Or Whatever
No technical stuff today. Enjoy your time doing whatever you’re doing, with whoever you’re doing it with.
SQL Server Consulting, Education, and Training
No technical stuff today. Enjoy your time doing whatever you’re doing, with whoever you’re doing it with.
Paul white (b|t) did what I think he does best: make a casual, off-hand remark about something mystifying with such absolute certainty that it makes your brain halt. At least that’s what happens to me.
It all started with:
“The Bitmap is hopeless.”
I’d never considered Bitmaps in excruciating detail.
Sorta Bloom Filter-y. They show up in some parallel Hash and Merge Join plans (simplifying a bit because they’re hidden in serial Hash Join plans).
They seem nice. Early row reductions. Never thought of one as “hopeless”.
But then!
Let’s take a look at a plan with a hopeless Bitmap.
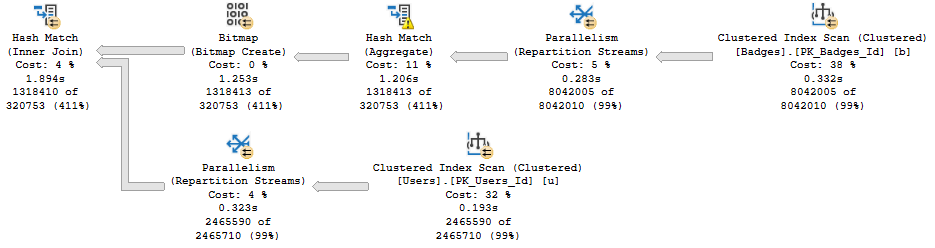
In the outer (top) branch of the plan, a Bitmap is created. It gets applied at the Scan of the Users table.
What makes it hopeless?
In other words, the Bitmap barely filtered out any rows whatsoever. Did it hurt performance? Am I mad at Bitmaps? No and no.
At least not here.
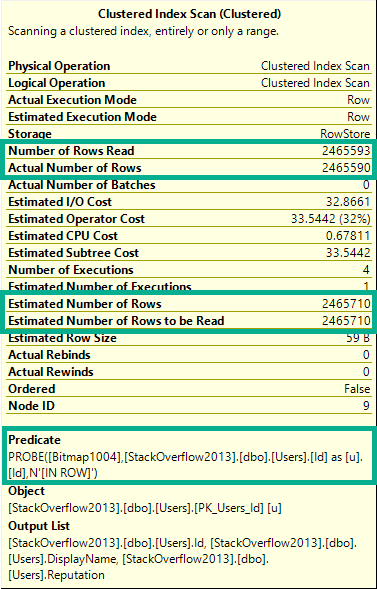
In some query plans, the Bitmap may not make it all the way down to the Scan operator.
If there’s a Partial Aggregate after the Scan, you may find the Bitmap applied at the Repartition Streams.
Better late than never, I suppose.
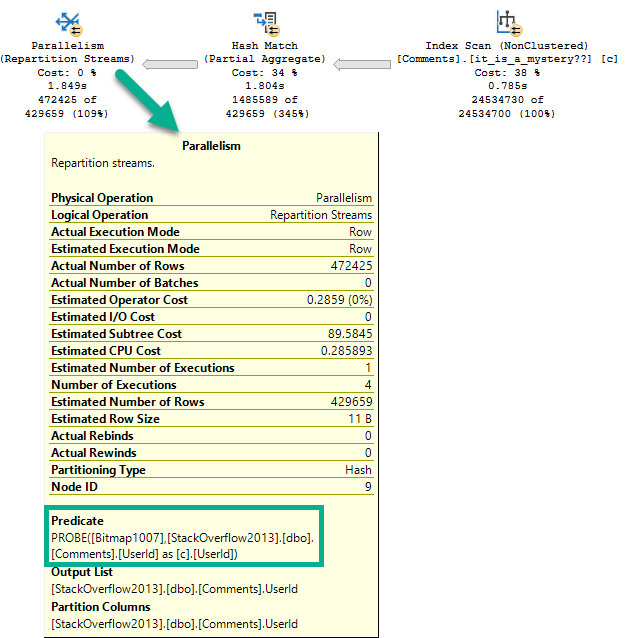
In a helpful Bitmap plan, the details look much different.
