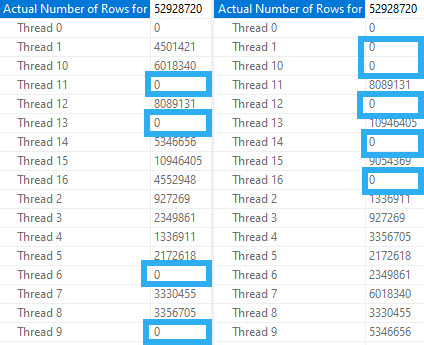
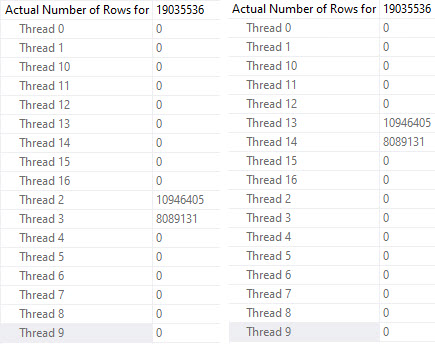
Kickball
To start things off, we’re going to talk about query plan patterns related to windowing functions.
There are several things to consider with windowing function query plans:
- Row vs Batch mode
- With and Without Partition By
- Index Support for Partition and Order By
- Column SELECTion
- Rows vs Range/Global aggregates
We’ll get to them in separate posts, because there are particulars about them that would make covering them all in a single post unwieldy.
Anyway, the first one is pretty simple, and starting simple is about my speed.
Row Mode
I’m doing all of this work in SQL Server 2019, with the database in compatibility level 150. It makes my life easier.
First, here’s the query we’ll be using. The only difference will be removing the hint to allow for Batch Mode later on.
WITH Comments AS
(
SELECT
ROW_NUMBER() OVER
(
PARTITION BY
c.UserId
ORDER BY
c.CreationDate
) AS n
FROM dbo.Comments AS c
)
SELECT
c.*
FROM Comments AS c
WHERE c.n = 0
OPTION(USE HINT('QUERY_OPTIMIZER_COMPATIBILITY_LEVEL_140'));
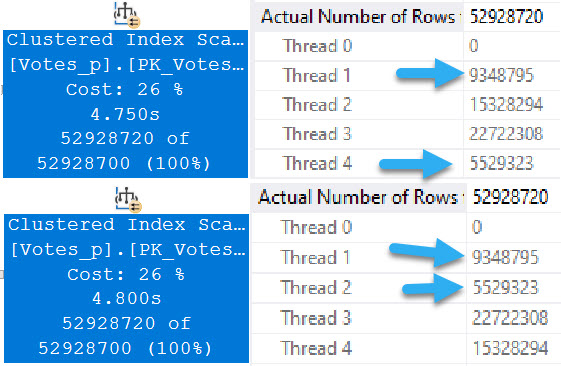
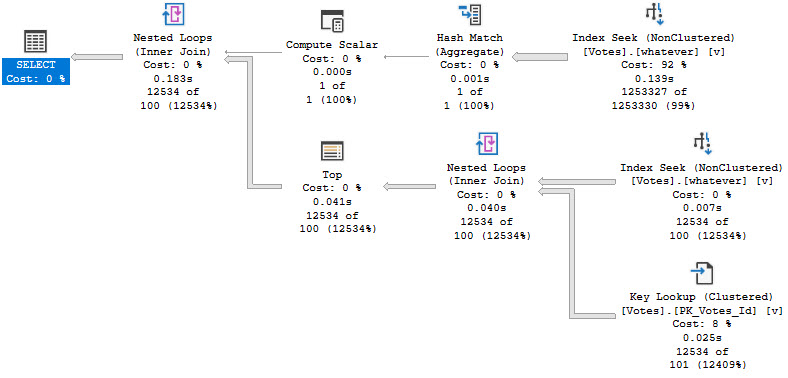
Part of the row mode query plan will look like this:
The two operators that generate the numbering are the Segment and Sequence Project.
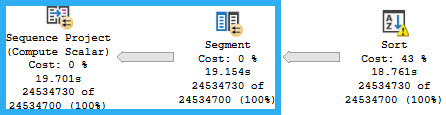
We’ll talk about the Sort later on. For now, we can see the segment “grouping” by UserId, and the Sequence Project description notes that it works over an ordered set.
You can probably guess why we need the Sort here.
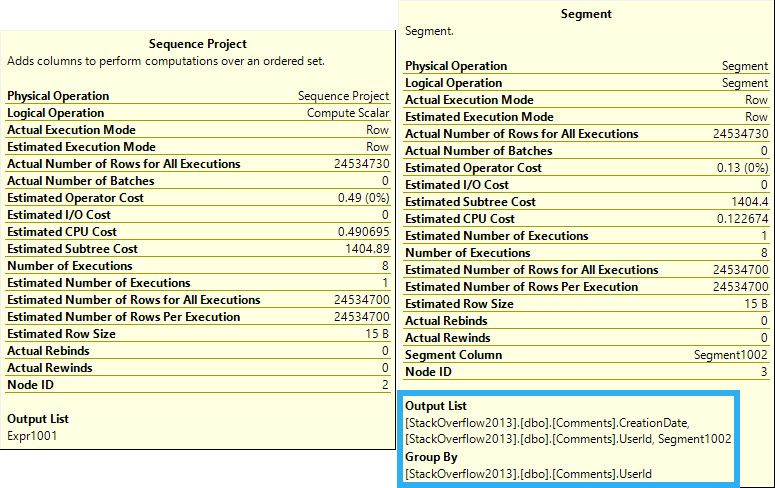
Group is in quotes up there, because technically there’s no grouping. The “Segment1002” column in the Output List of the Segment is a computed column that marks the beginning and ending of each set of values. Likewise, the Sequence Project outputs “Expr1001”, which in this case is the calculated row number.
