A while back, I wrote a bunch of posts about things I’d like to see vNext take care of. In this post, since it’s Friday and I don’t wanna do anything, will round those up and cover whether or they made it in or not.
Well, maybe I’ll need to update the list for future releases of SQL Server 2022.
Hmpf.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
This setting doesn’t get enough credit for all the good it does. Part of me thinks it should be the default for new SQL Server installs, if the amount of memory in the server is over a certain number, and max server memory is set to match.
You may not want it turned on only based on physical memory, because there are lunatics out there who stack SQL Server installs, and who install all sorts of other dimwitted things on there, too.
But since max server memory is a suggestion during setup, and perform volume maintenance tasks is included, this should be as well.
Again, it’s one less post-install step for automation-minded folks out there.
Burden
SQL Servers with large amounts of memory can especially benefit from this setting, because it allows them to access memory via a different API. The easy way to think of it is that SQL Server will get direct access to physical memory, instead of virtual memory.
Allocates physical memory pages to be mapped and unmapped within any Address Windowing Extensions (AWE) region of a specified process.
The AllocateUserPhysicalPages function is used to allocate physical memory that can later be mapped within the virtual address space of the process. The SeLockMemoryPrivilege privilege must be enabled in the caller’s token or the function will fail with ERROR_PRIVILEGE_NOT_HELD.
I generally advise people with good chunks of memory to enable this setting. There are very few good reasons not to on big boxes, and that’s why it should be called out in the installation process. Enabling it later means rebooting, and that sucks.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Unless you’re running a data warehouse, I can’t think of a good reason to leave this at the default (5) for most any workload.
Look at any SQL Server setup checklist not written by SharePoint admins, and you’ll see people tell you to change this setting to something higher than 5.
What you change it to is not what I’m here to talk about. I’m Team Start With 50, but you can be whatever team you want and we can still be friends.
I mean, unless you’re going to tell me I should look at the plan cache to figure that out, then we are mortal enemies because you are full of shabby ideas. The plan cache is full of lies and bad estimates, and totally unreliable in the long term.
You could probably make better guesses based on Query Store, but Cost Threshold For Parallelism is, unfortunately, not a database-level setting, and they’d still just be guesses. About estimates. So, you know… Cool your jets, hotshot.
But since MAXDOP is not only available, but also offers guidance for a correct setting to the installer, why not this one? It is, after all, an important counterpart.
If anything, it’d be nice to give folks who care about automation one less post-setup step to handle. To me, that’s a glaring omission.
Costy Things
Of course, maybe it’s time to get Cost Threshold For Parallelism some help. Cost is, after all, just a reference metric.
It can be good, it can be bad. High cost plans can run fast, low cost plans can run slow.
With all the intelligent stuff being built into the product, perhaps it’s time for it to consider things in addition to plan cost for whether a query is eligible for parallelism or not.
Imagine this scenario: You set Cost Threshold For Parallelism to 50, and a really important query that costs 20 query bucks comes along and runs slowly and single threaded every single time it executes. It never stands a chance at going parallel, unless you drop Cost Threshold For Parallelism way low for the whole server.
Your only option other than lowering Cost Threshold For Parallelism is using an unsupported trace flag (8649), or an unsupported USE hint (ENABLE_PARALLEL_PLAN_PREFERENCE).
It sure would be nice if there were a supported override that you could set, say a maximum CPU threshold for a serial plan. I don’t think you could change this in flight, but you could potentially have it act like memory grant feedback, and adjust between executions.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
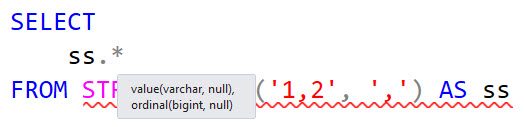
In 2016, we got the STRING_SPLIT function. That was nice, because prior implementations had a lot of problems
But out of the gate, everyone looked at what we got and couldn’t figure why this would drop without a column to tell you the position of each element in the string.
Recently I updated SSMS to 18.10, and went to work on a couple scripts that use STRING_SPLIT.
I was immediately confronted by a bunch of RED SQUIGGLY LINES.
Why?
Not Yet But Soon
Huh.
reminder
Insufficient! You’re insufficient!
stones
Oh, enable_ordinal. Neat.
selected
At least it’s a bigint.
get it
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
This is my 50th blog post! I’m going to do something a bit special.
