If you’re ever on a long flight and want something to fall asleep to, ask a DBA how to set MAXDOP.
Sometimes I even ask myself that question when I’m tossing and turning at night.
There are a lot of things to consider when fixing settings globally across a workload. For parallelism, it’s less about individual query performance, and more about overall server/workload performance
After all, letting every query go as absolutely parallel as possible is only good up to a point; that point is usually when you start regularly running out of worker threads, or your CPUs could double as crematoriums.
Setting MAXDOP is about limiting the damage that a parallel workload can do to a server. The expectation is that a query running at DOP 8 will run 8x faster than a query running at DOP 1.
But setting MAXDOP for every query isn’t something you catch even the most persnickety performance tuners doing. Perhaps some of the more critical ones, but you know…
Let Me Rust
I’m not going to demo DOP feedback in this post, I’m just going to show you the situation that it hopes to improve upon.
To do that, I’m going to run a simple aggregation query at different degrees of parallelism, and show you the changes in query timing.
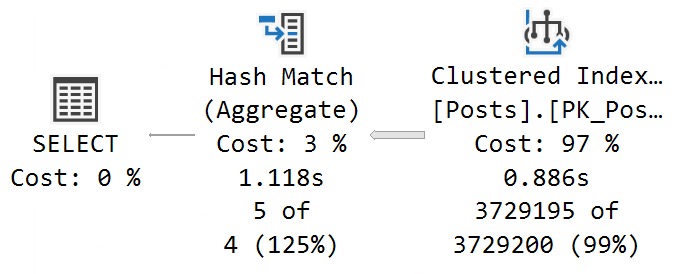
At DOP 1:
The query runs for 1.1 seconds, with 886ms consumed while scanning the Posts table.
DOPPER DON
At DOP 2:
The query runs just about twice as fast, starting with the scan of the Posts table taking about half as long. This is good scaling. Add one CPU, go twice as fast as you did with one CPU.
Rip Van Winkle
At DOP 4:
The gets about twice as fast again! The scan of the Posts table is now down to 263ms, and the query in total is at 330ms. Adding in two more cores seems a good choice, here.
Bed Rock
At DOP 8:
The query no longer continues to get 2x faster. This isn’t a knock against DOP 8 in general; my query just happens to hit a wall around DOP 4. With 4 additional CPUs, we only save ~130ms at the end of the day.
Anubis
Why This Is Cool
This new feature will help DBAs have to worry less about getting MAXDOP absolutely right across the board. Who knows, we may even see a day where MAXDOP is left at zero.
But you’d never skip that installer step, would you?
Anyway, for anyone out there who is paranoid about setting DOP too high, this should help your queries find a more approximately-good middle ground.
Hopefully it works as advertised.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Searching the internet for every problem isn’t cutting it. You need to be more proactive and efficient when it comes to finding and solving database performance fires.
I work with consulting customers around the world to put out SQL Server performance fires. In this day of learning, I will teach you how to find and fix your worst SQL Server problems using the same modern tools and techniques which I use every week.
You’ll learn tons of new and effective approaches to common performance problems, how to figure out what’s going on in your query plans, and how indexes really work to make your queries faster. Together, we’ll tackle query rewrites, batch mode, how to design indexes, and how to gather all the information you need to analyze performance.
This day of learning will teach you cutting edge techniques which you can’t find in training by folks who don’t spend time in the real world tuning performance. Performance tuning mysteries can easily leave you stumbling through your work week, unsure if you’re focusing on the right things. You’ll walk out of this class confident in your abilities to fix performance issues once and for all.
If you want to put out SQL Server performance fires, this is the precon you need to attend. Anyone can have a plan, it takes a professional to have a blueprint.
I’ve also got a couple regular sessions that’ll get announced later on.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
SQL Server query plans have had, forever, pretty generic reasons embedded in the XML for why your query was prevented from going parallel.
Not for things like it not breaking the Cost Threshold For Parallelism barrier, which should be obvious to the end user, but certainly for things like scalar UDFs, etc.
The thing is, the reason always seemed to be “Could Not Generate Valid Parallel Plan” for most of them, even though more explicit reasons were available.
They started cropping up, as things do, in Azure SQL DB, and have finally made it to the box product that we all know and mostly love.
Let’s explore some of them! Because that’s what we do.
Generate Valid Blog Post
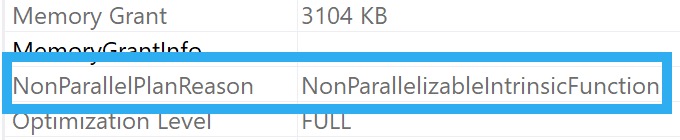
First, some intrinsic functions prevent a parallel plan. You can always see the reason (if one exists) if you look in the properties of the root operator in the query plan.
not for you!
Some Intrinsic Functions
An easy one to validate this with is OBJECT_NAME
SELECT
c = OBJECT_NAME(COUNT_BIG(*))
FROM dbo.Posts AS p;
There’s always some hijinks about with cursors, but here you go:
DECLARE
@c bigint;
DECLARE
c CURSOR
FAST_FORWARD
FOR
SELECT
c = COUNT_BIG(*)
FROM dbo.Posts AS p;
OPEN c;
FETCH NEXT
FROM
c
INTO
@c;
CLOSE c;
DEALLOCATE c;
GO
This is another reason that I have seen around for a while too, but we may as well be thorough:
CREATE OR ALTER FUNCTION
dbo.c
(
@c bigint
)
RETURNS bigint
WITH SCHEMABINDING, RETURNS NULL ON NULL INPUT
AS
BEGIN
DECLARE /*Ruin UDF inlining with one weird trick*/
@gd datetime = GETDATE();
RETURN @c;
END;
GO
SELECT
c = dbo.c(COUNT_BIG(*))
FROM dbo.Posts AS p;
Fun stuff is always in XML. Just think about all the best times in your life. I bet XML was involved.
Now when you look at it, it will tell you what’s screwing up parallel plan generation in your SQL Server queries.
