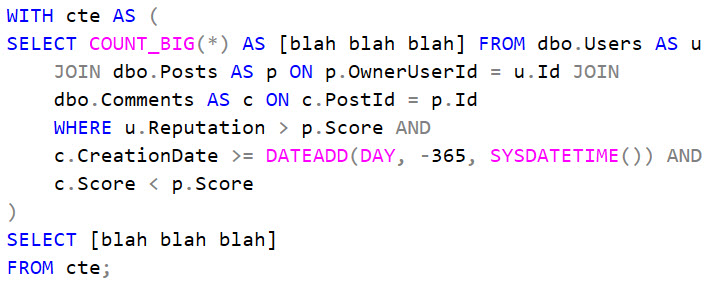
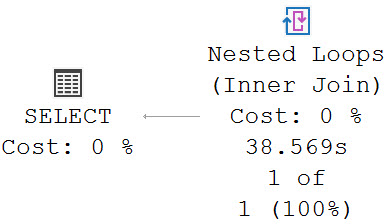One line I see over and over again — I’ve probably said it too when I was young and needed words to fill space — is that CTEs make queries more readable.
Personally, I don’t think they make queries any more readable than derived tables, but whatever. No one cares what I think, anyway.
Working with clients I see a variety of query formatting styles, ranging from quite nice ones that have influenced the way I format things, to completely unformed primordial blobs. Sticking the latter into a CTE does nothing for readability even if it’s commented to heck and back.
nope nope nope
There are a number of options for formatting code:
Formatting your code nicely doesn’t just help others read it, it can also help people understand how it works.
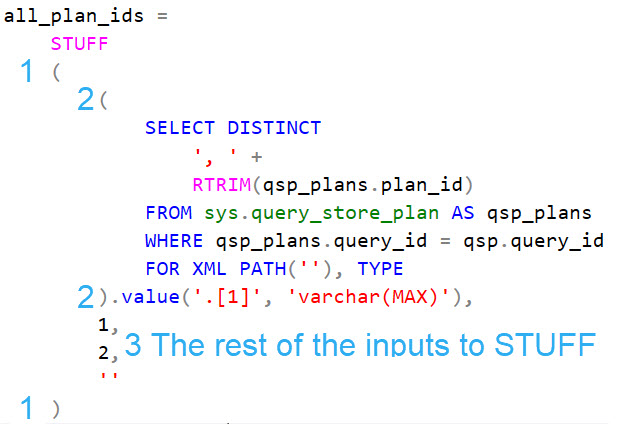
Take this example from sp_QuickieStore that uses the STUFF function to build a comma separated list the crappy way.
If STRING_AGG were available in SQL Server 2016, I’d just use that. Darn legacy software.
parens
The text I added probably made things less readable, but formatting the code this way helps me make sure I have everything right.
The opening and closing parens for the STUFF function
The first input to the function is the XML generating nonsense
The last three inputs to the STUFF function that identify the start, length, and replacement text
I’ve seen and used this specific code a million times, but it wasn’t until I formatted it this way that I understood how all the pieces lined up.
Compare that with another time I used the same code fragment in sp_BlitzCache. I wish I had formatted a lot of the stuff I wrote in there better.
carry the eleventy
With things written this way, it’s really hard to understand where things begin and end and that arguments belong to which part of the code.
Maybe someday I’ll open an issue to reformat all the FRK code ?
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
There was a three-part series of posts where I talked about a weird performance issue you can hit with parameterized top. While doing some query tuning for a client recently, I ran across a funny scenario where they were using TOP PERCENT to control the number of rows coming back from queries.
With a parameter.
So uh. Let’s talk about that.
Setup Time
Let’s start with a great index. Possibly the greatest index ever created.
CREATE INDEX whatever
ON dbo.Votes
(VoteTypeId, CreationDate DESC)
WITH
(
MAXDOP = 8,
SORT_IN_TEMPDB = ON
);
GO
Now let me show you this stored procedure. Hold on tight!
CREATE OR ALTER PROCEDURE dbo.top_percent_sniffer
(
@top bigint,
@vtid int
)
AS
SET NOCOUNT, XACT_ABORT ON;
BEGIN
SELECT TOP (@top) PERCENT
v.*
FROM dbo.Votes AS v
WHERE v.VoteTypeId = @vtid
ORDER BY v.CreationDate DESC;
END;
Cool. Great.