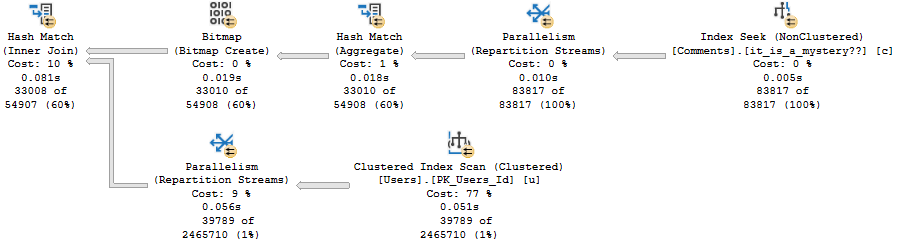
Visually, this plan looks much different than the Hopeless Bitmap plan.
The number of rows (39,789) read from the scan is much lower than the table cardinality (2,465,710).
The details of the scan are also interesting.
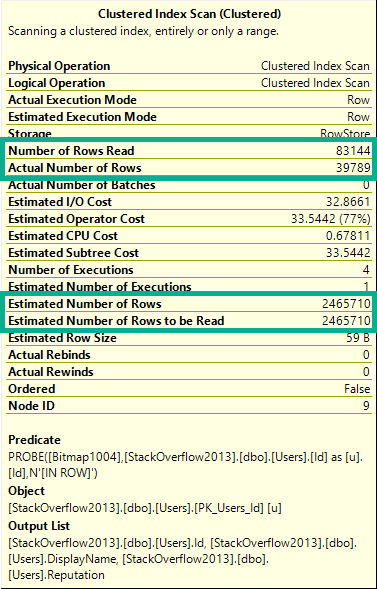
That’s a Bangin’ Bitmap.
Thanks for reading!
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
It’s been a while since SQL Server has had a real RECOMPILE problem. And if you put it up against the performance problems that you can hit with parameter sniffing, I’d have a hard time telling someone strapped for time and knowledge that it’s the worst idea for them.
Obviously, you can run into problems if you (“you” includes Entity Framework, AKA the Database Demolisher) author the kind of queries that take a very long time to compile. But as I list them out, I’m kinda shrugging.
Here are some problems you can hit with recompile. Not necessarily caused by recompile, but by not re-using plans.
But for everything in the middle: a little RECOMPILE probably won’t hurt that bad.
Thinking of the problems it can solve:
Those are very real problems that I see on client systems pretty frequently. And yeah, sometimes there’s a good tuning option for these, like changing or adding an index, moving parts of the query around, sticking part of the query in a temp table, etc.
But all that assumes that those options are immediately available. For third party vendors who have somehow developed software that uses SQL Server for decades without running into a single best practice even by accident, it’s often harder to get those changes through.
Sure, you might be able to sneak a recompile hint somewhere in the mix even if it’d make the vendor upset. You can always yoink it out later.
But you have alternatives, too.
Using a plan guide doesn’t interfere with that precious vendor IP that makes SQL Server unresponsive every 15 minutes. Or whatever. I’m not mad.
And yeah, there’s advances in SQL Server 2017 and 2019 that start to address some issues here, but they’re still imperfect.
I like’em, but you know. They’re not quite there yet.
Thanks for reading!
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Let’s say you have a parallel query running at DOP 4. The final logic of the query is some aggregate: COUNT, SUM, MIN, MAX, whatever.
Sure, the optimizer could gather all the streams, and then calculate one of those for all four of them, but why do that?
We have a Partial Aggregate operator that allows an aggregate per thread to be locally aggregated, then a final global aggregate can be more quickly calculated from the four locally aggregated values.
There are a couple odd things about Partial Aggregates though:
Which is why for identical executions of identical queries, you may see different numbers of rows come out of them.