J’accuse, as they say.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Whenever I’m looking over query plans with clients, their eyes get drawn towards many things that I’ve learned to ignore over the years.
It’s not that they’re never important, it’s just that, you know… There’s usually more important stuff.
One of those things is compilation timeouts. Most people think that it’s time-based, and it means that their query timed out or took a long time to compile.
Not so! It’s purely a set number of steps the optimizer will take to figure out things like:
Join order
Join/Aggregate type
Index usage
Seeks vs Scans
Parallelism
And probably some other stuff that I just don’t have the Friday afternoon energy to think about any more.
But anyway, the point is that it’s not a sign that your query timed out, or even that plan compilation took a long time.
The initial number of steps allowed is based on the optimizer’s assessment of statement complexity, which includes the number of joins (of course), in case you were wondering.
From there each additional stage gets a set number of steps based on the number of steps that the previous stage took.
Plan Cache Script
You can use this script to look in your plan cache for plans that the optimizer has marked as having a timeout.
WITH
XMLNAMESPACES
(
DEFAULT 'http://schemas.microsoft.com/sqlserver/2004/07/showplan'
)
SELECT
query_text =
SUBSTRING
(
st.text,
qs.statement_start_offset / 2 + 1,
CASE qs.statement_start_offset
WHEN -1
THEN DATALENGTH(st.text)
ELSE qs.statement_end_offset
END - qs.statement_start_offset / 2 + 1
),
compile_time_ms =
qs.query_plan.value('(//StmtSimple/QueryPlan/@CompileTime)[1]', 'bigint'),
compile_cpu_ms =
qs.query_plan.value('(//StmtSimple/QueryPlan/@CompileCPU)[1]', 'bigint'),
compile_memory_mb =
qs.query_plan.value('(//StmtSimple/QueryPlan/@CompileMemory)[1]', 'bigint') / 1024.,
qs.query_plan,
qs.execution_count,
qs.total_worker_time,
qs.last_execution_time
FROM
(
SELECT TOP (10)
qs.plan_handle,
qs.sql_handle,
qs.statement_start_offset,
qs.statement_end_offset,
qs.last_execution_time,
qs.execution_count,
qs.total_worker_time,
qp.query_plan
FROM sys.dm_exec_query_stats AS qs
CROSS APPLY sys.dm_exec_query_plan(qs.plan_handle) AS qp
WHERE qp.query_plan.exist('//StmtSimple/@StatementOptmEarlyAbortReason[.="TimeOut"]') = 1
ORDER BY
total_worker_time / qs.execution_count DESC
) AS qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) AS st;
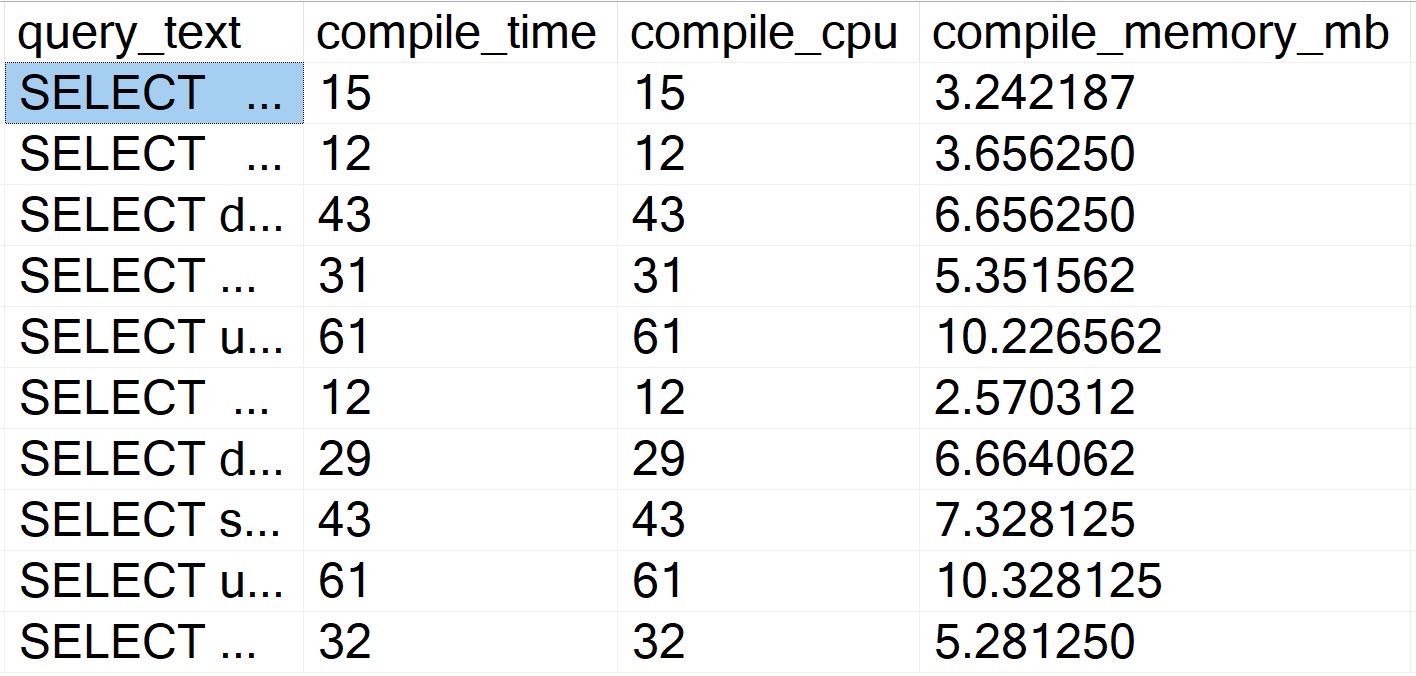
There’s not a whole lot of sense to this query other than to prove a point. Here are some abridged results from a client system:
amanaplanacanalpanama
Despite all of these queries “timing out” during optimization phases, the longest compile time is 61 milliseconds.