The Error Log
I’ve found the SQL Server error log to be slightly underrated as a source of useful information for how your SQL Server instance is doing. It’s true that it’s easy to find yourself in a situation where the applications write tens of thousands of failed login messages per day, but if you can get past that, SQL Server might be telling you important stuff that you really need to know about. Examples that I’ve seen:
Memory dumps
non-yielding schedulers
long I/Os
latch timeouts
Maybe this an odd thing to do, but I’ve personally set up alerting to get an email whenever SQL Server writes something to the error log. Naturally I filter out a lot of benign and informational messages. This kind of alerting is useful because let’s face it, using SSMS to open the error log isn’t always the fastest operation in the world. And who even knows if Azure Data Studio can be used to view the error log?
What’s in your error log?
If you haven’t checked your error log in a while, I challenge you to do so on your next working day. You never know what you’ll find. I’m happy to share my own, but readers may be confused as I run a custom version of SQL Server:
One tricky thing about working with dynamic SQL is that it’s rather unaccountable. You have a stored procedure, you build up a string, you execute it, and no one wants to claim responsibility.
Like a secret agent, or an ugly baby.
It would be nice if sp_executesql had an additional parameter to assign an object id to the code block so that when you’re looking at the plan cache or Query Store, you know immediately where the query came from.
Here’s an example.
A Contempt
Let’s use this as an example:
CREATE OR ALTER PROCEDURE dbo.dynamo
AS
SET NOCOUNT, XACT_ABORT ON;
BEGIN
DECLARE
@sql nvarchar(MAX) = N'';
SELECT TOP (1)
b.*
FROM dbo.Badges AS b
WHERE b.UserId = 22656
ORDER BY b.Date DESC
SELECT
@sql = N'
/*dbo.dynamo*/
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON p.OwnerUserId = u.Id;
';
EXEC sys.sp_executesql
@sql;
END;
GO
This is, by all accounts, Properly Written Dynamic SQL™
I know, this doesn’t need to be dynamic SQL, but I don’t need a great example of that to show what I mean. The first query is there to get the procedure to show up anywhere, and the dynamic SQL is there to show you that… dynamic SQL doesn’t show up as associated with the procedure that called it.
EXEC dbo.dynamo;
GO
EXEC sp_QuickieStore
@database_name = 'StackOverflow2013',
@procedure_schema = 'dbo',
@procedure_name = 'dynamo';
GO
twenty minutes
It sure would be nice to know that this procedure executed a whole other query.
A Temp
There’s no great workaround for this, but you can at least get a hint that something else happened if you dump the dynamic SQL results into a temp table.
CREATE OR ALTER PROCEDURE dbo.dynamo_insert
AS
SET NOCOUNT, XACT_ABORT ON;
BEGIN
DECLARE
@sql nvarchar(MAX) = N'';
CREATE TABLE
#results
(
c bigint
);
SELECT TOP (1)
b.*
FROM dbo.Badges AS b
WHERE b.UserId = 22656
ORDER BY b.Date DESC
SELECT
@sql = N'
/*dbo.dynamo*/
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON p.OwnerUserId = u.Id;
';
INSERT
#results WITH(TABLOCK)
(
c
)
EXEC sys.sp_executesql
@sql;
SELECT
r.*
FROM #results AS r
END;
GO
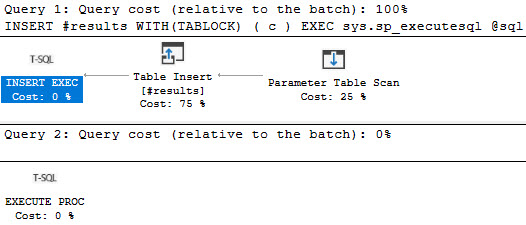
This still sucks though, because we don’t know what the dynamic portion of the query did.
one catch
The query plan looks like this, with no real details or metrics:
break room
A Fix
It would be super if sp_executesql took an additional parameter in the context of a stored procedure that could be assigned to a @@PROCID.
This would avoid all the headless dynamic SQL horsemen running around, and make it easier to locate procedure statements by searching for the procedure that executes them, rather than having to search a bunch of SQL text for a commented procedure name.