Spool Hardy
When we execute the query, the plan is stupid.
EXEC dbo.top_percent_sniffer
@top = 1,
@vtid = 6;
GO
the louis vuitton of awful
We don’t use our excellent index, and the optimizer uses an eager table spool to hold rows and pass the count to the TOP operator until we hit the correct percentage.
This is the least ideal situation we could possibly imagine.
Boot and Rally
A while back I posted some strange looking code on Twitter, and this is what it ended up being used for (among other things).
CREATE OR ALTER PROCEDURE dbo.top_percent_sniffer
(
@top bigint,
@vtid int
)
AS
SET NOCOUNT, XACT_ABORT ON;
BEGIN;
WITH pct AS
(
SELECT
records =
CONVERT(bigint,
CEILING(((@top * COUNT_BIG(*)) / 100.)))
FROM dbo.Votes AS v
WHERE v.VoteTypeId = @vtid
)
SELECT
v.*
FROM pct
CROSS APPLY
(
SELECT TOP (pct.records)
v.*
FROM dbo.Votes AS v
WHERE v.VoteTypeId = @vtid
ORDER BY v.CreationDate DESC
) AS v;
END;
GO
better butter
Soul Bowl
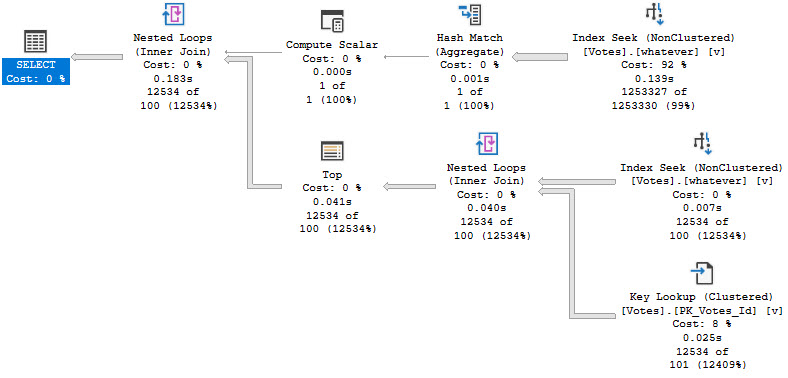
This definitely has drawbacks, since the expression in the TOP always gives a 100 row estimate. For large numbers of rows, this plan could be a bad choice and we might need to do some additional tuning to get rid of that lookup.
There might also be occasions when using a column store index to generate the count would be benefit, and the nice thing here is that since we’re accessing the table in two different ways, we could use two different indexes.
But for reliably small numbers of rows, this is a pretty good solution.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
In the year 950 B.C., Craig Freedman write a post about subqueries in CASE expressions. It’s amazing how relevant so much of this stuff stays.
In today’s post, we’re going to look at a slightly different example than the one given, and how you can avoid performance problems with them by using APPLY.
Like most query tuning tricks, this isn’t something you always need to employ, and it’s not a best practice. It’s just something you can use when a scalar subquery doesn’t perform as you’d like it to.
How Much Wood
Our starting query looks like this. The point of it is to determine the percentage of answered questions per month.
SELECT
x.YearPeriod,
MonthPeriod =
RIGHT('00' + RTRIM(x.MonthPeriod), 2),
PercentAnswered =
CONVERT(DECIMAL(18, 2),
(SUM(x.AnsweredQuestion * 1.) /
(COUNT_BIG(*) * 1.)) * 100.)
FROM
(
SELECT
YearPeriod = YEAR(p.CreationDate),
MonthPeriod = MONTH(p.CreationDate),
CASE
WHEN EXISTS
(
SELECT
1/0
FROM dbo.Votes AS v
WHERE v.PostId = p.AcceptedAnswerId
AND v.VoteTypeId = 1
)
THEN 1
ELSE 0
END AS AnsweredQuestion
FROM dbo.Posts AS p
WHERE p.PostTypeId = 1
) AS x
GROUP BY
x.YearPeriod,
x.MonthPeriod
ORDER BY
x.YearPeriod ASC,
x.MonthPeriod ASC;
Smack in the middle of it, we have a case expression that goes looking for rows in the Votes table where a question has an answer that’s been voted as the answer.
Amazing.
To start with, we’re going to give it this index.