Query Store Script
Like above, there’s not a lot of sense to this one. It is nice to be able to skip some of the additional XML shredding and go to some of the plan metadata stored in Query Store:
WITH
XMLNAMESPACES
(
DEFAULT 'http://schemas.microsoft.com/sqlserver/2004/07/showplan'
),
queries
AS
(
SELECT TOP (101)
parent_object_name =
ISNULL
(
OBJECT_NAME(qsq.object_id),
'No Parent Object'
),
qsqt.query_sql_text,
query_plan =
TRY_CAST(qsp.query_plan AS xml),
qsrs.last_execution_time,
qsrs.count_executions,
qsrs.avg_duration,
qsrs.avg_cpu_time,
avg_compile_duration_ms =
qsq.avg_compile_duration / 1000.,
avg_compile_memory_mb =
qsq.avg_compile_memory_kb / 1024.,
avg_optimize_cpu_time_ms =
qsq.avg_optimize_cpu_time / 1024.
FROM sys.query_store_runtime_stats AS qsrs
JOIN sys.query_store_plan AS qsp
ON qsp.plan_id = qsrs.plan_id
JOIN sys.query_store_query AS qsq
ON qsq.query_id = qsp.query_id
JOIN sys.query_store_query_text AS qsqt
ON qsqt.query_text_id = qsq.query_text_id
WHERE qsrs.last_execution_time >= DATEADD(DAY, -7, SYSDATETIME())
AND qsrs.avg_cpu_time >= (10 * 1000)
AND qsq.is_internal_query = 0
AND qsp.is_online_index_plan = 0
AND TRY_CAST(qsp.query_plan AS xml).exist('//StmtSimple/@StatementOptmEarlyAbortReason[.="TimeOut"]') = 1
ORDER BY
qsrs.avg_cpu_time DESC
)
SELECT
qs.query_sql_text,
qs.parent_object_name,
qs.query_plan,
qs.avg_compile_duration_ms,
qs.avg_optimize_cpu_time_ms,
qs.avg_compile_memory_mb,
qs.count_executions,
qs.avg_duration,
qs.avg_cpu_time,
qs.last_execution_time
FROM
queries AS qs
ORDER BY
qs.avg_cpu_time DESC
OPTION (RECOMPILE);
Also like above, the results bring back very short compile times.
So There
The point of this post was that you don’t need to worry about these timeouts from a plan compilation time perspective.
Of course, it may represent a plan quality issue, but that’s much harder to prove from first glances. You’d need to dig into that on your own Friday afternoon.
If you find user queries experiencing optimizer timeouts, it may solve the problem to simplify them as much as possible. Breaking long queries up into #temp tables is a popular solution for this.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Query hints seem to get treated like prescription drugs. You hear all the problems they can solve, but then you get a long list of problems they can cause.
“Your cholesterol will be lower, but you might bleed to death from your eyes.”
I use query hints all the time to show people what different (and often better) query plans would look like, and why they weren’t chosen.
Sometimes it’s cardinality estimation, sometimes it’s costing, sometimes there was an optimization timeout, and other times…
Msg 8622, Level 16, State 1, Line 20
Query processor could not produce a query plan because of the hints defined in this query. Resubmit the query without specifying any hints and without using SET FORCEPLAN.
Because, you know, you can’t always get what you want.
Problem Statement
When you’re dealing with untouchable vendor code full of mistakes, ORM queries that God has turned away from, and other queries that for some reason can’t be tinkered with, we used to not have a lot of options.
This is going to be a game changer in a lot of cases, because you can hint all sorts of useful changes to queries that would otherwise be stuck forever in their current hell.
Of course, not everything is supported. How could it all be? That would be insane.
According to the docs, here’s what’s supported currently:
These query hints are supported as Query Store hints:
This is where things get… tough. There aren’t any super-important query hints missing, but not being able to use ANY table hints is bad news for a number of reasons.
Duck Hint
Included in the potential table hints are all these delights:
WITH ( <table_hint> [ [, ]…n ] )
<table_hint> ::=
{ NOEXPAND [ , INDEX ( <index_value> [ ,…n ] ) | INDEX = ( <index_value> ) ]
| INDEX ( <index_value> [ ,…n ] ) | INDEX = ( <index_value> )
No index hints, no locking hints, no isolation level hints, no access method hints, and… no NOEXPAND hint 😭
The prior being made even more aggravating because EXPAND VIEWS is a query hint.
No one ever expands indexed views.
Gridlock
This feature has me pretty excited for SQL Server 2022. In particular for Entity Framework queries, I can see myself using:
FORCE ORDER
NO_PERFORMANCE_SPOOL
RECOMPILE
Maybe even all together. The more the merrier! Like beans.
I do hope that at some point there is a workaround for some of the table hints getting used, but in 4 years when folks finally start adopting this newfangled version, I’ll have a grand time fixing problems that used to be out of my reach.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
SQL Server 2022 has a new feature in it to help with parameter sensitive query plans.
That is great. Parameter sensitivity, sometimes just called parameter sniffing, can be a real bear to track down, reproduce, and fix.
In a lot of the client work I do, I end up using dynamic SQL like this to get things to behave:
But with this new feature, you get some of the same fixes without having to interfere with the query at all.
How It Works
You can read the full documentation here. But you don’t read the documentation, and the docs are missing some details at the moment anyway.
It only works on equality predicates right now
It only works on one predicate per query
It only gives you three query plan choices, based on stats buckets
There’s also some additional notes in the docs that I’m going to reproduce here, because this is where you’re gonna get tripped up, if your scripts associate statements in the case with calling stored procedures, or using object identifiers from Query Store.
For each query variant mapping to a given dispatcher:
The query_plan_hash is unique. This column is available in sys.dm_exec_query_stats, and other Dynamic Management Views and catalog tables.
The plan_handle is unique. This column is available in sys.dm_exec_query_stats, sys.dm_exec_sql_text, sys.dm_exec_cached_plans, and in other Dynamic Management Views and Functions, and catalog tables.