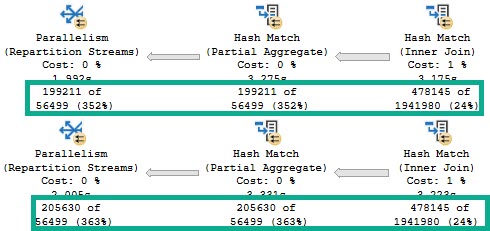
We start with the same number of rows coming out of the Hash Join, which is expected.
We ran the same query.
However, the Partial Aggregate emits different numbers of rows.
It doesn’t matter much, because the global aggregate later in the plan will still be able to figure things out, albeit slightly less efficiently.

If we look at the spills in the Hash Match Aggregates from both of the above plans, the warnings are slightly different.
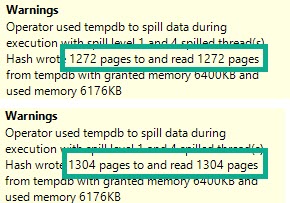
Hardly anything to worry about here, of course. But definitely something to be aware of.
No, SQL Server isn’t leaking memory, or full of bugs. It’s just sensitive.
Thanks for reading!
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I’m excited about this feature. I’m not being negative, here. I just want you, dear reader, to have reasonable expectations about it.
This isn’t a post about it making a query slower, but I do have some demos of that happening. I want to show you an example of it not kicking in when it probably should. I’m going to use an Extended Events session that I first read about on Dmitry Pilugin’s blog here. It’ll look something like this.
CREATE EVENT SESSION heristix
ON SERVER
ADD EVENT sqlserver.batch_mode_heuristics
( ACTION( sqlserver.sql_text ))
ADD TARGET package0.event_file
( SET filename = N'c:\temp\heristix' )
WITH
( MAX_MEMORY = 4096KB,
EVENT_RETENTION_MODE = ALLOW_SINGLE_EVENT_LOSS,
MAX_DISPATCH_LATENCY = 1 SECONDS,
MAX_EVENT_SIZE = 0KB,
MEMORY_PARTITION_MODE = NONE,
TRACK_CAUSALITY = OFF,
STARTUP_STATE = ON );
GO
Let’s start with some familiar indexes and a familiar query from other posts the last couple weeks.
CREATE INDEX something ON dbo.Posts(PostTypeId, Id, CreationDate); CREATE INDEX stuffy ON dbo.Comments(PostId, Score, CreationDate);
SELECT COUNT(*)
FROM dbo.Posts AS p
JOIN dbo.Comments AS c
ON p.Id = c.PostId
WHERE DATEDIFF(YEAR, p.CreationDate, c.CreationDate) > 1
AND p.PostTypeId = 1
AND c.Score > 0;
The query plan is unimportant. It just doesn’t use any Batch Mode, and takes right about 2 seconds.
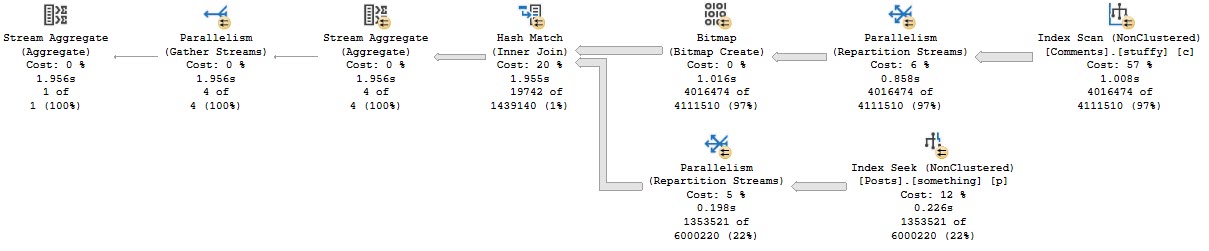
If we look at the entry for this query in our XE session, we can see that the optimizer considered the heck out of Batch Mode, but decided against it.
