If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
According to Not-Australians, there used to be a trace flag that would get queries to ignore any supplied hints. It doesn’t work anymore, which sucks, kinda.
Because people do lots of stupid things with hints. Real stupid things. Things you wouldn’t believe the stupid of.
Let’s say, for example, hypothetically of course, that your front end application would add an index hint to every query.
That index hint may or not be helpful to your query in any way. But there it is.
Let’s also posit, using the very depths of our imaginations, that the front end developer was unlikely to change that behavior.
Planning Fields
We’ve got a couple indexes:
CREATE INDEX r
ON dbo.Users(Reputation)
WITH(MAXDOP = 8, SORT_IN_TEMPDB = ON);
CREATE INDEX c
ON dbo.Users(CreationDate)
WITH(MAXDOP = 8, SORT_IN_TEMPDB = ON);
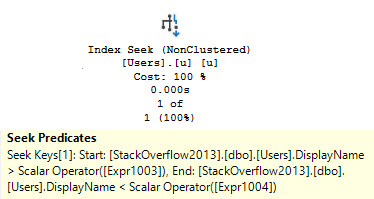
And we’ve got a query that, via an index hint, is being forced to use the wrong index.
DECLARE @Reputation int = 2;
EXEC sp_executesql N'SELECT * FROM dbo.Users WITH (INDEX = c) WHERE Reputation = @Reputation;',
N'@Reputation int',
@Reputation;
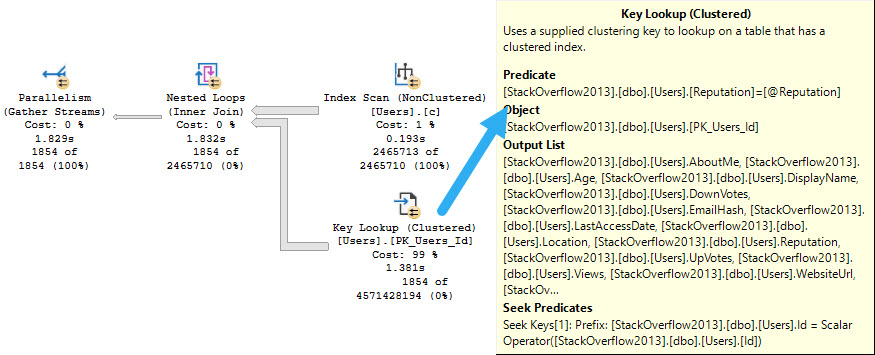
The ensuing query plan makes no sense whatsoever.
i really mean it
The things are all backwards. We scan the entire nonclustered index, and do a lookup to the clustered index just to evaluate the @Reputation predicate.
The idea is bad. Please don’t do the idea.
Guiding Bright
There are two things we could do here. We could hint the query to use the index we want, sure.
But what if we change something about this index, or add another one to the table? We might want the optimizer to have a bit more freedom to choose.
I mean, I know. That has its own risks, but whatever.
We can add a plan guide that looks like this:
EXEC sp_create_plan_guide
@name = N'dammit',
@stmt = N'SELECT * FROM dbo.Users WITH (INDEX = c) WHERE Reputation = @Reputation;',
@type = N'SQL',
@module_or_batch = NULL,
@params = N'@Reputation int',
@hints = N'OPTION(TABLE HINT(dbo.Users))';
If we were writing proper queries where tables are aliased, it’d look like this:
EXEC sp_create_plan_guide
@name = N'dammit',
@stmt = N'SELECT u.* FROM dbo.Users AS u WITH (INDEX = c) WHERE u.Reputation = @Reputation;',
@type = N'SQL',
@module_or_batch = NULL,
@params = N'@Reputation int',
@hints = N'OPTION(TABLE HINT(u))';
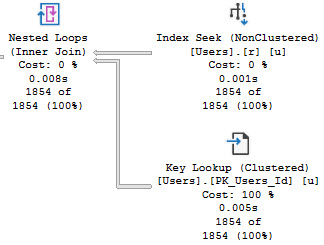
When we re-run our query, things look a lot better:
focus
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
One problem with Lookups, aside from the usual complaints, is that the optimizer has no options for when the lookup happens.
If the optimizer decides to use a nonclustered index to satisfy some part of the query, but the nonclustered index doesn’t have all of the columns needed to cover what the query is asking for, it has to do a lookup.
