I Have A Secret To Tell You
If you haven’t heard by now, Table Variables have some ✌features✌ that can cause performance issues pretty generally in SQL Server.
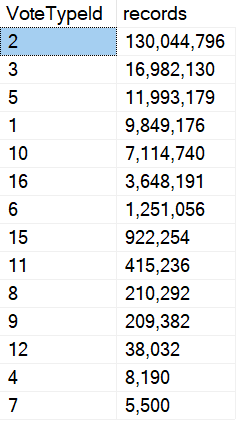
- One row estimates unless you recompile (or that darn trace flag)
- No column-level statistics (even with indexes)
- Modifications to them can’t go parallel (without sorcery)
But in SQL Server 2019, Microsoft fixed one of those things, kind of, with Table Variable Deferred Compilation.
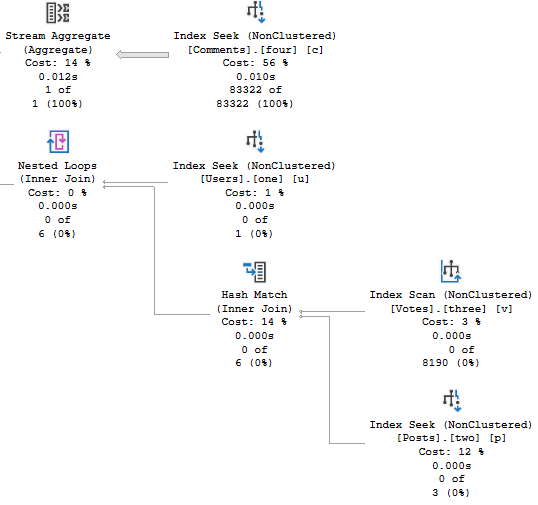
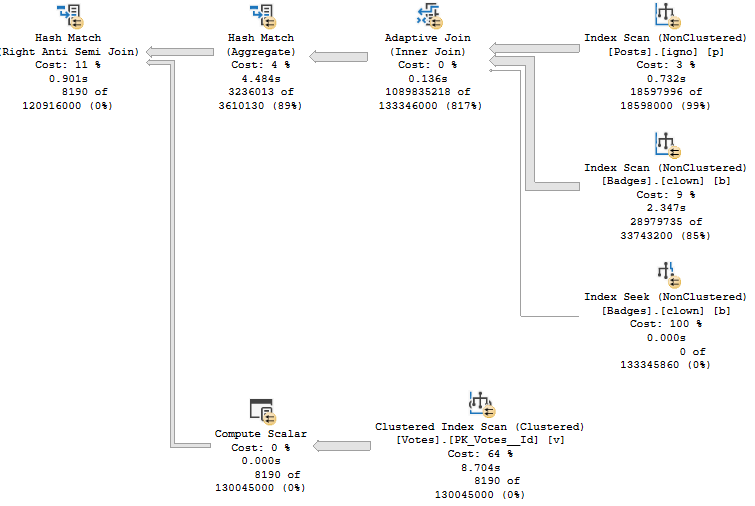
Rather than just give you that one row estimate, it’ll wait until you’ve loaded data in, and then it will use table cardinality for things like joins to the table variable. Just be careful when you use them in stored procedures.
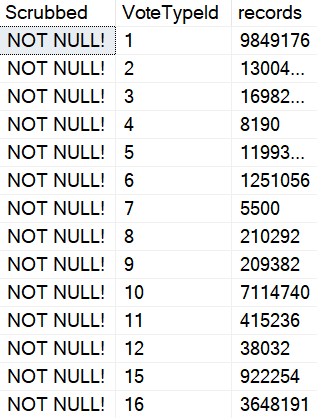
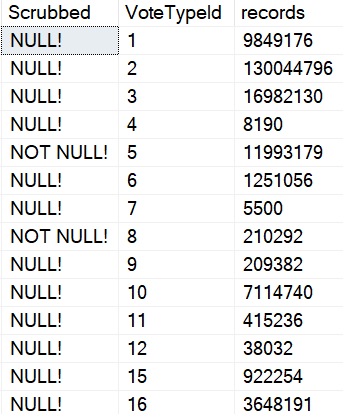
That can be a lot more helpful than what you currently get, but the guesses aren’t quite as helpful when you start using a where clause, because there still aren’t column-level statistics. You get the unknown guess for those.
How Can You Test It Out Before SQL Server 2019?