CREATE INDEX p
ON dbo.Posts(PostTypeId, AcceptedAnswerId)
INCLUDE(CreationDate)
WITH(MAXDOP = 8, SORT_IN_TEMPDB = ON);
Planpains
In all, this query will run for about 18 seconds. The majority of it is spent in a bad neighborhood.
but first
Why does this suck? Boy oh boy. Where do we start?
Sorting the Votes table to support a Merge Join?
Choosing Parallel Merge Joins ever?
Choosing a Many To Many Merge Join ever?
All of the above?
Bout It
If we change the way the query is structured to use OUTER APPLY instead, we can get much better performance in this case.
SELECT
x.YearPeriod,
MonthPeriod =
RIGHT('00' + RTRIM(x.MonthPeriod), 2),
PercentAnswered =
CONVERT(DECIMAL(18, 2),
(SUM(x.AnsweredQuestion * 1.) /
(COUNT_BIG(*) * 1.)) * 100.)
FROM
(
SELECT
YearPeriod = YEAR(p.CreationDate),
MonthPeriod = MONTH(p.CreationDate),
oa.AnsweredQuestion
FROM dbo.Posts AS p
OUTER APPLY
(
SELECT
AnsweredQuestion =
CASE
WHEN v.Id IS NOT NULL
THEN 1
ELSE 0
END
FROM dbo.Votes AS v
WHERE v.PostId = p.AcceptedAnswerId
AND v.VoteTypeId = 1
) oa
WHERE p.PostTypeId = 1
) AS x
GROUP BY
x.YearPeriod,
x.MonthPeriod
ORDER BY
x.YearPeriod ASC,
x.MonthPeriod ASC;
This changes the type of join chosen, and runs for about 3 seconds total.
buttercup
We avoid all of the problems that the parallel many-to-many Merge Join brought us.
Thanks, Hash Join.
It’s also worth noting that the OUTER APPLY plan asks for an index that would help us a bit, though like most missing index requests it’s a bit half-baked.
USE [StackOverflow2013]
GO
CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>]
ON [dbo].[Votes] ([VoteTypeId])
INCLUDE ([PostId])
GO
Index Plus
Any human could look at this query and realize that having the PostId in the key of the index would be helpful, since we’d have it in secondary order to the VoteTypeId column
CREATE INDEX v
ON dbo.Votes(VoteTypeId, PostId)
WITH(MAXDOP = 8, SORT_IN_TEMPDB = ON);
If we add that index, we can make the subquery fairly competitive, at about 4.5 seconds total.
bloop join
But the issue here is now rather than poorly choosing a Sort > Merge Join, we go into a Nested Loops join for ~6 million rows. That’s probably not a good idea.
This index doesn’t leave as profound a mark on the APPLY version of the query. It does improve overall runtime by about half a second, but I don’t think I’d create an index just to get a half second better.
astro weiner
But hey, who knows? Maybe it’d help some other queries, too.
Indexes are cool like that.
Back On The Map
If you’ve got subqueries in your select list that lead to poor plan choices, you do have options. Making sure you have the right indexes in place can go a long way.
You may be able to get competitive performance gains by rewriting them as OUTER APPLY. You really do need to use OUTER here though, because it won’t restrict rows and matches the logic of the subquery. CROSS APPLY would act like an inner join and remove any rows that don’t have a match. That would break the results.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Well over 500 years ago, Paul White wrote an article about distinct aggregates. Considering how often I see it while working with clients, and that Microsoft created column store indexes and batch mode rather than allow for hash join hints on CLR UDFs, the topic feels largely ignored.
But speaking of all that stuff, let’s look at how Batch Mode fixes multiple distinct aggregates.
Jumbo Size
A first consideration is around parallelism, since you don’t pay attention or click links, here’s a quote you won’t read from Paul’s article above:
Another limitation is that this spool does not support parallel scan for reading, so the optimizer is very unlikely to restart parallelism after the spool (or any of its replay streams).
In queries that operate on large data sets, the parallelism implications of the spool plan can be the most important cause of poor performance.
What does that mean for us? Let’s go look. For this demo, I’m using SQL Server 2019 with the compatibility level set to 140.