Whether the lookup is Key or RID depends on if the table has a clustered index, but that’s not entirely the point.
The point is that there’s no way for the optimizer to decide to defer the lookup until later in the plan, when it might be more opportune.
Gastric Acid
Let’s take one index, and two queries.
CREATE INDEX p
ON dbo.Posts(PostTypeId, Score, CreationDate)
INCLUDE(OwnerUserId);
Stop being gross.
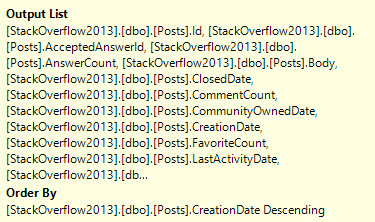
SELECT TOP (1000)
u.DisplayName,
p.*
FROM dbo.Posts AS p
JOIN dbo.Users AS u
ON p.OwnerUserId = u.Id
WHERE p.PostTypeId = 1
AND p.Score > 5
ORDER BY p.CreationDate DESC;
SELECT TOP (1000)
u.DisplayName,
p.*
FROM dbo.Posts AS p
JOIN dbo.Users AS u
ON p.OwnerUserId = u.Id
WHERE p.PostTypeId = 1
AND p.Score > 6
ORDER BY p.CreationDate DESC;
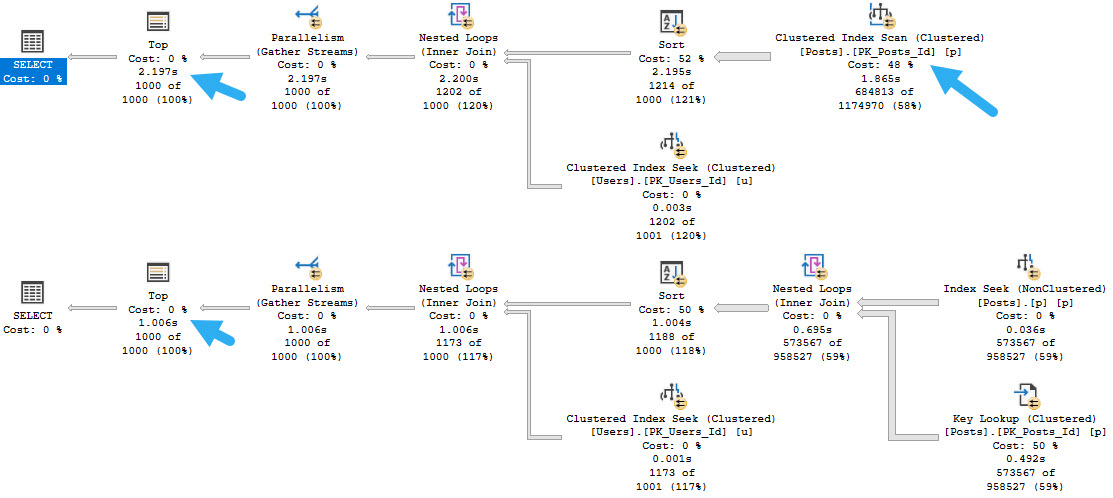
The main point here is not that the lookup is bad; it’s actually good, and I wish both queries would use one.
odd choice
If we hint the first query to use the nonclustered index, things turn out better.
SELECT TOP (1000)
u.DisplayName,
p.*
FROM dbo.Posts AS p WITH(INDEX = p)
JOIN dbo.Users AS u
ON p.OwnerUserId = u.Id
WHERE p.PostTypeId = 1
AND p.Score > 5
ORDER BY p.CreationDate DESC;
woah woah woah you can’t use hints here this is a database
Running a full second faster seems like a good thing to me, but there’s a problem.
