Way Out
Whenever I see people using NOLOCK hints, I try to point out that they’re not a great idea, for various reasons explained in detail all across the internet.
At minimum, I want them to understand that the hint name is the same as setting the entire transaction isolation level to READ UNCOMMITTED, and that the hint name is quite misleading. It doesn’t mean your query takes no locks, it means your query ignores locks taken by other queries.
That’s how you can end up getting incorrect results.
That warning often comes with a lot of questions about how to fix blocking problems so you can get rid of those hints.
After all, if you get rid of them, your SQL Server queries will (most likely) go back to using the READ COMMITTED isolation level and we all know that read committed is a garbage isolation level, anyway.
Cause and Wrecked
An important thing to understand is why the hint was used in the first place. I’ve worked with some nice developers who slapped it on every query just in case.
There was no blocking or deadlocking. They just always used it, and never stopped.
Not that I blame them; the blocking that can occur under read committed the garbage isolation level is plain stupid, and no respectable database platform should use it as a default.
In many ways, it’s easier for a user to re-run a query and hopefully get the right result and shrug and mumble something about computers being awful, which is also true.
So, first step: ask yourself if there was ever really a blocking problem to begin with.
Bing Tutsby
Next, we need to understand where the blocking was coming from. Under read committed the garbage isolation level, writers can block readers, and readers can block writers.
In most cases though, people have added the hint to all of their queries, even ones that never participated in blocking.
- If the problem was writers blocking writers, no isolation can help you.
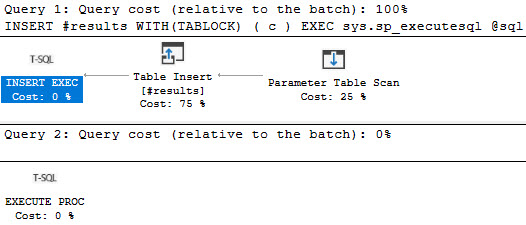
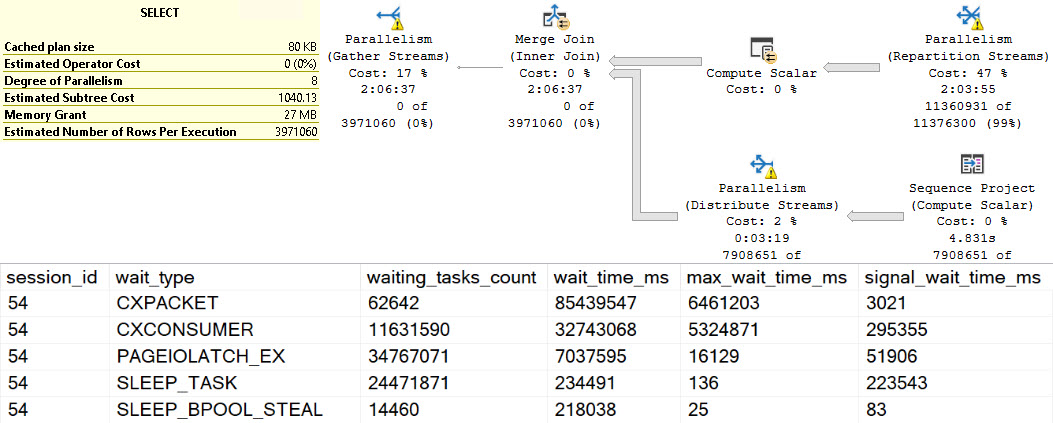
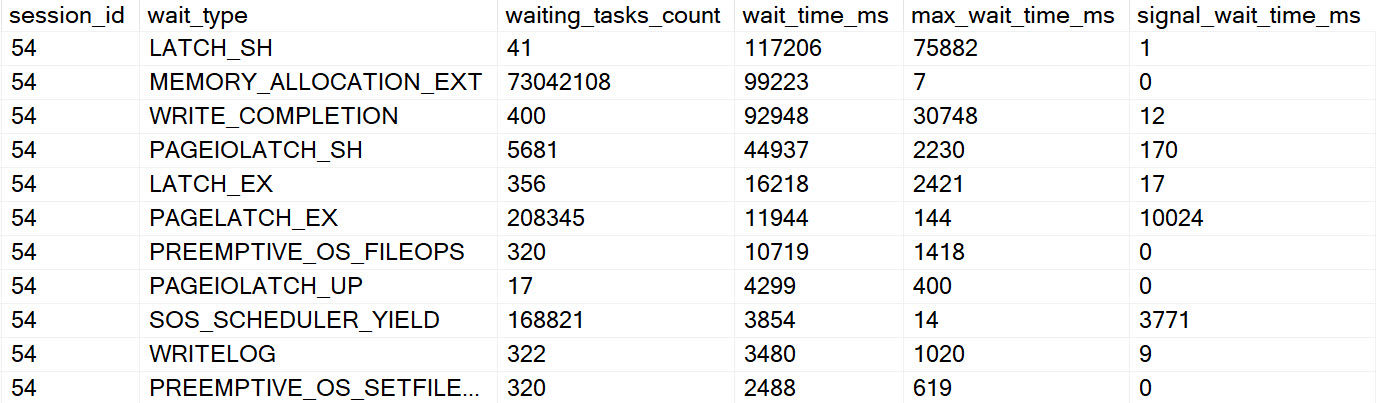
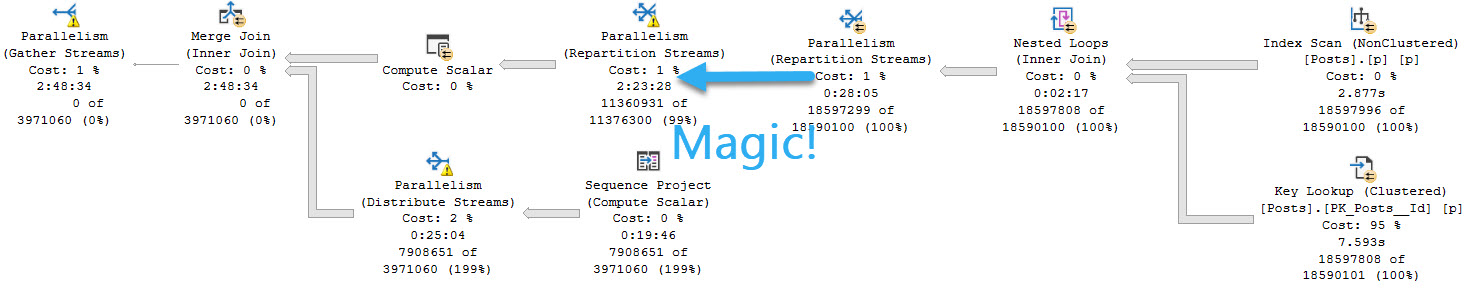