Sure, it’s fine if you stumble across dynamic SQL with a comment pointing to the procedure that runs it, but I hardly see anyone doing that.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
The more I work with Standard Edition, the more frustrated I get, and the more I have to tell people about the cost difference between it and Enterprise Edition, the more people start asking me about Postgres.
I wish that were a joke. Or that I knew Postgres better. Or that I knew the PIVOT syntax
(That was a terrible joke)
Mold And Musted
I’ve written about my Standard Edition annoyances in the past:
In the past I’ve thought that offering something between Standard and Enterprise Edition, or add-ons depending on what you’re after would be a good move.
For example, let’s say you want to unlock the memory limit and performance features, or you want the full Availability Group experience, you could buy them for some SA-like tax. But that just… makes licensing more complicated, and it’s already bad enough.
One install, one code base, one set of features, no documentation bedazzled with asterisks.
Perhaps best of all, everyone can stop complaining that Developer Edition is misleading because you can’t turn off Enterprise Edition features.
And you could better line the bits up with that’s in Azure SQL DB and Managed Instances.
Priceline
I have no idea how to handle the pricing, here. Perhaps that could also better line up with Azure offerings as well.
At any rate, something here has to give. Standard Edition is entirely uncompetitive in too many ways, and the price is too far apart from Enterprise Edition to realistically compare. That $5,000 jump per core is quite a jaw-dropper.
One option might be to make Express Edition the new Standard Edition, keeping it free and giving it the limitations that Standard Edition currently has.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Intelligent Query Processing (IQP) is quite a neat set of features. It allows the SQL Server Engine some flexibility in the plans that get used and re-used.
One in-flight example of IQP is the Adaptive Join, where a choice between Hash and Nested Loops Joins can be made at runtime based on a row threshold.
I think that threshold should also apply to serial and parallel plans, too.
Riddled
Right now, SQL Server can downgrade DOP when a server is under CPU pressure. I have a demo of that in this video about sp_PressureDetector.
The query plan will still look like it’s going parallel, but in reality it will only be running on a single thread.
Here’s the thing: I think that should happen more often, and I think it should be based on the same row thresholds that are used for Adaptive Joins.
If a query starts running and
It’s a serial plan, but way more rows start getting processed, DOP should scale up
It’s a parallel plan, but way fewer rows get processed, DOP should scale down
Perhaps the first point could be addressed more aggressively than the second, because it’s far more likely to cause a performance issue, but hey.
Think big.
Ghost Whopper
Queries that process lots of rows are typically the ones that benefit from going parallel.
Eight threads dealing with a million rows a piece will go a lot better than one thread dealing with eight million rows on its own.
This is another important piece of the parameter sniffing puzzle, too. Often I’ll be able to tune queries and indexes so that the same general plan shape is used, but the key difference is a parallel plan still being much better for a large data set.
Right now, I’m a little stuck optimizing for the large value, or using dynamic SQL to get different query plans.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
The thing is that most rewrites are pretty simple, as long as there aren’t two columns fed into it.
For example, there’s not much the optimizer could do about this:
WHERE DATEDIFF(DAY, u.CreationDate, u.LastAccessDate) > 1
But that’s okay, because if you do that you deserve exactly what you get.
Computed columns exist for a reason. Use them.
Whaffle House
Where things get a bit easier is for simpler use cases where constant folding and expression matching can be used to flip predicates around a little bit.
It’s just a little bit of pattern recognition, which the optimizer already does to make trees and apply rules, etc.
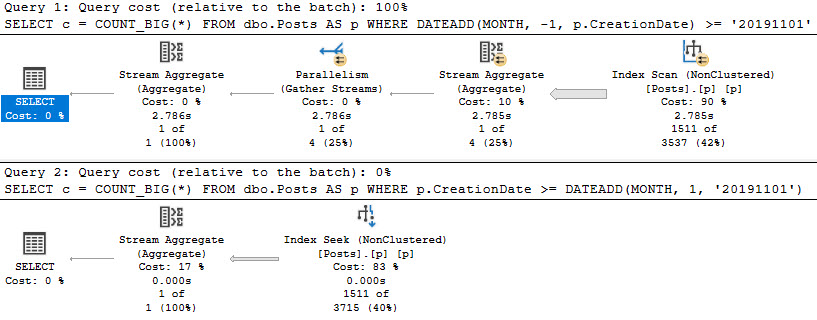
CREATE INDEX p ON dbo.Posts(CreationDate);
There’s a huge difference between these two query plans:
SELECT
c = COUNT_BIG(*)
FROM dbo.Posts AS p
WHERE DATEADD(MONTH, -1, p.CreationDate) >= '20191101'
GO
SELECT
c = COUNT_BIG(*)
FROM dbo.Posts AS p
WHERE p.CreationDate >= DATEADD(MONTH, 1, '20191101');
GO
hand rub
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
One might expect the query inside the cursor to be subject to some special rules, but alas, nothing good comes of it.