Ingest
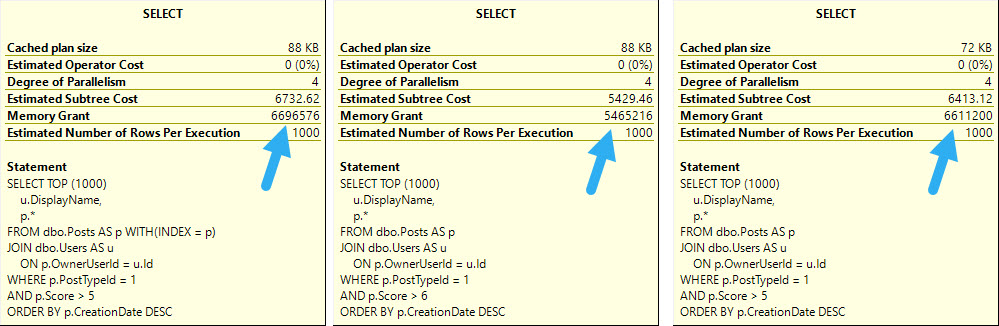
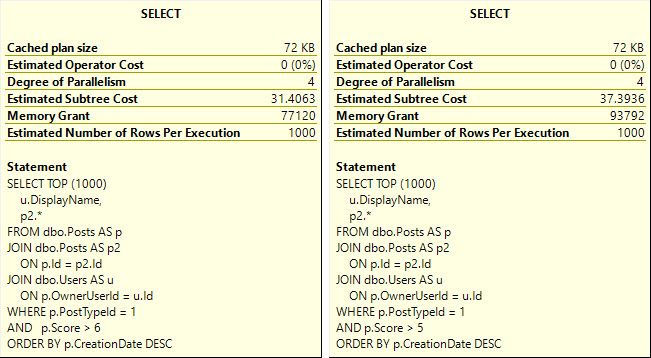
Whether we use the lookup or scan the clustered index, all of these queries ask for rather large memory grants, between 5.5 and 6.5 GB
bigsort4u
The operator asking for memory is the Sort — and while I’d love it if we could index for every sort — it’s just not practical.
So like obviously changing optimizer behavior is way more practical. Ahem.
The reason that the Sort asks for so much memory in each of these cases is that it’s forced to order the entire select output from the Posts table by the CreationDate column.
donk
Detach
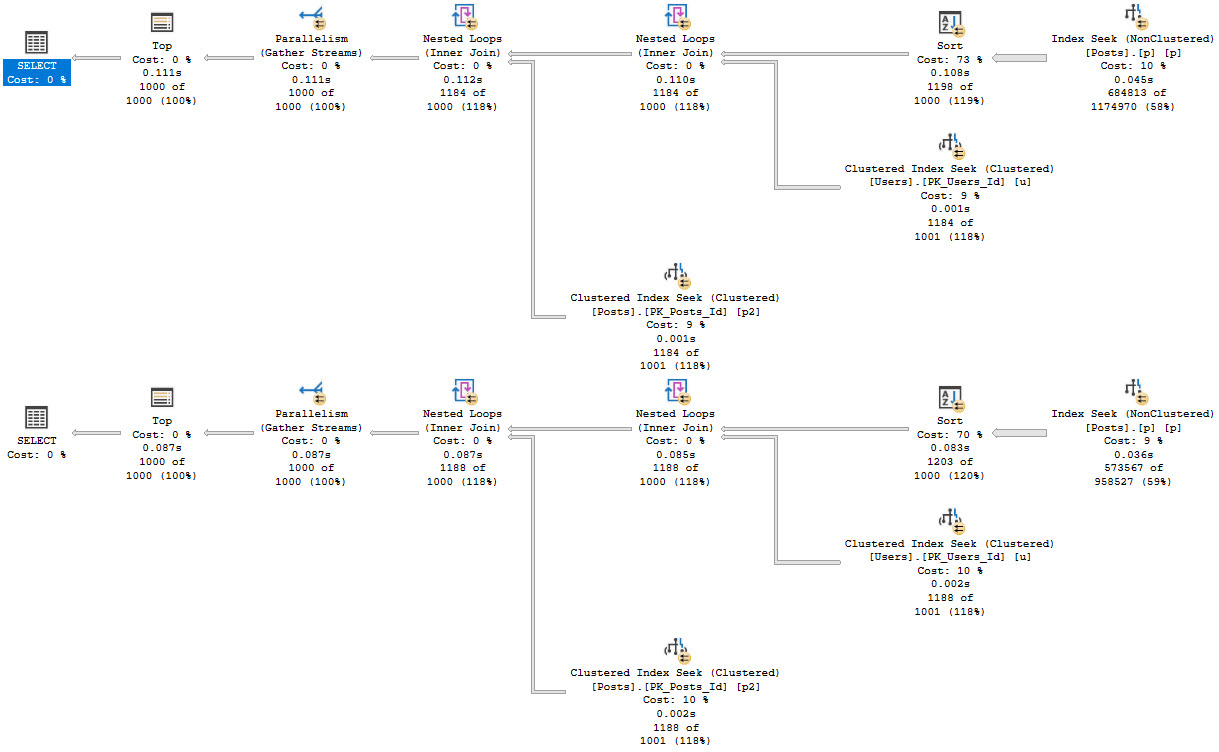
If we rewrite the query a bit, we can get the optimizer to sort data long before we go get all the output columns:
SELECT TOP (1000)
u.DisplayName,
p2.*
FROM dbo.Posts AS p
JOIN dbo.Posts AS p2
ON p.Id = p2.Id
JOIN dbo.Users AS u
ON p.OwnerUserId = u.Id
WHERE p.PostTypeId = 1
AND p.Score > 5
ORDER BY p.CreationDate DESC;
SELECT TOP (1000)
u.DisplayName,
p2.*
FROM dbo.Posts AS p
JOIN dbo.Posts AS p2
ON p.Id = p2.Id
JOIN dbo.Users AS u
ON p.OwnerUserId = u.Id
WHERE p.PostTypeId = 1
AND p.Score > 6
ORDER BY p.CreationDate DESC;
In both cases, we get the same query plan shape, which is what we’re after:
Seek into the nonclustered index on Posts
Sort data by CreationDate
Join Posts to Users first
Join back to Posts for the select list columns
weeeeeeeeee
Because the Sort happens far earlier on in the plan, there’s less of a memory grant needed, and by quite a stretch from the 5+ GB before.
turn down
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
