Speed Limit
When I’m blogging about performance tuning, most of it is from the perspective of Enterprise Edition. That’s where you need to be if you’re serious about getting SQL Server to go as fast as possible. Between the unrealistic memory limits and other feature restrictions, Standard Edition just doesn’t hold up.
Sure, you can probably get by with it for a while, but once performance becomes a primary concern it’s time to fork over an additional 5k a core for the big boat.
They don’t call it Standard Edition because it’s The Standard, like the hotel. Standard is a funny word like that. It can denote either high or low standing through clever placement of “the”. Let’s try an experiment:
- Erik’s blogging is standard for technical writing
- Erik’s blogging is the standard for technical writing
Now you see where you stand with standard edition. Not with “the”, that’s for sure. “The” has left the building.
Nerd Juice
A lot of the restrictions for column store in Standard Edition are documented, but:
- DOP limit of two for queries
- No parallelism for creating or rebuilding indexes
- No aggregate pushdown
- No string predicate pushdown
- No SIMD support
Here’s a comparison for creating a nonclustered column store index in Standard and Enterprise/Developer Editions:
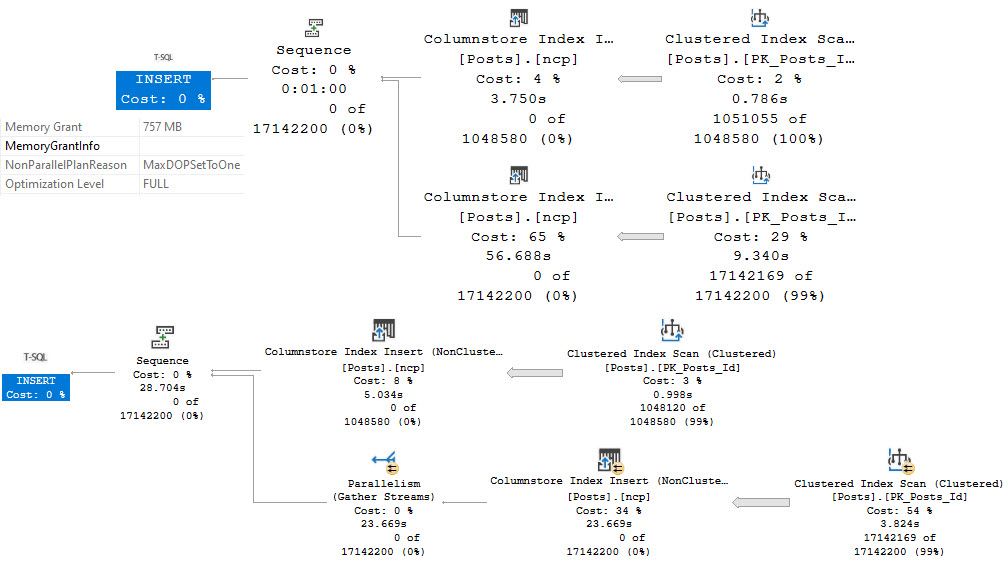
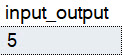
The top plan is from Standard Edition, and runs for a minute in a full serial plan. There is a non-parallel plan reason in the operator properties: MaxDOPSetToOne.
I do not have DOP set to one anywhere, that’s just the restriction kicking in. You can try it out for yourself if you have Standard Edition sitting around somewhere. I’m doing all my testing on SQL Server 2019 CU9. This is not ancient technology at the time of writing.
The bottom plan is from Enterprise/Developer Edition, where the the plan is able to run partially in parallel, and takes 28 seconds (about half the time as the serial plan).
Query Matters
One of my favorite query tuning tricks is getting batch mode to happen on queries that process a lot of rows. It doesn’t always help, but it’s almost always worth trying.
The problem is that on Standard Edition, if you’re processing a lot of rows, being limited to a DOP of 2 can be a real hobbler. In many practical cases, a batch mode query at DOP 2 will end up around the same as a row mode query at DOP 8. It’s pretty unfortunate.
In some cases, it can end up being much worse.