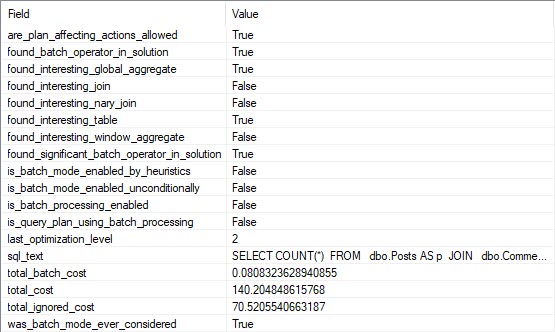
If we add a hash join hint to the query, it finishes in about 800ms.
SELECT COUNT(*)
FROM dbo.Posts AS p
JOIN dbo.Comments AS c
ON p.Id = c.PostId
WHERE DATEDIFF(YEAR, p.CreationDate, c.CreationDate) > 1
AND p.PostTypeId = 1
AND c.Score > 0
OPTION(HASH JOIN);
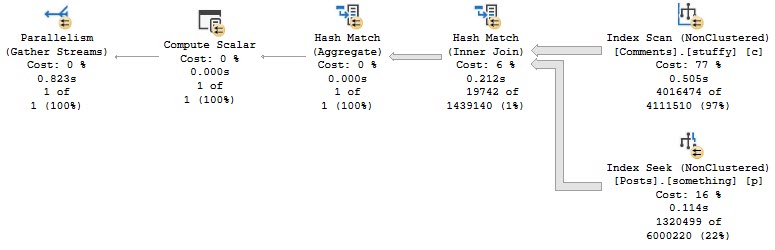
All the operators in this plan except Gather Streams are run in Batch Mode. Clearly it was helpful.
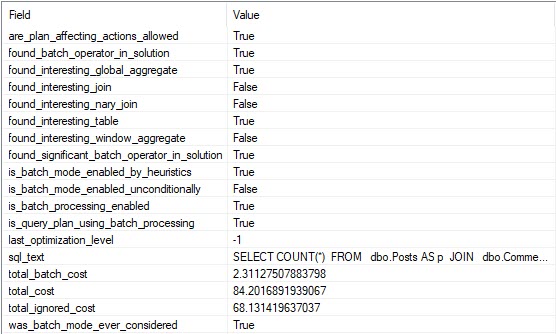
And according to the XE session, we can see that decision in writing. Yay.
If we modify our indexes slightly, we can get an Adaptive Join plan.
CREATE INDEX something_alt ON dbo.Posts(PostTypeId, CreationDate, Id); CREATE INDEX stuffy_alt ON dbo.Comments(Score, CreationDate, PostId);
And, yes, this is about twice as fast now (compared to the last Batch Mode query), mostly because of the better indexing.
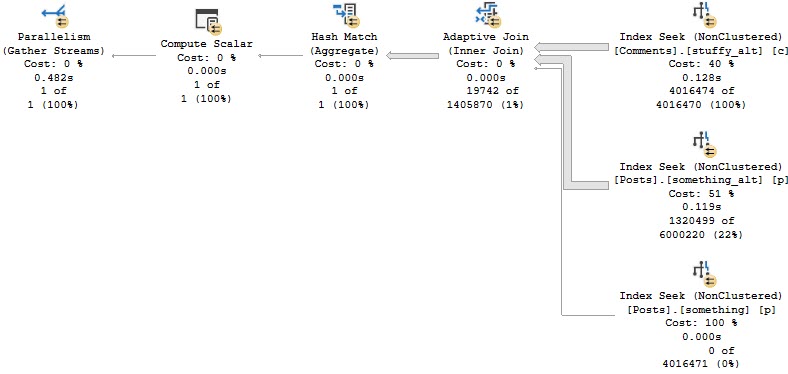
Yes, don’t count on Batch Mode to kick in for every query where it would be helpful.
If you want queries to consistently use Batch Mode, you’ll need to do something like this.