After blogging recently (maybe?) about filters, there was a Stack Exchange question about a performance issue when a variable was declared with a max type.
After looking at it for a minute, I realized that I had never actually checked to see if a recompile hint would allow the optimizer more freedom when dealing with them.
CREATE INDEX u
ON dbo.Users(DisplayName);
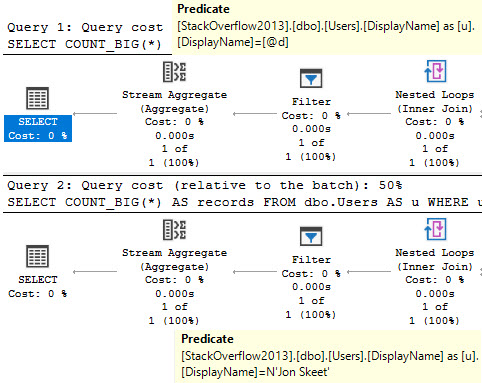
DECLARE @d nvarchar(MAX) = N'Jon Skeet';
SELECT
COUNT_BIG(*) AS records
FROM dbo.Users AS u
WHERE u.DisplayName = @d;
SELECT
COUNT_BIG(*) AS records
FROM dbo.Users AS u
WHERE u.DisplayName = @d
OPTION(RECOMPILE);
Turns out that it won’t, which is surprising.
happy cheese
Even though both plans have sort of a weird seek, the filter operator remains as a weird sort of residual predicate.
truly try me
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Anyway, I got back to thinking about it recently because a couple things had jogged in my foggy brain around table valued functions and parameter sniffing.
Go figure.
Reading Rainbow
One technique you could use to avoid this would be to use an inline table valued function, like so:
CREATE OR ALTER FUNCTION dbo.TopParam(@Top bigint)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
SELECT TOP (@Top)
u.DisplayName,
b.Name
FROM dbo.Users AS u
CROSS APPLY
(
SELECT TOP (1)
b.Name
FROM dbo.Badges AS b
WHERE b.UserId = u.Id
ORDER BY b.Date DESC
) AS b
WHERE u.Reputation > 10000
ORDER BY u.Reputation DESC;
GO
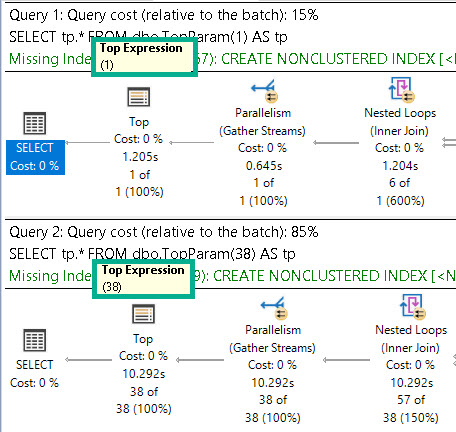
When we select from the function, the top parameter is interpreted as a literal.