- If the problem was readers blocking writers, you may need to look at long running queries with Key Lookups
If the problem was writers blocking readers, you’d have to look at a few things:
- Are you modification queries biting off more than they should chew?
- Do they have good indexes in place to locate rows to update or delete?
If you have query store enabled, you can use sp_QuickieStore to search it for queries that do a lot of writes. If you don’t, you can use sp_BlitzCache to search the plan cache for them.
Best Case
Of course, you can avoid all of these problems, except for writers blocking writers, by using an optimistic isolation level like Read Committed Snapshot Isolation or Snapshot Isolation.
In the past, people made a lot of fuss about turning these on, because
- You may not have tempdb configured correctly
- You have queue type code that relied on blocking for correctness
But in reasonably new versions of SQL Server, tempdb’s setup is part of the install process, and the wacky trace flags you used to have to turn on are the default behavior.
If you do have code in your application that processes queues and relies on locking to correctly process them, you’re better off using locking hints in that code, and using an optimistic isolation level for the rest of your queries. This may also be true of triggers that are used to enforce referential integrity, which would need READCOMMITTEDLOCK hints.
The reason why they’re a much better choice than using uncommitted isolation levels is because rather than get a bunch of dirty reads from in-flight changes, you read the last known good version of the row before a modification started.
This may not be perfect, but it will prevent the absolute majority of your blocking headaches. It will even prevent deadlocks between readers and writers.
No, Lock
If your code has a lot of either NOLOCK hints or READ UNCOMITTED usage, you should absolutely be worried about incorrect results.
There are much better ways to deal with blocking, and I’ve outlined some of them in this post.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.