Nothing Works
There are things that queries just weren’t meant to do all at once. Multi-purpose queries are often just a confused jumble with crappy query plans.
If you have a Swiss Army Knife, pull it out. Open up all the doodads. Now try to do one thing with it.
If you didn’t end up with a corkscrew in your eye, I’m impressed.
En Masse
The easiest way to think of this is conditionals. If what happens within a stored procedure or query depends on something that is decided based on user input or some other state of data, you’ve introduced an element of uncertainty to the query optimization process.
Of course, this also depends on if performance is of some importance to you.
Since you’re here, I’m assuming it is. It’s not like I spend a lot of time talking about backups and crap.
There are a lot of forms this can take, but none of them lead to you winning an award for Best Query Writer.
IFTTT
Let’s say a stored procedure will execute a different query based on some prior logic, or an input parameter.
Here’s a simple example:
IF @i = 1
BEGIN
SELECT
u.*
FROM dbo.Users AS u
WHERE u.Reputation = @i;
END;
IF @i = 2
BEGIN
SELECT
p.*
FROM dbo.Posts AS p
WHERE p.PostTypeId = @i;
END;
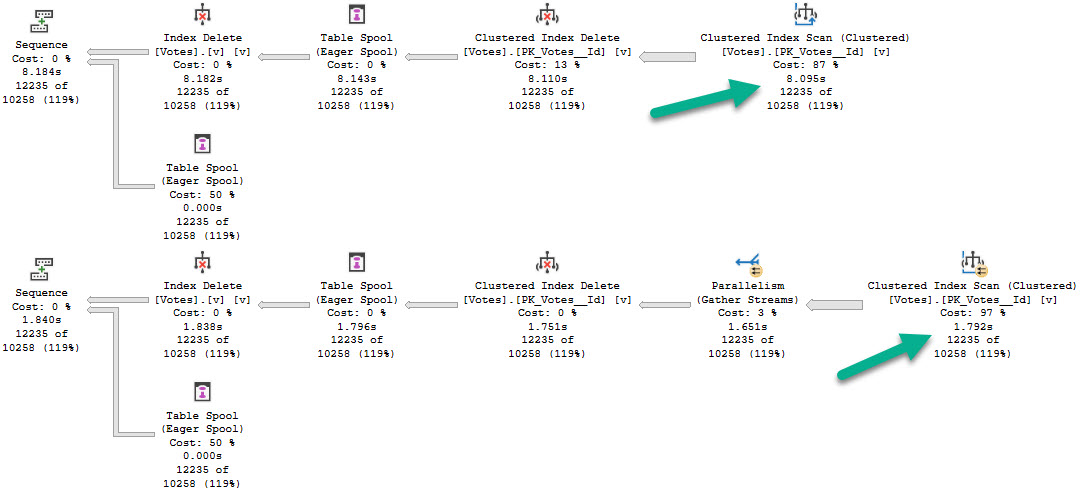
If the stored procedure runs for @i = 1 first, the second query will get optimized for that value too.
Using parameterized dynamic SQL can get you the type of optimization separation you want, to avoid cross-optimization contamination.
I made half of that sentence up.
For more information, read this article.
Act Locally
Local variables are another great use of dynamic SQL, because one query’s local variable is another query’s parameter.
DECLARE @i int = 2;
SELECT
v.*
FROM dbo.Votes AS v
WHERE v.VoteTypeId = @i;
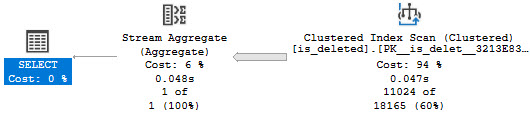
Doing this will get you weird estimates, and you won’t be happy.
You’ll never be happy.
For more information, read this article.
This Or That
You can replace or reorder the where clause with lots of different attempts at humor, but none of them will be funny.
SELECT
c.*
FROM dbo.Comments AS c
WHERE (c.Score >= @i OR @i IS NULL);
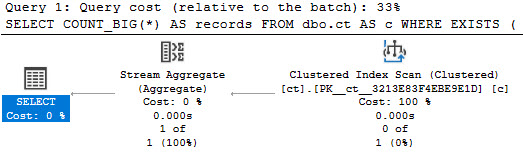
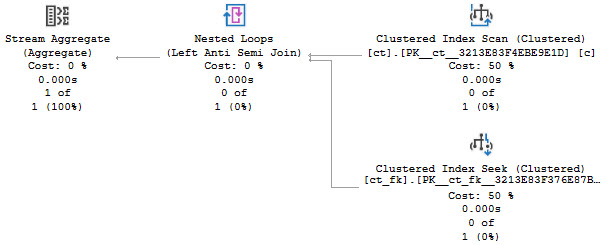
The optimizer does not consider this SARGable, and it will take things out on you in the long run.
Maybe you’re into that, though. I won’t shame you.
We can still be friends.
For more information, watch this video.
Snortables
Dynamic SQL is so good at helping you with parameter sniffing issues that I have an entire session about it.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.