Here’s Another One
In the first post, I looked at a relatively large table. 50 million rows is a decent size.
But 50 million row tables might not be the target audience for this wait.
So, we’re gonna go with a >2 billion row table. Yes, dear reader, this table would break your PUNY INTEGER limits.
Slightly different
The full setup scripts are pretty long, but I’ll show the basic idea here.
Because this table is going to be fairly large, I’m gonna use clustered column store for maximum compressions.
USE StackOverflow2013;
GO
DROP TABLE IF EXISTS dbo.Vetos;
GO
CREATE TABLE dbo.Vetos
(
Id INT NOT NULL,
PostId INT NOT NULL,
UserId INT NULL,
BountyAmount INT NULL,
VoteTypeId INT NOT NULL,
CreationDate DATETIME NOT NULL,
INDEX c CLUSTERED COLUMNSTORE
);
INSERT INTO dbo.Vetos WITH(TABLOCKX)
SELECT ISNULL(v.Id, 0) AS Id,
v.PostId,
v.UserId,
v.BountyAmount,
v.VoteTypeId,
v.CreationDate
FROM
(
SELECT * FROM dbo.Votes
UNION ALL
-- I'm snipping 18 union alls here
SELECT * FROM dbo.Votes
) AS v;
The first test is just with a single statistics object.