SELECT
tp.*
FROM dbo.TopParam(1) AS tp;
SELECT
tp.*
FROM dbo.TopParam(38) AS tp;
genius!
Performance is “fine” for both in that neither one takes over a minute to run. Good good.
Departures
This is, of course, not what happens in a stored procedure or parameterized dynamic SQL.
EXEC dbo.ParameterTop @Top = 1;
doodad
Keen observers will note that this query runs for 1.2 seconds, just like the plan for the function above.
That is, of course, because this is the stored procedure’s first execution. The @Top parameter has been sniffed, and things have been optimized for the sniffed value.
If we turn around and execute it for 38 rows right after, we’ll get the “fine” performance noted above.
EXEC dbo.ParameterTop @Top = 38;
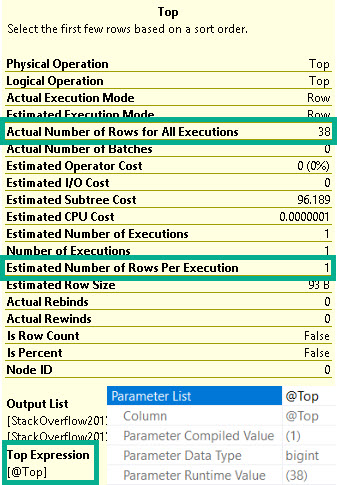
Looking at the plan in a slightly different way, here’s what the Top operator is telling us, along with what the compile and runtime values in the plan are:
snort
It may make sense to make an effort to cache a plan with @Top = 1 initially to get the “fine” performance. That estimate is good enough to get us back to sending the buffers quickly.
Buggers
Unfortunately, putting the inline table valued function inside the stored procedure doesn’t offer us any benefit.
Without belaboring the point too much:
CREATE PROCEDURE dbo.ParameterTopItvf(@Top BIGINT)
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
SELECT
tp.*
FROM dbo.TopParam(@Top) AS tp;
END;
GO
EXEC dbo.ParameterTopItvf @Top = 1;
EXEC dbo.ParameterTopItvf @Top = 38;
EXEC sp_recompile 'dbo.ParameterTopItvf';
EXEC dbo.ParameterTopItvf @Top = 38;
EXEC dbo.ParameterTopItvf @Top = 1;
If we do this, running for 1 first gives us “fine” performance, but running for 38 first gives us the much worse performance.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
UPDATE: After writing this and finding the results fishy, I reported the behavior described below in “Somewhat Surprising” and “Reciprocal?” and it was confirmed a defect in SQL Server 2019 CU8, though I haven’t tested earlier CUs to see how far back it goes. If you’re experiencing this behavior, you’ll have to disable UDF inlining in another way, until CU releases resume in the New Year.
With SQL Server 2019, UDF inlining promises to, as best it can, inline all those awful scalar UDFs that have been haunting your database for ages and making queries perform terribly.
But on top of the long list of restrictions, there are a number of other things that might inhibit it from kicking in.
For example, there’s a database scoped configuration:
ALTER DATABASE SCOPED CONFIGURATION SET TSQL_SCALAR_UDF_INLINING = ON/OFF; --Toggle this
SELECT
dsc.*
FROM sys.database_scoped_configurations AS dsc
WHERE dsc.name = N'TSQL_SCALAR_UDF_INLINING';
There’s a function characteristic you can use to turn them off:
CREATE OR ALTER FUNCTION dbo.whatever()
RETURNS something
WITH INLINE = ON/OFF --Toggle this
GO
And your function may or not even be eligible:
SELECT
OBJECT_NAME(sm.object_id) AS object_name,
sm.is_inlineable
FROM sys.sql_modules AS sm
JOIN sys.all_objects AS ao
ON sm.object_id = ao.object_id
WHERE ao.type = 'FN';
Somewhat Surprising
One thing that caught me off guard was that having the database in compatibility level 140, but running the query in compatibility level 150 also nixed the dickens out of it.