Batch Mode
In Batch Mode, there are three operators associated with windowing functions that get replaced with a single operator: the Window Aggregate.
The operators that get replaced are two we’ve already seen — Segment and Sequence Project, along with one we’ll see in a future post, the Window Spool.
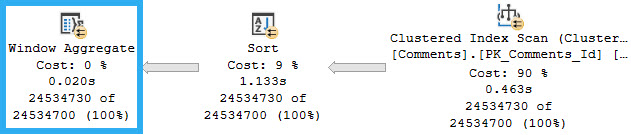
We still need to Sort data for it without a supporting index. Gosh, those indexes sure are magickal.
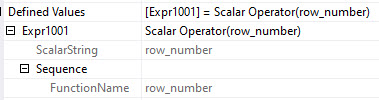
The details of the Window Aggregate do still show a sequence generated, but we no longer see the “grouping”.
Baby Steps
Batch Mode kicks the pantalones off of Row Mode when it comes to window functions, but that’s not really the point of the post.
If you’re using a relatively modern version of SQL Server and also windowing functions, you should look at various ways to get Batch Mode processing alongside them.
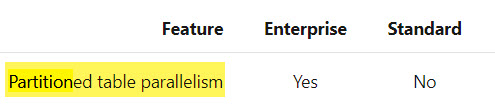
Unless you’re on Standard Edition, probably.
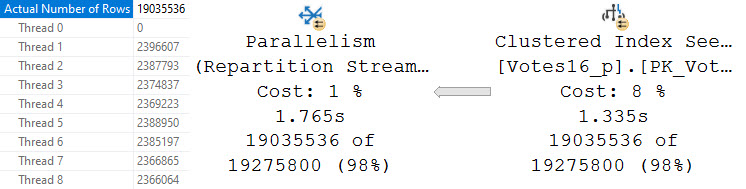
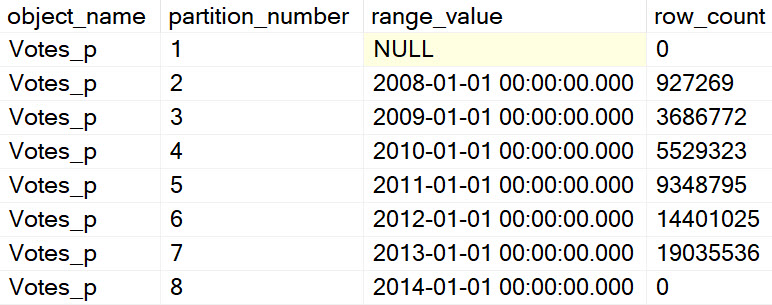
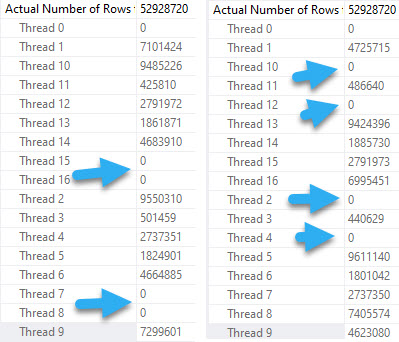
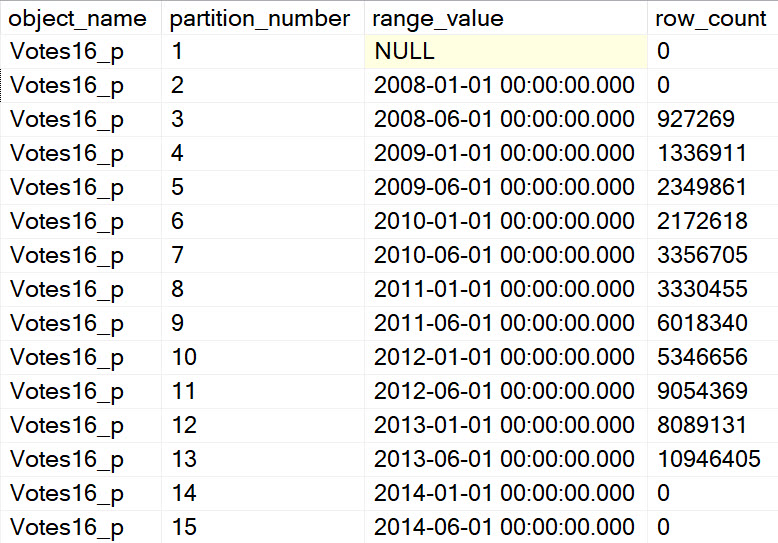
In the next entry in this series, we’ll look at how the absence and presence of Partition By changes parallelism.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.