The query_hash is common to other variants mapping to the same dispatcher, so it’s possible to determine aggregate resource usage for queries that differ only by input parameter values. This column is available in sys.dm_exec_query_stats, sys.query_store_query, and other Dynamic Management Views and catalog tables.
The sql_handle is unique due to special PSP optimization identifiers being added to the query text during compilation. This column is available in sys.dm_exec_query_stats, sys.dm_exec_sql_text, sys.dm_exec_cached_plans, and in other Dynamic Management Views and Functions, and catalog tables. The same handle information is available in the Query Store as the last_compile_batch_sql_handle column in the sys.query_store_query catalog table.
The query_id is unique in the Query Store. This column is available in sys.query_store_query, and other Query Store catalog tables.
The problem is that, sort of like dynamic SQL, this makes each different plan/statement impossible to tie back to the procedure.
What I’ve Tried
Here’s a procedure that is eligible for parameter sensitivity training:
CREATE OR ALTER PROCEDURE
dbo.SQL2022
(
@ParentId int
)
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
SELECT TOP (10)
u.DisplayName,
p.*
FROM dbo.Posts AS p
JOIN dbo.Users AS u
ON p.OwnerUserId = u.Id
WHERE p.ParentId = @ParentId
ORDER BY u.Reputation DESC;
END;
GO
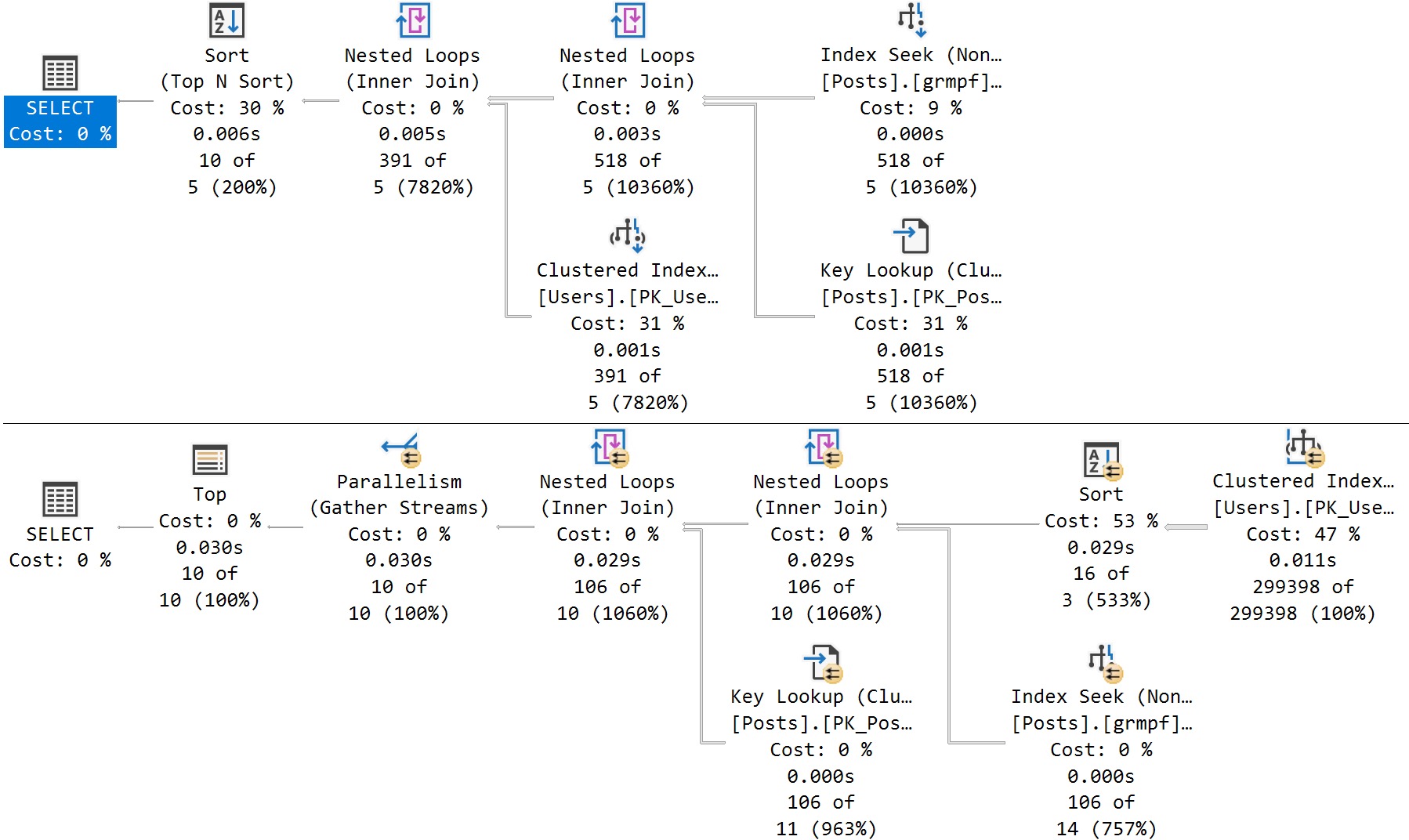
Here’s the cool part! If I run this stored procedure back to back like so, I’ll get two different query plans without recompiling or writing dynamic SQL, or anything else:
EXEC dbo.SQL2022
@ParentId = 184618;
GO
EXEC dbo.SQL2022
@ParentId = 0;
GO
amazing!