SELECT COUNT(*)
FROM dbo.Posts AS p
JOIN dbo.Comments AS c
ON p.Id = c.PostId
LEFT JOIN dbo.t ON 1 = 0
WHERE DATEDIFF(YEAR, p.CreationDate, c.CreationDate) > 1
AND p.PostTypeId = 1
AND c.Score > 0;
But you have to be careful there too.
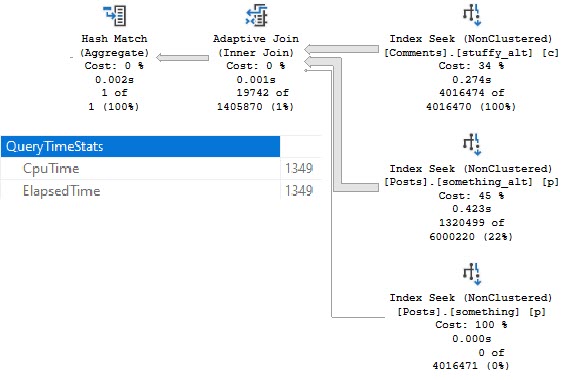
You might lose your nice parallel plan and end up with a slower query.
Huh.
Thanks for reading!
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Intermediate result materialization is one of the most successful tuning methods that I regularly use.
Separating complexity is only second to eliminating complexity. Of course, sometimes those intermediate results need indexing to finish the job.
Not always. But you know. I deal with some weird stuff.
Like anime weird.
Regular ol’ #temp tables can have just about any kind of index plopped on them. Clustered, nonclustered, filtered, column store (unless you’re using in-memory tempdb with SQL Server 2019). That’s nice parity with regular tables.
Of course, lots of indexes on temp tables have the same problem as lots of indexes on regular tables. They can slow down loading data in, especially if there’s a lot. That’s why I usually tell people load first, create indexes later.
There are a couple ways to create indexes on #temp tables:
/*Create, then add*/ CREATE TABLE #t (id INT NOT NULL); /*insert data*/ CREATE CLUSTERED INDEX c ON #t(id);
/*Create inline*/
CREATE TABLE #t(id INT NOT NULL,
INDEX c CLUSTERED (id));
It depends on what problem you’re trying to solve:
Another option to help with #temp table recompiles is the KEEPFIXED PLAN hint, but to wit I’ve only ever seen it used in sp_WhoIsActive.
Often forgotten is that table variables can be indexed in many of the same ways (at least post SQL Server 2014, when the inline index create syntax came about). The only kinds of indexes that I care about that you can’t create on a table variable are column store and filtered (column store generally, filtered pre-2019).
Other than that, it’s all fair game.
DECLARE @t TABLE( id INT NOT NULL,
INDEX c CLUSTERED (id),
INDEX n NONCLUSTERED (id) );
You can create clustered and nonclustered indexes on them, they can be unique, you can add primary keys.
It’s a whole thing.
In SQL Server 2019, we can also create indexes with included columns and filtered indexes with the inline syntax.
CREATE TABLE #t( id INT,
more_id INT,
INDEX c CLUSTERED (id),
INDEX n NONCLUSTERED (more_id) INCLUDE(id),
INDEX f NONCLUSTERED (more_id) WHERE more_id > 1 );
DECLARE @t TABLE ( id INT,
more_id INT,
INDEX c CLUSTERED (id),
INDEX n NONCLUSTERED (more_id) INCLUDE(id),
INDEX F NONCLUSTERED (more_id) WHERE more_id > 1 );
Notice that I’m not talking about CTEs here. You can’t index create indexes on those.
Perhaps that’s why they’re called “common”.
Yes, you can index the underlying tables in your query, but the results of CTEs don’t get physically stored anywhere that would allow you to create an index on them.
Thanks for reading!
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
This was originally posted by me as an answer here. I’m re-posting it locally for posterity.
We’ll look at a few of the reasons in more detail, and also talk about some of the general limitations of the feature.
First, from: Limitations of the Missing Indexes Feature:
- It does not specify an order for columns to be used in an index.
As noted in this Q&A: How does SQL Server determine key column order in missing index requests?, the order of columns in the index definition is dictated by Equality vs Inequality predicate, and then column ordinal position in the table.
