I Apologize
I’ve been working with CDC and CT way too much, and even I’m annoyed with how much it’s coming out in blog posts.
I’m going to cover a lot of ground quickly here. If you get lost, or there’s something you don’t understand, your best bet is to reference the documentation to get caught up.
The idea of this post is to show a few different concepts at once, with one final goal:
- How to see if a specific column was updated
- How to get just the current change information about a table
- How to add information about user and time modified
- How to add information about which proc did the modification
The first thing we’re gonna do is get set up.
ALTER DATABASE Crap
SET CHANGE_TRACKING = ON;
GO
USE Crap;
GO
--Bye Bye
DROP TABLE IF EXISTS dbo.user_perms;
--Oh, hello
CREATE TABLE dbo.user_perms
(
permid int,
userid int,
permission varchar(20),
CONSTRAINT pu PRIMARY KEY CLUSTERED (permid)
);
--Turn on CT first this time
ALTER TABLE dbo.user_perms
ENABLE CHANGE_TRACKING
WITH (TRACK_COLUMNS_UPDATED = ON);
With that done, let’s stick some rows in the table, and see what we have for changes.
--Insert some rows
INSERT
dbo.user_perms(permid, userid, permission)
SELECT
x.c,
x.c,
CASE WHEN x.c % 2 = 0
THEN 'db_datareader'
ELSE 'sa'
END
FROM
(
VALUES (1),(2),(3),(4),(5),
(6),(7),(8),(9),(10)
) AS x(c);
--What's in the table?
SELECT
cc.*
FROM dbo.user_perms AS cc
--What's in Change Tracking?
SELECT
ct.*
FROM CHANGETABLE(CHANGES dbo.user_perms, 0) AS ct;
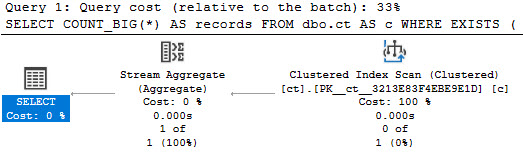
This is what the output look like:
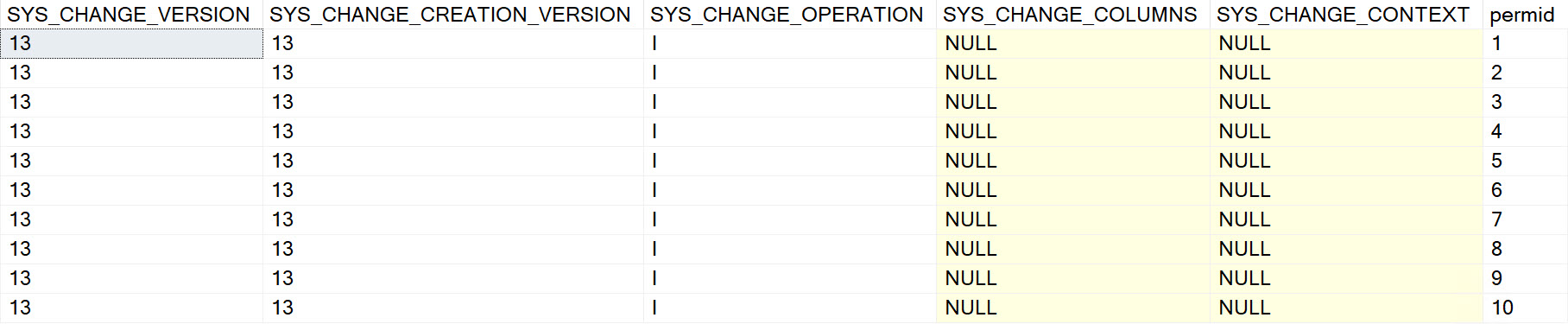
What Changed?
To find this out, we need to look at CHANGE_TRACKING_IS_COLUMN_IN_MASK, but there’s a caveat about this: it only shows up if you look at specific versions of the changed data. If you just pass null or zero into CHANGETABLE, you won’t see that.
Let’s update and check on some things.
--Update one row, change it to 'sa'
UPDATE up
SET up.permission = 'sa'
FROM dbo.user_perms AS up
WHERE up.permid = 2;
--No update?
SELECT
ct.*
FROM CHANGETABLE(CHANGES dbo.user_perms, NULL) AS ct;
--No update?
SELECT
ct.*
FROM CHANGETABLE(CHANGES dbo.user_perms, 0) AS ct;
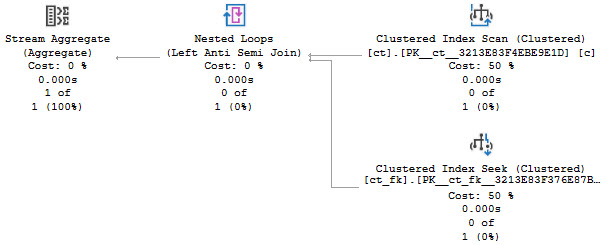
We updated a row, but if we look at the wrong version, we won’t see the change:

But we will see that permid = 2 has a different change version than the rest of the rows.
Zooming In
If we want to see the version of things with our change, we need to figure out the current version change tracking has stored. This is database-level, but it’s also… wrong.
But to start us off, we query CHANGE_TRACKING_CURRENT_VERSION.
The max version always seems to be one version too high. Doing this will return nothing from CHANGETABLE:
--No update?
DECLARE @ctcv bigint = (SELECT CHANGE_TRACKING_CURRENT_VERSION());
SELECT @ctcv AS CHANGE_TRACKING_CURRENT_VERSION;
SELECT
ct.*
FROM CHANGETABLE(CHANGES dbo.user_perms, @ctcv) AS ct;
GO
To get data back that we care about, we need to do advanced maths and subtract 1 from the current version.
--No update?
DECLARE @ctcv bigint =
(SELECT CHANGE_TRACKING_CURRENT_VERSION() -1);
SELECT @ctcv AS CHANGE_TRACKING_CURRENT_VERSION;
SELECT
ct.*,
CHANGE_TRACKING_IS_COLUMN_IN_MASK
(COLUMNPROPERTY(OBJECT_ID('dbo.user_perms'),
'permission',
'ColumnId'),
ct.SYS_CHANGE_COLUMNS) AS is_permission_column_in_mask
FROM CHANGETABLE(CHANGES dbo.user_perms, @ctcv) AS ct;

This is also when we need to bring in CHANGE_TRACKING_IS_COLUMN_IN_MASK to figure out if the permission column was updated.
Audacious
The next thing we’ll wanna do is tie an update to a particular user. We can do that with CHANGE_TRACKING_CONTEXT.
As a first example, let’s just get someone’s user name when they run an update.
--Update one row, change it to 'sa'
DECLARE @ctc varbinary(128) =
(SELECT CONVERT(varbinary(128), SUSER_NAME()));
WITH CHANGE_TRACKING_CONTEXT (@ctc)
UPDATE up
SET up.permission = 'sa'
FROM dbo.user_perms AS up
WHERE up.permid = 4;
To validate things a little, we’re gonna join the results of the CHANGETABLE function to the base table.
SELECT
up.permid,
up.userid,
up.permission,
ct.SYS_CHANGE_VERSION,
ct.SYS_CHANGE_OPERATION,
CONVERT(sysname, ct.SYS_CHANGE_CONTEXT) as 'SYS_CHANGE_CONTEXT'
FROM CHANGETABLE (CHANGES dbo.user_perms, 0) AS ct
LEFT OUTER JOIN dbo.user_perms AS up
ON ct.permid = up.permid;

We get sa back from SYS_CHANGE_CONTEXT, so that’s nice. But we’re doing this a bit naively, because the SYS_CHANGE_OPERATION column is telling us that sa inserted that row.
That’s… technically wrong. But it’s wrong because we’re looking at the wrong version. This solution definitely isn’t perfect unless you really only dig into the most recent rows. Otherwise, you might blame the wrong person for the wrong thing.
Let’s add a little more information in, and get the right row out. We’re gonna go a step further and add a date to the context information.
--Update one row, change it to 'sa'
DECLARE @ctc varbinary(128) =
(SELECT CONVERT(varbinary(128),
'User: ' +
SUSER_NAME() +
' @ ' +
CONVERT(varchar(30), SYSDATETIME())) );
WITH CHANGE_TRACKING_CONTEXT (@ctc)
UPDATE up
SET up.permission = 'sa'
FROM dbo.user_perms AS up
WHERE up.permid = 6;
DECLARE @ctcv bigint =
(SELECT CHANGE_TRACKING_CURRENT_VERSION() -1);
SELECT @ctcv AS CHANGE_TRACKING_CURRENT_VERSION;
SELECT
up.permid,
up.userid,
up.permission,
ct.SYS_CHANGE_VERSION,
ct.SYS_CHANGE_CREATION_VERSION,
ct.SYS_CHANGE_OPERATION,
ct.SYS_CHANGE_COLUMNS,
CONVERT(sysname, ct.SYS_CHANGE_CONTEXT) as 'SYS_CHANGE_CONTEXT'
FROM CHANGETABLE (CHANGES dbo.user_perms, @ctcv) AS ct
LEFT OUTER JOIN dbo.user_perms AS up
ON ct.permid = up.permid;
GO