It happens because the queries look like this under the covers:
SELECT TOP (10)
u.DisplayName,
p.*
FROM dbo.Posts AS p
JOIN dbo.Users AS u
ON p.OwnerUserId = u.Id
WHERE p.ParentId = @ParentId
ORDER BY u.Reputation DESC
OPTION (PLAN PER VALUE(QueryVariantID = 1, predicate_range([StackOverflow2010].[dbo].[Posts].[ParentId] = @ParentId, 100.0, 1000000.0)))
SELECT TOP (10)
u.DisplayName,
p.*
FROM dbo.Posts AS p
JOIN dbo.Users AS u
ON p.OwnerUserId = u.Id
WHERE p.ParentId = @ParentId
ORDER BY u.Reputation DESC
OPTION (PLAN PER VALUE(QueryVariantID = 3, predicate_range([StackOverflow2010].[dbo].[Posts].[ParentId] = @ParentId, 100.0, 1000000.0)))
Where Things Break Down
Normally, sp_BlitzCache will go through whatever statements it picks up and associate them with the parent object:
But it doesn’t do that here, it just says that they’re regular ol’ statements:
do i know you?
The way that it attempts to identify queries belonging to objects is like so:
RAISERROR(N'Attempting to get stored procedure name for individual statements', 0, 1) WITH NOWAIT;
UPDATE p
SET QueryType = QueryType + ' (parent ' +
+ QUOTENAME(OBJECT_SCHEMA_NAME(s.object_id, s.database_id))
+ '.'
+ QUOTENAME(OBJECT_NAME(s.object_id, s.database_id)) + ')'
FROM ##BlitzCacheProcs p
JOIN sys.dm_exec_procedure_stats s ON p.SqlHandle = s.sql_handle
WHERE QueryType = 'Statement'
AND SPID = @@SPID
OPTION (RECOMPILE);
Since SQL handles no longer match, we’re screwed. I also looked into doing something like this, but there’s nothing here!
SELECT
p.plan_handle,
pa.attribute,
object_name =
OBJECT_NAME(CONVERT(int, pa.value)),
pa.value
FROM
(
SELECT 0x05000600B7F6C349E0824C498D02000001000000000000000000000000000000000000000000000000000000 --Proc plan handle
UNION ALL
SELECT 0x060006005859A71BB0304D498D02000001000000000000000000000000000000000000000000000000000000 --Query plan handle
UNION ALL
SELECT 0x06000600DCB1FC11A0224D498D02000001000000000000000000000000000000000000000000000000000000 --Query plan handle
) AS p (plan_handle)
CROSS APPLY sys.dm_exec_plan_attributes (p.plan_handle) AS pa
WHERE pa.attribute = 'objectid';
The object identifiers are 0 for these two queries.
One Giant Leap
This isn’t a complaint as much as it is a warning. If you’re a monitoring tool vendor, script writer, or script relier, this is gonna make things harder for you.
Perhaps it’s something that can or will be fixed in a future build, but I have no idea at all what’s going to happen with it.
Maybe we’ll have to figure out a different way to do the association, but stored procedures don’t get query hashes or query plan hashes, only the queries inside it do.
This is gonna be a tough one!
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Well, okay. But we can try to get it working on our own. Usually I use this method to figure out what parameters a new thing requires to run.
Not this time!
Trial And Error
What I usually do is stick NULL or DEFAULT after the EXEC to to see what comes back. Sometimes using a number or something makes sense too, but whatever.
This at least helps you figure out:
Number of parameters
Expected data types
Parameter NULLability
Etc. and whenceforth
Eventually, I figured out that sp_copy_data_in_batches requires two strings, and that it expects those strings to exist as tables.
The final command that ended up working was this. Note that there is no third parameter at present to specify a batch size.
sp_copy_data_in_batches
N'dbo.art',
N'dbo.fart';
Path To Existence
This, of course, depends on two tables existing that match those names.
CREATE TABLE dbo.art(id int NOT NULL PRIMARY KEY);
CREATE TABLE dbo.fart(id int NOT NULL PRIMARY KEY);
One thing to note here is that you don’t need a primary key to do this, but the table definitions do need to match exactly or else you’ll get this error:
Msg 37486, Level 16, State 2, Procedure sp_copy_data_in_batches, Line 1 [Batch Start Line 63]
'sp_copy_data_in_batches' failed because column 'id' does not have the same collation,
nullability, sparse, ANSI_PADDING, vardecimal, identity or generated always attribute, CLR type
or schema collection in tables '[dbo].[art]' and '[dbo].[fart]'.
Because GENERATE_SERIES is still a bit rough around the edges, I’m gonna do this the old fashioned way, which turns out a bit faster.
INSERT
dbo.art WITH(TABLOCK)
(
id
)
SELECT TOP (10000000)
id =
ROW_NUMBER() OVER
(
ORDER BY 1/0
)
FROM sys.messages AS m
CROSS JOIN sys.messages AS m2;
Behind The Scenes
I sort of expected to run some before and after stuff, and see the count slowly increment, but the query plan for sp_copy_data_in_batches just showed this:
wink wink
I’m not really sure what the batching is here.
Also, this is an online index operation, so perhaps it won’t work in Standard Edition. If there even is a Standard Edition anymore?
Has anyone heard from Standard Edition lately?
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
These table valued functions of the built-in variety have this problem.
This one is no exception. Well, it does throw an exception. But you know.
That’s not exceptional.