There are no guesses at selectivity, and there may be a better order available. It’s your job to figure that out.
Special Indexes
Missing index requests also don’t cover ‘special’ indexes, like:
Missing Index key columns are generated from columns used to filter results, like those in:
Missing Index Included columns are generated from columns required by the query, like those in:
Even though quite often, columns you’re ordering by or grouping by can be beneficial as key columns. This goes back to one of the Limitations:
- It is not intended to fine tune an indexing configuration.
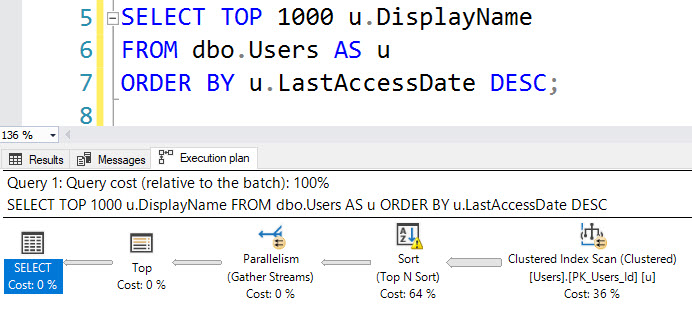
For example, this query will not register a missing index request, even though adding an index on LastAccessDate would prevent the need to Sort (and spill to disk).
SELECT TOP (1000) u.DisplayName FROM dbo.Users AS u ORDER BY u.LastAccessDate DESC;
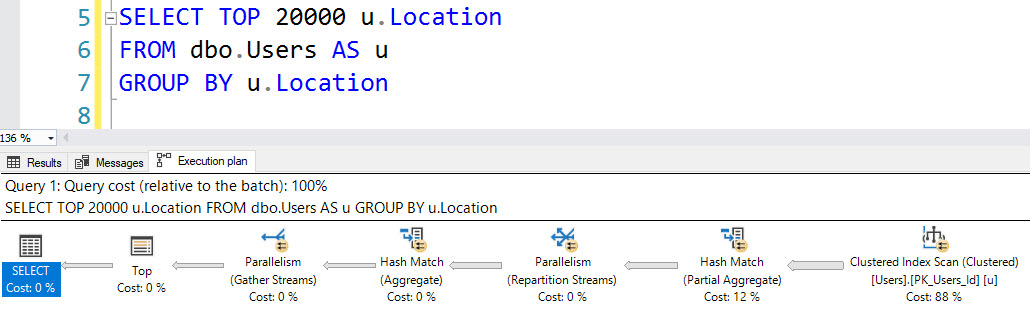
Nor does this grouping query on Location.
SELECT TOP (20000) u.Location FROM dbo.Users AS u GROUP BY u.Location
Well, yeah, but it’s better than nothing. Think of missing index requests like a crying baby. You know there’s a problem, but it’s up to you as an adult to figure out what that problem is.
Relax, bucko. We’re getting there.
If you enable TF 2330, missing index requests won’t be logged. To find out if you have this enabled, run this:
DBCC TRACESTATUS;
Rebuilding indexes will clear missing index requests. So before you go Hi-Ho-Silver-Away rebuilding every index the second an iota of fragmentation sneaks in, think about the information you’re clearing out every time you do that.
You may also want to think about Why Defragmenting Your Indexes Isn’t Helping, anyway. Unless you’re using Columnstore.
Adding, removing, or disabling an index will clear all of the missing index requests for that table. If you’re working through several index changes on the same table, make sure you script them all out before making any.
If a plan is simple enough, and the index access choice is obvious enough, and the cost is low enough, you’ll get a trivial plan.
This effectively means there were no cost based decisions for the optimizer to make.
Via Paul White:
The details of which types of query can benefit from Trivial Plan change frequently, but things like joins, subqueries, and inequality predicates generally prevent this optimization.
When a plan is trivial, additional optimization phases are not explored, and missing indexes are not requested.
