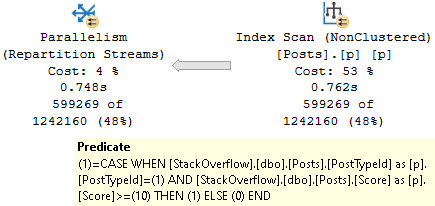
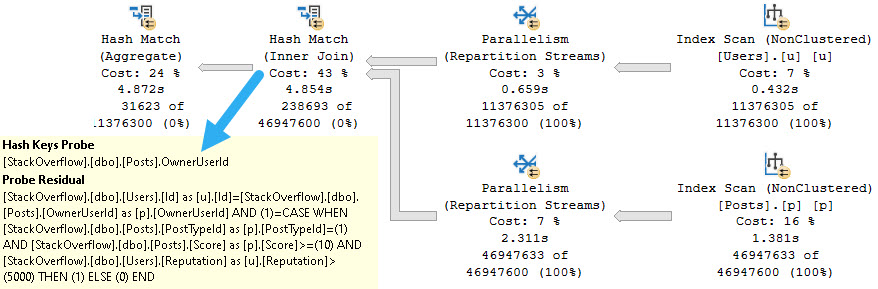
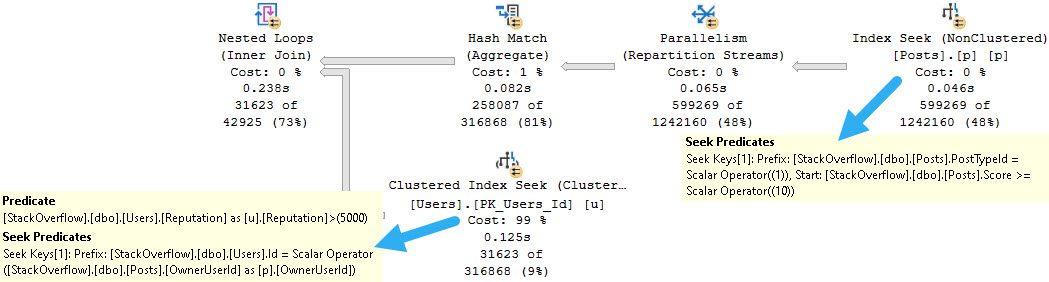
Cloudy With A Chance
The more I work with Standard Edition, the more frustrated I get, and the more I have to tell people about the cost difference between it and Enterprise Edition, the more people start asking me about Postgres.
I wish that were a joke. Or that I knew Postgres better. Or that I knew the PIVOT syntax
(That was a terrible joke)
Mold And Musted
I’ve written about my Standard Edition annoyances in the past:
- SQL Server 2019: Please Increase the RAM Limit For Standard Edition
- How Useful Is Column Store In Standard Edition?
- Standard Edition Programmability Features Are Not Performance Features
- Allow Memory Grant Percent In Standard Edition
In the past I’ve thought that offering something between Standard and Enterprise Edition, or add-ons depending on what you’re after would be a good move.
For example, let’s say you want to unlock the memory limit and performance features, or you want the full Availability Group experience, you could buy them for some SA-like tax. But that just… makes licensing more complicated, and it’s already bad enough.
One install, one code base, one set of features, no documentation bedazzled with asterisks.
Perhaps best of all, everyone can stop complaining that Developer Edition is misleading because you can’t turn off Enterprise Edition features.
And you could better line the bits up with that’s in Azure SQL DB and Managed Instances.
Priceline
I have no idea how to handle the pricing, here. Perhaps that could also better line up with Azure offerings as well.
At any rate, something here has to give. Standard Edition is entirely uncompetitive in too many ways, and the price is too far apart from Enterprise Edition to realistically compare. That $5,000 jump per core is quite a jaw-dropper.
One option might be to make Express Edition the new Standard Edition, keeping it free and giving it the limitations that Standard Edition currently has.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.