SELECT
MIN(p.Id) AS TinyId,
COUNT_BIG(*) AS records
FROM dbo.Posts AS p WITH(INDEX = ncp)
JOIN dbo.Votes AS v
ON p.Id = v.PostId
WHERE p. OwnerUserId = 22656;
SELECT
MIN(p.Id) AS TinyId,
COUNT_BIG(*) AS records
FROM dbo.Posts AS p WITH(INDEX = 1)
JOIN dbo.Votes AS v
ON p.Id = v.PostId
WHERE p. OwnerUserId = 22656;
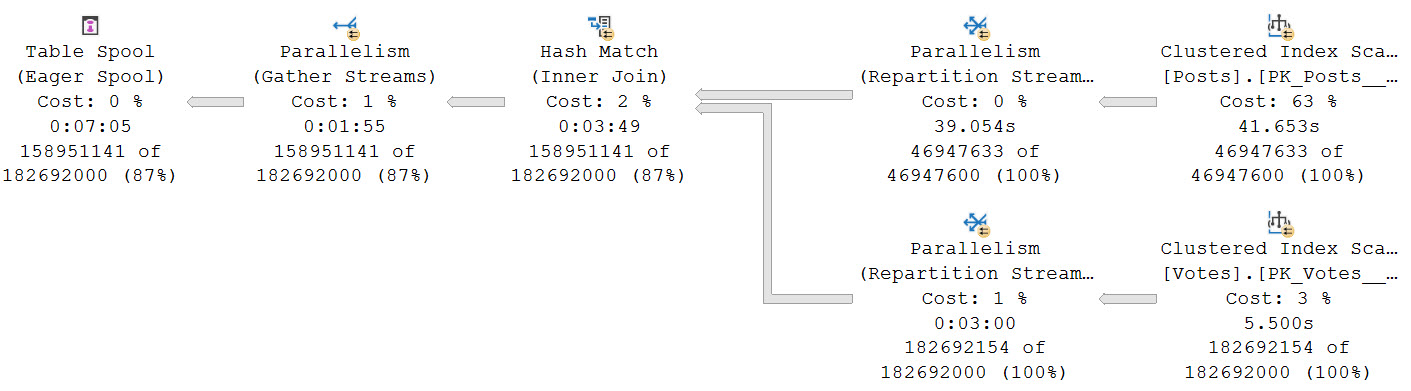