See the difference between these queries and their plans:
SELECT * FROM dbo.Users AS u WHERE u.Reputation = 2; SELECT * FROM dbo.Users AS u WHERE u.Reputation = 2 AND 1 = (SELECT 1);
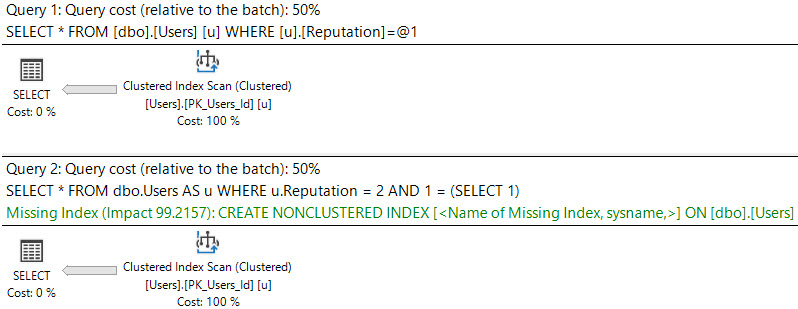
The first plan is trivial, and no request is shown. There may be cases where bugs prevent missing indexes from appearing in query plans; they are usually more reliably logged in the missing index DMVs, though.
Predicates where the optimizer wouldn’t be able to use an index efficiently even with an index may prevent them from being logged.
Things that are generally not SARGable are:
SELECT * FROM dbo.Users AS u WHERE ISNULL(u.Age, 1000) > 1000; SELECT * FROM dbo.Users AS u WHERE DATEDIFF(DAY, u.CreationDate, u.LastAccessDate) > 5000; SELECT * FROM dbo.Users AS u WHERE u.UpVotes + u.DownVotes > 10000000; DECLARE @ThisWillHappenWithStoredProcedureParametersToo NVARCHAR(40) = N'Eggs McLaren'; SELECT * FROM dbo.Users AS u WHERE u.DisplayName LIKE @ThisWillHappenWithStoredProcedureParametersToo OR @ThisWillHappenWithStoredProcedureParametersToo IS NULL;
None of these queries will register missing index requests. For more information on these, check out the following links:
Take this index:
CREATE INDEX ix_whatever ON dbo.Posts(CreationDate, Score) INCLUDE(OwnerUserId);
It looks okay for this query:
SELECT p.OwnerUserId, p.Score FROM dbo.Posts AS p WHERE p.CreationDate >= '20070101' AND p.CreationDate < '20181231' AND p.Score >= 25000 AND 1 = (SELECT 1) ORDER BY p.Score DESC;
The plan is a simple Seek…

But because the leading key column is for the less-selective predicate, we end up doing more work than we should:
Table ‘Posts’. Scan count 13, logical reads 136890
If we change the index key column order, we do a lot less work:
CREATE INDEX ix_whatever ON dbo.Posts(Score, CreationDate) INCLUDE(OwnerUserId);

And significantly fewer reads:
Table ‘Posts’. Scan count 1, logical reads 5
In certain cases, SQL Server will choose to create an index on the fly via an index spool. When an index spool is present, a missing index request won’t be. Surely adding the index yourself could be a good idea, but don’t count on SQL Server helping you figure that out.
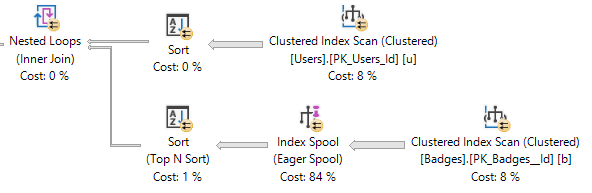
Thanks for reading!
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Last week’s thrilling, stunning, flawless episode of whatever-you-wanna-call-it.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I’ll sometimes see people implement retry logic to catch deadlocks, which isn’t a terrible idea by itself. The problem that may arise is when the deadlock monitor takes a full 5 seconds to catch a query, which can block other queries, and may generally make things feel slower.
An alternative is to set a lock timeout that’s shorter than five seconds.