SELECT
COUNT_BIG(DISTINCT v.PostId) AS PostId,
COUNT_BIG(DISTINCT v.UserId) AS UserId,
COUNT_BIG(DISTINCT v.BountyAmount) AS BountyAmount,
COUNT_BIG(DISTINCT v.VoteTypeId) AS VoteTypeId,
COUNT_BIG(DISTINCT v.CreationDate) AS CreationDate
FROM dbo.Votes AS v;
In the plan for this query, we scan the clustered index of the Votes table five times, or once per distinct aggregate.
skim scan
In case you’re wondering, this results in one intent shared object lock on the Votes table.
This query runs for 38.5 seconds, as the crow flies.
push the thing
A Join Appears
Let’s join Votes to Posts for no apparent reason.
SELECT
COUNT_BIG(DISTINCT v.PostId) AS PostId,
COUNT_BIG(DISTINCT v.UserId) AS UserId,
COUNT_BIG(DISTINCT v.BountyAmount) AS BountyAmount,
COUNT_BIG(DISTINCT v.VoteTypeId) AS VoteTypeId,
COUNT_BIG(DISTINCT v.CreationDate) AS CreationDate
FROM dbo.Votes AS v
JOIN dbo.Posts AS p
ON p.Id = v.PostId;
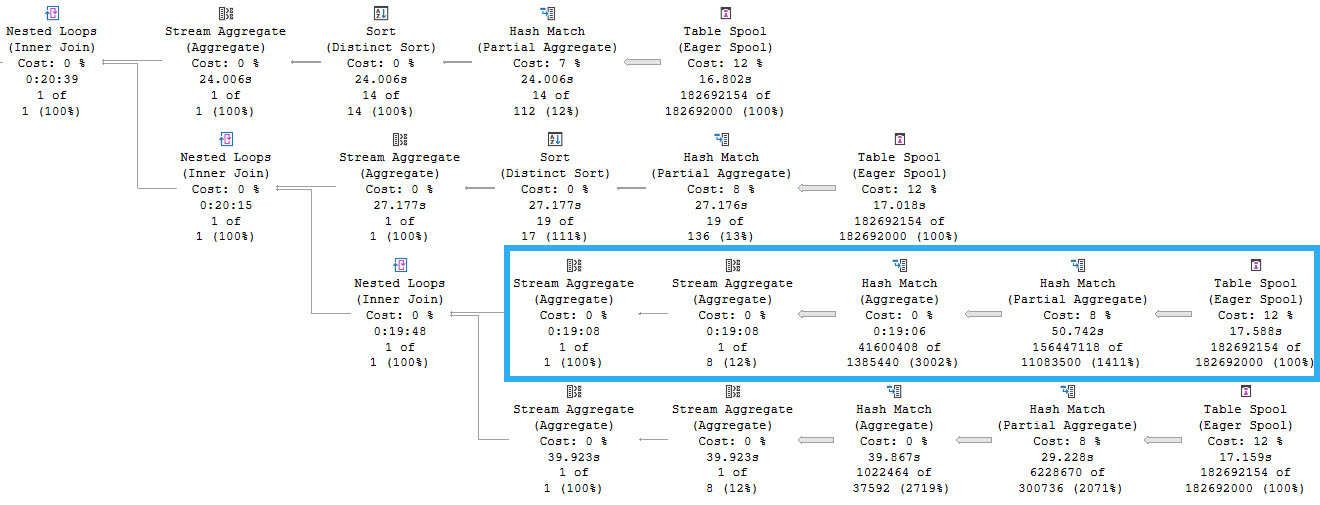
The query plan now has two very distinct (ho ho ho) parts.