DBCC FREEPROCCACHE;
GO
ALTER DATABASE StackOverflow2013 SET COMPATIBILITY_LEVEL = 140;
GO
WITH Comments AS
(
SELECT
dbo.serializer(1) AS udf, --a function
ROW_NUMBER()
OVER(ORDER BY
c.CreationDate) AS n
FROM dbo.Comments AS c
)
SELECT
c.*
FROM Comments AS c
WHERE c.n BETWEEN 1 AND 100
OPTION(USE HINT('QUERY_OPTIMIZER_COMPATIBILITY_LEVEL_150'), MAXDOP 8);
GO
Our query has all the hallmarks of one that has been inflicted with functions:
it can’t go parallel
And if you’re on SQL Server 2016+, you can see that it executes once per row:
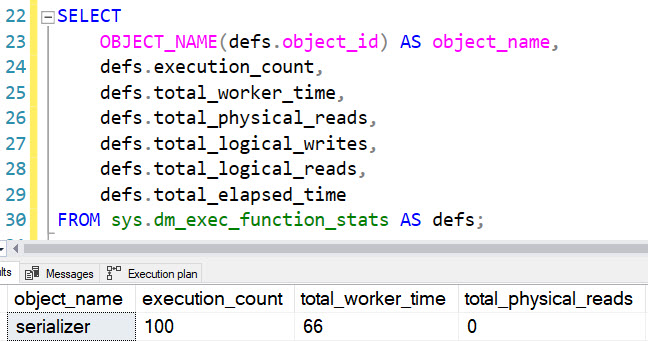
SELECT
OBJECT_NAME(defs.object_id) AS object_name,
defs.execution_count,
defs.total_worker_time,
defs.total_physical_reads,
defs.total_logical_writes,
defs.total_logical_reads,
defs.total_elapsed_time
FROM sys.dm_exec_function_stats AS defs;
rockin’ around
Reciprocal?
There’s an odd contradiction here, though. If we repeat the experiment setting the database compatibility level to 150, but running the query in compatibility level 140, the function is inlined.
DBCC FREEPROCCACHE;
GO
ALTER DATABASE StackOverflow2013 SET COMPATIBILITY_LEVEL = 150;
GO
WITH Comments AS
(
SELECT
dbo.serializer(c.Id) AS udf,
ROW_NUMBER()
OVER(ORDER BY
c.CreationDate) AS n
FROM dbo.Comments AS c
)
SELECT
c.*
FROM Comments AS c
WHERE c.n BETWEEN 1 AND 100
OPTION(USE HINT('QUERY_OPTIMIZER_COMPATIBILITY_LEVEL_140'), MAXDOP 8);
GO
Rather than seeing a non-parallel plan, and non-parallel plan reason, we see a parallel plan, and an attribute telling us that a UDF has been inlined.
call hope
And if we re-check the dm_exec_function_stats DMV, it will have no entries. That seems more than a little bit weird to me, but hey.
I’m just a lowly consultant on SSMS 18.6
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I will be able to not care about this sort of thing. But for now, here we are, having to write multiple blogs in a day to cover a potpourri of grievances.
Let’s get right to it!
First, without a where clause, the optimizer doesn’t think that an index could improve one single, solitary metric about this query. We humans know better, though.
WITH Votes AS
(
SELECT
v.Id,
ROW_NUMBER()
OVER(PARTITION BY
v.PostId
ORDER BY
v.CreationDate) AS n
FROM dbo.Votes AS v
)
SELECT *
FROM Votes AS v
WHERE v.n = 0;
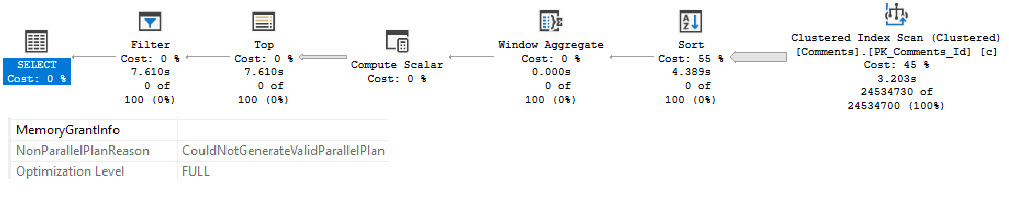
The tough part of this plan will be putting data in order to suit the Partition By, and then the Order By, in the windowing function.
Without any other clauses against columns in the Votes table, there are no additional considerations.
Two Day
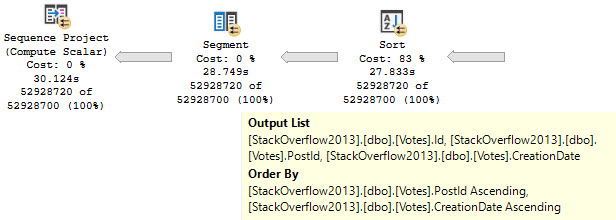
What often happens is that someone wants to add an index to help the windowing function along, so they follow some basic guidelines they found on the internet.