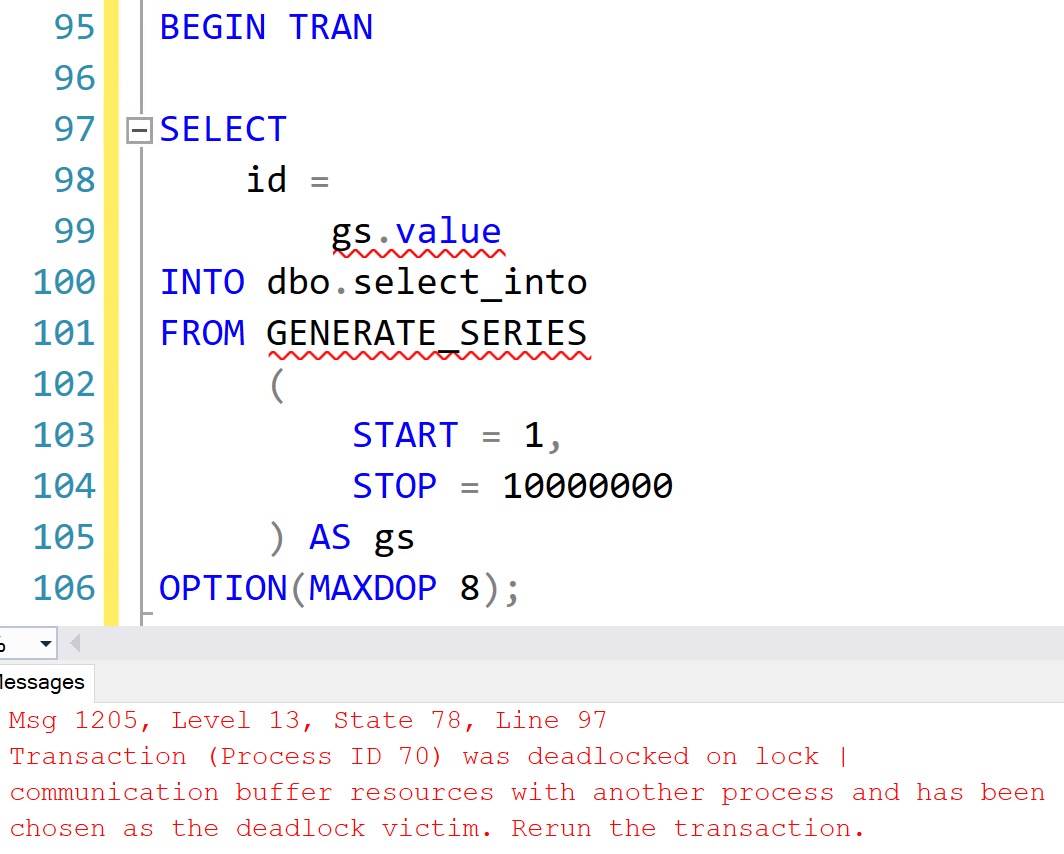
DROP TABLE IF EXISTS
dbo.select_into;
BEGIN TRAN
SELECT
id =
gs.value
INTO dbo.select_into
FROM GENERATE_SERIES
(
START = 1,
STOP = 10000000
) AS gs
OPTION(MAXDOP 8);
COMMIT;
If you run the above code, you’ll get this error:
Msg 1205, Level 13, State 78, Line 105
Transaction (Process ID 70) was deadlocked on lock | communication buffer resources with another process and has been chosen as the deadlock victim. Rerun the transaction.
pilot program
Like the issues I outlined in yesterday’s post, I do hope these get fixed before go-live.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
It’s the first public CTP. Things will change. Things will get better. Think about the rich history of Microsoft fixing stuff immediately, like with adding an ordinal position to STRING_SPLIT.
That came out in SQL Server 2016, and uh… Wait, they just added the ordinal position in SQL Server 2022. There were two major versions in between that function getting released and any improvements.
With that in mind, I’m extending as much generosity of spirit to improvements to the function at hand: GENERATE_SERIES.
In this post, I want to go over some of the disappointing performance issues I found when testing this function out.
Single Threaded In A Parallel Plan
First up, reading streaming results from the function is single threaded. That isn’t necessarily bad on its own, but can result in annoying performance issues when you have to distribute a large number of rows.
If you have to ask what the purpose or use case for 10 million rows is, it’s your fault that SQL Server doesn’t scale.
Got it? Yours, and yours alone.
DROP TABLE IF EXISTS
dbo.art_aux;
CREATE TABLE
dbo.art_aux
(
id int NOT NULL PRIMARY KEY CLUSTERED
);
The first way we’re going to try this is with a simple one column table that has a primary key/clustered index on it.
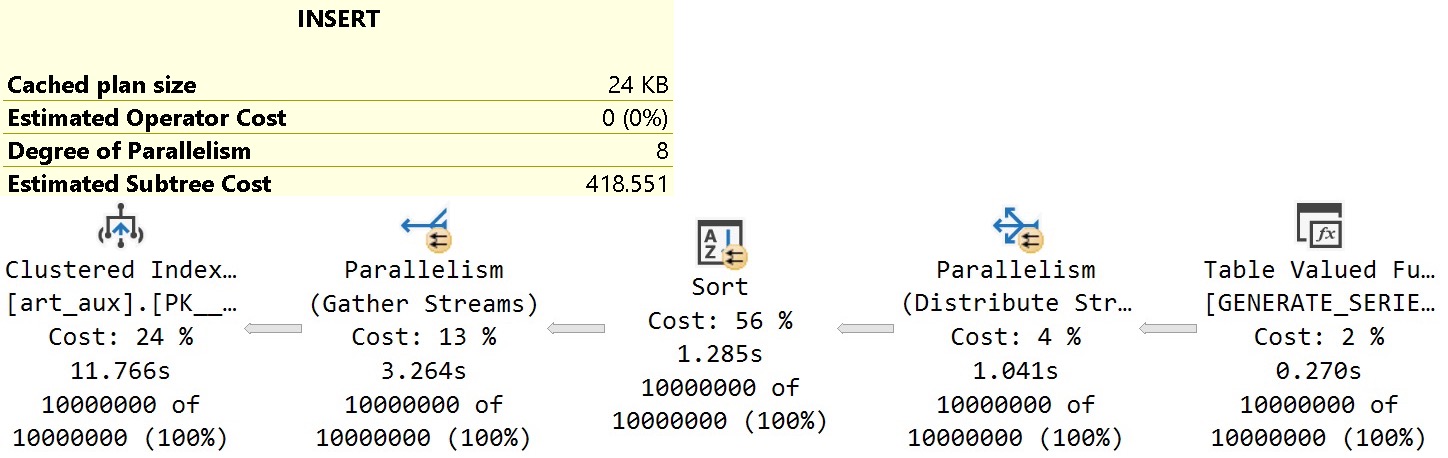
INSERT INTO
dbo.art_aux WITH(TABLOCK)
(
id
)
SELECT
gs.value
FROM GENERATE_SERIES
(
START = 1,
STOP = 10000000
) AS gs
OPTION(MAXDOP 8);
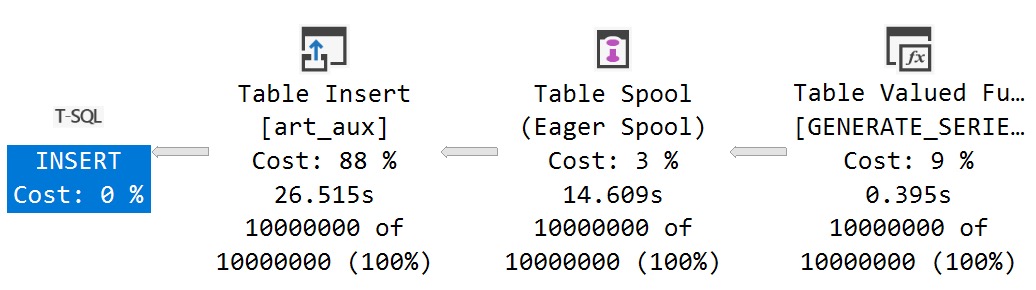
The query plan for this insert looks about like so:
sup with that
I’m only including the plan cost here to compare it to the serial plan later, and to understand the per-operator cost percentage breakdown.