CREATE STATISTICS s_UserId ON dbo.Vetos (UserId);
Fork In The Road
Since every sane person in the world knows that updating column store indexes is a donkey, I’m switching to an insert to tick the modification counter up.
INSERT INTO dbo.Vetos WITH(TABLOCKX)
SELECT ISNULL(v.Id, 0) AS Id,
v.PostId,
v.UserId,
v.BountyAmount,
v.VoteTypeId,
v.CreationDate
FROM
(
SELECT * FROM dbo.Votes
UNION ALL
SELECT * FROM dbo.Votes
UNION ALL
SELECT * FROM dbo.Votes
UNION ALL
SELECT * FROM dbo.Votes
UNION ALL
SELECT * FROM dbo.Votes
) AS v;
Query Time
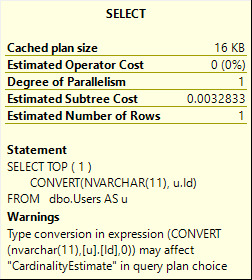
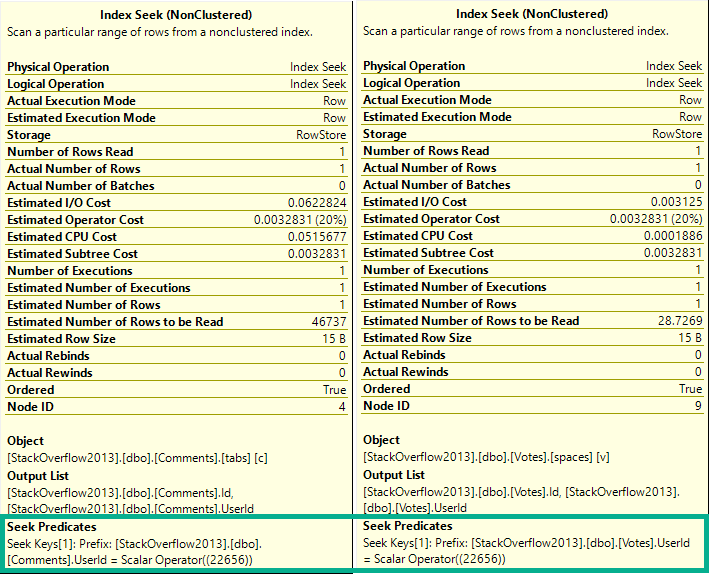
To test the timing out, I can use a pretty simple query that hits the UserId column:
SELECT COUNT_BIG(*) FROM dbo.Vetos WHERE UserId = 138 AND 1 = (SELECT 1);
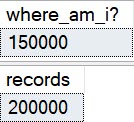
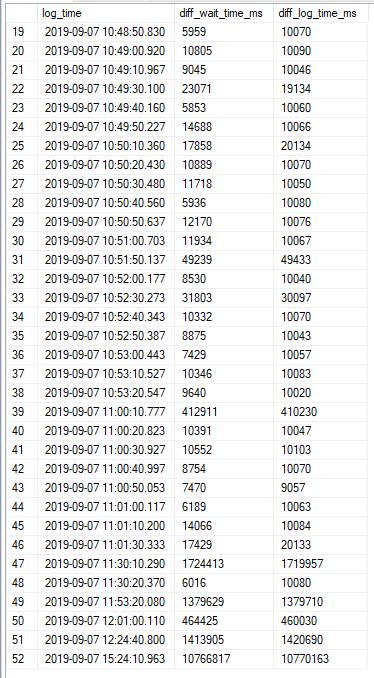
The query runs for ~3 seconds, and…
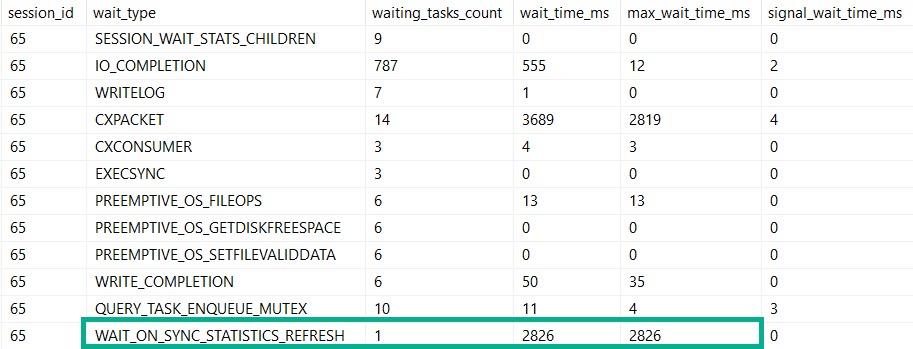
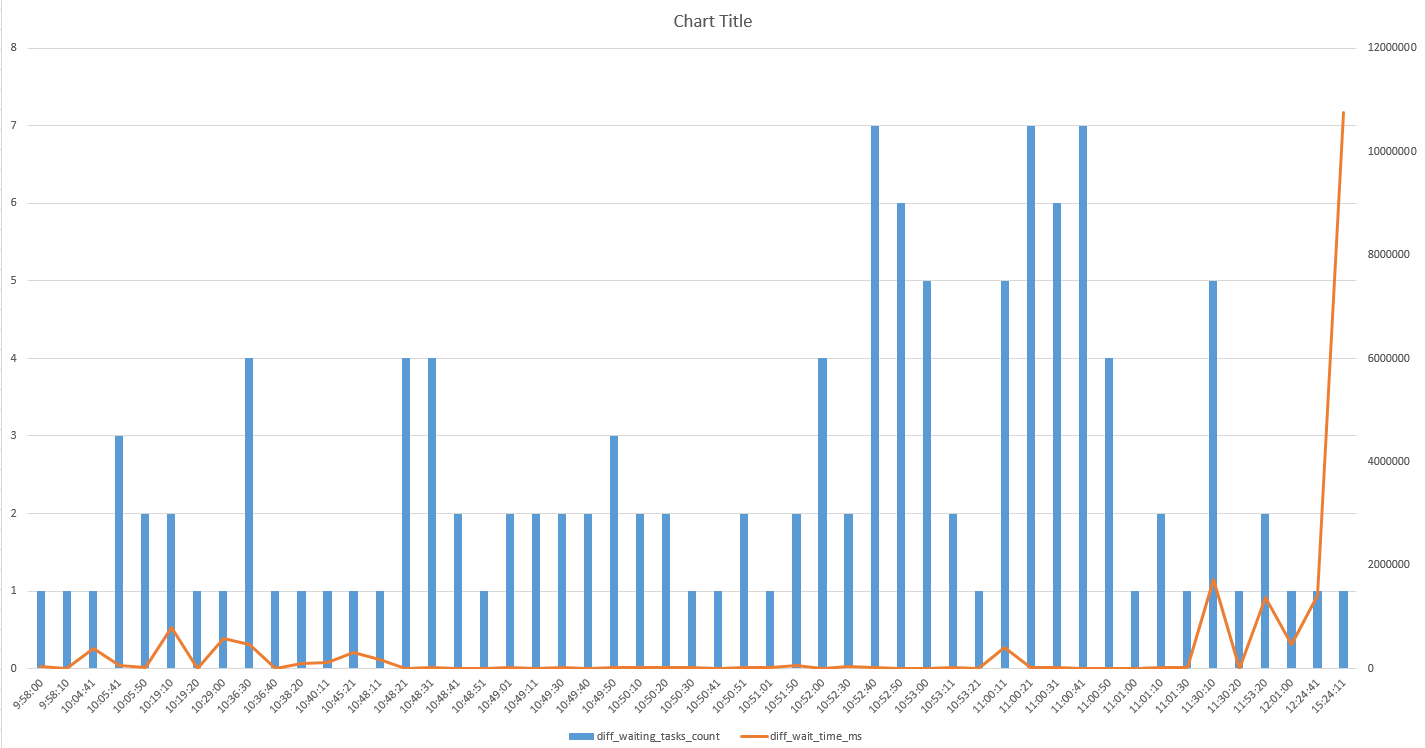
We spent most of that three seconds waiting on the stats refresh.