What they end up with is an index on the Partition By, Order By, and then Covering any additional columns. In this case there’s no additional Covering Considerations, so we can just do this:
CREATE INDEX v2 ON dbo.Votes(PostId, CreationDate);
If you’ve been following my blog, you’ll know that indexes put data in order, and that with this index you can avoid needing to physically sort data.
limousine
Three Day
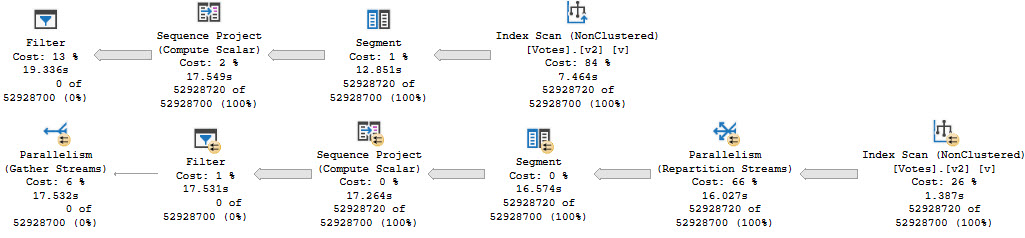
The trouble here is that, even though we have Cost Threshold For Parallelism (CTFP) set to 50, and the plan costs around 195 Query Bucks, it doesn’t go parallel.
Creating the index shaves about 10 seconds off the ordeal, but now we’re stuck with this serial calamity, and… forcing it parallel doesn’t help.
Our old nemesis, repartition streams, is back.
wackness
Even at DOP 8, we only end up about 2 seconds faster. That’s not a great use of parallelism, and the whole problem sits in the repartition streams.
This is, just like we talked about yesterday, a row mode problem. And just like we talked about the day before that, windowing functions generally do benefit from batch mode.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
When queries go parallel, you want them to be fast. Sometimes they are, and it’s great.
Other times they’re slow, and you end up staring helplessly at a repartition streams operator.
brick wall
Sometimes you can reduce the problem with higher DOP hints, or better indexing, but overall it’s a crappy situation.
Snap To
Let’s admire a couple familiar looking queries, because that’s been working really well for us so far.
WITH Comments AS
(
SELECT
ROW_NUMBER()
OVER(PARTITION BY
c.UserId
ORDER BY
c.CreationDate) AS n
FROM dbo.Comments AS c
)
SELECT *
FROM Comments AS c
WHERE c.n = 0
OPTION(USE HINT('QUERY_OPTIMIZER_COMPATIBILITY_LEVEL_140'));
WITH Comments AS
(
SELECT
ROW_NUMBER()
OVER(PARTITION BY
c.UserId
ORDER BY
c.CreationDate) AS n
FROM dbo.Comments AS c
)
SELECT *
FROM Comments AS c
WHERE c.n = 0
OPTION(USE HINT('QUERY_OPTIMIZER_COMPATIBILITY_LEVEL_150'));
One is going to run in compatibility level 140, the other in 150, as foretold by ancient alien prophecy.
The two query plans will have a bit in common, but…
just batch
The second query, which runs in batch mode, runs about 15 seconds faster. One big reason why is that we skip that most unfortunate repartition streams operator.
It’s a cold sore. An actual factual cold sore.
The only ways I’ve found to fix it completely are:
Induce batch mode
Use the parallel apply technique
But the parallel apply technique doesn’t help much here, because of local factors.
In this case, me generating the largest possible result set and then filtering it down to nothing at the end.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
If you ask people who tune queries why batch mode is often much more efficient with windowing functions, they’ll tell you about the window aggregate operator.
That’s all well and good, but there’s another, often sneaky limitation of fully row mode execution plans with windowing functions.
Let’s go take a look!
Global Aggregates
One thing that causes an early serial zone in execution plans is if you use a windowing function that only has the order by
For example, let’s look at the plans for these two queries:
WITH Comments AS
(
SELECT
ROW_NUMBER()
OVER(ORDER BY
c.CreationDate) AS n
FROM dbo.Comments AS c
)
SELECT *
FROM Comments AS c
WHERE c.n = 0;
WITH Comments AS
(
SELECT
ROW_NUMBER()
OVER(PARTITION BY
c.UserId
ORDER BY
c.CreationDate) AS n
FROM dbo.Comments AS c
)
SELECT *
FROM Comments AS c
WHERE c.n = 0;
The resulting estimated plans look like this, using the 140 compatibility level:
oops
In the top plan, where the windowing function only has an order by, the serial zone happens immediately before the Segment operator. In the second plan, the parallel zone carries on until right before the select operator.