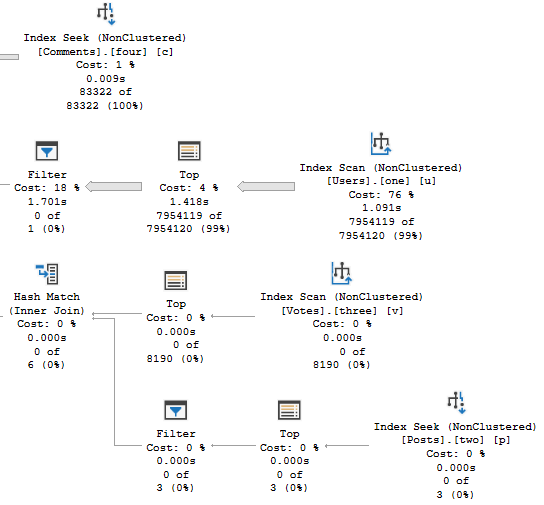
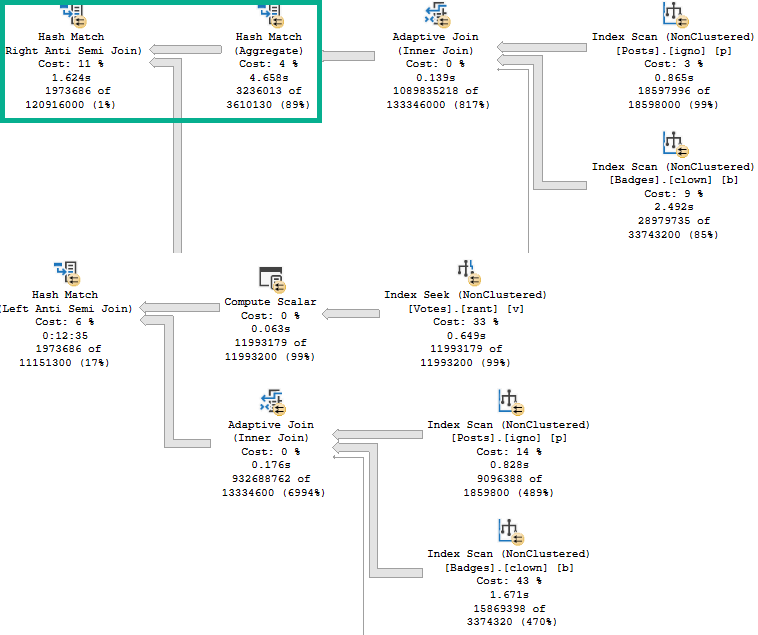
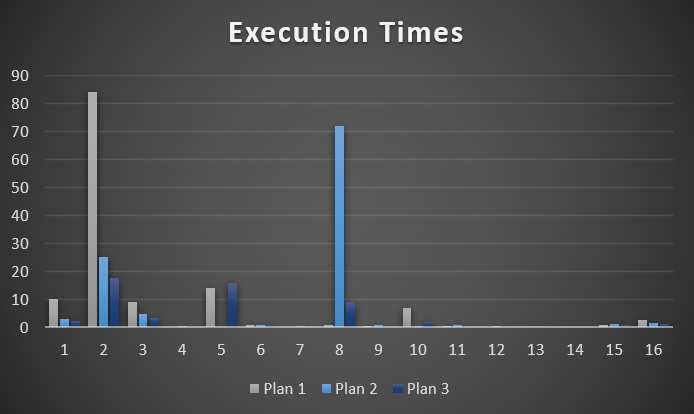
You can use #temp tables.
That’s right, regular old #temp tables.
They’ll give you nearly the same results as Table Variable Deferred Compilation in most cases, and you don’t need trace flags, hints, or or SQL Server 2019.
Heck, you might even fall in love with’em and live happily ever after.
The Fine Print
I know, some of you are out there getting all antsy-in-the-pantsy about all the SQL Jeopardy differences between temp tables and table variables.
I also realize that this may seem overly snarky, but hear me out:
Sure, there are some valid reasons to use table variables at times. But to most people, the choice about which one to use is either a coin flip or a copy/paste of what they saw someone else do in other parts of the code.
In other words, there’s not a lot of thought, and probably no adequate testing behind the choice. Sort of like me with tattoos.
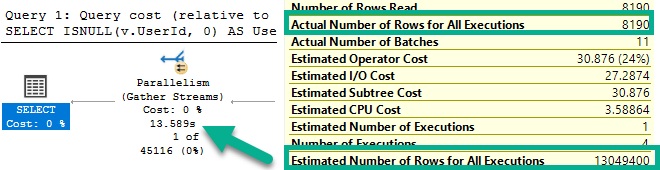
Engine enhancements like this that benefit people who can’t change the code (or who refuse to change the code) are pretty good indicators of just how irresponsible developers have been with certain ✌features✌. I say this because I see it week after week after week. The numbers in Azure had to have been profound enough to get this worked on, finally.
I can’t imagine how many Microsoft support tickets have been RCA’d as someone jamming many-many rows in a table variable, with the only reasonable solution being to use a temp table instead.
I wish I could say that people learned the differences a lot faster when they experienced some pain, but time keeps proving that’s not the case. And really, it’s hardly ever the software developers who feel it with these choices: it’s the end users.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.