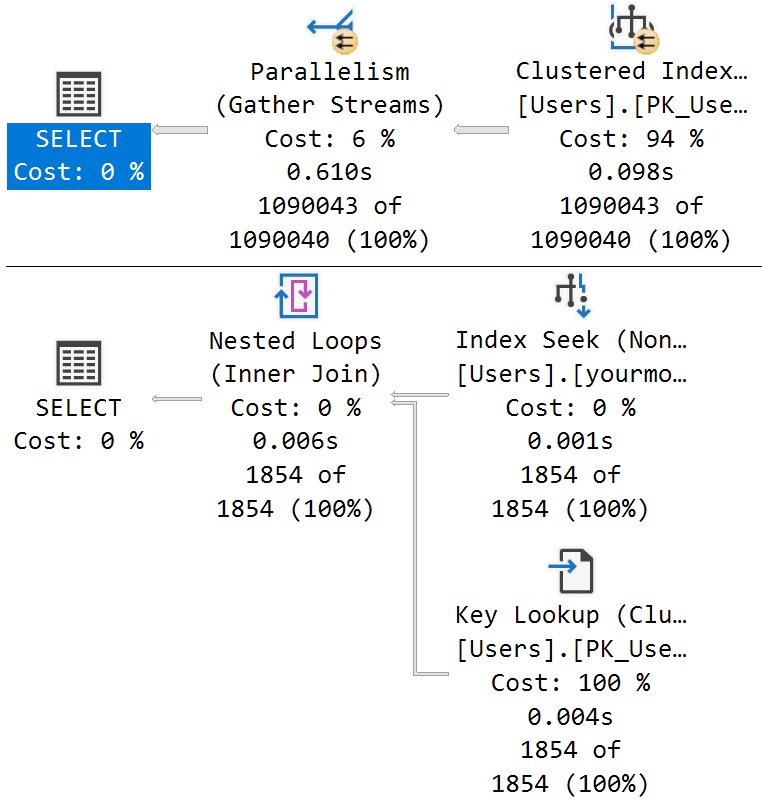
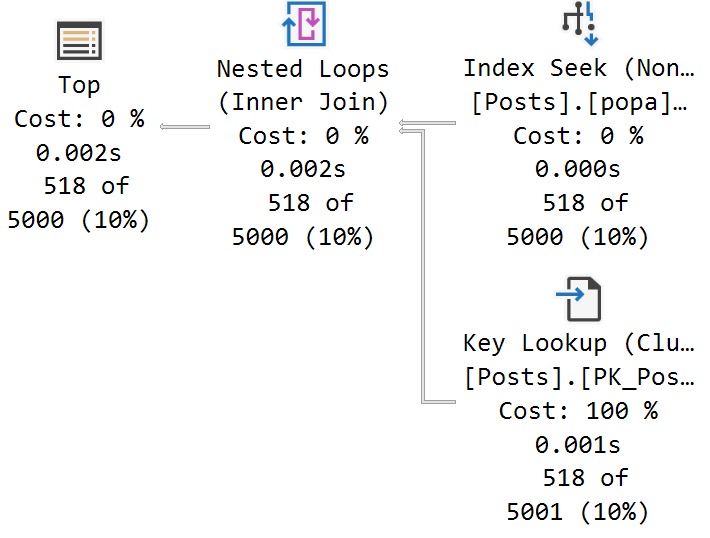
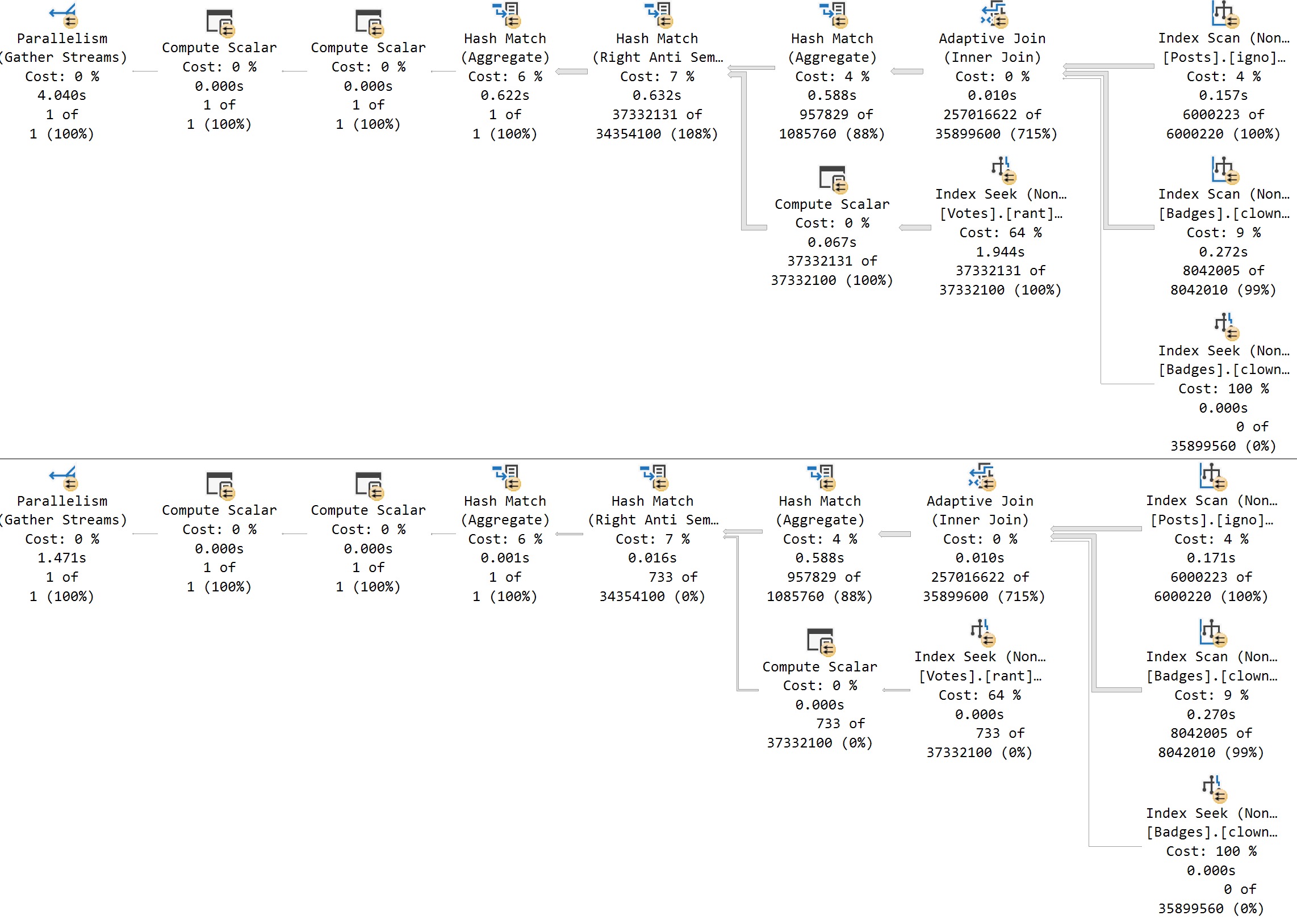
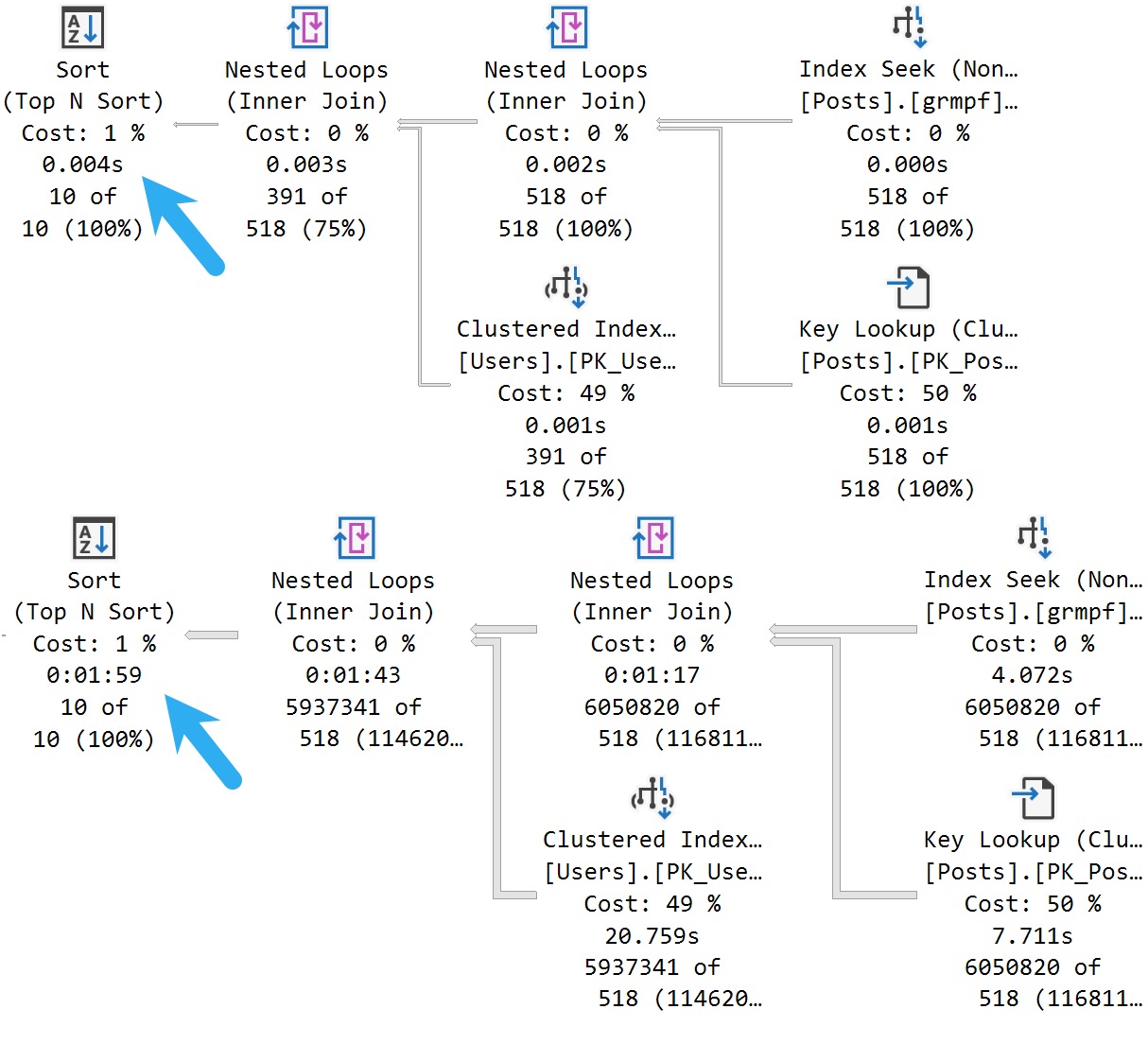
The better-performing query here with the batch mode on row store enhancement(!) is using a single filtered ROW_NUMBER to grab the rows we care about.
DECLARE
@page_number int = 1,
@page_size int = 1000;
WITH
fetching AS
(
SELECT
p.Id,
n =
ROW_NUMBER() OVER
(
ORDER BY
p.LastActivityDate,
p.Id
)
FROM dbo.Posts AS p
)
SELECT
p.*
FROM fetching AS f
JOIN dbo.Posts AS p
ON f.Id = p.Id
WHERE f.n > ((@page_number - 1) * @page_size)
AND f.n < ((@page_number * @page_size) + 1)
ORDER BY
p.LastActivityDate,
p.Id
OPTION (RECOMPILE);
Again, this is about the best I can write the query. Maybe you have a better way. Maybe you don’t.
Mine takes a shade under 2 seconds. Twice as fast. Examine!