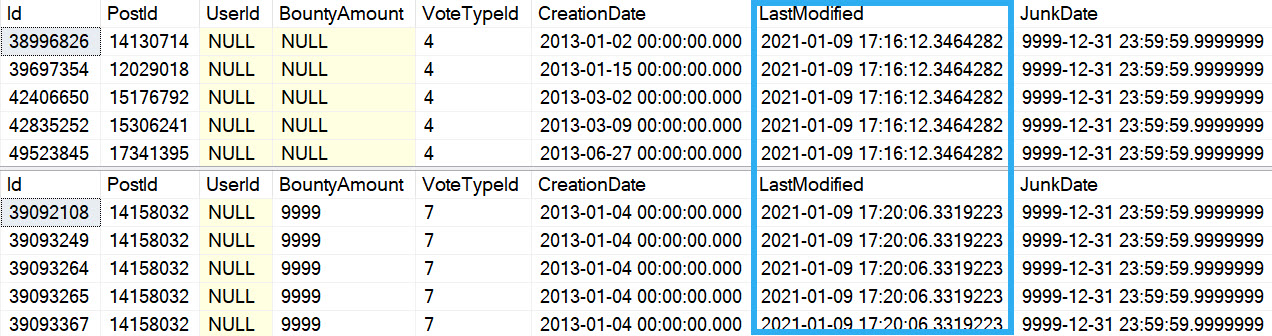
Cool! Now we have the right operation, and some auditing information correctly associated with it.
Proc-nosis Negative
To add in one more piece of information, and tie things all together, we’re going to add in a stored procedure name. You could do this with a string if you wanted to identify app code, too. Just add something in like Query: dimPerson or whatever you want to call the section of code generated the update.
CREATE OR ALTER PROCEDURE dbo.ErikIsSickOfChangeTracking
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
DECLARE @ctc varbinary(128) =
(SELECT CONVERT(varbinary(128),
'User: ' +
SUSER_NAME() +
' @ ' +
CONVERT(varchar(30), SYSDATETIME()) +
' with ' +
OBJECT_NAME(@@PROCID)) );
WITH CHANGE_TRACKING_CONTEXT (@ctc)
UPDATE up
SET up.permission = 'sa'
FROM dbo.user_perms AS up
WHERE up.permid = 8;
DECLARE @ctcv bigint =
(SELECT CHANGE_TRACKING_CURRENT_VERSION() -1);
SELECT @ctcv AS CHANGE_TRACKING_CURRENT_VERSION;
SELECT
up.permid,
up.userid,
up.permission,
ct.SYS_CHANGE_VERSION,
ct.SYS_CHANGE_CREATION_VERSION,
ct.SYS_CHANGE_OPERATION,
CHANGE_TRACKING_IS_COLUMN_IN_MASK
(COLUMNPROPERTY(OBJECT_ID('dbo.user_perms'),
'permission',
'ColumnId'),
ct.SYS_CHANGE_COLUMNS) AS is_column_in_mask,
ct.SYS_CHANGE_COLUMNS,
CONVERT(sysname, ct.SYS_CHANGE_CONTEXT) as 'SYS_CHANGE_CONTEXT'
FROM CHANGETABLE (CHANGES dbo.user_perms, @ctcv) AS ct
LEFT OUTER JOIN dbo.user_perms AS up
ON ct.permid = up.permid;
END;
EXEC dbo.ErikIsSickOfChangeTracking;
Which will give us…

It’s Over
I don’t think I have anything else to say about Change Tracking right now.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.