If you’re wondering why we’re only looking at estimated plans here, it’s because repartition streams ruins everything.
In The Year 2000
In compatibility level 150, things change a bit (yes, a window aggregate appears):
merry christmas
And the window aggregate appears within the parallel zone. The parallel zone does end before the filter operator, which may or may not be a disaster depending on how restrictive your filter is, and how many rows end up at it.
Also note the distinct lack of a repartition streams operator ruining everything. We’ll talk about that tomorrow.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I think Batch Mode is quite spiffy for the right kind of query, but up until SQL Server 2019, we had to play some tricks to get it:
Do a funny join to an empty table with a column store index
Create a filtered column store index with no data in it
If you’re on SQL server 2019 Enterprise Edition, and you’ve got your database in compatibility level 150, you may heuristically receive Batch Mode without those tricks.
One important difference between Batch Mode Tricks™ and Batch Mode On Rowstore (BMOR) is that the latter allows you to read from row mode tables using Batch Mode, while the former doesn’t.
Tricks have limits, apparently.
Squish Squish
To cut down on typing, I’ll often create a helper object like this:
CREATE TABLE dbo.t
(
id int NULL,
INDEX c CLUSTERED COLUMNSTORE
);
SELECT
p.OwnerUserId,
COUNT_BIG(*) AS records
FROM dbo.Posts AS p
LEFT JOIN dbo.t
ON 1 = 0
WHERE p.Score < 50
GROUP BY p.OwnerUserId
HAVING COUNT_BIG(*) > 2147483647
OPTION(USE HINT('QUERY_OPTIMIZER_COMPATIBILITY_LEVEL_140'), MAXDOP 8);
SELECT
p.OwnerUserId,
COUNT_BIG(*) AS records
FROM dbo.Posts AS p
WHERE p.Score < 50
GROUP BY p.OwnerUserId
HAVING COUNT_BIG(*) > 2147483647
OPTION(USE HINT('QUERY_OPTIMIZER_COMPATIBILITY_LEVEL_150'), MAXDOP 8);
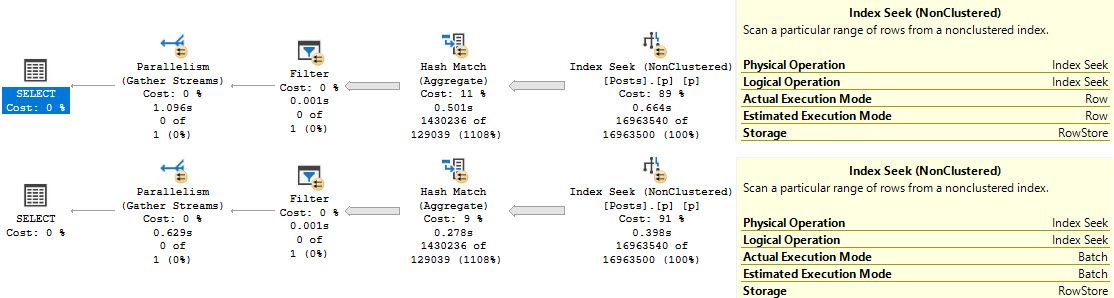
One executes in compatibility level 140, the other in 150.
Splish Splash
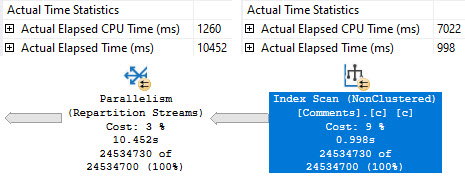
There are a couple interesting things, here.
the porter
Even though both queries have operators that execute in Batch Mode (Filter, Hash Match), only the second query can read from the row store clustered index in Batch Mode. In this case, that shaves a couple hundred milliseconds off the seek.
There is likely some additional invisible benefit to not having to convert the row mode seek to a batch mode hash join at the next operator, since one executes for 501ms, and the other executes for 278ms. There’s nothing in the query plan to signal that happening, so you’ll just have to use your imagination.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.