DECLARE @lock_try INT = 0
WHILE @lock_try < 5
BEGIN
BEGIN TRY
SET LOCK_TIMEOUT 5; /*five milliseconds*/
SELECT COUNT(*) AS records FROM dbo.Users AS u;
END TRY
BEGIN CATCH
IF ERROR_NUMBER() <> 1222 /*Lock request time out period exceeded.*/
RETURN;
END CATCH;
SET @lock_try += 1;
WAITFOR DELAY '00:00:01.000' /*Wait a second and try again*/
END;
While 5 milliseconds is maybe an unreasonably short time to wait for a lock, I’d rather you start low and go high if you’re trying this at home. The catch block is set up to break if we hit an error other than 1222, which is what gets thrown when a lock request times out.
This is a better pattern than just hitting a deadlock, or just waiting for a deadlock to retry. Normally when a deadlock occurs, one query throws an error, and there’s no attempt to try it again (unless a user is sitting there hitting submit until something works). Waiting ~5 seconds (I know I’m simplifying here, and the deadlock monitor will wake up more frequently after it detects one)
The big question is: are you better off doing this in T-SQL than in your application?
Thanks for reading!
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
It’s sorta kinda pretty crazy when every major database platform has something implemented, and SQL Server doesn’t.
Geez, even MySQL.
But a fairly common need in databases is to find the max value from two columns.
Maybe even across two tables.
For one table, it’s fairly straight forward.
SELECT MAX(x.CombinedDate) AS greatest FROM dbo.Users AS u CROSS APPLY( VALUES( u.CreationDate ), ( u.LastAccessDate )) AS x( CombinedDate );
We’re using our old friend cross apply with a values clause to create on “virtual” column from two date columns.
As far as indexing goes, I couldn’t find any performance difference between these two. They both take about 1 second.
CREATE INDEX smoochies ON dbo.Users(CreationDate, LastAccessDate); CREATE INDEX woochies ON dbo.Users(LastAccessDate, CreationDate);
Indexing strategy will likely rely on other local factors, like any where clause filtering.
A similar pattern will work across two tables:
SELECT MAX(x.Score)
FROM dbo.Posts AS p
JOIN dbo.Comments AS c
ON p.Id = c.PostId
CROSS APPLY( VALUES( p.Score ), ( c.Score )) AS x ( Score );
Though this is the worst possible way to write the query. It runs for around 10 seconds.
The indexes I have for this query look like so:
CREATE INDEX thicc ON dbo.Posts(Id, Score); CREATE INDEX milky ON dbo.Comments(PostId, Score);
Reversing the key column order helps — the query runs in about 3 seconds, but I need to force index usage.
Of course, this is still the second worst way to write this query.
The best way I’ve found to express this query looks like so:
SELECT MAX(x.Score)
FROM
(
SELECT MAX(p.Score) AS Score
FROM dbo.Posts AS p
) AS p
CROSS JOIN
(
SELECT MAX(c.Score) AS Score
FROM dbo.Comments AS c
) AS c
CROSS APPLY( VALUES( p.Score ), ( c.Score )) AS x( Score );
The cross join here isn’t harmful because we only produce two rows.
And it finishes before we have time to move the mouse.

Likewise, the faster pattern for a single table looks like this:
SELECT MAX(x.Dates)
FROM
(
SELECT MAX(u.CreationDate) CreationDate
FROM dbo.Users AS u
) AS uc
CROSS JOIN
(
SELECT MAX(u.LastAccessDate) LastAccessDate
FROM dbo.Users AS u
) AS ul
CROSS APPLY (VALUES (uc.CreationDate), (ul.LastAccessDate)) AS x (Dates);
Because we’re able to index for each MAX
CREATE INDEX smoochies ON dbo.Users(CreationDate); CREATE INDEX woochies ON dbo.Users(LastAccessDate);
Of course, not every query can be written like this, or indexed for perfectly, but it’s gruel for thought if you need specific queries like this to be as fast as possible.
Thanks for reading!
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.