problemium
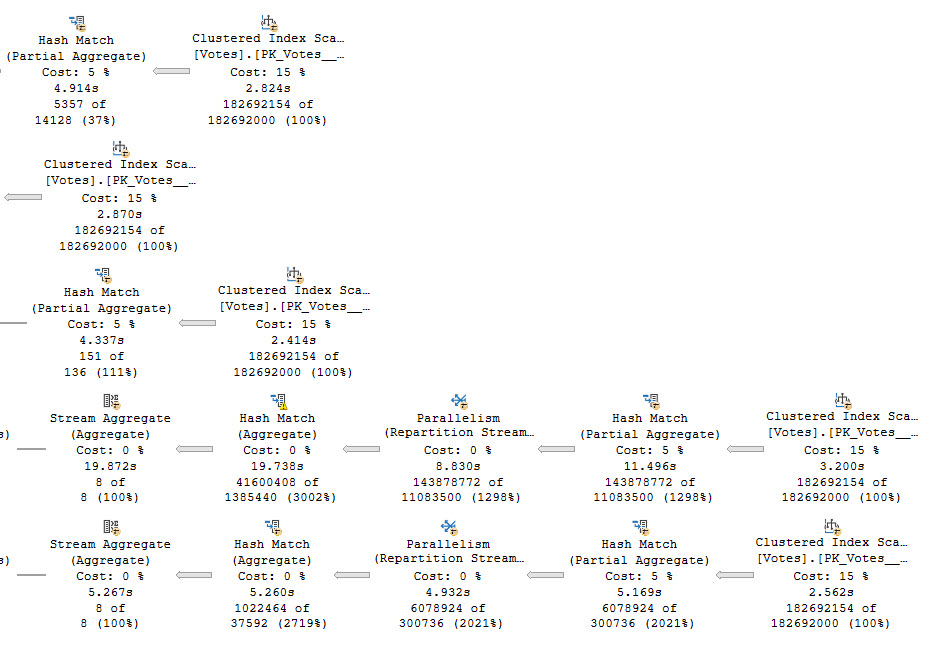
This is part 1. Part 1 is a spoiler. Ignoring that Repartition Streams is bizarre and Spools are indefensible blights, as we meander across the execution plan we find ourselves at a stream aggregate whose child operators have executed for 8 minutes, and then a nested loops join whose child operators have run for 20 minutes and 39 seconds. Let’s go look at that part of the plan.
downstream
Each branch here represents reading from the same spool. We can tell this because the Spool operators do not have any child operators. They are starting points for the flow of data. One thing to note here is that there are four spools instead of five, and that’s because one of the five aggregates was processed in the first part of the query plan we looked at.
The highlighted branch is the one that accounts for the majority of the execution time, at 19 minutes, 8 seconds. This branch is responsible for aggregating the PostId column. Apparently a lack of distinct values is hard to process.
But why is this so much slower? The answer is parallelism, or a lack thereof. So, serialism. Remember the 500 year old quote from above?
Another limitation is that this spool does not support parallel scan for reading, so the optimizer is very unlikely to restart parallelism after the spool (or any of its replay streams).
In queries that operate on large data sets, the parallelism implications of the spool plan can be the most important cause of poor performance.
Processing that many rows on a single thread is painful across all of the operators.
Flounder Edition
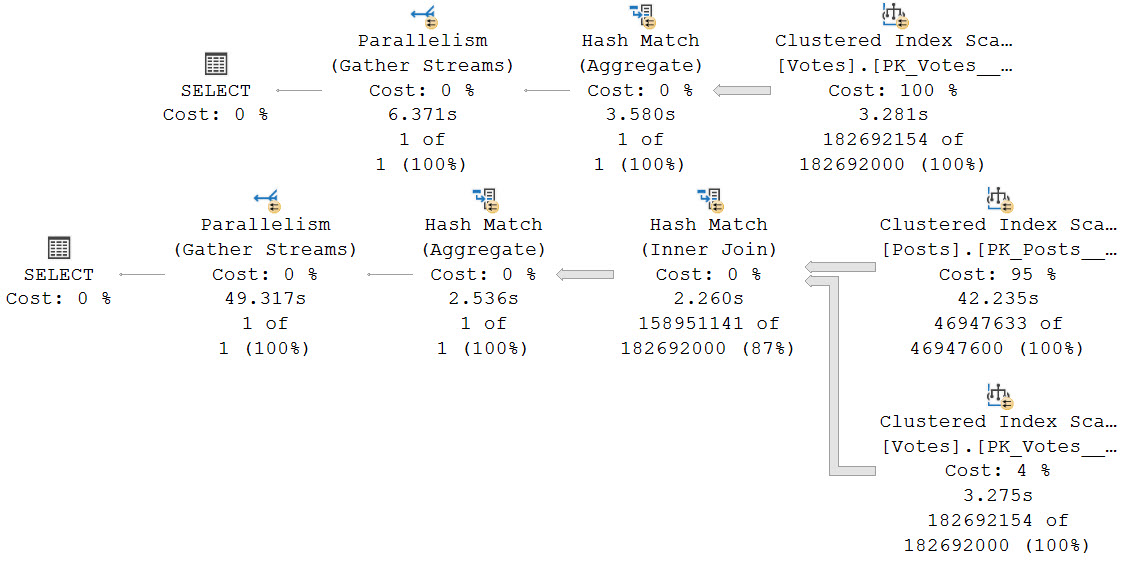
With SQL Server 2019, we get Batch Mode On Row store when compatibility level gets bumped up to 150.