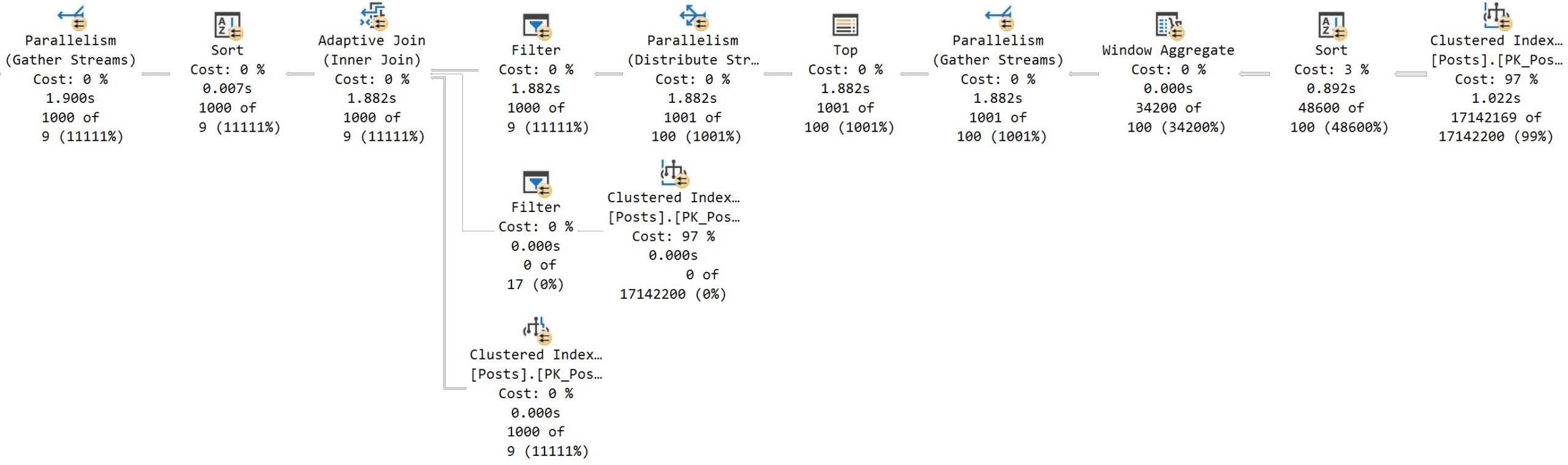
I’ll take twice as fast any day of the week.
Compare/Contrast
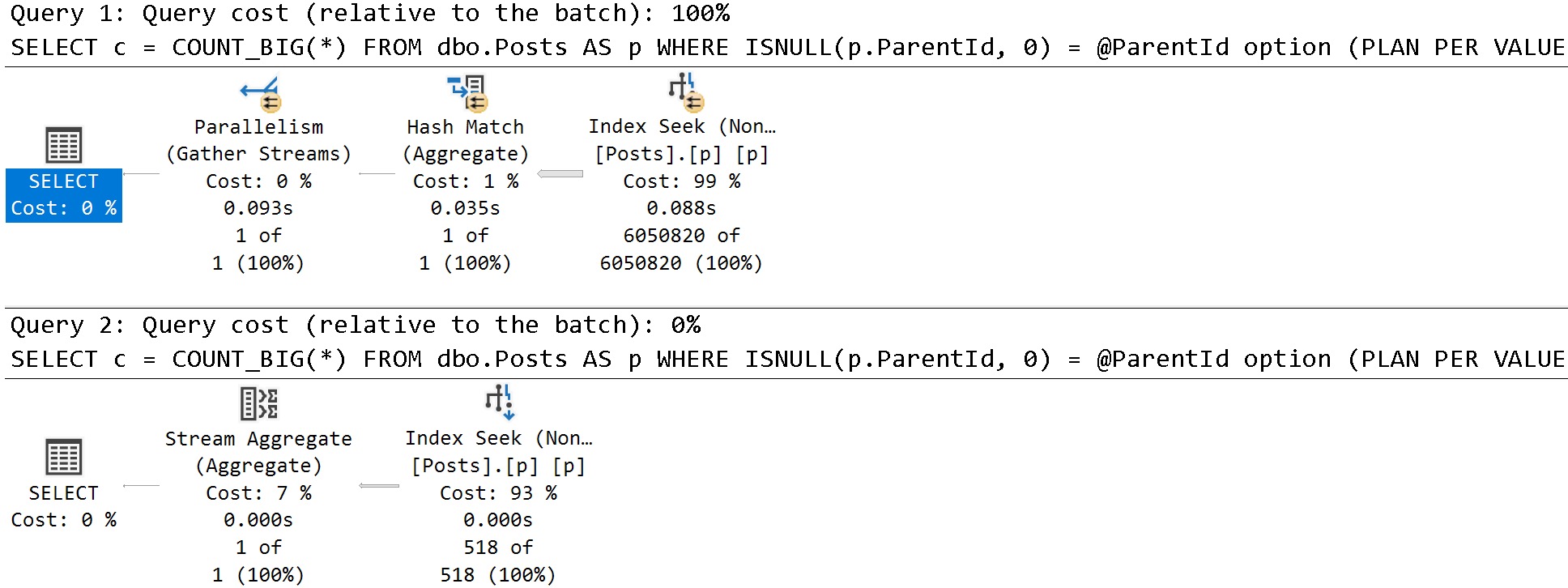
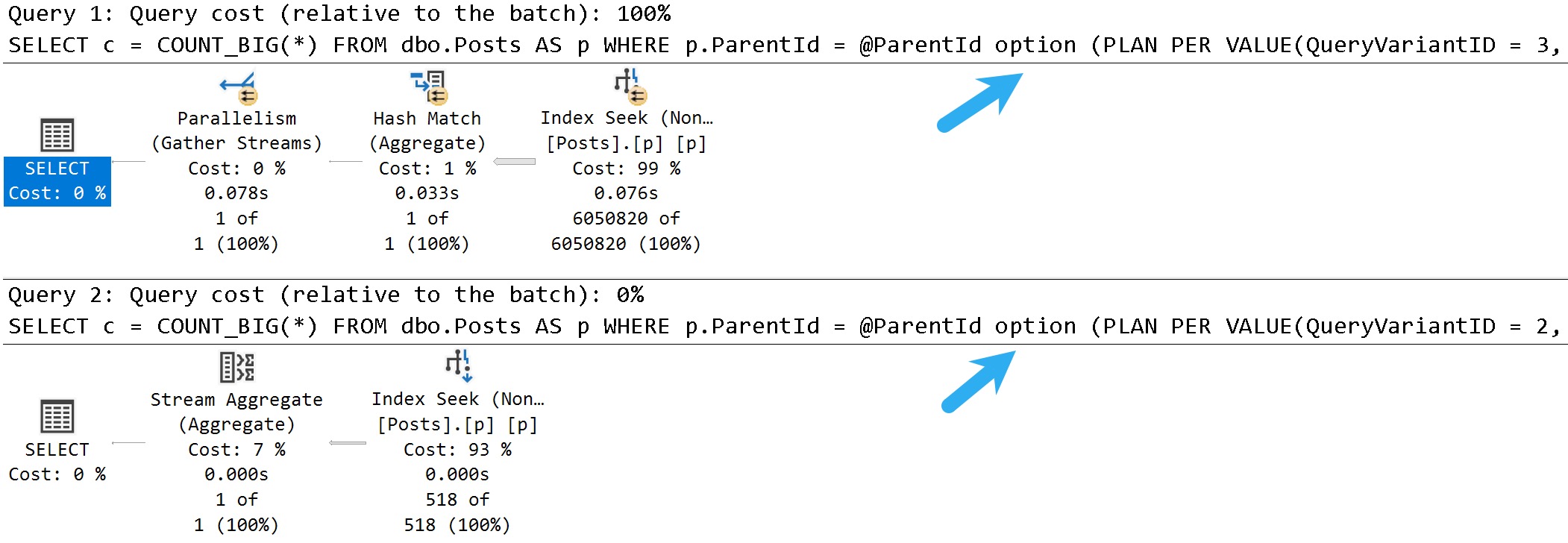
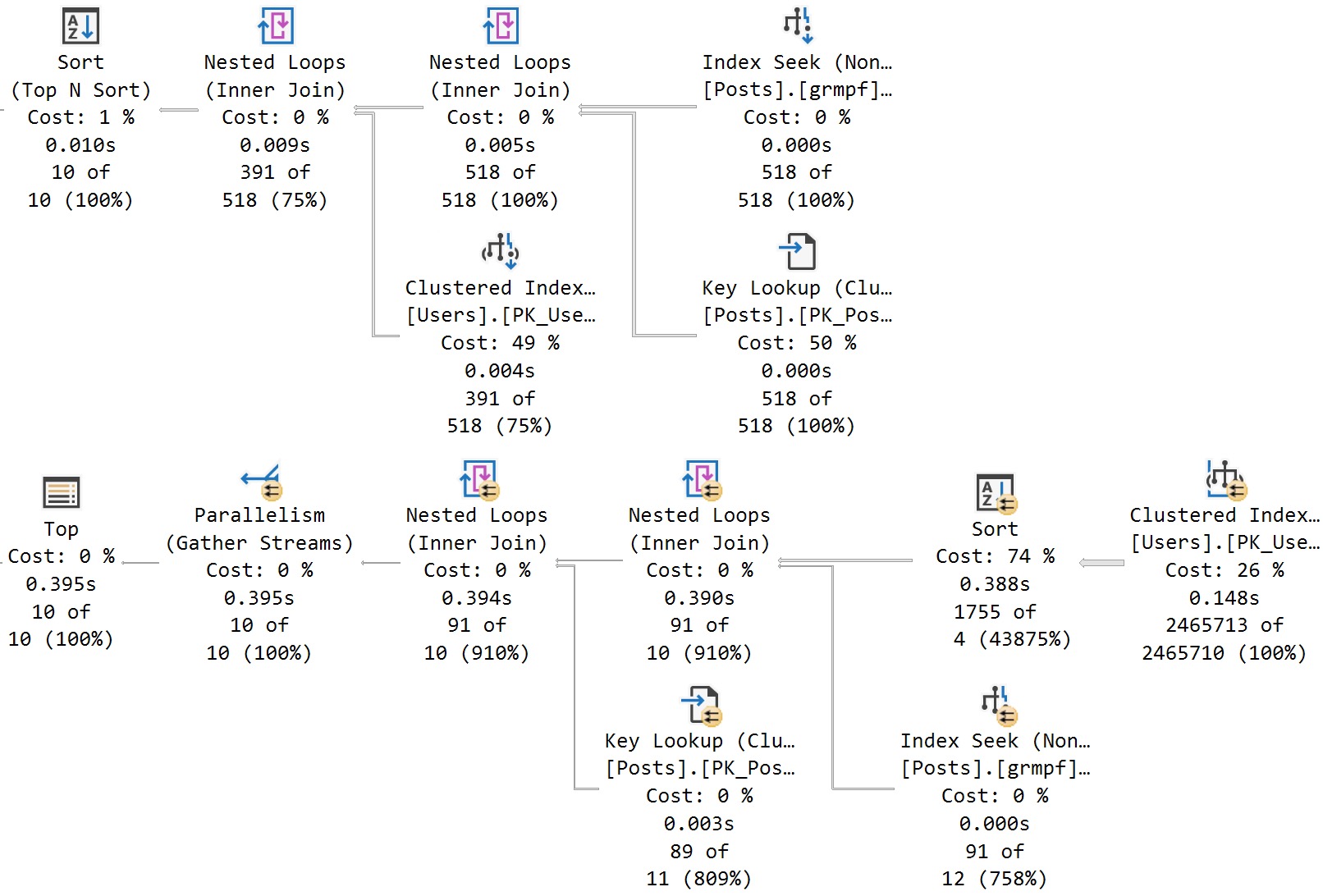
The OFFSET/FETCH query plan is all in row mode, while the ROW_NUMBER query has batch mode elements.
You can see this by eyeballing the plan: it has a window aggregate operator, and an adaptive join. There are other batch mode operators here, but none have visual cues in the graphical elements of the plan.
This is part of what makes things faster, of course. The differences can be even more profound when you add in the “real life” stuff that paging queries usually require. Filtering, joining, other sorting elements, etc.
Anyway, the point here is that how you write your paging queries from the start can make a big difference in how they end up, performance-wise.
Newer versions of SQL Server where certain behaviors are locked behind heuristics (absent column store indexes being present in some manner) can be especially fickle.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.