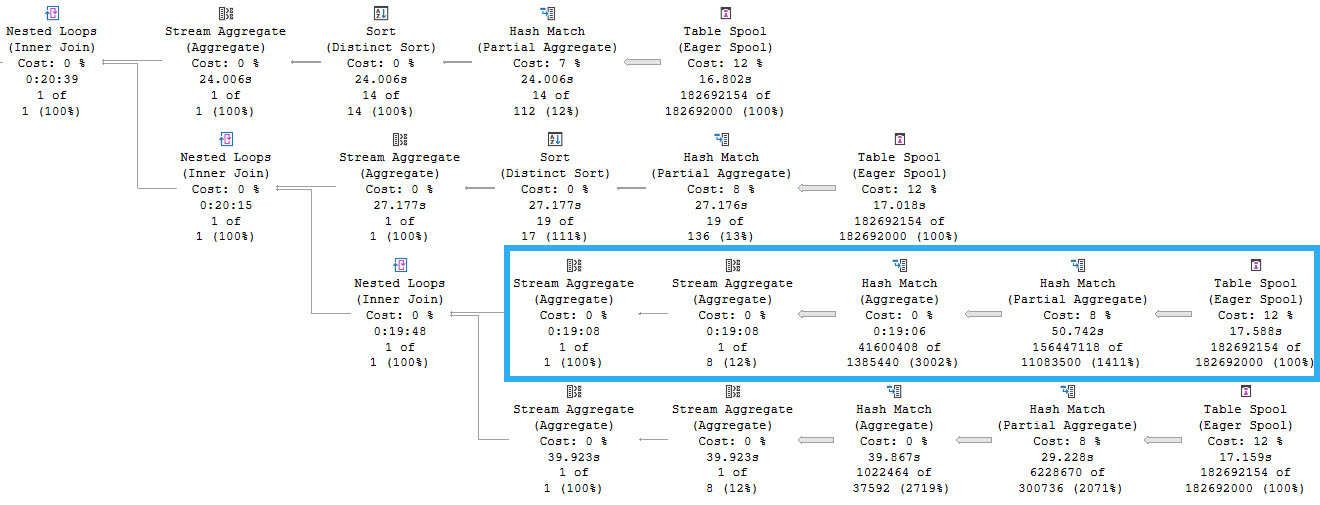
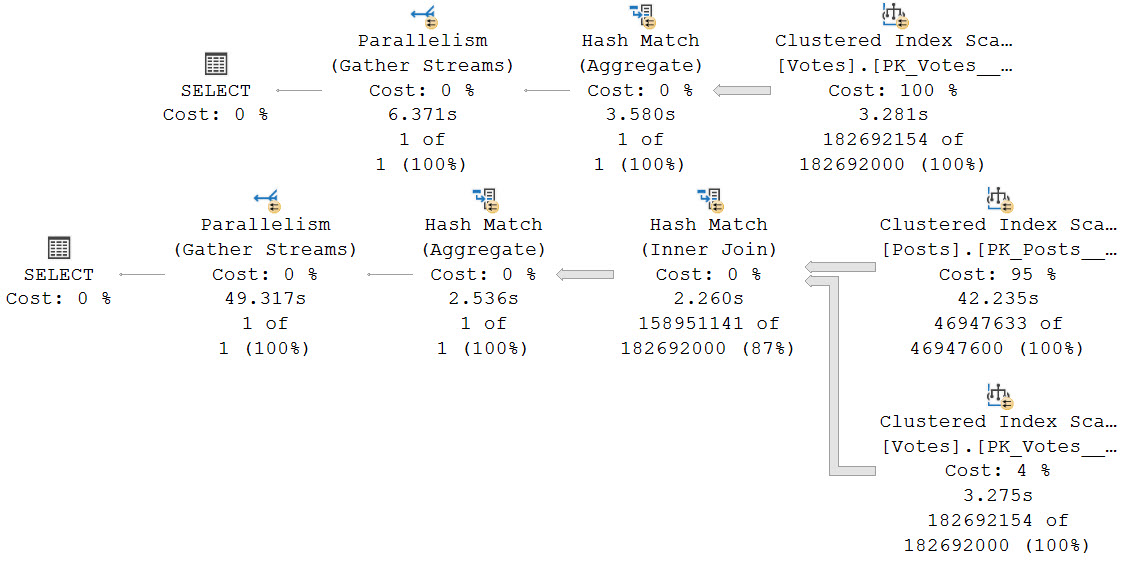
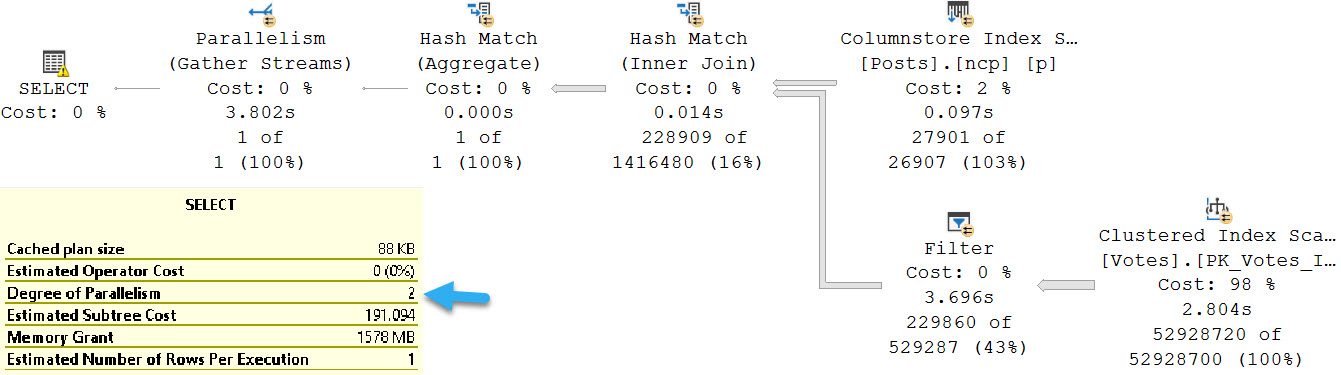
Here’s the query plan for the first one, which uses the nonclustered column store index on Posts. There is no hint or setting that’s keeping DOP at 2, this really is just a feature restriction.