I know, you’re looking at those parallelism waits.
But what if the stats update went parallel? I’ll come back to this in another post.
Query Times Two
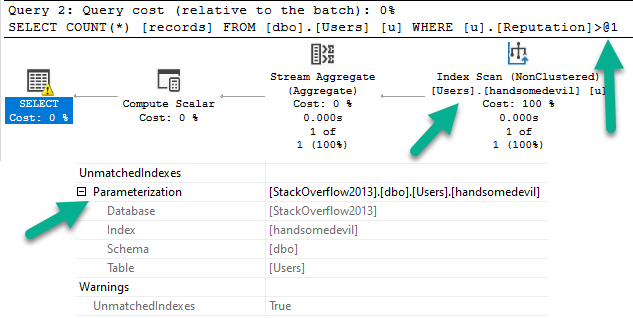
If you’re thinking that I could test this further by adding more stats objects to the UserId column you’d be dreadfully wrong.
SQL Server will only update one stats object per column. What’s the sense in updating a bunch of identical stats objects? I’ll talk about this more in another post, too.
If I reload the table, and create more stats objects on different columns, though…
CREATE STATISTICS s_UserId ON dbo.Vetos (UserId); CREATE STATISTICS s_PostId ON dbo.Vetos (PostId); CREATE STATISTICS s_BountyAmount ON dbo.Vetos (BountyAmount); CREATE STATISTICS s_VoteTypeId ON dbo.Vetos (VoteTypeId); CREATE STATISTICS s_CreationDate ON dbo.Vetos (CreationDate);
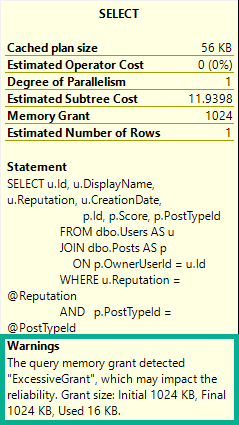
And then write a bigger query after inserting more data to tick up modification counters…
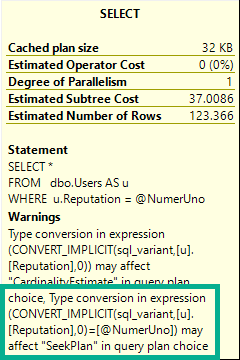
SELECT COUNT(*) FROM dbo.Vetos WHERE UserId = 138 AND PostId = 138 AND BountyAmount = 138 AND VoteTypeId = 138 AND CreationDate = 138;
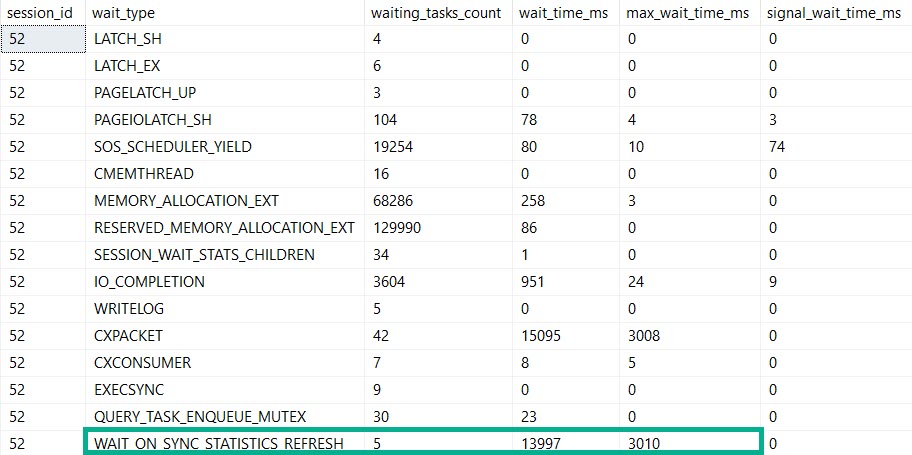
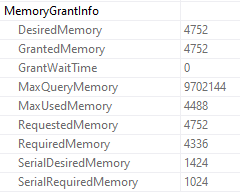
This query runs for 14 seconds, and all of it is spent in the stats update.
Bigger, Badder
Alright, prepare to be blown away: things that are fast against 50 million rows are slower against 2 billion rows.
That include automatic stats updates.
So yeah, if you’re up in the billion row range, automatic stats creation and updates might just start to hurt.
If you move to SQL Server 2019, you’ll have some evidence for when refreshes take a long time, but still nothing for when the initial creation takes a long time.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.