Eau de Sample
To repro a little bit, we need to create a certainly suboptimal index.
CREATE INDEX p ON dbo.Posts
(OwnerUserId);
If you have a lot of single key column indexes, you’re probably doing indexing wrong.
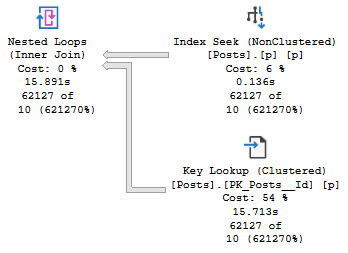
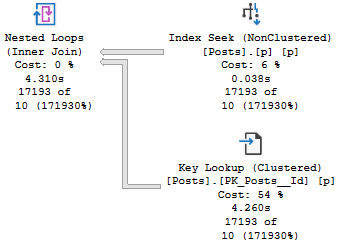
Full demo code is at the end because it’s a bit long, but the end result is five query plans that all share the same bad estimate based off the density vector.
The worst of them looks like this:
Occurling
And the best of them looks like this:
Gruntled
Over and Over
If you’re getting bad guesses like this over and over again in any loop-driven code, local variables might just be to blame.
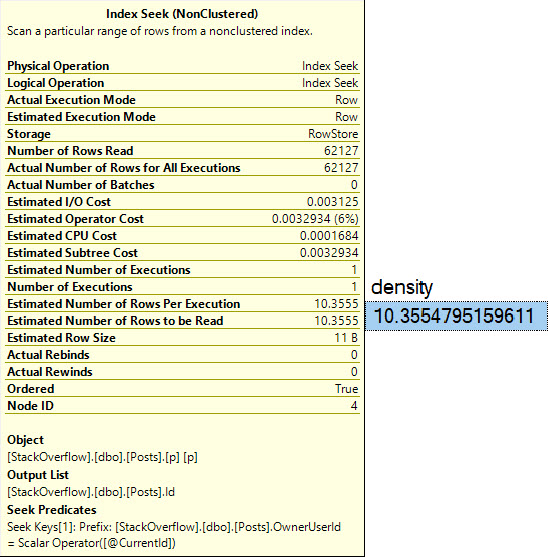
That guess of 10 rows of course comes from this calculation:
SELECT
density =
(
1 /
CONVERT
(
float,
COUNT(DISTINCT p.OwnerUserId)
)
) *
COUNT_BIG(*)
FROM Posts AS p
Which, with a little bit of rounding, gets us to the estimate we see in the query plan:
hectic
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Demo Code
SET STATISTICS XML OFF;
SET NOCOUNT ON;
DECLARE
@CurrentId int;
DROP TABLE IF EXISTS #UserIds;
CREATE TABLE #UserIds
(
UserId int PRIMARY KEY CLUSTERED
);
INSERT
#UserIds WITH(TABLOCK)
(
UserId
)
SELECT
u.Id
FROM dbo.Users AS u
WHERE u.Reputation > 850000
ORDER BY u.Reputation DESC;
DECLARE counter CURSOR
LOCAL STATIC
FOR
SELECT
UserId
FROM #UserIds;
OPEN counter;
FETCH NEXT FROM counter
INTO @CurrentId;
WHILE @@FETCH_STATUS = 0
BEGIN
SET STATISTICS XML ON;
SELECT
p.PostTypeId,
c = COUNT_BIG(*)
FROM dbo.Posts AS p
WHERE p.OwnerUserId = @CurrentId
GROUP BY p.PostTypeId
ORDER BY c DESC;
SET STATISTICS XML OFF;
FETCH NEXT FROM counter
INTO @CurrentId;
END;
CLOSE counter;
DEALLOCATE counter;