Higher Ground
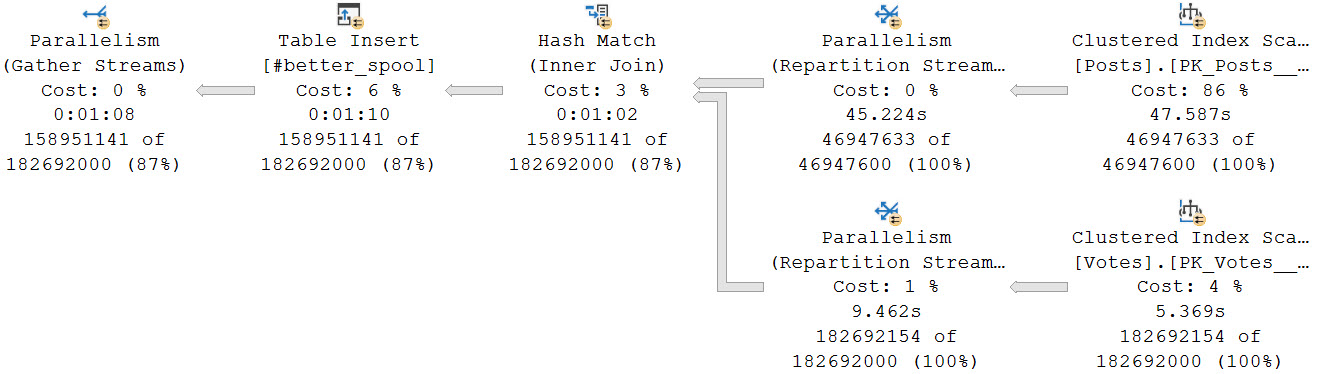
The second query, which is limited by the MAXDOP setting to 8, turns out much faster. The batch mode query takes 3.8 seconds, and the row mode query takes 1.4 seconds.

In Enterprise Edition, there are other considerations for getting batch mode going, like memory grant feedback or adaptive joins, but those aren’t available in Standard Edition.
In a word, that sucks.
Dumb Limit
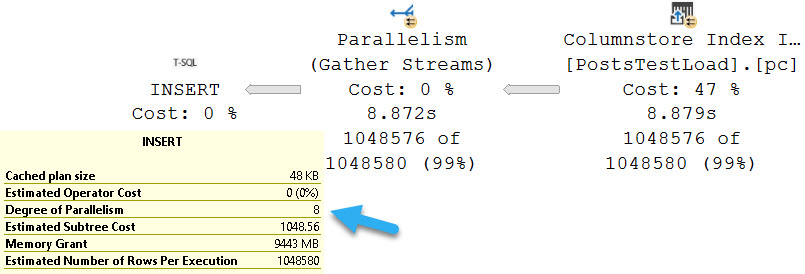
The restrictions on creating and rebuilding column store indexes to DOP 1 (both clustered and nonclustered), and queries to DOP 2 all seems even more odd when we consider that there is no restriction on inserting data into a table with a column store index on it.
As an example:
SELECT
p.*
INTO dbo.PostsTestLoad
FROM dbo.Posts AS p
WHERE 1 = 0;
CREATE CLUSTERED COLUMNSTORE INDEX pc ON dbo.PostsTestLoad;
SET IDENTITY_INSERT dbo.PostsTestLoad ON;
INSERT dbo.PostsTestLoad WITH(TABLOCK)
(
Id, AcceptedAnswerId, AnswerCount, Body, ClosedDate,
CommentCount, CommunityOwnedDate, CreationDate,
FavoriteCount, LastActivityDate, LastEditDate,
LastEditorDisplayName, LastEditorUserId, OwnerUserId,
ParentId, PostTypeId, Score, Tags, Title, ViewCount
)
SELECT TOP (1024 * 1024)
p.Id, p.AcceptedAnswerId, p.AnswerCount, p.Body, p.ClosedDate, p.
CommentCount, p.CommunityOwnedDate, p.CreationDate, p.
FavoriteCount, p.LastActivityDate, p.LastEditDate, p.
LastEditorDisplayName, p.LastEditorUserId, p.OwnerUserId, p.
ParentId, p.PostTypeId, p.Score, p.Tags, p.Title, p.ViewCount
FROM dbo.Posts AS p;
SET IDENTITY_INSERT dbo.PostsTestLoad OFF;
Unsupportive Parents
These limits are asinine, plain and simple, and I hope at some point they’re reconsidered. While I don’t expect everything from Standard Edition, because it is Basic Cable Edition, I do think that some of the restrictions go way too far.
Perhaps an edition somewhere between Standard and Enterprise would make sense. When you line the two up, the available features and pricing are incredibly stark choices.
There are often mixed needs as well, where some people need Standard Edition with fewer HA restrictions, and some people need it with fewer performance restrictions.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.