Be Yourself
We’ve got a problem, Sam Houston. We’ve got a problem with a query that has some strange issues.
It’s not parameter sniffing, but it sure could feel like it.
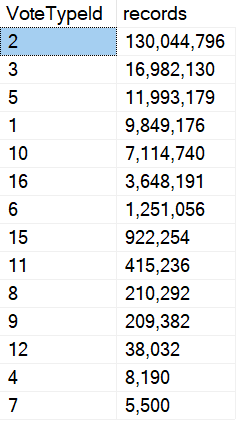
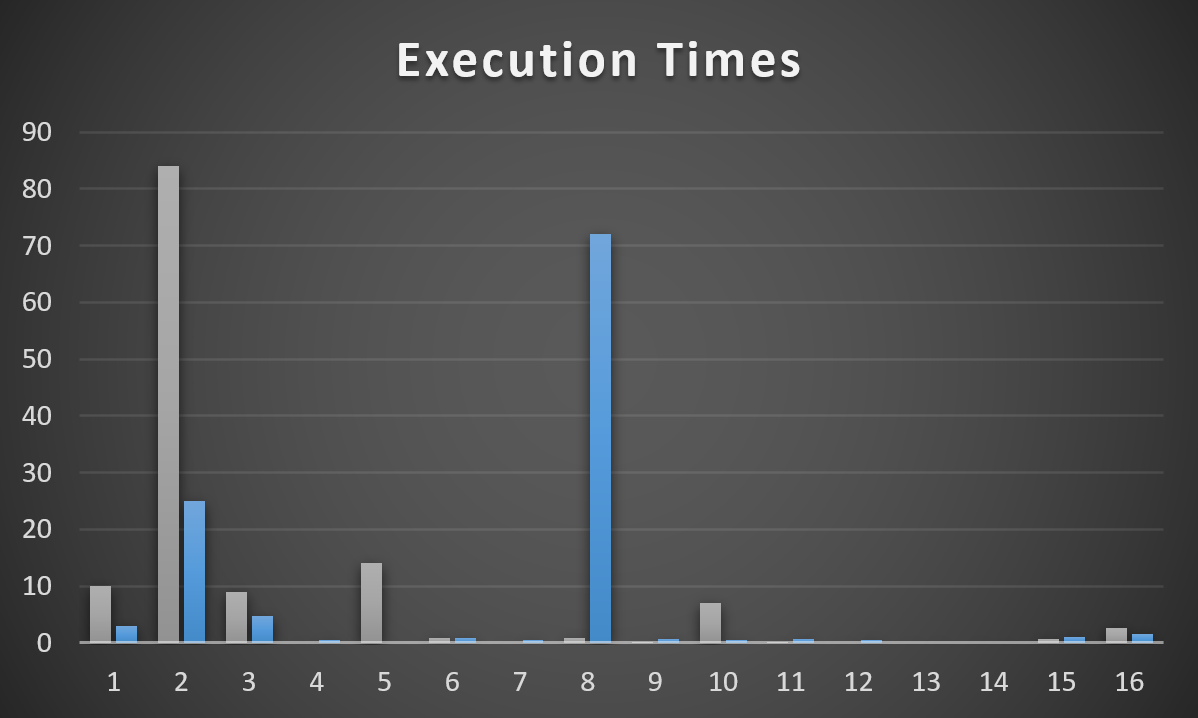
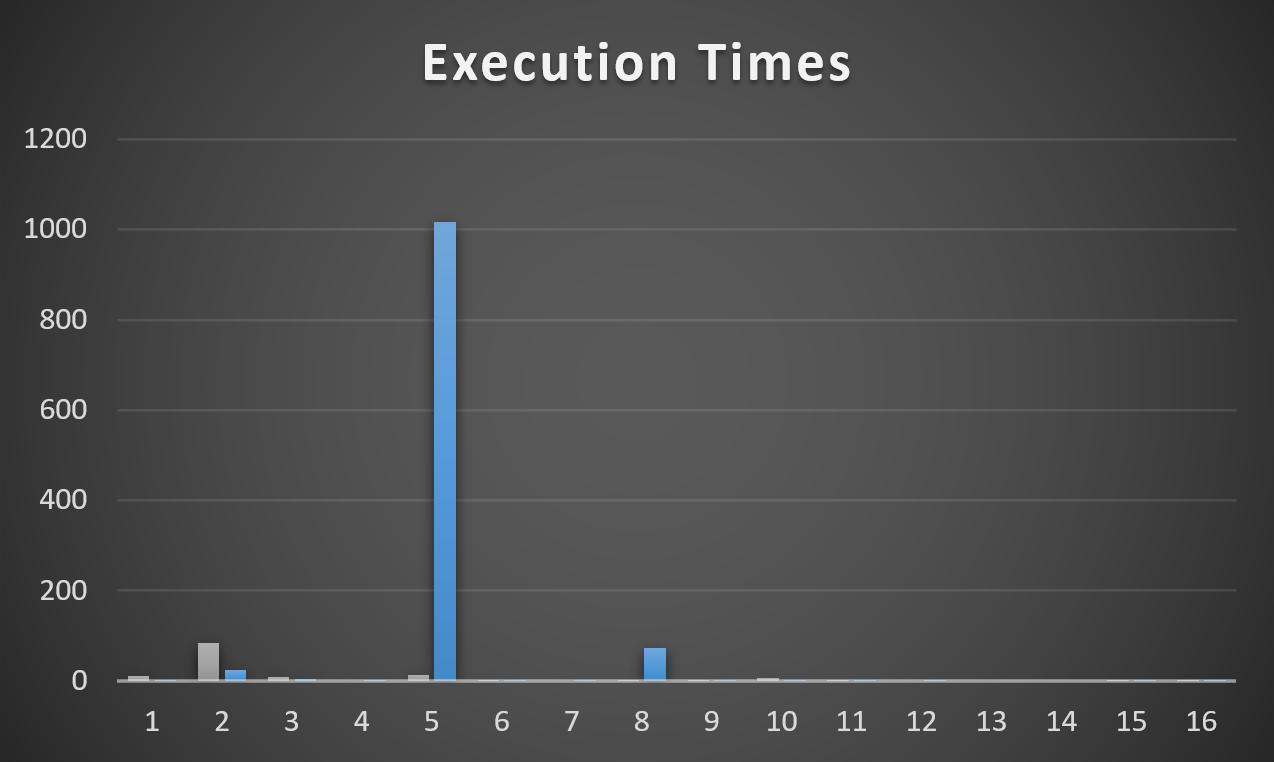
- When the procedure compiles and runs with VoteTypeId 5, it runs for 12 minutes
- Other VoteTypeIds run well with the same plan that VoteTypeId 5 gets
- When VoteTypeId 5 runs with a “small” plan, it does okay at 10 seconds
Allow me to ruin a graph to illustrate. The Y axis is still seconds, but… it goes up a little higher now.
The Frustration (A Minor Digression)
Here’s where life can be tough when it comes to troubleshooting actual parameter sniffing.
If you’re relying solely on the plan cache, you’re screwed. You’ll see the plan, and the compile value, but you won’t have the runtime value anywhere that “caused” the problem. In other words, the set of parameters that were adversely affected by the query plan that didn’t fit.
There are some things that can help, like if you’re watching it happen live, or if you have a monitoring tool that might capture runtime parameters.
OR IF YOU USE SP UNDERSCORE HUMANEVENTS.
Like I said, this isn’t parameter sniffing, but it feels like it.
It could extra-feel like it because you might see a misbehaving query, and a compile-time parameter that runs quickly on its own when you test it, e.g. VoteTypeId 6.
It would be really hard to tell that even if a plan were to compile specifically for a different parameter, it would still run for 12 minutes.
Heck, that’d even catch me off-guard.
But that’s what we have here: VoteTypeId 5 gets a bad plan special for VoteTypeId 5.
Examiner
Let’s dig in on what’s happening to cause us such remarkable grief. There has to be a reason.
I don’t need more grief without reason; I’ve already got a public school education.