The result is just swell.
yes you can
The second query with the join still runs for nearly a minute, but 42 seconds of the process is scanning that big ol’ Posts table.
Grumpy face.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
sp_PressureDetector now includes statement start and end offsets, in case you want to build plan guides for queries
WhatsUpMemory got a huge performance tuning, which I’ll talk about in tomorrow’s post!
Nothing else here. Happy downloading and analyzing.
Or analysing, if you’re from a refined country.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
It’s likely also obvious that your join clauses should also be SARGable. Doing something like this is surely just covering up for some daft data quality issues.
SELECT
COUNT_BIG(*) AS records
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON ISNULL(p.OwnerUserId, 0) = u.Id;
If 0 has any real meaning here, replace the NULLs with zeroes already. Doing it at runtime is a chore for everyone.
But other things can be thought of as “SARGable” too. But perhaps we need a better word for it.
I don’t have one, but let’s define it as the ability for a query to take advantage of index ordering.
World War Three
There are no Search ARGuments here. There’s no argument at all.
But we can plainly see queries invoking functions on columns going all off the rails.
Here’s an index. Please enjoy.
CREATE INDEX c ON dbo.Comments(Score);
Now, let’s write a query. Once well, once poorly. Second verse, same as the first.
SELECT TOP(1)
c.*
FROM dbo.Comments AS c
ORDER BY
c.Score DESC;
SELECT TOP(1)
c.*
FROM dbo.Comments AS c
ORDER BY
ISNULL(c.Score, 0) DESC;
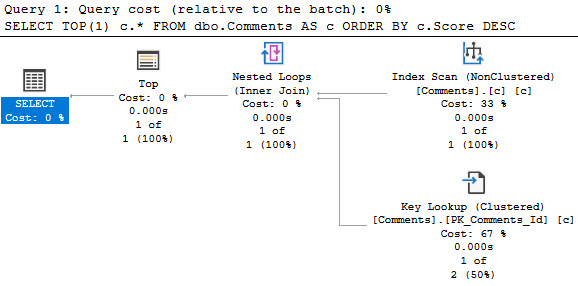
The plan for the first one! Yay!
inky
Look at those goose eggs. Goose Gossage. Nolan Ryan.
The plan for the second one is far less successful.
trashy vampire
We’ve done our query a great disservice.
Not Okay
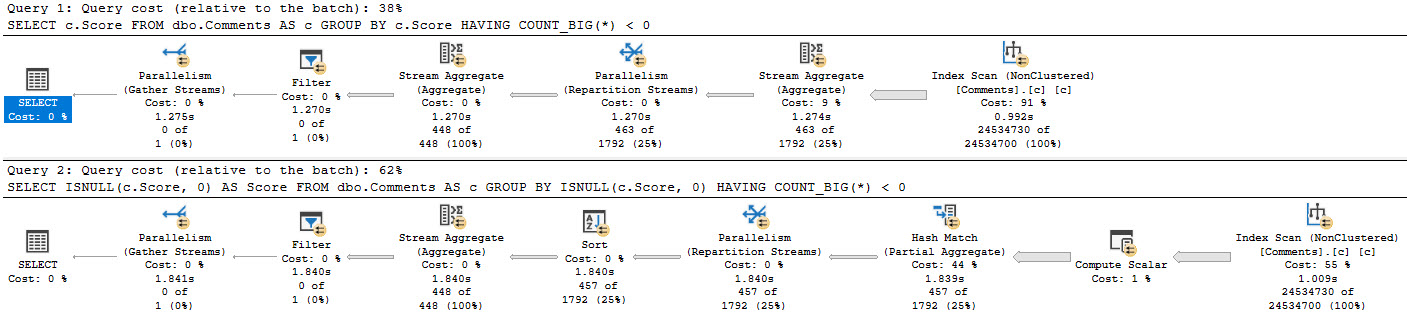
Grouping queries, depending on scope, can also suffer from this. This example isn’t as drastic, but it’s a simple query that still exhibits as decent comparative difference.