It’s worth noting that the Distribute Streams operator uses Round Robin partitioning to put rows onto threads. That seems an odd choice here, since Round Robin partitioning pushes packets across exchanges.
For a function that produces streaming integers, it would make more sense to use Demand partitioning which only pulls single rows across exchanges. Waiting for Round Robin to fill up packets with integers seems a poor choice, here.
Then we get to the Sort, which Microsoft has promised to fix in a future CTP. Hopefully that happens! But it may not help with the order preserving Gather Streams leading up to the Insert.
preservatives
It seems a bit odd ordered data from the Sort would hamstring the Gather Streams operator’s ability to do its thing, but what do I know?
I’m just a bouncer, after all.
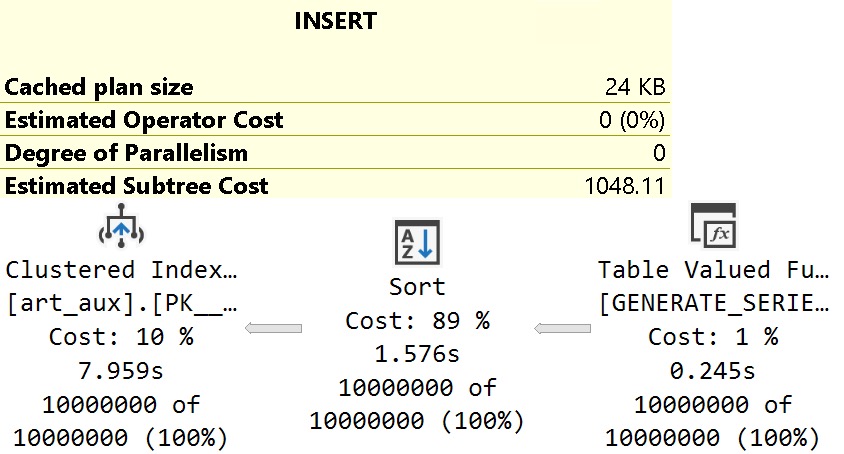
But The Serial Plan
Using the same setup, let’s make that plan run at MAXDOP 1.
INSERT INTO
dbo.art_aux WITH(TABLOCK)
(
id
)
SELECT
gs.value
FROM GENERATE_SERIES
(
START = 1,
STOP = 10000000
) AS gs
OPTION(MAXDOP 1);
You might expect this to run substantially slower to generate and insert 10,000,000 rows, but it ends up being nearly three full seconds faster.
Comparing the query cost here (1048.11) vs. the cost of the parallel plan above (418.551), it’s easy to understand why a parallel plan was chosen.
It didn’t work out so well, though, in this case.
cereal
With no need to distribute 10,000,000 rows out to 8 threads, sort the data, and then gather the 8 threads back to one while preserving that sorted order, we can rely on the serial sort operator to produce and feed rows in index-order to the table.
Hopefully that will continue to be the case once Microsoft addresses the Sort being present there in the first place. That would knock a second or so off the the overall runtime.
Into A Heap
Taking the index out of the picture and inserting into a heap does two things:
But it also… Well, let’s just see what happens. And talk about it. Query plans need talk therapy, too. I’m their therapist.
DROP TABLE IF EXISTS
dbo.art_aux;
CREATE TABLE
dbo.art_aux
(
id int NOT NULL
);
hmmmmm
The Eager Table Spool here is for halloween protection, I’d wager. Why we need it is a bit of a mystery, since we’re guaranteed to get a unique, ever-increasing series of numbers from the function. On a single thread.
Performance is terrible here because spooling ten million rows is an absolute disaster under any circumstance.
With this challenge in mind, I tried to get a plan here that would go parallel and avoid the spool.
Well, mission accomplished. Sort of.
Crash And Burn
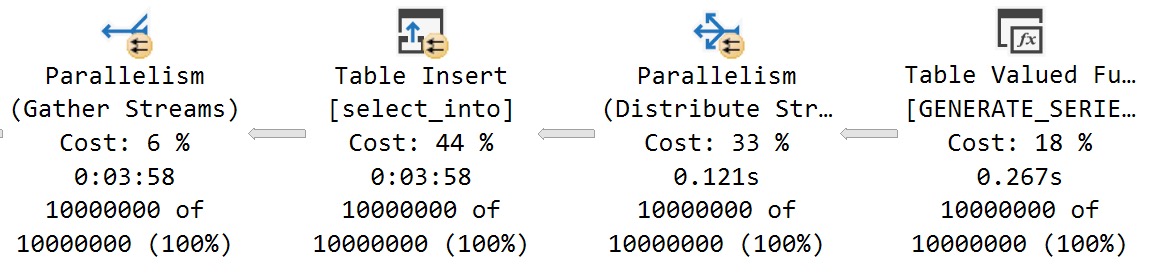
One thing we can do is use SELECT INTO rather than relying on INSERT SELECT WITH (TABLOCK) to do try to get it. There are many restrictions on the latter method.