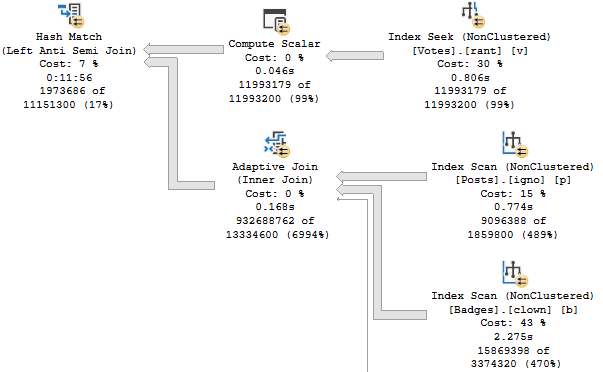
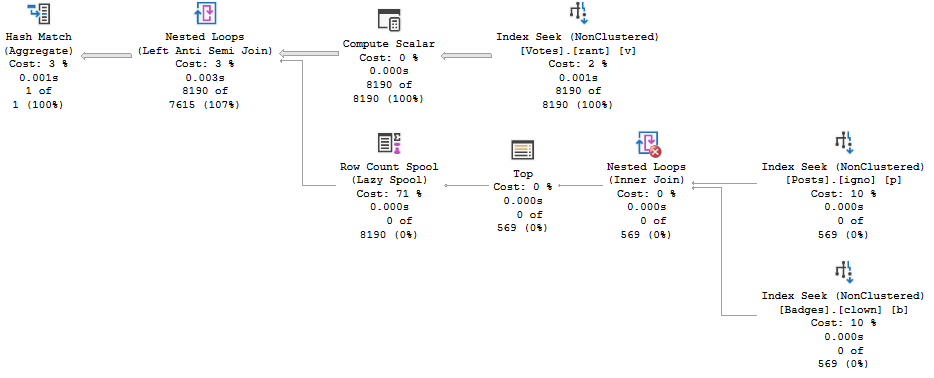
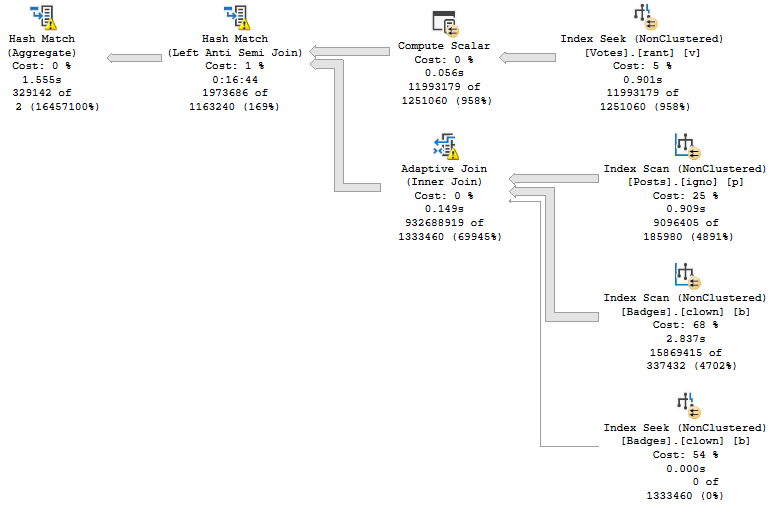
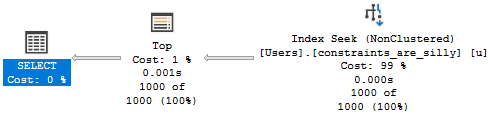
If we were to summarize the problem here: that Hash Match Left Anti Semi Join runs for 12 minutes on its own.
No other operator, or group of operators, is responsible for a significant amount of time comparatively.
Magnifier
Some things to note:
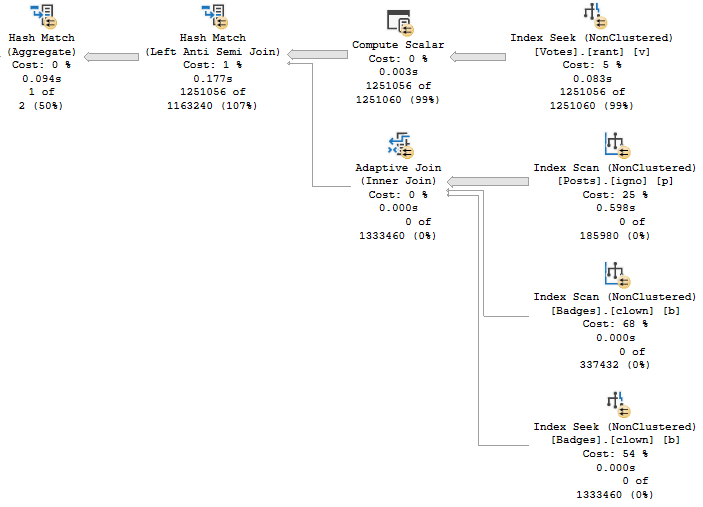
- The bad estimates aren’t from predicates, they’re from Batch Mode Bitmaps
- Those bad estimates end up producing a much larger number of rows from the Adaptive Join
- The Hash Match ends up needing to probe 932 million rows
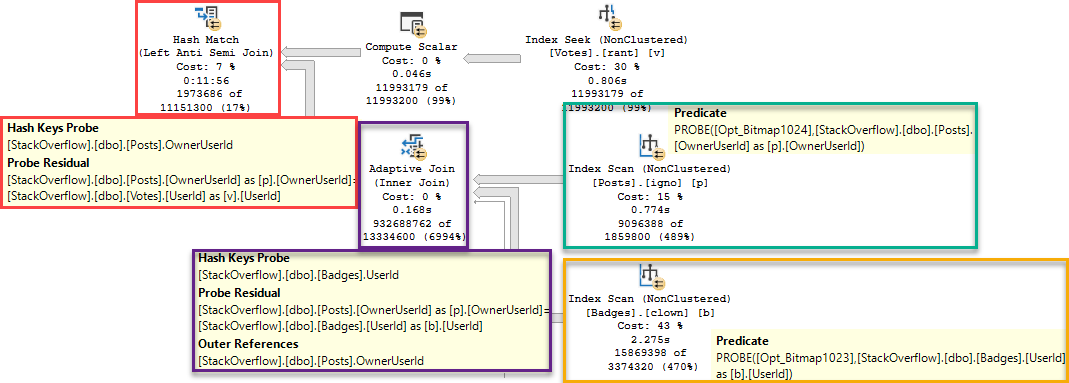
Taking 12 minutes to probe 932 million rows is probably to be expected, now that I think about it.
If the optimizer had a good estimate from the Bitmaps here, it may have done the opposite of what a certain Pacific Island Dwelling Bird said:
Getting every nuance of this sort of relational transformation correct can be tricky. It is very handy that the optimizer team put the effort in so we do not have to explore these tricky rewrites manually (e.g. by changing the query text). If nothing else, it would be extremely tedious to write all the different query forms out by hand just to see which one performed better in practice. Never mind choosing a different version depending on current statistics and the number of changes to the table.