SELECT
c.Score
FROM dbo.Comments AS c
GROUP BY
c.Score
HAVING
COUNT_BIG(*) < 0;
SELECT
ISNULL(c.Score, 0) AS Score
FROM dbo.Comments AS c
GROUP BY
ISNULL(c.Score, 0)
HAVING
COUNT_BIG(*) < 0;
To get you back to drinking, here’s both plans.
the opposite of fur
We have, once again, created more work for ourselves. Purely out of vanity.
Indexable
Put yourself in SQL Server’s place here. Maybe the optimizer, maybe the storage engine. Whatever.
If you had to do this work, how would you prefer to do it? Even though I think ISNULL should have better support, it applies to every other function too.
Would you rather:
Process data in the order an index presents it and group/order it
Process data by applying some additional calculation to it and then grouping/ordering
That’s what I thought.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
My dear friend Kendra asked… Okay, look, I might have dreamed this. But I maybe dreamed that she asked what people’s Cost Threshold For Blogging™ is. Meaning, how many times do you have to get asked a question before you write about it.
I have now heard people talking and asking about in-memory table variables half a dozen times, so I guess here we are.
Talking about table variables.
In memory.
Yes, Have Some
First, yes, they do help relieve tempdb contention if you have code that executes under both high concurrency and frequency. And by high, I mean REALLY HIGH.
Like, Snoop Dogg high.
Because you can’t get rid of in memory stuff, I’m creating a separate database to test in.
Here’s how I’m doing it!
CREATE DATABASE trash;
ALTER DATABASE trash
ADD FILEGROUP trashy
CONTAINS MEMORY_OPTIMIZED_DATA ;
ALTER DATABASE trash
ADD FILE
(
NAME=trashcan,
FILENAME='D:\SQL2019\maggots'
)
TO FILEGROUP trashy;
USE trash;
CREATE TYPE PostThing
AS TABLE
(
OwnerUserId int,
Score int,
INDEX o HASH(OwnerUserId)
WITH(BUCKET_COUNT = 100)
) WITH
(
MEMORY_OPTIMIZED = ON
);
GO
Here’s how I’m testing things:
CREATE OR ALTER PROCEDURE dbo.TableVariableTest(@Id INT)
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
DECLARE @t AS PostThing;
DECLARE @i INT;
INSERT @t
( OwnerUserId, Score )
SELECT
p.OwnerUserId,
p.Score
FROM Crap.dbo.Posts AS p
WHERE p.OwnerUserId = @Id;
SELECT
@i = SUM(t.Score)
FROM @t AS t
WHERE t.OwnerUserId = 22656
GROUP BY t.OwnerUserId;
SELECT
@i = SUM(t.Score)
FROM @t AS t
GROUP BY t.OwnerUserId;
END;
GO
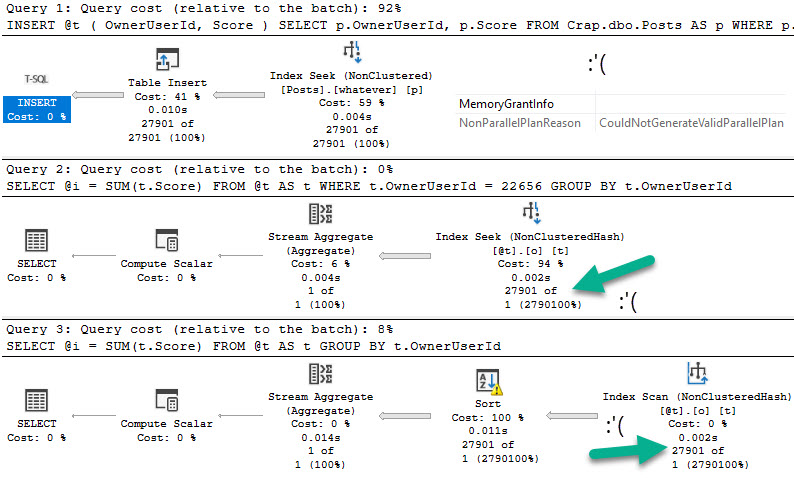
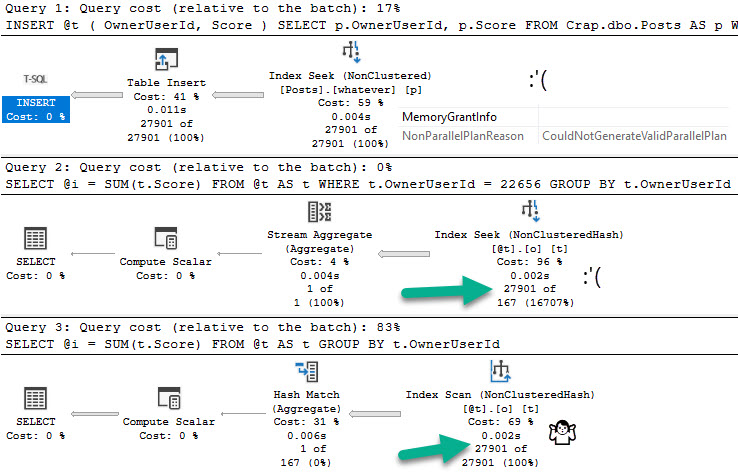
If we flip database compatibility levels to 150, deferred compilation kicks in. Great. Are you on SQL Server 2019? Are you using compatibility level 150?