SELECT
id =
gs.value
INTO dbo.select_into
FROM GENERATE_SERIES
(
START = 1,
STOP = 10000000
) AS gs
OPTION(MAXDOP 8);
This doesn’t make things better:
four minutes!
This strategy clearly didn’t work out.
Bummer.
Again, I’d say most of the issue is from Round Robin partitioning on the Distribute Streams.
Finish Him
The initial version of GENERATE_SERIES is a bit rough around the edges, and I hope some of these issues get fixed.
And, like, faster than issues with STRING_SPLIT did, because it took a really long time to get that worked on.
And that was with a dozen or so MVPs griping about it the whole time.
But there’s an even bigger problem with it that we’ll look at tomorrow, where it won’t get lost in all this stuff.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
You can normally eyeball a query to find things that generally don’t agree with performance out of the box, like:
Functions (inline ones aside)
Table variables
Stacked Common Table Expressions
Non-SARGable predicates
Overly complicated queries
Insert a million other things here
But of course, the more complicated queries are, or the more layers of abstraction exist in a query, the harder this stuff is to spot quickly. Particularly with views, and nested views, bad ideas can be buried many layers deep in the sediment.
I call it sediment because code often looks like geologic layers, where you can tell who wrote what and when based on style and techniques that got used.
And to vendors who encrypt their god-awful code: �
The Great Untangling
Getting through that untangling can be a costly and time consuming process, depending on the level of damage done over the years, and the desired outcome. Sometimes it’s easier to rewrite everything from scratch than to do in-place rewrites of existing objects.
It’s obviously worth exploring enhancements in newer versions of SQL Server that may power things across the finish line:
Perhaps the new cardinality estimator does more good than harm
Batch Mode On Row Store does a lot of good with bad code
Scalar UDF Inlining can solve a lot of function problems
There are many other general and targeted improvements that might help your workload without code changes. Hopefully that continues with SQL Server 2022.
On top of the workload improvements, new versions also provide improved insights into problems via dynamic management views, Query Store, logging, and more.
If you’re not on at least SQL Server 2016 right now, you’re leaving a whole lot on the table as far as this goes.
Hiring Issues
It’s tough for smaller companies to attract full time talent to fix huge backlogs of issues across SQL Server stored procedures, functions, views, index and table design, and all that.
Or even harder, convert ORM queries into sensible stored procedures, etc. when you start hitting performance limitations in the single-query model.
First, I need acknowledge that not everyone wants to work for a huge company. Second, I need to acknowledge that salary isn’t everything to everyone.
But let’s assume that a smaller company want to hire someone in competition with a larger company. What can they offer when they run out of salary runway, and can’t match equity?
Clear career paths/Upward mobility
Flexible schedules
Paid time off for training
Covering the costs of training and certifications
Focusing on employee growth (not just sticking them in a corner to monkey with the same thing for years)
Quality of company culture (meeting overload was something I got a lot of DMs about)
Conference travel budgets
Meaningful company mission
Introducing tech savvy folks to the business side of things
Recognizing that not every employee wants to be an On-callogist
There were more, but these were the things I got the most hits from folks on. Having these doesn’t mean you can expect someone to take 20-30% less on the salary front, of course, but if you’re close to another offer these things might sway folks to your side.
Far and away, what I took from responses is that folks want to feel effective; like they can make a difference without a lot of bureaucracy and red tape. Get the hell out of my way, to coin a phrase.
Finder’s Fee
When it comes to attracting people to your company — think of it as your employer SEO — the SQL Server community is a great place to start.
If you want to try something for free, keep an eye out for when Brent posts to find out Who’s Hiring In The Database Community. It doesn’t cost you anything, but you have to keep on top of the posts and replies, and make sure you have good job description that sticks out.
If you have any location-based requirements for your candidates, try sponsoring a local SQL Server user group’s meetings for a few months. There may be a small, nominal fee if it’s entirely virtual. If it’s in-person, you’ll foot the bill for dozen or so pizza pies for attendees. That usually gets you an announcement before and after whatever speaker is presenting. It’s totally fair to ask for attendance numbers. Keeping on with that, consider sponsoring a SQL Saturday event. These typically have a deeper reach than a monthly user group, since there are more attendees in a concentrated area. You may get a booth, or your logo on slides, and whatever else you can negotiate with the event planners.
If you’re okay with spending more money for a lot of eyeballs, larger events like PASS Summit, and SQLBits are annual conferences with thousands of attendees. As a FYI, these are the types of conferences whomever you hire is probably going to want to attend, too.
Imagine that.
Askance
I have clients ask me to help them find quality employees for roles from time to time, or to help them interview folks they’ve farmed themselves.
Normally I’m happy to help on either front, and leave sealing the deal to them. I think from now on I’m gonna point them to this post, so they have some better ideas about how to put a stamp on things.
Not every company can offer everything, but as large companies continue to gobble up smaller ones, and Microsoft in particular keeps fishing folks out of the MVP pool, it’s going to be harder for those who remain to stay competitive. At least I think so: I haven’t quite been persuaded that there will be a coomba ya moment where everyone gets sick of the MegaCorp grind and goes back to mom and pop shops to reclaim their lost souls.
After all, a lot of folks do have their sights set on retirement. High salaries and generous equity (well, maybe not equity as the market is currently behaving) certainly help get them there faster.
That’s part of the picture that you can’t easily ignore, along with the oft-proferred wisdom that the only way to stay on a competitive salary track is to change jobs every 2-3 years.
Retention is going to get more difficult for everyone across the board, but the revolving door will largely let out with the bigger players who can afford to keep it spinning.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.