In this case, the Aggregate happens after the join. If the estimate were correct, or even in the right spacetime dimension, this would be fine.
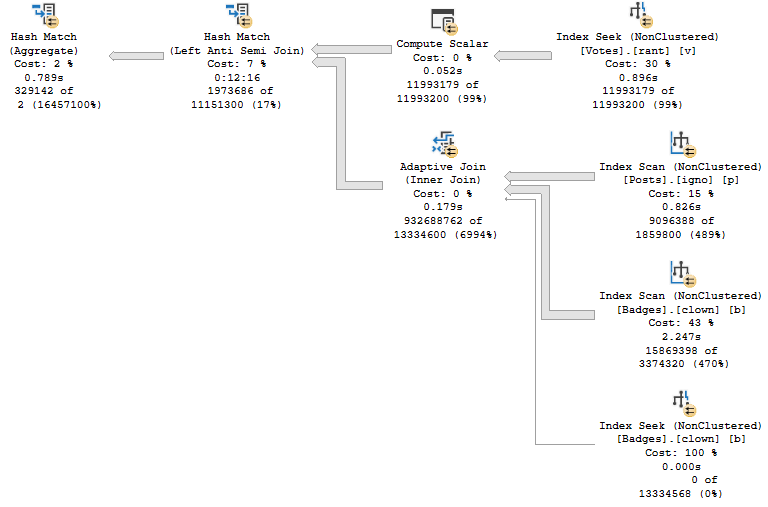
We can gauge the general efficiency of it by looking at when this plan is used for other parameters that produce numbers of rows that are closer to this estimate.
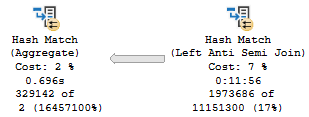
If the optimizer had made a good guess for this parameter, it may have changed the plan to put an aggregate before the join.
Unfortunately we have very little control over estimates for Bitmaps, and the guesses for Batch Mode Bitmaps are a Shrug of Atlassian proportions.
Finisher
We’ve learned some things:
- This isn’t parameter sniffing
- Batch Mode Bitmaps wear pants on their head
- Batch Mode Bitmaps set their head-pants on fire
- Most of the time Batch Mode performance covers this up
- The plan for VoteTypeId 5 is not a good plan for VoteTypeId 5
- The plan for VoteTypeId 5 is great for a lot of other VoteTypeIds
In tomorrow’s post, we’ll look at how we can fix the problem.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.