Don’t get too excited.
Let’s give this a test run in compat level 140:
DECLARE @i INT = 22656;
EXEC dbo.TableVariableTest @Id = @i;
everything counts in large amounts
Switching over to compat level 150:
yeaaahhhhh
Candy Girl
So what do memory optimized table variables solve?
Not the problem that table variables in general cause.
They do help you avoid tempdb contention, but you trade that off for them taking up space in memory.
Precious memory.
Do you have enough memory?
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I got a mailbag question recently about some advice that floats freely around the internet regarding indexing for windowing functions.
But even after following all the best advice that Google could find, their query was still behaving poorly.
Why, why why?
Ten Toes Going Up
Let’s say we have a query that looks something like this:
SELECT
u.DisplayName,
u.Reputation,
p.Score,
p.PostTypeId
FROM dbo.Users AS u
JOIN
(
SELECT
p.Id,
p.OwnerUserId,
p.Score,
p.PostTypeId,
ROW_NUMBER() OVER
(
PARTITION BY
p.OwnerUserId,
p.PostTypeId
ORDER BY
p.Score DESC
) AS n
FROM dbo.Posts AS p
) AS p
ON p.OwnerUserId = u.Id
AND p.n = 1
WHERE u.Reputation >= 500000
ORDER BY u.Reputation DESC,
p.Score DESC;
Without an index, this’ll drag on forever. Or about a minute.
But with a magical index that we heard about, we can fix everything!
Ten Toes Going Down
And so we create this mythical, magical index.
CREATE INDEX bubble_hard_in_the_double_r
ON dbo.Posts
(
OwnerUserId ASC,
PostTypeId ASC,
Score ASC
);
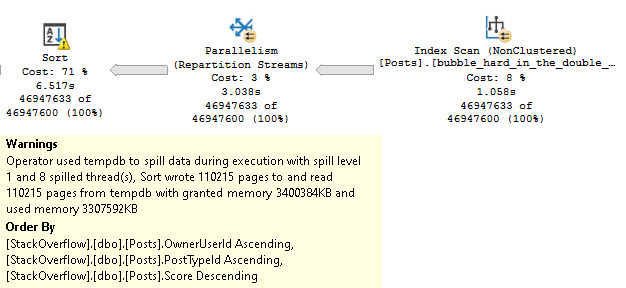
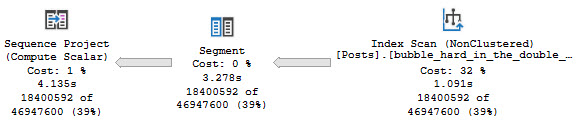
But there’s still something odd in our query plan. Our Sort operator is… Well, it’s still there.
grinch
Oddly, we need to sort all three columns involved in our Windowing Function, even though the first two of them are in proper index order.
OwnerUserId and PostTypeId are both in ascending order. The only one that we didn’t stick to the script on is Score, which is asked for in descending order.
Dram Team
This is a somewhat foolish situation, all around. One column being out of order causing a three column sort is… eh.
We really need this index, instead:
CREATE INDEX bubble_hard_in_the_double_r
ON dbo.Posts
(
OwnerUserId ASC,
PostTypeId ASC,
Score DESC
);
mama mia
Granted, I don’t know that I like this plan at all without parallelism and batch mode, but we’ve been there before.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.